






目录
前言
首先我们应该思考一下,选取合适的索引应该有什么标准。
MySQL是将数据保存到磁盘上的,也就是说我们想要通过索引查找某行数据的时候,要先从磁盘读索引到内存,再通过索引从磁盘找到数据读到内存,整个过程会涉及到多次的磁盘I/O,又因为磁盘I/O次数越多,消耗的时间就越多,所以我们希望所选的数据结构能够尽量减少磁盘I/O的次数。
另外,MySQL也是支持范围查询的,这又要求数据结构还能高效地进行范围查找。
综上,我们选取的数据结构应该满足:
- 能尽量用少的磁盘I/O完成数据查询。
- 不仅能查询某一个记录,还能高效地进行范围查找。
下面,我们就对比几个树型结构,体会一下为什么B+树是MySQL的最佳选择。
一、二叉搜索树
为什么第一个考虑的就是一棵树而不是其他的数据结构呢,因为它能解决连续插入新元素开销大的问题,所以我们对比的都是树型结构。
而二叉搜索树呢,因为它的特性(一个节点的左子树的所有节点都小于这个节点,右子树的所有节点都大于这个节点),所以它查找数据时是相当于二分查找,能节省查找时间。
但是,二叉树最终的检索效率,其实是取决于数据的分布情况。如果数据分布均匀,还是能提高一定的查询效率的;数据如果分布不均匀,用二叉树来做索引的话,还是存在着一定的不足性。
比如,当我们每次新插入的元素都是二叉树中最大的元素,那么它就会退化成一条链表,就不具备二分的效果了。而且,每访问一个节点,就涉及一次磁盘I/O,也就是说树的层数越高,代表磁盘I/O次数(最大值)越多,这种情况下,二叉搜索树不满足我们的两个条件,不适合作为数据库的索引结构。
二、平衡二叉树
平衡二叉树(Balanced Binary Tree),它具有以下性质:它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
平衡二叉树的常用算法有红黑树、AVL、Treap、伸展树、SBT等。
它解决了二叉搜索树会退化成链表的问题,那么它为什么没能作为索引结构呢?
是因为它还存在一些问题:
1.太深了:二叉树每个节点只能保存两个子节点,数据量增多,二叉树的高度也随之变多,这就会导致磁盘I/O的次数也变多,会影响整体的查询效率,举个例子,如果是多叉树,每一层放的节点数量多变多了,那同样的数据量,树的高度变小了,效率就高了。
2.太小了:通过N多次 I/O 操作后,拿到的数据太少了
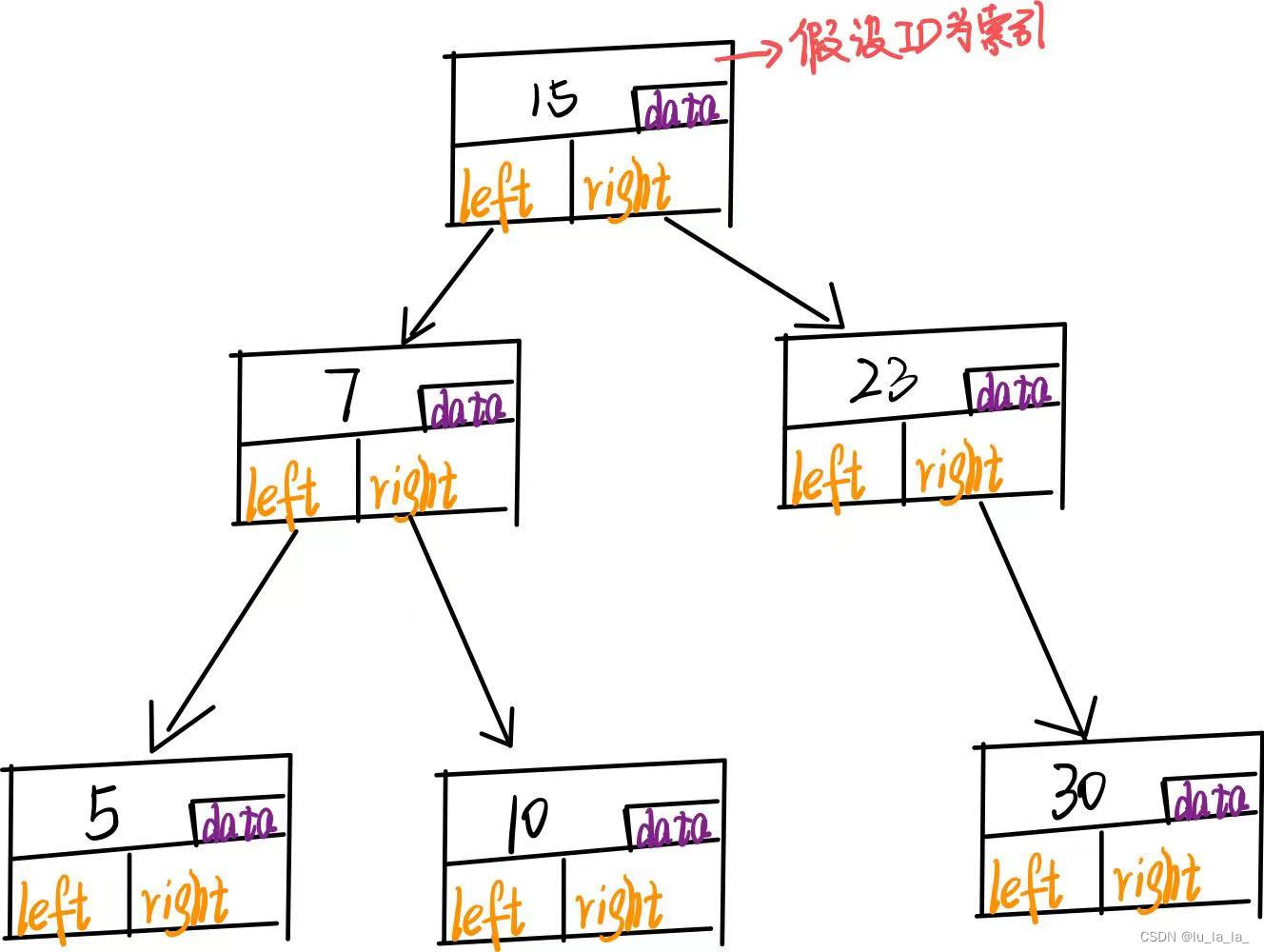
一个节点的结构可参考下图,其中,data指向真正数据存储的磁盘位置(内存地址),通过数据区去加载数据。一般情况下,为了节省空间,数据区是不会保存数据的,而是指向磁盘的一个位置,然后去磁盘把内容加载过来,达到快速检索的目的。
I/O操作是以页为单位,交换一次,大约是4K的数据,而一个节点中除了数据还要保存关键字,子节点引用,再去掉用不到的数据,一次I/O操作获得的有效信息太少了。
(手画的有点丑,不要介意)
这种结构也没有很好的利用预读能力, 操作系统在IO操作时,比如说要读 2M txt 文件。先把头部 4k 读回来后,它会认为你马上就会使用接下来的 4k 数据,会提前加载好,所以真正交换数据时,交换的不是4k,是更多的数据。
三、B树
B树本质是多叉树,不再限制一个节点就只能有 2 个子节点,而是允许 M 个子节点 (M>2),从而降低树的高度。
假设我们把B树定成1000路,高度为3时,能存放的数据量特别多,远远高于平衡二叉树(才7个节点),也可以理解成平衡二叉树时高瘦的,B树时矮胖的,所以B树这种多路平衡树远好于平衡二叉树。
但是B树也存在不足:
- B 树的每个节点都包含数据,这意味着在读取节点时可能会读取到不必要的数据,增加了磁盘 I/O 开销。
- 如果使用 B 树来做范围查询的话,需要使用中序遍历,这会涉及多个节点的磁盘 I/O 问题,从而导致整体速度下降。
那有没有更完美的结构了呢?
主角登场!
四、B+树
B+Tree 是 B-Tree 的变种,多路绝对平衡查找树,它拥有 B-Tree 的优势;
也有优于B树的地方:
1.扫库、扫表能力更强:B-Tree 扫库扫表,会扫每一个枝节点,最后再扫子节点,基本都得扫一遍。B+Tree,只扫子节点即可。
2.磁盘读写能力更强:B+树非叶子节点不存放数据,相比于B树的非叶子节点来说,所占内存小。磁盘IO的大小是固定的,节点越小,一次IO所能读取到的节点数量就越多。因此B+树单次磁盘IO效率高于B树。
3.查询效率更加稳定:
B树相当于对关键字二分查找,范围是1~logmN,距离根节点越近效率越高,涉及到跨层查找,所以在查询时可能需要多次磁盘访问,导致查询性能较低。
B+树:都是logmN,因为数据都在叶子节点上,而且通过叶子节点形成的链表可以快速定位到范围查询的起始位置,提高了查询性能。
4.B+树更适用于MySQL索引这种范围查询和顺序访问的场景















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









