







Hadoop版本:hadoop-1.2.1-bin.tar
Jdk版本:jdk-6u30-linux-i586
需要的软件:VMWare 9,ubuntu10.04
首先安装vmware9,然后在其中利用ubuntu的镜像安装3个虚拟机,具体方法可以搜到
在每个虚拟机中,执行以下操作:
(1)创建hadoop用户组:sudo addgroup hadoop
(2)创建hadoo用户:sudo adduser -ingroup hadoop hadoop
(3)给hadoop用户增加权限:sudo gedit /etc/sudoers ,在root ALL =(ALL:ALL) ALL 下面添加如下
hadoop ALL = (ALL:ALL) ALL
(4)安装JDK,具体过程如下:
1.下载jdk
2.在/usr/local下创建一个java文件夹
3.将jdk文件拷贝到/usr/local/java中
4.切换到root
5.运行jdk-6u30-linux-i586.bin
6.这时候在java文件夹中多了一个jdk1.6.0_30文件
7.修改配置文件,在文件~/.bashrc最后添加
export JAVA_HOME=/usr/local/java/jdk1.6.0_30
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
8.测试jdk是不是安装成功:$java ,如果能正确的输出其版本就代表其安装成功
(5)修改本机的host文件
sudo gedit /etc/hosts
在其中加入:
192.168.15.129 master
192.168.15.130 son-1
192.168.15.131 son-2
(6)修改本机(master)和子节点(son-1...)机器名
sudo gedit /etc/hostname
分别改成master,son-1,son-2
(7)为本机(master)和子节点安装ssh服务
sudo apt-get install openssh-server
(8)先建立ssh无密码登陆环境
切换到hadoop用户
创建ssh-key,采用rsa的方式:ssh-keygen -t rsa -P “”
(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的)
进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的:
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
(9)为本机master安装hadoop
1.将hadoop-6u30.tar.gz 文件复制到/usr/local下
2.解压文件 sudo tar -zxf hadoop-6u30.tar.gz hadoop
3.将该hadoop文件夹的属主用户设为hadoop:
sudo chown -R hadoop:hadoop hadoop
4.打开hadoop/conf/hadoop-env.sh文件
sudo gedit hadoop/conf/hadoop-env.sh
5.修改JAVA_HOME路径,这里的路径是
export JAVA_HOME=/usr/local/java/jdk-XXX
6.打开conf/core-site.xml文件,编辑如下:

7.打开conf/mapred-site.xml文件,编辑如下:

8.打开conf/hdfs-site.xml,编辑如下:
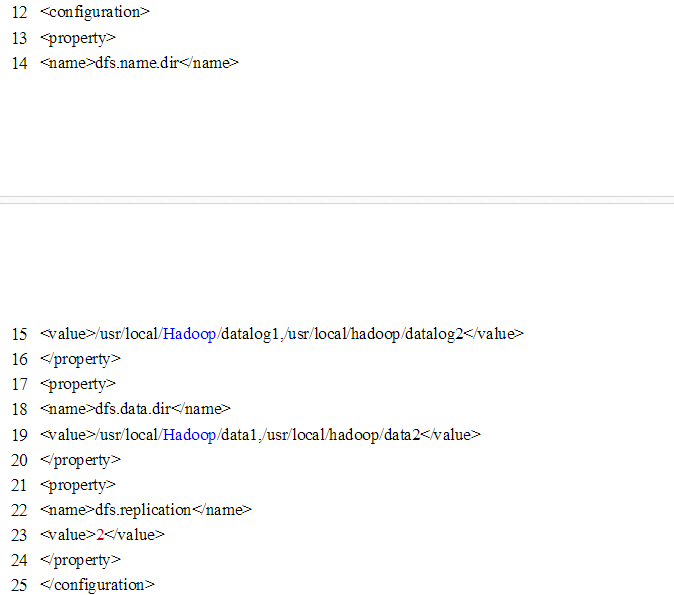
(10)打开conf/masters:
sudo gedit hadoop/conf/masters
在其中添加master
(11)打开conf/slaves文件,添加作为slave的主机名,一行一个:
sudo gedithadoop/conf/slaves
在其中添加:
son-1
son-2
然后进入hadoop目录,格式化文件系统
bin/hadoop namenode -format
(12) 将master机器上的文件一一复制到datanode机器上(son-1,son-2)
都要复制
1.公钥的复制
先要在son-1和son-2 hadoop目录下建立.ssh目录,不然无法复制
scp ~/.ssh/id_rsa.pub hadoop!son-1:~/.ssh/
2.hosts文件的复制
scp /etc/hosts hadoop@son-1;/etc/hosts
注意:这里可能会出现权限的问题,可以先将先将文件复制到/home/hadoop下面,再到son-1和son-2机器上面用root用户将hosts文件写到/etc/hosts下
3.hadoop文件夹的复制
scp -r /usr/lcoal/hadoop hadoop!@son-1:/usr/local
如果出现权限问题方法和上一步一样。
4.将所有节点的hadoop目录的权限进行如下修改:(注意在son-1,son-2的/usr/local路径中进行): sudo chown -R hadoop:hadoop hadoop
5.这些东西都复制完了之后,datanode机器还要将复制过来的公钥追加到收信任列表:在每个子节点的自己种都要操作: cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
还有很重要的一点,子节点datanode机器要把复制过来的hadoop里面的data1,data2和logs删除掉!
13 )运行hadoop,首先进入master的hadoop目录
cd /usr/local/hadoop
启动datanode和tasktracker:
1 bin/start-dfs.sh
2 bin/hadoop-daemon.sh start datanode
3 bin/hadoop-daemon.sh start tasktracker
启动全部服务直接一条指令:
bin/starr-all.sh
查看自己的datanode是不是已经启动
Jsp
关闭全部服务指令:
bin/stop-all.sh
参考资料:
单节点的安装
Jdk安装:
http://www.linuxidc.com/Linux/2012-06/62078p2.htm
集群安装:
http://blog.csdn.net/zhangheng1225/article/details/8246788
错误总结:
http://www.linuxidc.com/Linux/2012-08/67395.htm















 5778
5778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









