







- windows10 环境
- 训练word2vec
- 中文语料
- 概述
本人是NLP中的菜鸟,喜欢这个领域,自己论文打算做这方面,训练word2vec是每一项NLP工作的基础内容。形成词向量直接用于神经网络的输入层,也可以作为辅助特征扩展现有模型,提高识别效果。先了解一下word2vec,是google在2013年提出的开源项目,是一个Deep Learning模型,它将term表征成实数值向量,采用CBOW(Continuous Bag-Of-Words Model,连续词袋模型)和Skip-Gram(Continuous Skip-GramModel)两种模型。具体原理可以参考这篇文章。这篇文章
环境配置
本人使用的Windows10 ,大部分工作在windows环境下进行,对linux了解非常少,配环境换了不少事件。安装linux环境模拟器,我用的是cygwin64你可以去官网载,但是我在载的过程中出现了进度条到70%卡住现象,所以在网上直接下载的安装包。我传到百度云盘上。在安装时注意:因为默认安装下没有安装make命令工具(后面要用到),所以在安装时,选择package时,需要选择Devel与Utils模块。
源码下载,我用的是word2vec的源码,[这是源码],除此以外还用改动过的java版本和c++版本这里就不介绍了(http://pan.baidu.com/s/1c1dxIE0)
- 训练数据下载,其中源文件自带两个英文语料分别是
我用的几个语料放在一起的一篇叫做peoplePaper.txt的语料,分享给大家
具体语料见文件夹下面,网上还有其他的语料但我看了一下得需要积分下载吧,这里面的语料可以直接应用不需要进行分词了 - 启动cygwin,使用cd+文件目录下,(不熟悉语法的,可以将文件夹直接拖拽过去,windows给我们惯坏了,呵呵),在make之前打开makefile文件需要修改一下,我把修改完的文件给大家看一下

CC = gcc
#Using -Ofast instead of -O3 might result in faster code, but is supported only by newer GCC versions
#CFLAGS = -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result
all: word2vec word2phrase distance word-analogy compute-accuracy
word2vec : word2vec.c
$(CC) word2vec.c -o word2vec $(CFLAGS)
word2phrase : word2phrase.c
$(CC) word2phrase.c -o word2phrase $(CFLAGS)
distance : distance.c
$(CC) distance.c -o distance $(CFLAGS)
word-analogy : word-analogy.c
$(CC) word-analogy.c -o word-analogy $(CFLAGS)
compute-accuracy : compute-accuracy.c
$(CC) compute-accuracy.c -o compute-accuracy $(CFLAGS)
chmod +x *.sh
clean:
rm -rf word2vec word2phrase distance word-analogy compute-accuracy把没用的注释掉了,具体什么意思,本菜鸟也不懂。编译完成后会生成一些.exe文件去目录下看一下! [本人生成的文件]
(https://img-blog.csdn.net/20160303153508519)
5 . 进入到word2vec目录下面,用记事本或者UE打开demo-word.sh文件,(demo-classes.sh用于聚类用的文件),将自己的数据添加进去,具体结果如下:
#make
#if [ ! -e text8 ]; then
#wget http://mattmahoney.net/dc/text8.zip -O text8.gz
#gzip -d text8.gz -f
#fi
time ./word2vec -train peoplePaper.txt -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -binary 1 ./distance vectors.bin这里有必要说一下集体参数的含义:
- time:训练的事件
- word2vec:训练执行的文件
- peoplePaper.txt:训练数据
- vectors.bin:输出文件
- cbow:在cbow和skip-Gram语言模型选一个,网上说skip-Gram模型要好一些,但速度慢一下
- size:输出词向量的维数
- window:一个词考虑前五个词和后五个词之间联系
- negative 表示是否使用NEG方,0表示不使用,其它的值目前还不是很清楚
- -hs 是否使用HS方法,0表示不使用,1表示使用
- sample 表示 采样的阈值,如果一个词在训练样本中出现的频率越大,那么就越会被采样
- binary 表示输出的结果文件是否采用二进制存储,0表示不使用(即普通的文本存储,可以打开查看),1表示使用,即vectors.bin的存储类型
- alpha 表示 学习速率
- min-count 表示设置最低频率,默认为5,如果一个词语在文档中出现的次数小于该阈值,那么该词就会被舍弃
- classes 表示词聚类簇的个数,从相关源码中可以得出该聚类是采用k-means
6 .运行sh demo-word.sh,等待完成
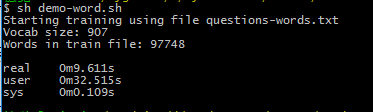
7 .训练完成
模型训练完成之后,得到了vectors.bin这个词向量文件,文件的存储类型由binary参数觉得,如果为0,便可以直接用编辑器打开,进行查看,向量维度由size参数决定。于是我们可以使用这个向量文件进一步进行自然语言处理了。比如求相似词,关键词聚类与分类等。其中word2vec中提供了distance求词的cosine相似度,并排序。也可以在训练时,设置-classes参数来指定聚类的簇个数,使用kmeans进行聚类。

我把训练完成的文件也分享给大家;
包含英文和中文
8 .问题
生成的英文语料可以计算向量之间的相似程度,如下图所示:
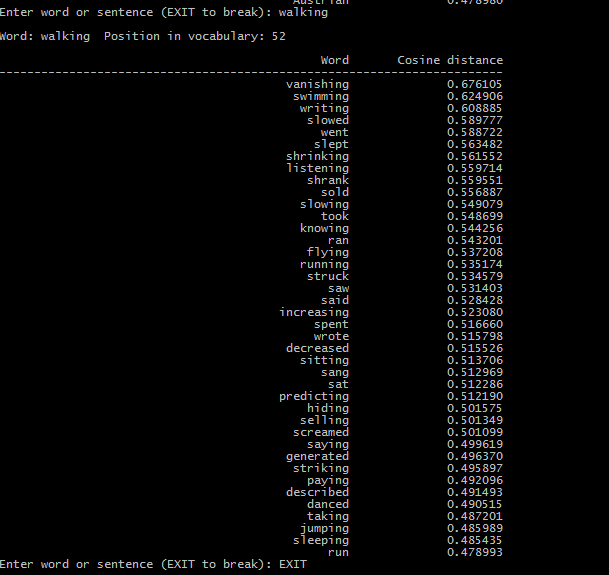
但中文文本下相似距离计算出现下面的结果:
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









