






 本文详细分析了通过Hadoop命令行工具`hadoopfs-cat`读取HDFS文件的过程,从官方架构理解开始,通过源码追踪,揭示了从命令行参数解析、NameNode通信、DFSClient获取块信息、创建DFSInputStream到实际读取数据的完整步骤。
本文详细分析了通过Hadoop命令行工具`hadoopfs-cat`读取HDFS文件的过程,从官方架构理解开始,通过源码追踪,揭示了从命令行参数解析、NameNode通信、DFSClient获取块信息、创建DFSInputStream到实际读取数据的完整步骤。
一、简单回顾下HDFS的架构
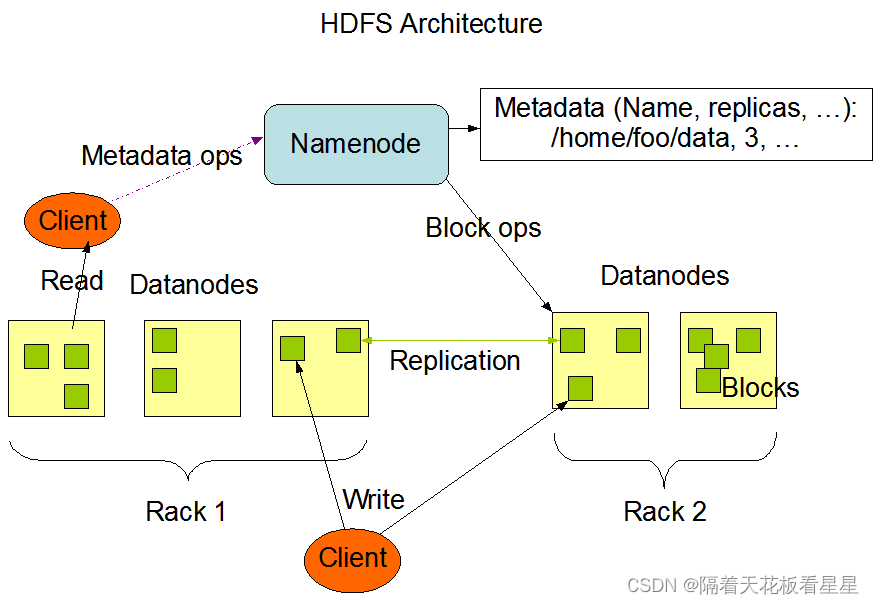
如果不了解HDFS的可以看下我写的一篇博客<Hadoop-HDFS概览>,这里先贴下官网架构图:
二、静静的思考一会儿
爱因斯坦说过:想象力比知识更重要。想象力推动世界,是知识进化的源泉。
我们先不看源码,先通过官方架构图和我们对HDFS的了解来想象下读流程是什么样的。
我要读HDFS上的一份文件,首先需要知道它在哪台节点上,HDFS上存储的文件都是以块的形式存放在各个DataNode节点上。因此需要知道这个文件对应的了多少块(包括副本)都在什么哪些节点上以及节点的哪些目录中(那就需要请求NameNode),通过机架感知找到离Client节点最近的文件对应的每个块,然后依次发起读请求(请求DataNode),最后合成结果文件即可。
三、通过源码进行验证
源码中写的肯定是最真实的,下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧
1、命令行
我们读取HDFS上的数据时是怎么读取的呢?我一般是通过命令行查看文件大小或一些示例数据,如:
hadoop fs -du -h /user/hhs/test.txt
hadoop fs -cat /user/hhs/test.txt | head -10
我们以 -cat 为例看看它背后执行了什么,我们看下hadoop命令

fs 对应的是 运行一个通用文件系统用户客户端,我们用more命令看下hadoop命令里面的实现
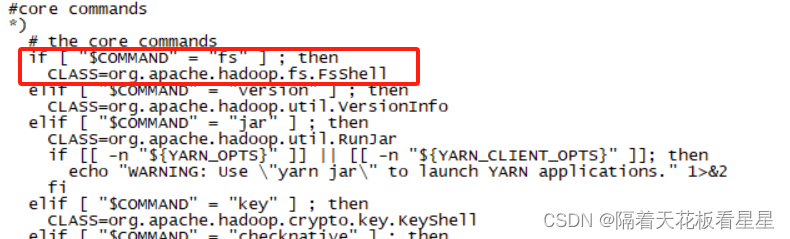

最后用java命令执行($@:表示获取执行脚本传入的所有参数)
我们去源码里面看下 org.apache.hadoop.fs.FsShell
2、FsShell
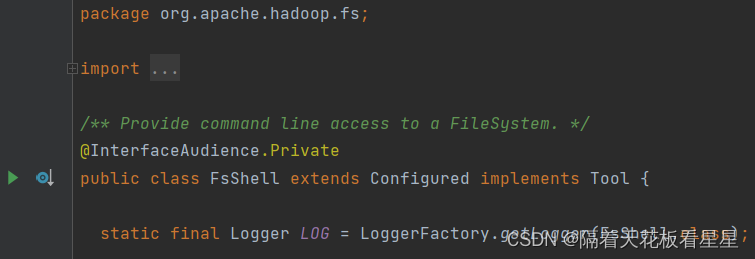
注释:提供对文件系统的命令行访问
我们查看细main方法并跟一下(如果跳一次截图下太多了,这里和后面只截重要的地方)

设置调用者和Configuration并解析命令行参数 例如 [fs,-cat,/user/hhs/test.txt]
Configuration提供了对配置参数的访问,比如读取搭建集群时的配置的core-site.xml
调用tool.run(toolArgs)

接着调用的是org.apache.hadoop.fs.shell.Command.run(String...argv)
3、Command

方法注释为:调用命令处理程序。默认行为是处理选项、展开参数,然后处理每个参数。
//处理命令行标志并检查其余参数的边界。如果抛出IllegalArgumentException,FsShell对象将打印该命令的简短用法。
processOptions(args);
//调用了子类的实现,下面看下org.apache.hadoop.fs.shell.FsCommand.processRawArguments(args)
processRawArguments(args);
4、FsCommand
类注释是这样描述的:所有“hadoop-fs”命令的基类。而且注册了很多常用命令处理类,如ls、mkdir等,但是没有看到cat
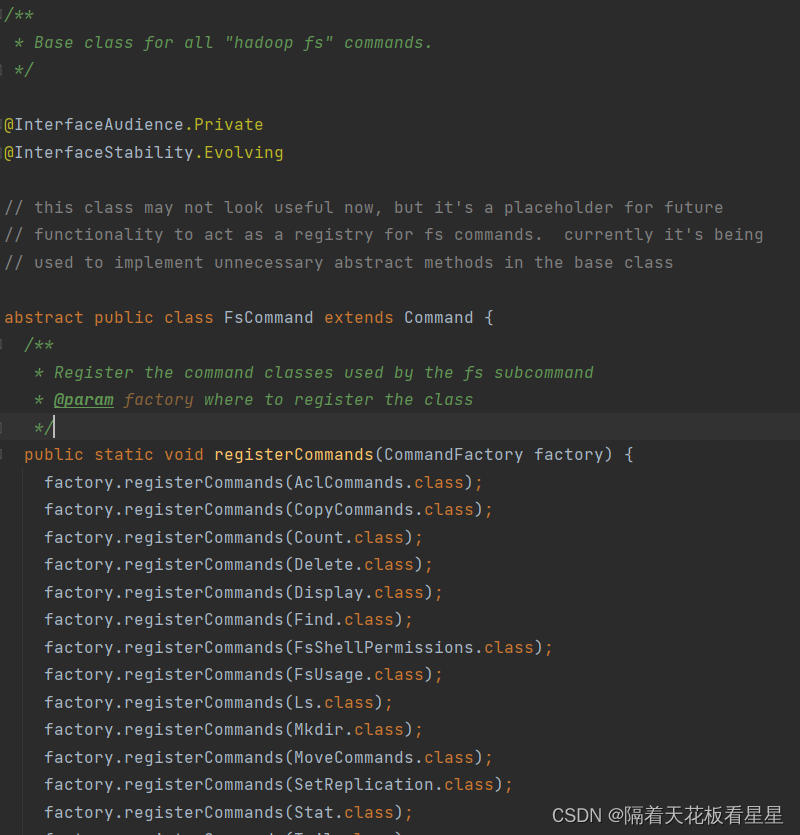

processRawArguments(args) 方法中对环境是否设置fs.defaultFs做了校验,如果没有设置会提示:警告:当你运行....命令时fs.defaultFs未设置
processArguments(expendedArgs) 最终又调用了父类Command的方法,经过多次调用后会来到对应的Cat.class 它是Display的内部类,下面我们看下Display
5、Display-Cat
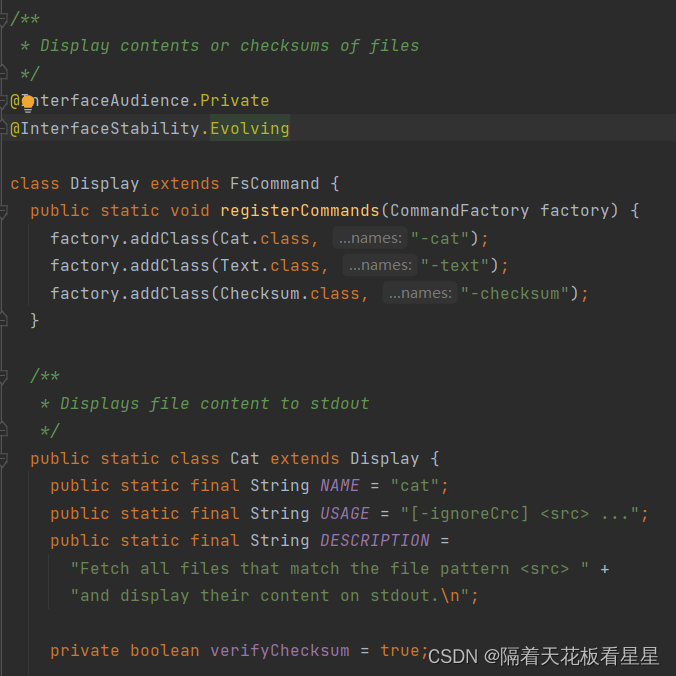
类注释:显示文件的内容或校验和
原来在这里注册了cat 和 text ,并且和 mkdir、ls命令不同这里多了一个校验和(检测文件内容是否受损),因为cat命令涉及到了具体文件内容的读取,而mkdir、ls不涉及内容的读取,只和命名空间数据交互即可。
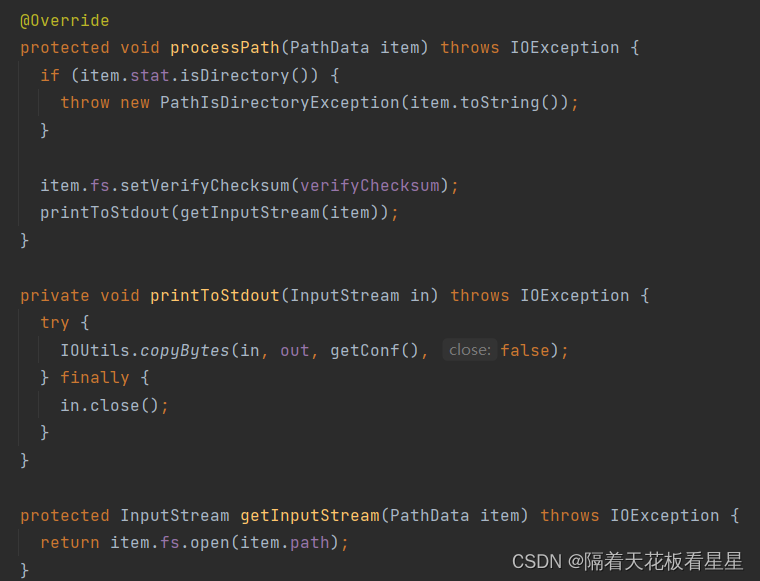
可以看到会通过FileSystem拿到对应文件的InputStream,并输出到命令行界面。到此整个流程就结束了,下面我们详细看下item.fs.open(item.path); 也就是怎么通过文件路径拿到InputStream的
6、FileSystem
类注释:这是一个相当通用的文件系统的抽象基类。它可以实现为分布式文件系统,也可以实现连接本地磁盘的“本地”文件系统。且建议如果使用HDFS应该使用其父对象:FileSystem。
FileSystem 有很多子类,即DistributedFileSystem、FTPFileSystem、HttpFSFileSystem、RawLocalFileSystem、WebHdfsFileSystem等等,DistributedFileSystem只是其中一个子类。
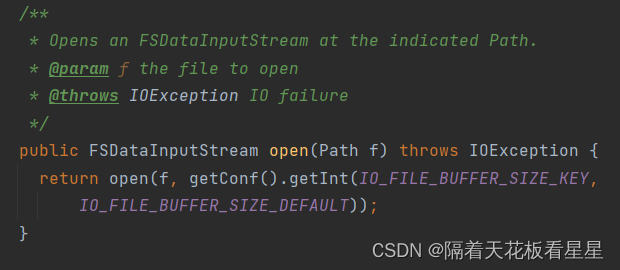
最终还是调用子类的open方法,这里用的是HDFS,所以我们看DistributedFileSystem的open()
7、DistributedFileSystem
类注释:此对象是最终用户代码与Hadoop DistributedFileSystem(HDFS)交互的方式
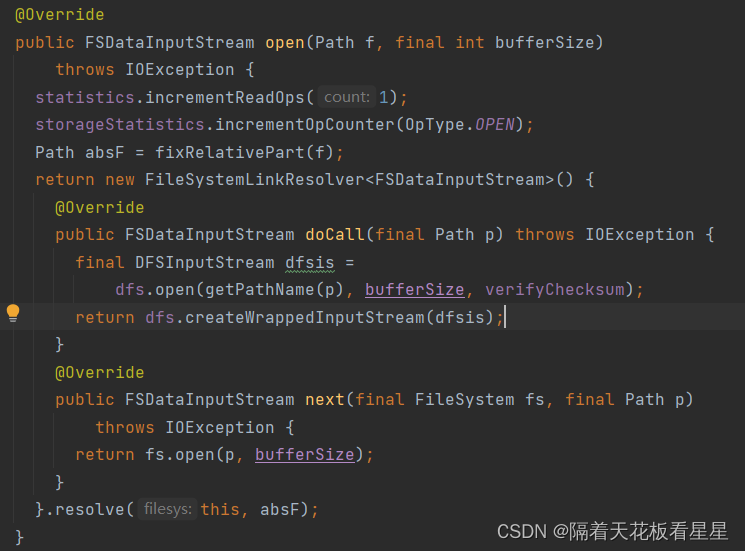
调用了FileSystemLinkResolver.resolve(),这里重写了doCall()和next()
resolve()会先调用重写的{@link#doCall(Path)}方法,如果调用失败并出现UnsolvedLinkException,将尝试解析路径,并通过调用{@link#next(FileSystem,path)}重试调用。
dfs.open()会调用DFSClient.open()
8、DFSClient
类注释:DFSClient可以连接到Hadoop文件系统并执行基本的文件任务。它使用ClientProtocol与NameNode守护进程通信,并直接连接到DataNodes以读取/写入块数据。Hadoop DFS用户应该获得DistributedFileSystem的一个实例,该实例使用DFSClient来处理文件系统任务。
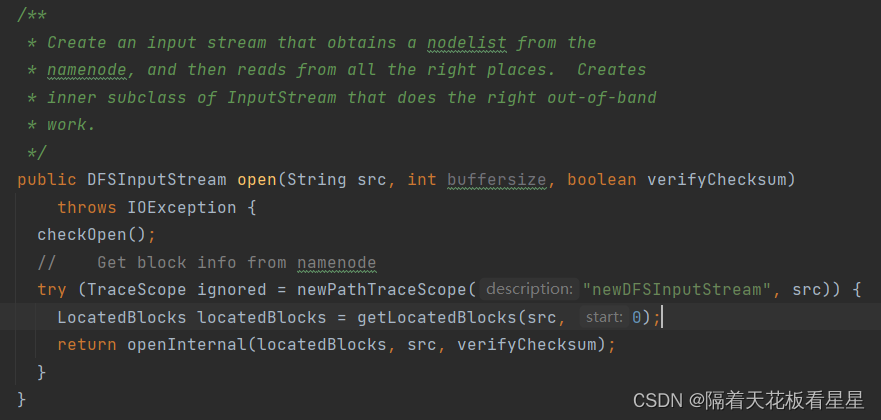
创建一个输入流,该流从namenode获取块的节点信息列表,然后从所有正确的位置读取。创建InputStream的内部子类,该子类执行带外工作
8.1、从NameNode获取块信息
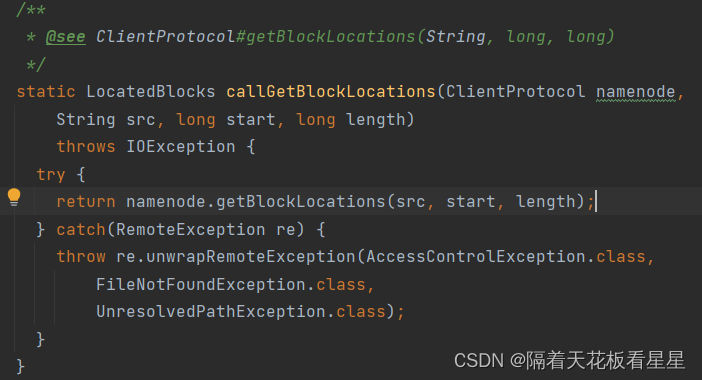
这里通过ClientProtocol调用了NameNodeRpcServer.getBlockLocations()
8.1.1、NameNodeRpcServer
ClientProtocol类注释:用户代码通过DistributedFileSystem类使用ClientProtocol与NameNode通信。用户代码可以操作目录命名空间,以及打开/关闭文件流等。
NameNodeRpcServer类注释:负责处理对NameNode的所有RPC调用。它由{@link NameNode}创建、启动和停止
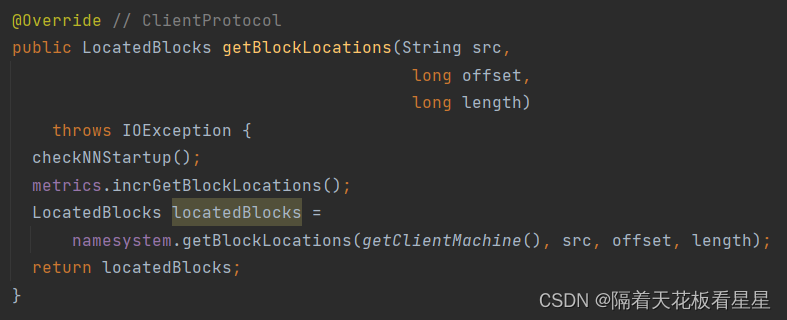
获取指定文件的块在指定范围内的位置。每个块的DataNode位置根据与客户端的接近程度进行排序。
返回{@link LocatedBlocks},其中包含文件长度、块及其位置。每个块的DataNode位置根据到客户端地址的距离进行排序。
然后,客户端将连接所指示的DataNode节点之一以获得实际数据。
这里会调用FSNamesystem.getBlockLocations()
8.1.2、FSNamesystem
类注释:FSNamesystem是一个临时和持久名称空间状态的容器,并在NameNode上完成所有的记账工作。其作用简述如下:
1) 是BlockManager、DatanodeManager、DelegationTokens、LeaseManager等服务的容器。
2) 修改或检查命名空间的RPC调用应在此处获得委派。
3) 任何只涉及区块的东西(例如区块报告),都会委托给区块管理器。
4) 任何只涉及文件信息(例如权限、mkdirs)的内容,它都会委托给FSDirectory。
5) 任何跨越上述两个组成部分的内容都应该在此处进行协调。
6) 将突变记录到FSEditLog。
此类及其内容保持:
1) 有效的fsname--> blocklist(保存在磁盘上,已记录)
2) 所有有效块的集合
3) 块--> 机器列表(保存在内存中,根据报告动态重建)
4) 机器-->blocklist
5) 更新的心跳机器的LRU缓存
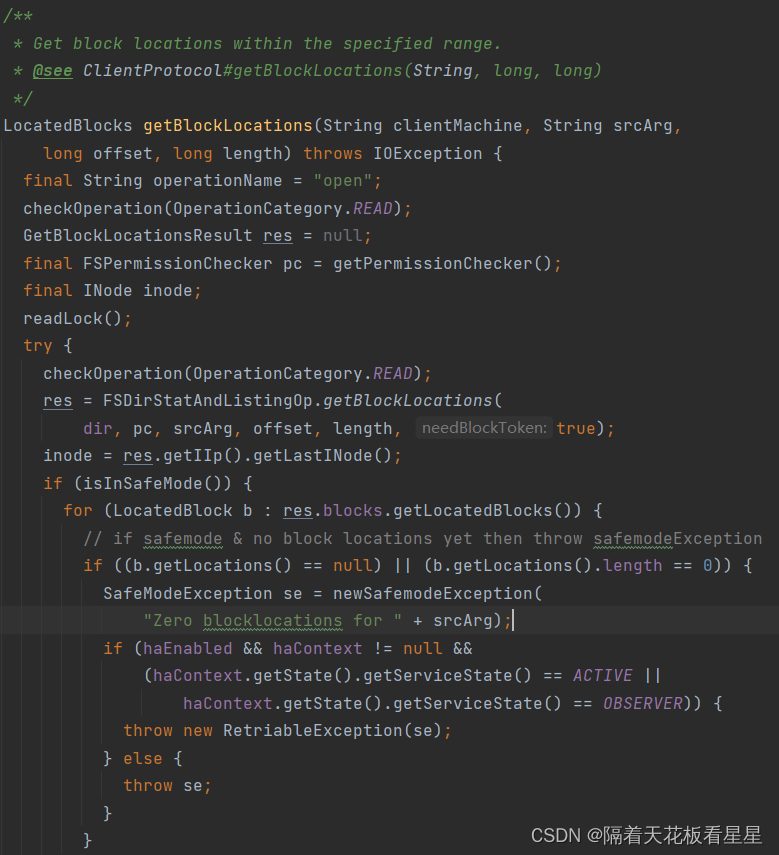
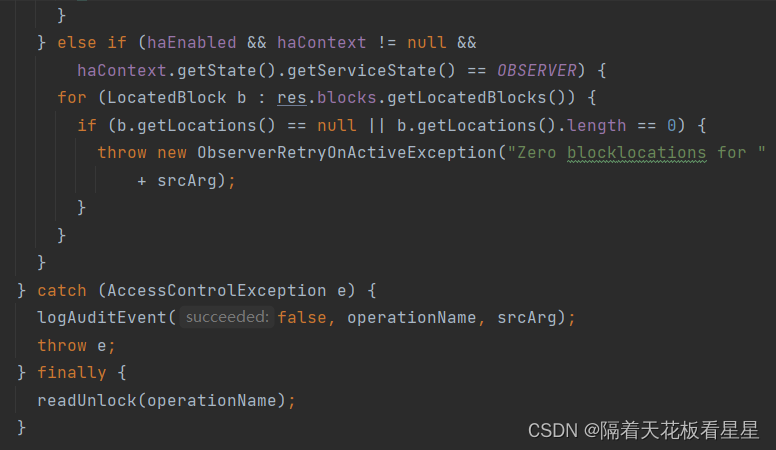
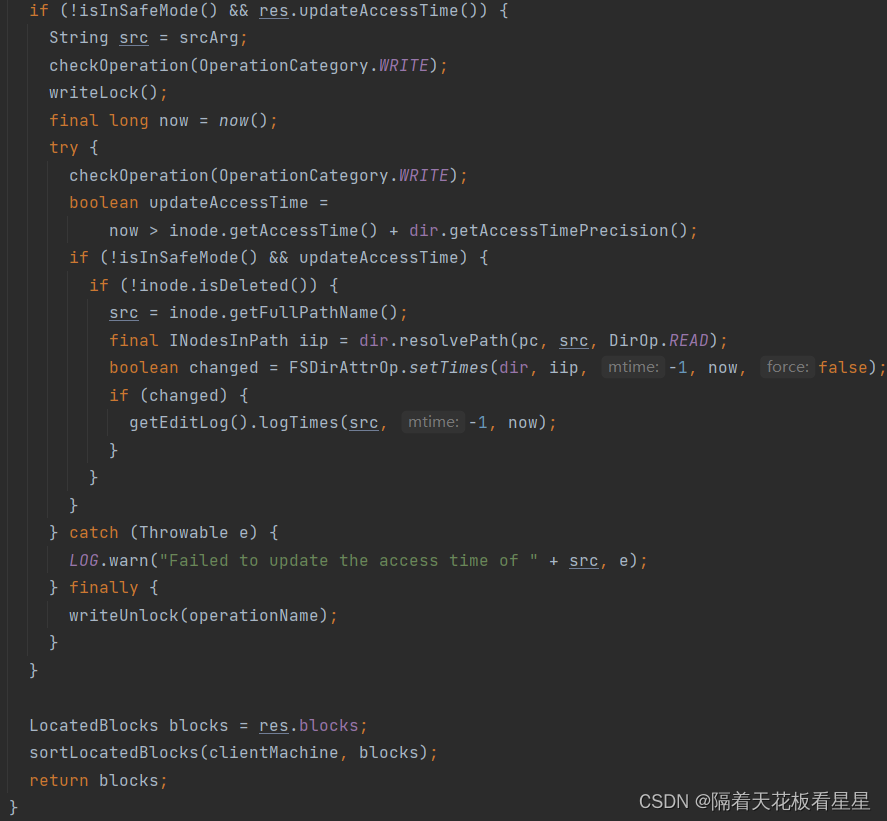
方法注释:获取指定范围内的块位置。
从return可以看到按照和客户端机器的距离顺序返回了块信息列表
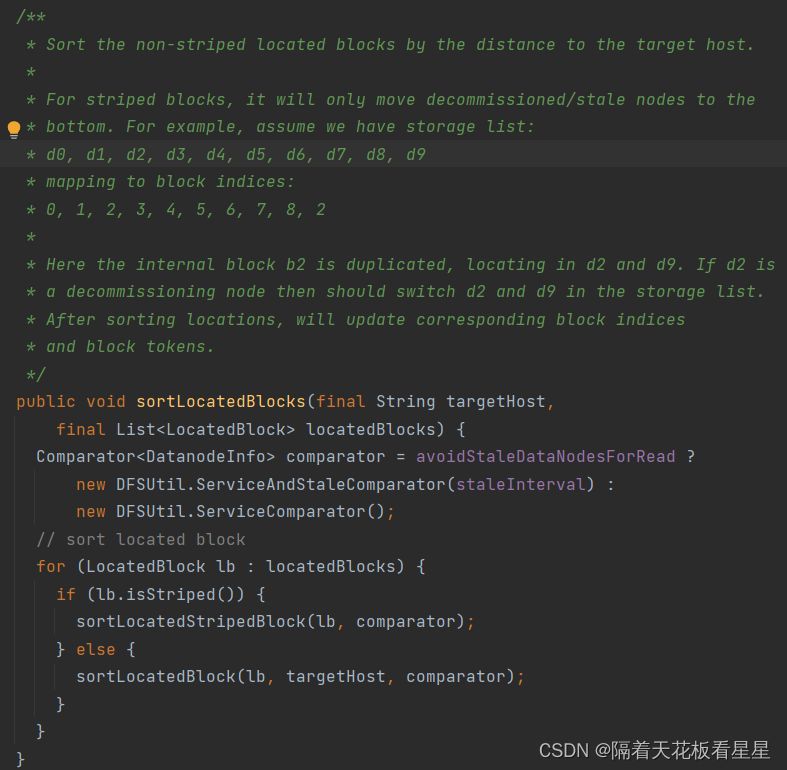
方法注释:根据到目标主机的距离对非条带化定位的块进行排序。
对于条带化块,它只会将已停用/过时的节点移到底部。例如,假设我们有存储列表:
d0, d1, d2, d3, d4, d5, d6, d7, d8, d9
映射到块索引:
0, 1, 2, 3, 4, 5, 6, 7, 8, 2
这里,内部块b2被复制,位于d2和d9中。如果d2是停用节点,则应当切换存储列表中的d2和d9。排序位置后,将更新相应的块索引和块标记。
8.1.3、FSDirStatAndListingOp
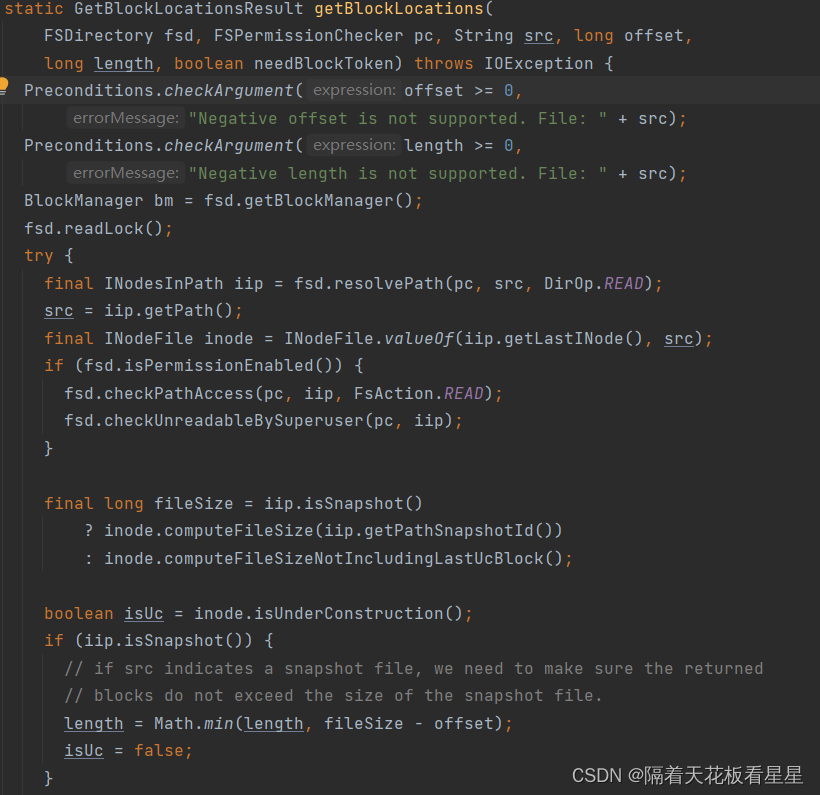
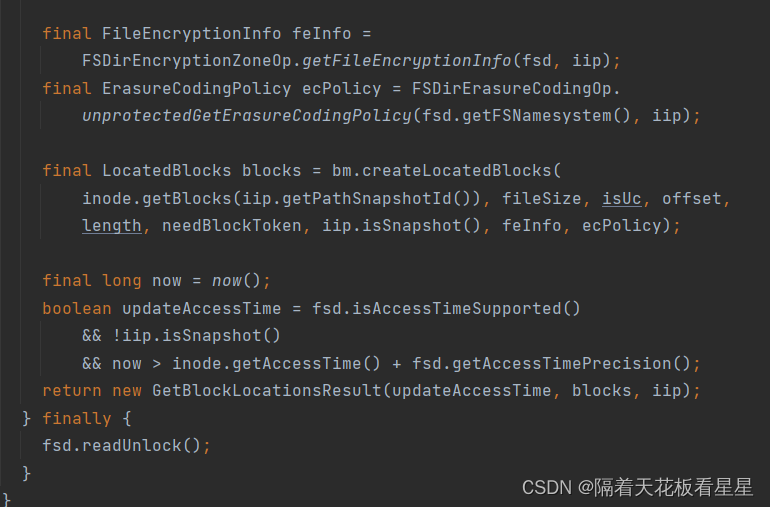
调用 BlockManager.createLocatedBlocks()
8.1.4、BlockManager
类注释:保存与Hadoop集群中存储的块相关的信息。对于块状态管理,它试图在任何事件(如退役、名称节点故障转移、数据节点故障)下维护“实时副本数==预期冗余数”的安全属性。(也就是当一个块坏了,BlockManager会帮我们再复制一个块出来)
维护模式的动机是允许管理员在不支付退役成本的情况下快速修复节点。因此,在维护模式下,实时复制副本的数量不必等于预期冗余的数量。如果任何复制副本处于维护模式,则安全属性扩展如下。这些属性仍然适用于零维护副本的情况,因此我们可以在所有场景中使用这些安全属性。
a、实时复制副本的数量>=用于维护的最小复制数量。
b、实时复制副本的数量<=预期冗余的数量。
c、实时复制副本和维护复制副本的数量>=预期冗余的数量。
另一个安全特性是满足块放置策略。虽然该策略是可配置的,但应用该策略的副本是实时副本+维护副本。
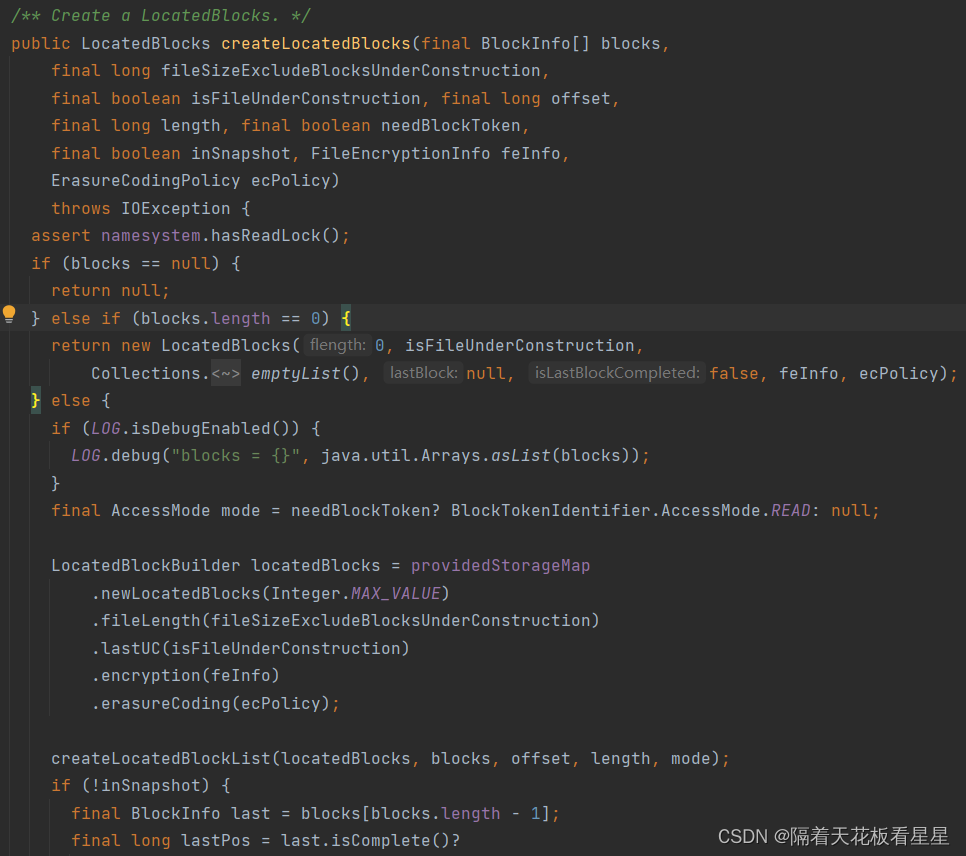

利用CacheManager把块信息列表放入缓存并返回信息列表
8.1.5、CacheManager
类注释:缓存管理器处理DataNode上的缓存。这个类是由FSNamesystem实例化的。它通过处理DataNode缓存报告来维护缓存块到数据节点的映射。基于这些报告以及缓存指令的添加和删除,我们将安排缓存和取消缓存工作。

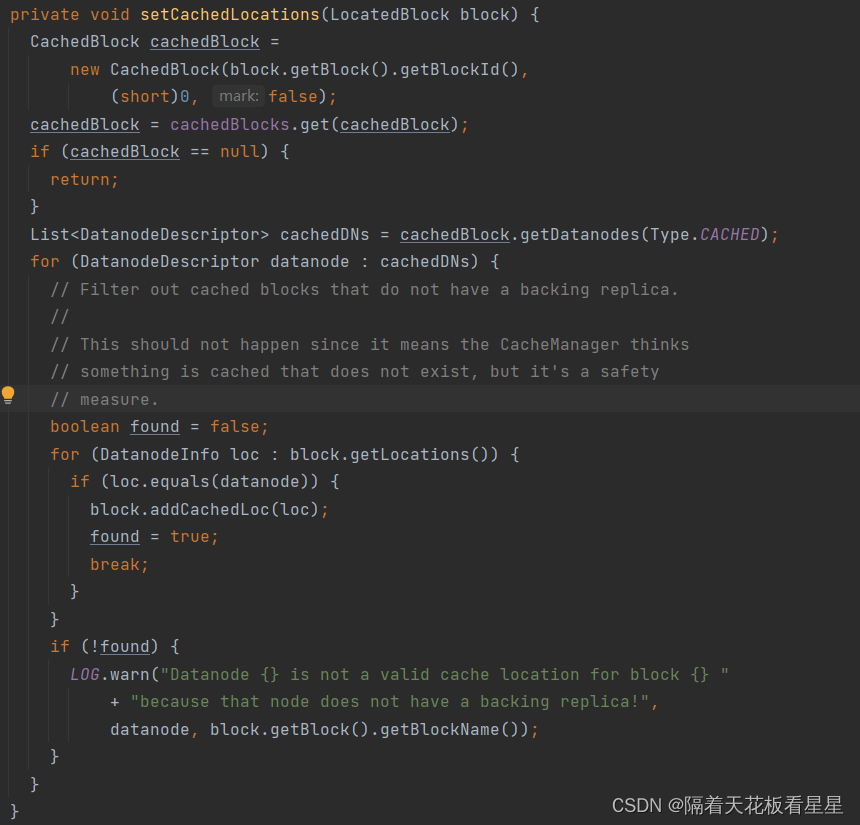
循环每一个块,并获取缓存、计划缓存或计划取消缓存此块的数据节点的列表。
循环该块所在的有缓存的DataNode列表,找到第一个DataNode并设置该块的缓存位置
如果循环下来没有发现该块在DataNode上有缓存,就不设置。
8.2 根据块信息列表创建DFSInputStream
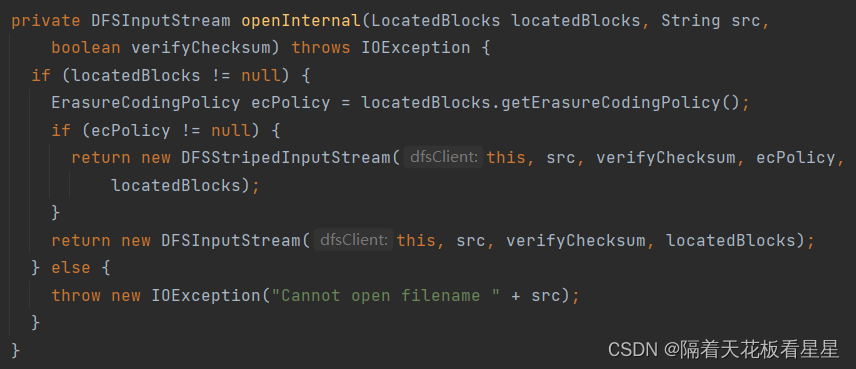
//根据这些块是否有策略走不同的实例化方法,有策略构建DFSStripedInputStream,没有构建DFSInputStream
ErasureCodingPolicy ecPolicy = locatedBlocks.getErasureCodingPolicy();
我们先看DFSInputStream构建过程
8.2.1、DFSInputStream
类注释:DFSInputStream提供来自命名文件的字节。它根据需要处理NameNode和各种DataNode的协商。

//刷新已经定位的块信息,刷新inputstream的blocklocation之前的等待时间窗口
this.refreshReadBlockIntervals = this.dfsClient.getRefreshReadBlkLocationsInterval();
后面有对是否校验和、HDFS路径、块信息列表后执行openInfo(false);从NameNode获取打开的文件信息。
openInfo(false);
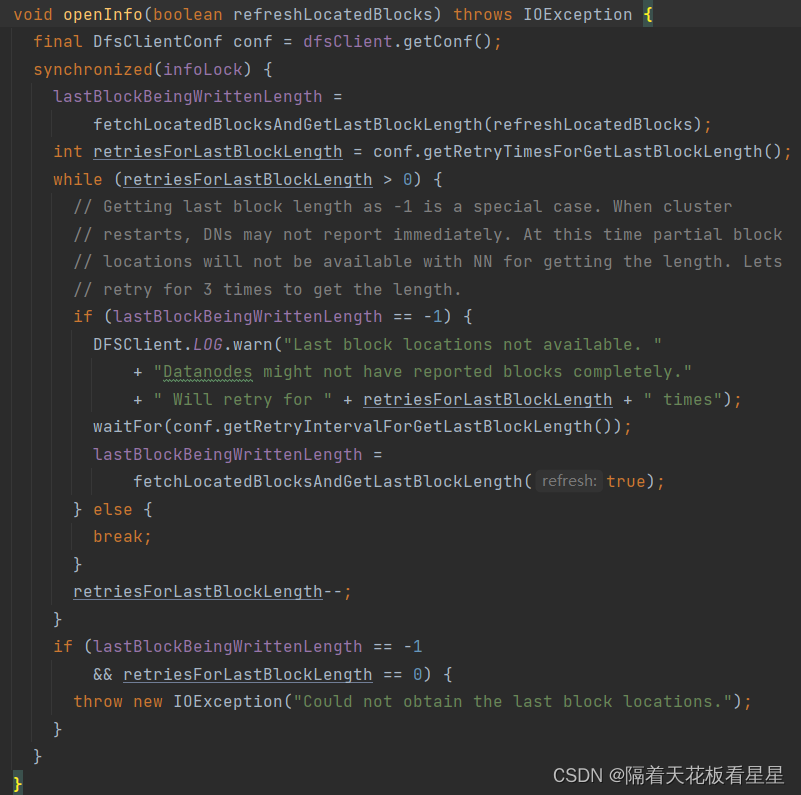
//重写连接NameNode,并从DataNodes中的一个节点获取最后一个块的长度信息
lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength(refreshLocatedBlocks);
//对最后一个块的长度进行重试读取,默认三次重试(当HDFS启动时,DataNode可能不会立即报告块信息,因此要重新获取)
9、再回Display-Cat
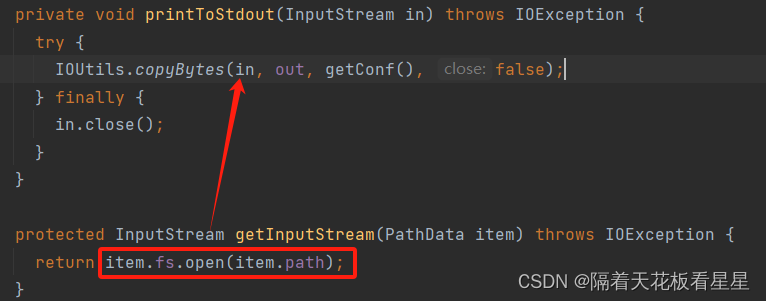
得到输入流后会调用IOUtils.copyBytes()将输入流的内容都给输出流然后展示给命令行进行回显(默认缓冲区大小为4096)
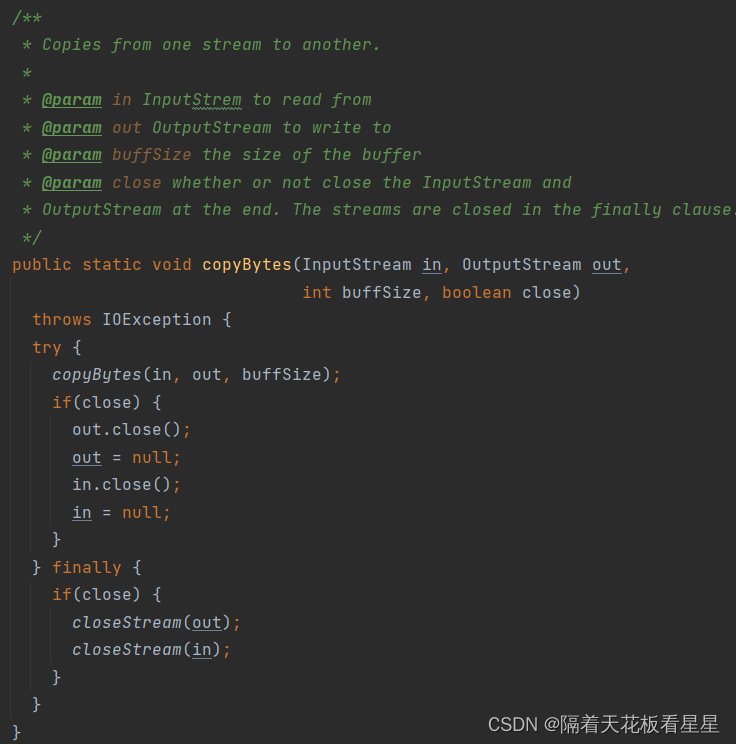
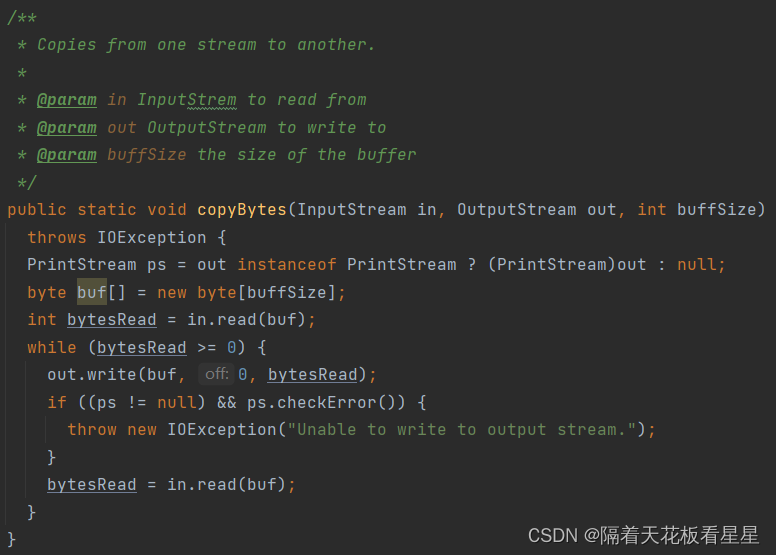
用递归的方式将DFSInputStream中的数据都读出来并复制给输出流。
到这里整体的读流程就分析完了,下面我们重点看下DFSInputStream.read(buf)
10、再回DFSInputStream
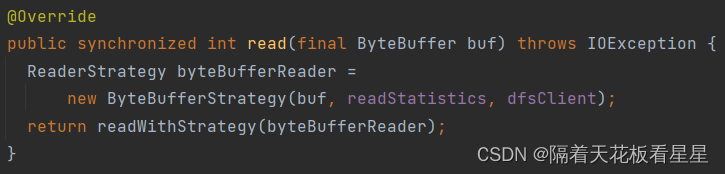
ByteBufferStrategy类注释:用于将字节读取到用户提供的ByteBuffer中。请注意,它不是线程安全的,如果并发操作,则不会定义行为。执行读取操作时,底层字节缓冲区的位置将向前移动,如ByteBufferReadable#read(ByteBuffer-buf)方法中所述。
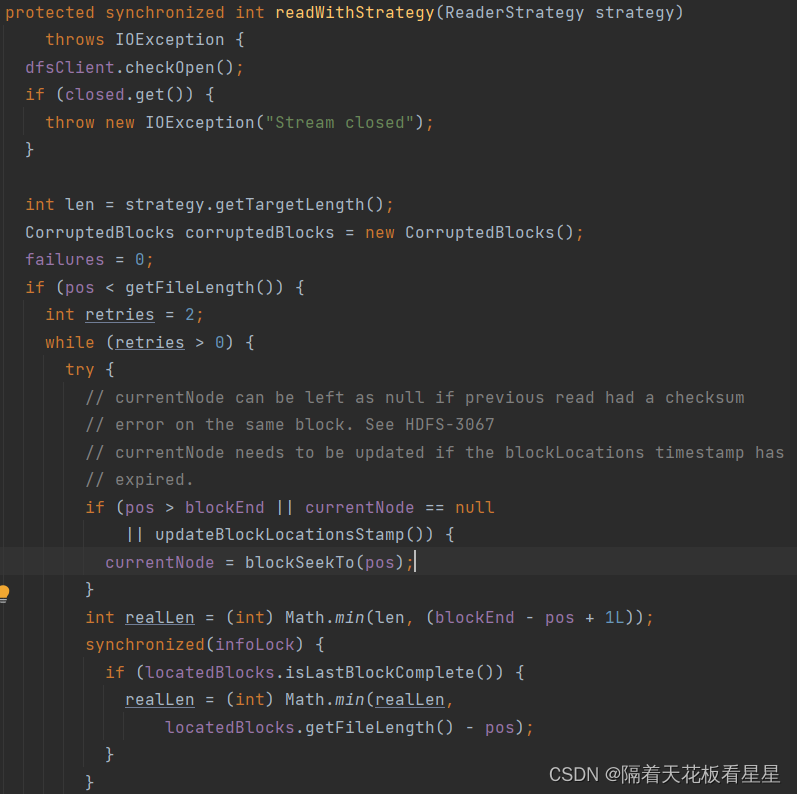
如果在同一块上有校验和错误currentNode可以保留为null。如果blockLocations时间戳已过期currentNode需要更新
//打开到DataNode的DataInputStream,以便可以从中读取它。在启动时从namenode获取块ID和目的地的ID。
10.1、blockSeekTo()
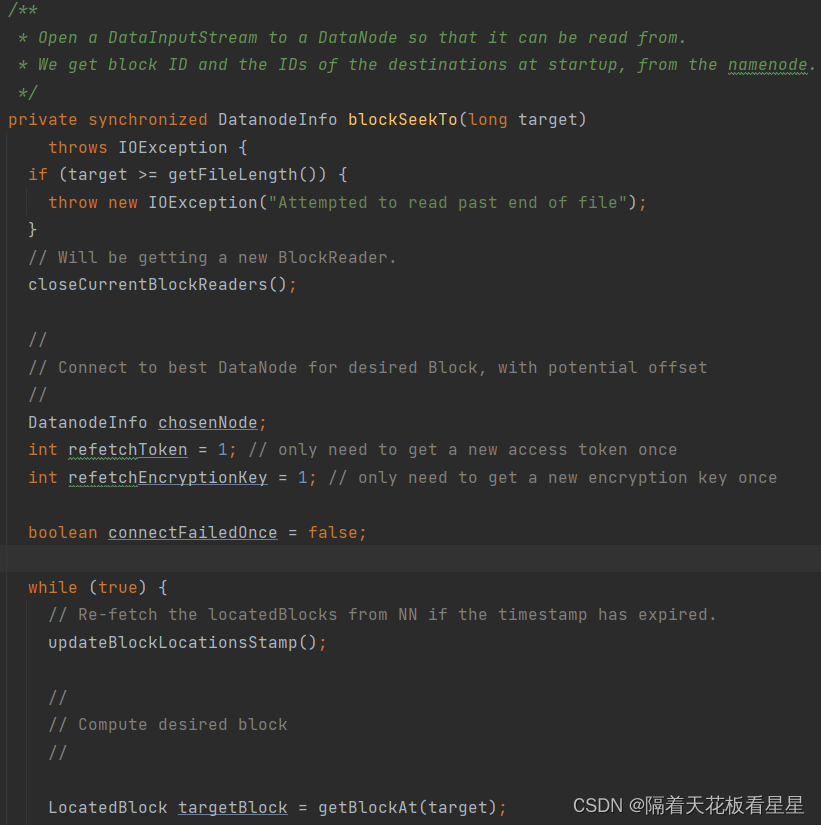
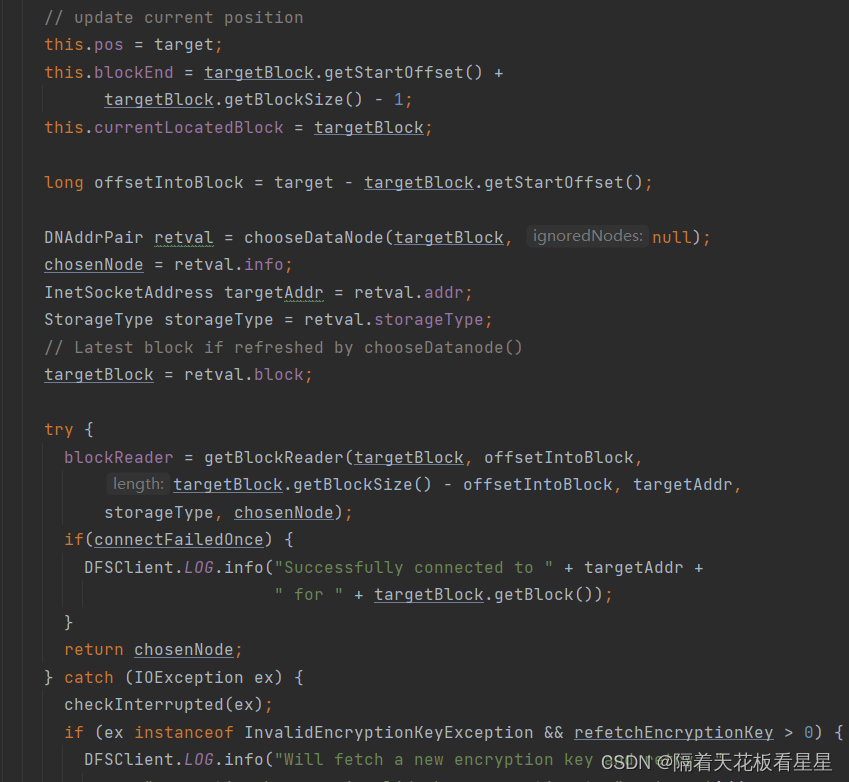
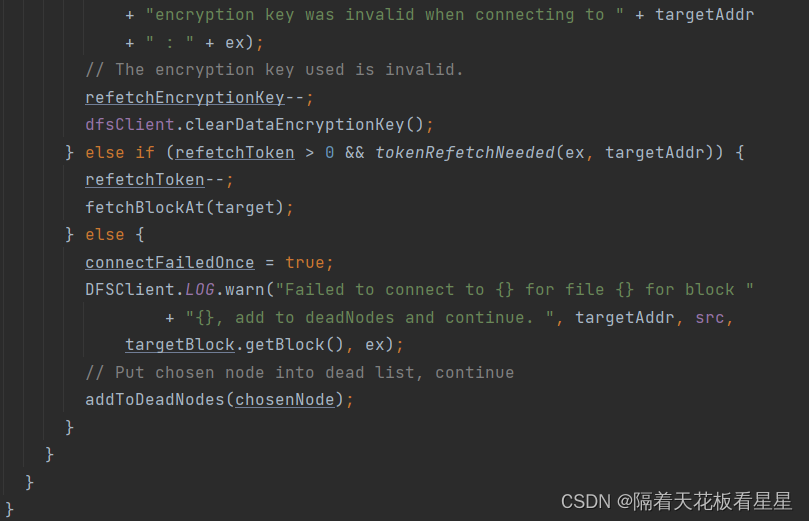
1、关闭当前的BlockReader 获取新的BlockReader(关闭当前的块读取器,以便新的缓存设置可以立即生效)
2、连接到所需块的最佳DataNode,具有潜在偏移
2.1、如果时间戳已过期,则从NameNode重新获取locatedBlocks。
2.2、计算所需块(在指定位置获取块。如果没有缓存,则从namenode获取块并缓存该块)
2.3、getBestNodeDNAddrPair() 获取块对应最好的DataNode(FSNamesystem处已经写了块信息列表是按照和客户端的距离排好序的,这里剔除了坏块DataNode信息和需要忽略的DataNode,然后取列表中的最后一个DataNode来做为最终的DataNode,如果找不到就报告块丢失)
2.4、创建和块对应最佳DataNode的socket连接
2.5、返回DNAddrPair(里面有最佳DataNode、socket连接、存储类型、块信息)
3、创建BlockReader(BlockReader负责从单个DataNode读取单个块)
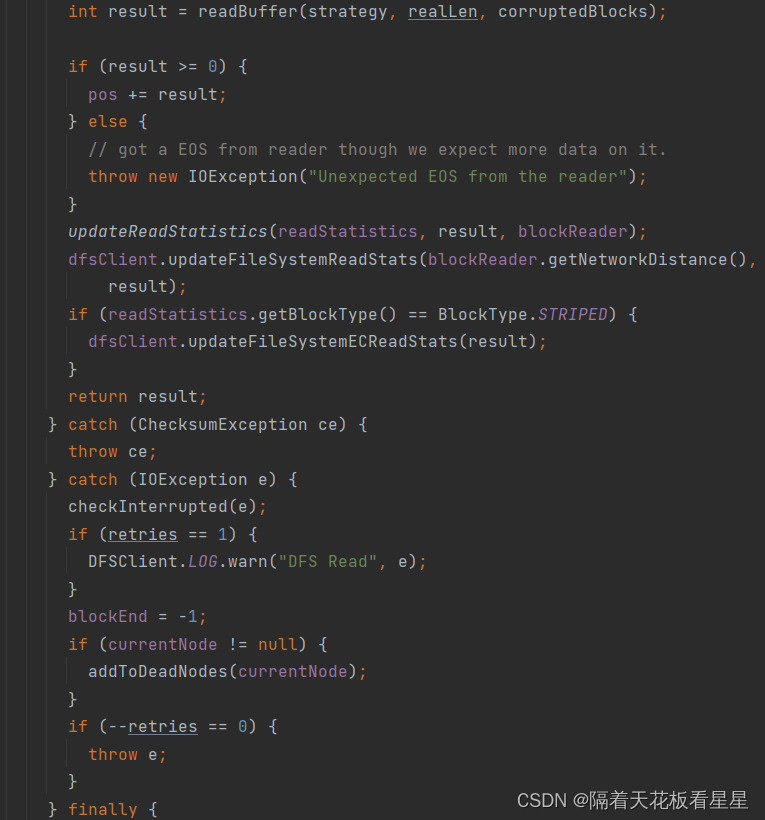
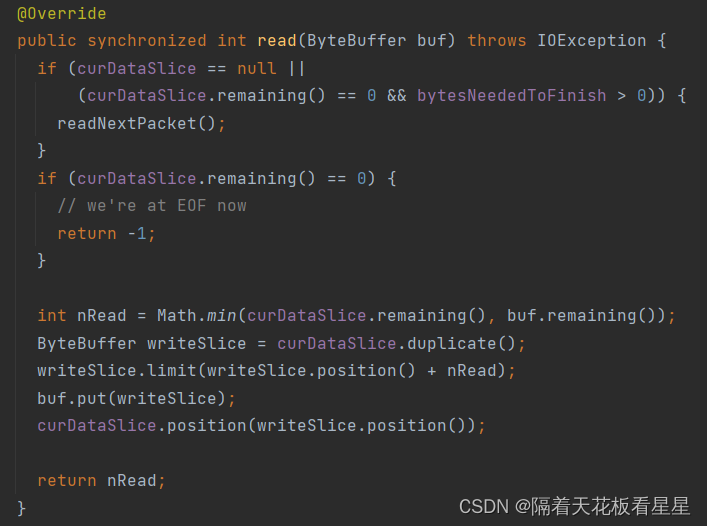
10.2、readBuffer()
int result = readBuffer(strategy, realLen, corruptedBlocks);
readBuffer会调readFromBlock()
readFromBlock又会调blockReader.read()按照Packet进行读取。
四、整理读取流程
1、命令行输入hadoop fs -cat /user/hhs/test.txt | head -10
2、hadoop命令对应脚本启动java进程(启动类为org.apache.hadoop.fs.FsShell)并把所有参数(fs -cat /user/hhs/test.txt | head -10)作为参数都传进去
3、解析参数(如果参数有fs设置FileSystem的默认Uri)并调用命令处理程序Display-Cat
4、Display-Cat调用FileSystem.open()方法,最终调用DFSClient.open()
5、DFSClient通过ClientProtocol连接NameNode获取块列表信息(块对应的DataNode列表是按照和客户端的距离排好序的)
6、创建DFSInputStream并返回给命令处理程序Display-Cat
7、Display-Cat调用DFSInputStream.read()读取文件内容(连接最佳的DataNode并按照Packet进行读取)
8、命令行通过linux管道 | 回显文件内容的前10行数据















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









