







目 录
一、概述
1.说明
- 存储过程即过程化 SQL 语言,是在普通 SQL 语句上增加了编程语言的特点,将 DML 和 DQL 组织在过程化代码中,通过逻辑判断、循环等实现复杂计算的程序语言;
- 存储过程有自己的变量、条件判断、循环语句等,一个存储过程中,可以将多条 SQL 语句以逻辑代码的方式将其串联,所以一个存储过程可以看作是为了完成特定任务的 SQL 语句集合;
- 每一个存储过程就是一个数据库对象,和 table、view一样存储在数据库当中,一次编译永久有效。每个存储过程都有自己的名称,可以通过存储过程的名称调用;
- 在数据量庞大的情况下,利用存储过程可以提升效率;
- 实际开发中,只有在需要进行性能优化时考虑使用。
2.优点
速度快。降低了应用服务器和数据库服务器之间的网络通讯开销。
3.缺点
移植性差、编写难度大、维护性差。每一个数据库管理系统都有独特的存储过程语法规则,一旦使用了存储过程,较难更换数据库产品。且对于数据库存储过程语法,没有专业的 IDE,编码效率较低,维护成本较高。
二、存储过程的操作
# 为了演示存储过程的一系列操作,首先初始化
drop table if exists human;
create table human(
id int not null auto_increment,
name varchar(10),
gender char(2) default '未知',
age int,
phone varchar(20),
primary key (id)
);
insert into human(name, gender, age, phone) values
('王磊', '男', 18, '13328345217'),
('刘颖', '女', 23, '17728589999'),
('周子恩', '女', 21, '11253467846');在 dos 命令窗口下,MySQL 遇到【;】将结束输入, 所以在创建存储过程时会报错。
此时,需要使用【delimiter <符号>】更改结束符。为方便操作,以下操作均在 Navicat 里进行。
1.创建
create procedure p()
begin
select name, age, gender, phone from human;
end;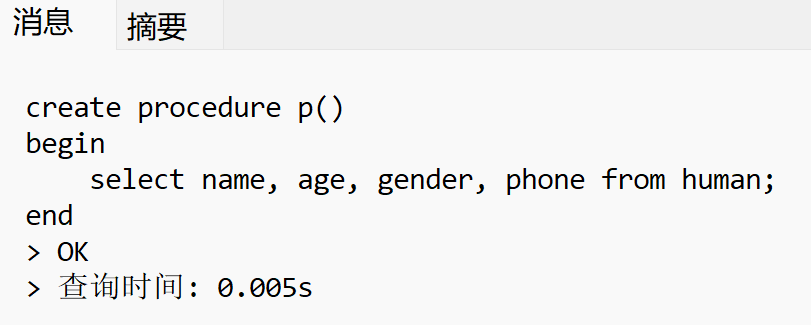
2.调用
call p();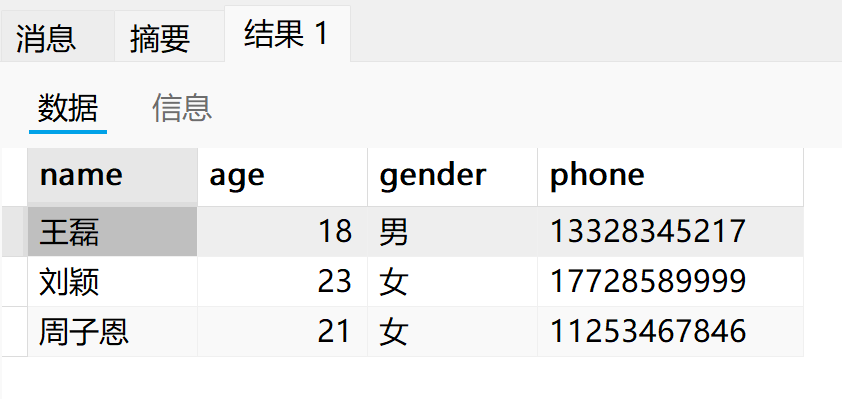
3.查看
- 系统表 information_schema.routines 存储了存储过程、函数对象、触发器对象等状态信息;
- SPECIFIC_NAME:存储过程的具体名称,包括名称和参数列表;
- ROUTINE_SCHEMA:存储过程所在的数据库名称;
- ROUTINE_NAME:存储过程名称;
- ROUTINE_TYPE:PROCEDURE 表示存储过程,FUNCTION 表示一个函数;
- ROUTINE_DEFINITION:存储过程定义语言;
- CREATED:存储过程创建时间;
- LAST_ALTERED:存储过程最后修改时间;
- DATA_TYPE:存储过程返回值类型、参数类型等。
select
SPECIFIC_NAME, ROUTINE_SCHEMA, ROUTINE_NAME,
ROUTINE_TYPE, ROUTINE_DEFINITION, CREATED,
LAST_ALTERED, DATA_TYPE
from
information_schema.ROUTINES
where
ROUTINE_NAME = 'p';
4.删除
drop procedure if exists p;
三、变量
1.系统变量
(1)说明
- MySQL 系统变量是 MySQL 服务器运行时控制行为的参数,可以被设置为特定值从而改变服务器的默认设置;
- 系统变量有全局作用域和会话作用域。全局作用域对所有连接和所有数据库都适用,会话作用域只对当前连接和当前数据库适用。
(2)查看系统变量
- 语法格式:
- 【show [ global | session ] variables;】;
- 【show [ global | session ] variables like ' ';】;
- 【select @@[ global | session ].系统变量名;】。
- 未指定 global 和 session 时,默认是 session。
(3)设置系统变量
- 语法格式:
- 【set [ global | session ] 系统变量名 = 值;】;
- 【set @@[ global | session ].系统变量名 = 值;】。
- 无论是全局设置还是会话设置,MySQL 服务器重启之后,之前的配置都会失效。可以通过修改 MySQL 安装根目录下的 my.ini 配置文件实现永久修改;
- my.ini 默认不存在,需要新建。在 Windows 系统下,文件后缀是【.ini】,在 Linux 系统下,文件后缀是【.cnf】。
2.用户变量
(1)说明
- 用户自定义的变量;
- 只对当前会话有效;
- 所有用户变量以【@】开始。
(2)用户变量赋值
- 语法格式:
- 【set @用户变量名 = 值;】;
- 【set @用户变量名 := 值;】(推荐使用“:”形式);
- 【set @用户变量名 := 值, @用户变量名 := 值;】;
- 【select @用户变量名 := 值;】;
- 【select 字段名 into @用户变量名 from 表名 where 条件;】。
- MySQL 中用户变量无需声明,可直接赋值。若未声明直接读取,则返回 NULL。
set @id = 1;
set @`name` := '张鹏';
set @age := 23;
set @gender = '男', @phone = '13325678910';(3)读取用户变量
语法格式:【select @变量名1, @变量名2, …;】。
select @id, @`name`, @age, @gender, @phone;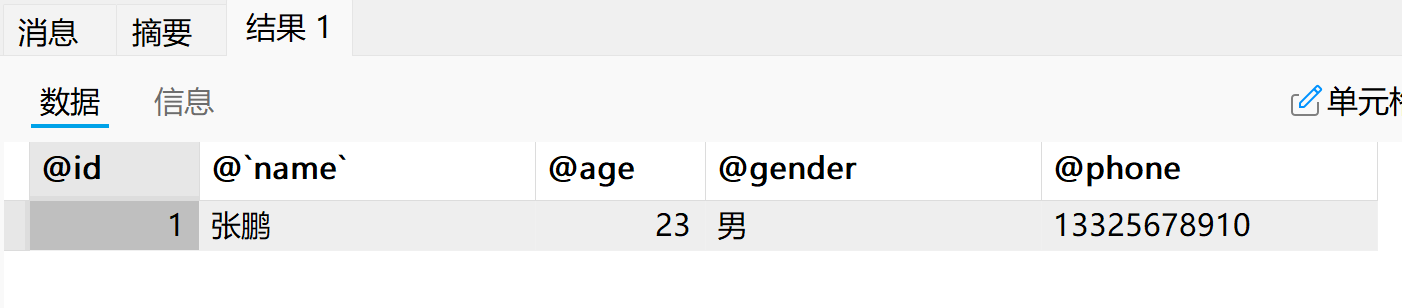
3.局部变量
(1)说明
- 存储过程可以使用局部变量,使用【declare】声明,在 begin 和 end 之间有效;
- 局部变量只在存储过程中有效。
(2)声明、赋值、读取与调用
- 语法格式:【declare 变量名 数据类型 [default …];】;
- declare 通常出现在 begin 和 end 之间。
drop procedure if exists p1;
create procedure p1()
begin
-- 1.声明
declare name varchar(10) default '佚名';
declare age int default 0;
-- 2.赋值
set name := '徐佳禾';
set age := 22;
-- 3.读取
select name, age;
end;
-- 4.调用
call p1();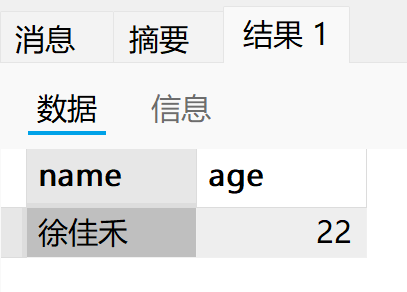
四、IF
1.语法格式
if [条件1] then [分支1]
elseif [条件2] then [分支2]
elseif [条件3] then [分支3]
else [分支4]
end if;
2.实例
员工月薪高于 10000 属于“高收入”,6000 ~ 10000 属于中收入,低于 6000 属于低收入。查询员工薪资收入级别。
drop procedure if exists p2;
create procedure p2()
begin
-- 声明一个局部变量,存储月薪
declare sal int default 0;
-- 声明一个局部变量,存储薪资等级
declare gra varchar(3);
-- 赋值月薪
set sal := 6000;
if
sal > 10000
then
set gra := '高收入';
elseif
sal between 6000 and 10000
then
set gra := '中收入';
else
set gra := '低收入';
end if;
select gra;
end;
call p2();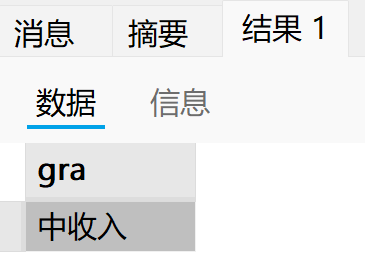
五、参数
1.三种类型
- in:入参,接收调用者传入数据。未指定时默认为 in;
- out:出参,保存存储过程执行结果;
- inout:即是入参也是出餐。
2.in、out 实例
上方使用 if 语句判断薪资等级,每次修改月薪需要在存储过程中进行,如此不利于维护。可以使用参数改进。
drop procedure if exists p3;
create procedure p3(in sal int, out gra varchar(3))
begin
if
sal > 10000
then
set gra := '高收入';
elseif
sal < 6000
then
set gra := '低收入';
else
set gra := '中收入';
end if;
end;
call p3(10001, @grade);
select @grade;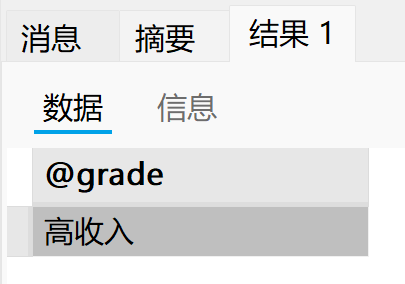
3.inout 实例
将传入的薪资上调 10%。
drop procedure if exists p4;
create procedure p4(inout sal int)
begin
set sal := sal * 1.1;
end;
set @sal := 100;
call p4(@sal);
select @sal;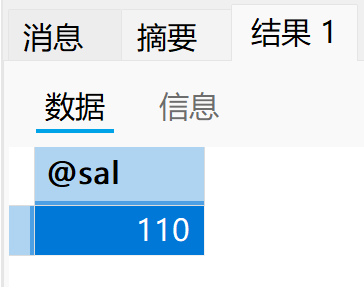
六、CASE
1.语法格式1
case 匹配条件
when [值1] then [处理1]
when [值2] then [处理2]
else [处理3]
end case;
2.语法格式2
case
when [条件1] then [处理1]
when [条件1] then [处理1]
else [处理3]
end case;
3.实例
3、4、5 月为春季,6、7、8 月为夏季,9,10,11 月为秋季,12,1,2 月为冬季。根据月份输出季节,其他输入为非法输入。
-- 语法1
drop procedure if exists p5;
create procedure p5(in month int, out result char(2))
begin
case month
when 3 then set result := '春季';
when 4 then set result := '春季';
when 5 then set result := '春季';
when 6 then set result := '夏季';
when 7 then set result := '夏季';
when 8 then set result := '夏季';
when 9 then set result := '秋季';
when 10 then set result := '秋季';
when 11 then set result := '秋季';
when 12 then set result := '冬季';
when 1 then set result := '冬季';
when 2 then set result := '冬季';
else set result := '非法';
end case;
end;
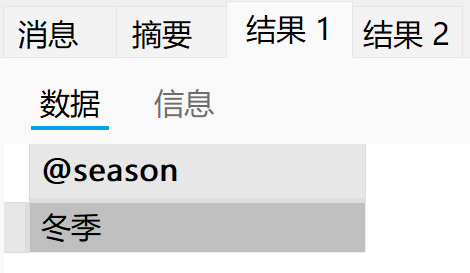
call p5(1, @season);
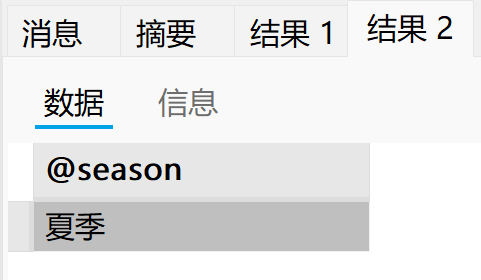
select @season;
-- 语法2
drop procedure if exists p6;
create procedure p6(in month int, out result char(2))
begin
case
when month between 3 and 5 then set result := '春季';
when month between 6 and 8 then set result := '夏季';
when month between 9 and 11 then set result := '秋季';
when month = 12 or month between 1 and 2 then set result := '冬季';
else set result := '非法';
end case;
end;
call p6(6, @season);
select @season;
七、循环
1.WHILE 循环
(1)语法格式
while [条件] do
-- 循环体
end while;
(2)实例
传入整数 n,计算 1 ~ n 中所有偶数和。
drop procedure if exists p7;
create procedure p7(in n int)
begin
declare sum int default 0;
while
n > 0
do
if n % 2 = 0
then set sum := sum + n;
end if;
set n := n - 1;
end while;
select sum;
end;
call p7(10);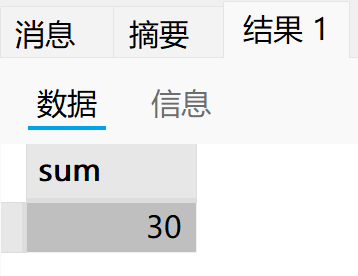
2.REPEAT 循环
(1)语法格式
repeat
-- 循环体
until 条件
end repeat;
(2)实例
传入整数 n,计算 1 ~ n 中所有偶数和。
drop procedure if exists p8;
create procedure p8(in n int)
begin
declare sum int default 0;
repeat
if n % 2 = 0
then set sum := sum + n;
end if;
set n := n - 1;
until n <= 0
end repeat;
select sum;
end;
call p8(10);
3. LOOP 循环
(1)语法格式
循环名:loop
-- 循环体
[ leave \ iterate ] 循环名;
end loop;
# leave:类似于 Java 中的 break,结束当前循环;
# iterate:类似于 Java 中的 continue,结束本次循环。
(2)leave 实例
输出 1 ~ 6。
drop procedure if exists p9;
create procedure p9()
begin
declare i int default 0;
num:loop
set i := i + 1;
if i = 7
then leave num;
end if;
select i;
end loop;
end;
call p9();
(3)iterate 实例
输出 1、2、3、4、6、7、8、9。
drop procedure if exists p10;
create procedure p10()
begin
declare i int default 0;
num:loop
set i := i + 1;
if i = 11
then leave num;
elseif i = 5
then iterate num;
elseif i = 10
then iterate num;
end if;
select i;
end loop;
end;
call p10();
八、游标 cursor
1.说明
- 游标是指向结果集中某条记录的指针,允许程序逐个访问结果集中的每条记录,并进行逐行操作;
- 使用游标需要在存储过程或函数中定义一个游标变量,并通过【declare】进行声明和初始化;
- 使用【open】开启游标;
- 使用【fetch】逐行获取游标指向的记录并处理;
- 最后使用【close】关闭游标,释放资源;
- 声明游标的语句必须在声明普通变量的下方。
2.步骤
(1)声明
declare 游标名称 cursor for 查询语句;
(2)开启
open 游标名称;
(3)获取
fetch 游标名称 into 变量1, 变量2, …;
(4)关闭
close 游标名称;
3.实例
从 二 中的 human 表中查询 name 和 gender,并插入一张新表 human_summary。
drop procedure if exists p11;
create procedure p11()
begin
-- 声明变量
declare human_name varchar(10);
declare human_gender char(2);
-- 声明游标
declare human_cursor cursor for
select `name`, gender from human;
-- 新建 human_summary 表
drop table if exists human_summary;
create table human_summary(
id int primary key auto_increment,
`name` varchar(10),
gender char(2) default '未知'
);
-- 开启游标
open human_cursor;
-- 循环获取数据
while true do
fetch human_cursor into human_name, human_gender;
-- 插入数据
insert into human_summary(`name`, gender) values(human_name, human_gender);
end while;
-- 关闭游标
close human_cursor;
end;
call p11();
九、捕捉并处理异常
1.说明
- 语法格式:【declare [ 异常处理程序名 ] handler for [ SQL状态码 ] [ 执行语句 ];】;
- 异常处理程序:
- continue:发生异常后,程序不终止,正常执行后续过程。即捕捉;
- exit:发生异常后,终止存储过程的执行。即上抛。
- SQL 状态码:
- 可以填具体的数字状态码;
- SQLWARNING:代表所有 01 开始的 SQL 状态码;
- NOT FOUND:代表所有 02 开始的 SQL 状态码;
- SQLEXCEPTION:代表所有除 01、02 开始的 SQL 状态码。
- 执行语句:异常发生时执行的语句。
2.实例
上述游标中的实例,执行时会报错,因为循环是死循环。
那么,如何改进呢?

drop procedure if exists p11;
create procedure p11()
begin
declare human_name varchar(10);
declare human_gender char(2);
declare human_cursor cursor for
select `name`, gender from human;
-- 异常处理,在发生未发现异常时终止并关闭游标
declare exit handler for not found close human_cursor;
drop table if exists human_summary;
create table human_summary(
id int primary key auto_increment,
`name` varchar(10),
gender char(2) default '未知'
);
open human_cursor;
while true do
fetch human_cursor into human_name, human_gender;
insert into human_summary(`name`, gender) values(human_name, human_gender);
end while;
close human_cursor;
end;
call p11();十、存储函数
1.说明
- 存储函数是带有返回值的存储过程;
- 参数只能是 in,但不能显示地写 in。没有 out 和 inout。
2.语法格式
create function 存储函数名称(参数列表) returns 数据类型 [ 特征 ]
begin
-- 函数体
return …;
end;
# 特征重要取值:
- deterministic:标记该函数为确定性函数,即每次调用函数时,传入相同的参数,返回值是固定的。这是一种优化策略,此情况下全部函数体的执行会省略,直接返回之前缓存的结果,提高函数的执行效率;
- no sql:标记该函数执行过程不会查询数据库,以向 MySQL 优化器表示不需要使用查询缓存和优化器缓存优化。避免不必要的查询消耗;
- reads sql data:标记该函数会进行查询操作,以向 MySQL 优化器表示该函数需要查询数据库,可以使用查询缓存优化。同时 MySQL 还会进行优化器缓存处理。
3.实例
传入整数 n,计算 1 ~ n 中所有偶数和。
drop function if exists f;
create function f(n int) returns int deterministic
begin
declare sum int default 0;
while n > 0 do
if n % 2 = 0
then set sum := sum + n;
end if;
set n := n - 1;
end while;
return sum;
end;
set @result := f(10);
select @result;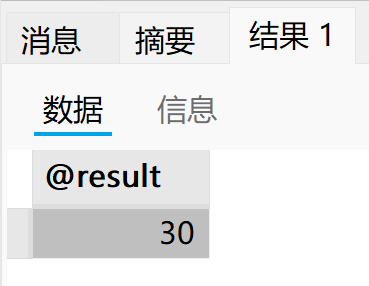
十一、触发器
1.说明
MySQL 触发器是一种数据库对象, 是与表相关联的特殊程序;
可以在 插入、更新、删除 触发时自动执行;
作用:
强制实施业务规则:可以确保表中业务规则强制执行;
数据审计:可以声明在执行数据修改时自动记录日志或审计数据变化的操作;
执行特定业务操作:可以自动执行特定业务操作。
分类:
before:在执行 insert、update、delete 语句之前执行;
after:在执行 insert、update、delete 语句之后执行。
触发器是一种数据库高级功能,只在必要条件下使用。过量的触发器和复杂的触发器逻辑可能会影响查询性能和扩展性。
2.语法规则
create trigger 触发器名称 [ before \ after ] [ insert \ update \ delete ] on 表名 for each row
begin
-- 触发器执行的 SQL 语句
end;
3.关键字 new、old
- new 和 old 是两个特殊的关键字,用于引用在触发器中修改前后的旧值、新值。
- new:触发 insert 或 update 操作期间,new 用于引用将要插入或更新到表中新行的值;
- old:出发 update 和 delete 操作期间,old 用于引用更新或删除之前在表中旧行的值。
- 可以像引用其他列一样引用 new 和 old。
4.实例
# 1.首先,初始化一个日志表 log
drop table if exists log;
create table log(
id bigint primary key auto_increment,
table_name varchar(255) not null,
operate varchar(10) not null,
time datetime not null,
operate_id bigint not null,
description text
);# 2.向 human 表插入的触发器
drop trigger if exists trigger_human_insert;
create trigger trigger_human_insert after insert on human for each row
begin
insert into log(table_name, operate, time, operate_id, description) values
('human', '新增', now(), new.id, concat('插入:id = ', new.id, ',name = ', new.name, ',gender = ', new.gender, ',age = ', new.age, ',phone = ', new.phone));
end;
-- 查询 log 日志表
select * from log;
-- 向 human 表插入一条新数据
insert into human values(null, '柳梓熙', '女', '24', '18333256677');
-- 查询 log 日志表
select * from log;
# 3.向 human 表更新的触发器
drop trigger if exists trigger_human_update;
create trigger trigger_human_update after update on human for each row
begin
insert into log values(null, 'human', '更新', now(), new.id, concat('更新:[原数据:name = ', old.name, ',gender = ', old.gender, ',age = ', old.age, ',phone = ', old.phone, '];[新数据:name = ', new.name, ',gender = ', new.gender, ',age = ', new.age, ',phone = ', new.phone, ']'));
end;
-- 查询 log 日志表
select * from log;
-- 向 human 表修改一条新数据
update human set name = '刘梓琪' where id = 4;
-- 查询 log 日志表
select * from log;# 4.向 human 表删除的触发器
drop trigger if exists trigger_human_delete;
create trigger trigger_human_delete after delete on human for each row
begin
insert into log values(null, 'human', '删除', now(), old.id, concat('删除:name = ', old.name, ',gender = ', old.gender, ',age = ', old.age, ',phone = ', old.phone));
end;
-- 查询 log 日志表
select * from log;
-- 向 human 表删除一条新数据
delete from human where name = '刘梓琪';
-- 查询 log 日志表
select * from log;

















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









