







算法老师留了三个作业给我们。额,因为他的题目写在黑板上,不能Copy,所以没抄了。不过,按照我意思的理解。他出的题目就是我这篇文章的题目吧。嗯嗯,根据老师的题目,我还是把题目意思写过来。
题目1 全排列
Description
输入正整数n,按字典序从小到大的顺序输出1~n的所有排列。
Input
输入一个正整数n(1<=n<=20)。
Output
输出前n个数的所有序列,序列之间的数字用空格隔开,每个序列占一行。
Sample Input
3
Sample Output
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
题目2 不重复排列
Description
按字典序从小到大不重复的顺序输出n个数的所有排列。
Input
输入的第一行是一个正整数n(1<=n<=20),表示整数的个数。第二行有n个整数,用空格隔开。
Output
输出n个数的所有不重复序列,序列之间的数字用空格隔开,每个序列占一行。
Sample Input
3
8 -8 8
Sample Output
-8 8 8
8 -8 8
8 8 -8
题目3 枚举子集
Description
从集合{1,2,3,...,n}中选取k个数所组成的所有集和。
Input
输入的两个正整数。第一个数为n(1<=n<=20),第二个数为k,(k<=n),两个数之间用空格隔开。
Output
输出含有k个数的所有不相同的集合,输出集合的序列按照字典序输出,每个集合占一行,集合的相邻两个数字用空格隔开。
Sample Input
3 2
Sample Output
1 2
1 3
2 3
嗯嗯,题目意思描述可能和老师描述的有点差异。请结合Sample Input和Sample Output应该就能看懂了。在这篇博文中,老师的题目只是作为引子,可能到最后我不会把这三个题目用Code实现,但我会逐渐把我理解的关于怎样生成全排列和怎样生成子集的知识讲出来。OK,就开始我的全排列和子集生成之旅吧。
===================================我是无奈的分割线===================================
第一次接触全排列是是我大二时候参加ACM的暑假选拔赛遇到的。那个时候我是使用STL中的next_permutation交的。不过很不幸的是TLE(Time Limit Exceeded)了。不是因为next_permutation的效率而TLE,而是我那个时候自以为是的在输入n前加了一个while(true),所以理所当然TLE了。呵呵,偶提这个东西只是想让你们知道,有很多的基本算法都在STL里面实现了。当然,有可能有的同学还不晓得STL为何物,那你就先把她当成是一位PLMM吧。
好的,首先,我要介绍的是使用递归的思想来实现全排列。我们看测试样例的输出就可以看出,在生成全排列的时候,以1开头的的序列,首先输出1,然后输出2~n的序列。而你把1开始的序列的前面的1去掉,则变成了2~n的按照字典序输出的序列,把2开始的序列的前面的2去掉……我相信你对递归了解的话,很显然看到这是一个不断递归的过程。按照这个思想,我们只要把递归的过程写出来,找到递归的出口,全排列自然就出来了。按照这个思想,我就写一个伪代码:
额,不要嫌伪代码有点难看,偶觉得只有能让人很容易明白的伪代码才是好伪码。所以,我找女朋友的标准一直是if(有内涵) 追她;我不敢使用if(漂亮||有内涵) 追她;虽然有可能让我追到一个(漂亮&&有内涵)的MM,但也有可能追到一个(漂亮&&!内涵)的MM。当然,你可能会说为什么不把if里面的判断语句改为(有内涵&&漂亮)呢?额,我没那个资本……话说还是来稍微解释一下那个伪代码吧。递归的边界应该很好理解吧,当集合s[]中没有一个元素的时候,按照上面的伪码,s[]中的元素只能向序列a[]中跑,s[]没了元素,那么序列a[]就是一个完整的序列了。那么,直接输出序列a[]即可。按照从小到大的顺序考虑s[]中的每个元素,每次递归的调用以a[]开始。
如果伪码了解了,那么就得用代码实现了。很容易想到序列a[]用数组保存集合s[]中跑过来得数字,而s[]呢?如果要完成老师布置的第一个题目,那么s[]中的元素根本不要保存,因为s[]中的元素往a[]中跑,那么,跑过来得数字就间接的保存在了序列a[]中,只要没在序列a[]中出现过的数字都可以备选。由于C/C++传递数组的时候传递的是数组的首地址,所以,还需要传一个到底填了多少个数,也就是到底填到数组的第几个位置来了,我们把这个参数取名为cur。OK,下面就用代码来实现老师布置的第一个题目吧。
可能有很多同学对于递归的机制完全不理解,其实我一直也不是很理解……C/C++语言函数,调用自己和调用其他函数没有什么区别,都是建立新栈(这就是为什么递归次数太多容易stack overflow),传递参数并修改相应的数据。在函数执行完毕的时候删除栈,处理返回值并修改相应的数据。打个比较简单的比方,如果我想知道CMM是不是喜欢我(LCQ),但我又不能直接问CMM。于是,就有了下面这个过程:
LCQ:AMM,你帮我问下CMM是不是喜欢我;
AMM:BMM,你帮我问下CMM是不是喜欢LCQ;
BMM:CMM,你喜不喜欢LCQ;
CMM:经过我用KMP匹配之后,我的表白中找不到"LCQ"这个子串。
于是,CMM把不喜欢LCQ这个结果给BMM,BMM又把这个结果返回AMM,AMM又把这个不幸的结果告诉LCQ。于是,LCQ终于知道了CMM不喜欢他……这就是一个递归的实例。当然,这个狗屁比方甚是不好,但是递归基本就是这样一个过程,不断的给下一个被递归的函数安排工作。要是你还是没明白递归是啥回事,下面我在word上画了一个当n==3时怎样生成全排列的过程,其中x表示的是未被下一级递归函数不确认的数字。图画的不好,凑合着看吧。
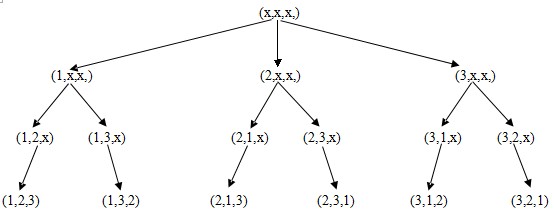
好的,递归生成全排列就到此结束。如果你还是不怎么理解递归,那就用我在网上看到的另外一种方法实现,他的名字叫做字典序生成算法。
字典序生成算法:
设 P 是 1 ~ n 的一个全排列 :p = p1 p2 ...pn = p1 p2 ...pj-1 pj pj+1 ......pk-1 pk pk+1 ...pn
1、从排列的右端开始,找出第一个比右边数字小的数字的序号j ( j 从左端开始计算),即 j = max{i | pi < pi+1 }
2、在pj 的右边的数字中,找出所有比 pj 大的数中最小的数字 pk ,即 k = max{i | pj < pi } 右边的数从右至左是递增的,因此k是所有大于pj的数字中序号最大者)
3、对换pj,pk
4、再将pj+1 ......pk-1 pk pk+1 ...pn 倒转得到排列 p' = p1 p2 ...pj-1 pj pn ......pk+1 pk pk-1 ...pj+1 , 这就是排列p的下一个排列。
例如839647521是数字1~9的一个排列。从它生成下一个排列的步骤如下:
1、自右至左找出排列中第一个比右边数字小的数字4;
2、在该数字后的数字中找出比4大的数中最小的一个5;
3、将5与4交换得到839657421;
4、将7421倒转得到839651247;
5、所以839647521的下一个排列是839651247。
我只是按照这个算法的思想写了一个Code。这个算法的思想我是经过查阅网上的blog得到的。在写这篇blog的过程中,我参考了很多的文章,我现在不一一列举,等写完这篇博客之后,我会把他们的超链接全部放到后面,有些看不懂的东西你们点击超链接去看。比如这个算法为什么这样就能得到下一个全排列,我就不把证明Copy到这个上面了,下面是我按照这个算法写的Code。代码有点繁琐,命名的地方可能有点不规范,请大家凑合看一下,你们自己写代码的时候可以参考一下。
按字典序生成全排列我就不打算再多作介绍了。还有很多生成全排列的算法,http://thankshelen.blog.hexun.com/list.aspx?tag=%d7%e9%ba%cf%ca%fd%d1%a7 。这个网页上就有六种,大家好好去看。接下来我要介绍STL中的next_permutation。
如果说你是一个C++程序设计者,别人问你啥是STL,如果你和我在前面一样说是一位PLMM,那估计就有被别人鄙视的份了。STL:Sandard Template Library,中译曰标准模板库,更准确的说就是是 C++ 程序设计语言标准模板库。我们大二的时候学过MFC吧,MFC是MS创建的 C++ 类库,与之相似的是STL模板库,不过呢,STL是 ANSI/ISO 标准的一部分,而MFC是MS的一个产品……顺便提一下,经常听见有的同学说我要学Visual C++语言,Visual C++只是一个编译器,而不是语言。你要学的其实是MFC。
好的,先去看MSDN关于next_permutation解释:
Reorders the elements in a range so that the original ordering is replaced by the lexicographically next greater permutation if it exists, where the sense of next may be specified with a binary predicate.
template<class BidirectionalIterator>
bool next_permutation(
BidirectionalIterator _First,
BidirectionalIterator _Last
);
template<class BidirectionalIterator, class BinaryPredicate>
bool next_permutation(
BidirectionalIterator _First,
BidirectionalIterator _Last,
BinaryPredicate _Comp
);
Parameters
_First A bidirectional iterator pointing to the position of the first element in the range to be permuted. _Last A bidirectional iterator pointing to the position one past the final element in the range to be permuted. _Comp User-defined predicate function object that defines the comparison criterion to be satisfied by successive elements in the ordering. A binary predicate takes two arguments and returns true when satisfied and false when not satisfied.
Return Value
true if the lexicographically next permutation exists and has replaced the original ordering of the range; otherwise false, in which case the ordering is transformed into the lexicographically smallest permutation.
Remarks
The range referenced must be valid; all pointers must be dereferenceable and within the sequence the last position is reachable from the first by incrementation.
The default binary predicate is less than and the elements in the range must be less than comparable to insure that the next permutation is well defined.
The complexity is linear with at most (_Last – _First)/2 swaps.
额,我是个考了N次连CET6都没过的英语菜鸟,所以你不要奢望我给你把这一大段英语翻译成汉语了。你只要看懂怎样使用 next_permutation 即可,大概的意思就是你传递两个迭代器给 next_permutation。当然,正如 Remarks里面所说,The range referenced must be valid。即你传的迭代器的范围要合理。然后,你看到了有两个重载的对吧,下面一个_Comp意思就是可以按照你的规则来生成下一个全排列。然后看到next_permutation前面的bool了吧,理所当然,他的返回值就是bool。返回true的时候,这个函数生成下一个全排列,返回false的时候,这时候就表明没有下一个全排列了,当然,也有可能你传的迭代器不合理等原因。值得一提的是,STL完全适应可重集,所以,老师提的第二个问题完全可以用STL解决,当然,第一个问题就更不用说了。下面我用STL来演示一下对于这些"lcq", "love", "code", "plmm"字符串按照字典序把他们的全排列输出来。OK,看代码演示:
看到STL的强悍了吧?那就好好去看看STL吧。你有可能会问,这个STL里面的next_permutation到底是怎么实现的啊。不用急,如果你有侯捷的《STL 源码剖析》,请翻开第380页,如果没有,那么请接着往下看:

你看了之后会忍不住骂,这不就是前面的字典排序的思想吗?是的没错,但我还是把侯捷写的源码贴出来了,提醒一下用模板写的代码和自己写的代码之间的差别。建议在使用STL中的算法时,要先明白它到底是怎样实现的,如果你只会使用而不知道它是如何实现的,碰到细节问题你可能就束手无策了。出来混的,迟早是要还的!感叹一下,侯捷写的代码异常简洁高效……这就是大牛和菜鸟之间的差别~~~
既然有next_permutation,那就必有prev_permutation。有兴趣的同学请查找MSDN上或C++参考(http://www.cppreference.com/wiki/cn:start )上关于prev_permutation()的内容。
额,你可能会说,老师的第二个题目你还没做呢,虽然可以用STL中的next_permutation解决,但老师肯定不认。好吧,我用我自己写的第一个递归函数再来解决一下老师提的第二个问题。
显然,当输入重复的数字时,必须用一个数组init[]来保存输入的数字。然后,只要调用noRepeatPermutation(a, init, n, 0)即可。但是,有了重复的数字,由于前面的递归程序禁止a[]数组的数字出现重复,那么你输入3 1 1 1,程序那就什么也不输出了。(本来应该输出1 1 1的)~~~一个解决办法就是统计a[0] ~ a[cur-1] 中 init[i]的出现次数timeA,以及init[]数组中init[i]出现的次数timeInit。只要timeA<timeInit,那你就放心的递归调用吧。代码如下:
好了,代码写好了,那就测试吧。输入 3 1 1 1,很不幸的是,输出了27个1 1 1.遗漏倒是没有了,可又出现了重复……唉,为什么受伤的人总是我呀!仔细看了代码,问题主要出现在这段代码实现试着把第一个1作为开头,递归结束之后又用第二个1作为开头,递归结束之后又用第三个1作为开头……可实际这三个1是相同的,应该只调用一次,而不是三次!我们应该枚举的下标不重复、不遗漏的取遍所有的init[i]的值。由于我先调用qsort把init[]排过序,那么请在noRepeatPermutation函数里面的第二个for循环后面加上这条语句:if( !i || init[i] != init[i-1])。如果你不知道加到哪里,请把我上面的代码中的"//if( !i || init[i] != init[i-1])"这条语句的"//"去掉。
至此,结果终于正确了,老师的前面两个题目也解答完毕!
===================================我是无奈的分割线===================================
嗯嗯,先抛开老师布置的第三个题目不说,一般的。给一个集合{1,2,3,...,n},输出他的所有的子集。
第一种方法就是选出一个元素放到集合中,代码如下:
很显然,递归的边界是集合num[]中没有数的时候。
第二种方法是构造一个位向量B[i],其中当B[i]==1的时候i元素在子集a[]中,B[i]==0时不在子集a[]中。代码如下:
接下来我要重点介绍的一种方法是利用二进制来表示{1,2,3,……,}的子集S:从右往左用一个整数的二进制表示元素i是不是再集合S中。下面演示了用二进制110110100表示集合{7,6,4,3,1}。
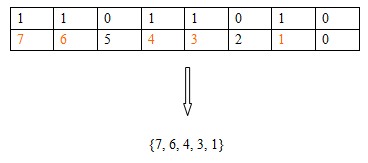
OK,有了这个思想,我们就可以把整数想象为二进制的数,实际上,我们也知道,整数在机器里面都是用0,1表示的,可以这么说,0,1创造了计算机的整个世界。这就是为什么判断一个整数是不是奇数用if(n&1) n为奇数;(奇数用二进制表示末尾一定是1)比用if(1 == n%1) n为奇数;快多了的原因。知道了表示,还要知道怎样操作整数来表示集合,这点发明C语言的人早就为我们想到了。他们分别是&,|, ^.
好了,就看怎样用代码实现吧:
这段代码的效率肯定要比前面两段代码快多了。不过不要得意太早,你输入31试试?代码什么也没输出。这是为什么呢?1~30都能输出他的所有子集,为什么30以后的就不行了……仔细想想int是多少位你就明白了……所以还是应了那句话,出来混的,迟早是要还的,而前面两段代码虽然效率低些,但只要内存足够,原则上是能输出1~UINT_MAX的子集。
好了,该是来解决老师提的问题的时候了。我比较喜欢第三段代码。所以把第三段代码稍微修改一下就能完成老师的所提的问题了。修改后的代码如下:
至此为止,老师的问题全部解答完毕.但这个问题有点遗憾的是子集按照非字典顺序输出的,请同学们思考按照字典顺序输出的方法(其实很简单……)
===================================我是无奈的分割线===================================
如果看了这篇文章后想要了解全排列和子集生成掌握得如何,请思考如下问题:
1、输入一个数组a[],里面有n(1<=n<=1000)个数,给出数组a[]所有数字的一个全排列,求他按照字典排序,这个全排列是所有排列中的第几个。比如a[5] = {1, 1, 4, 5, 8};1 4 1 5 8是该全排列的第8个。
2、如果不晓得对全排列掌握得怎么样,请到POJ上提交你的代码,注意,请不要使用next_permutation();题目的链接为:
http://poj.org/problem?id=1731
http://poj.org/problem?id=1256
http://poj.org/problem?id=1833
http://poj.org/problem?id=1318
http://poj.org/problem?id=1146
如果你能不使用next_permutation()把这5个题目AC,那么,估计以后面试的时候全排列应该没问题。等不用next_permutation()把那五个题目AC之后,再用next_permutation()爽一把吧。
3、如果输入n个数,求着n个数构成的所有子集,不允许输出重复项。如
输入
3
1 1 3
输出
1
1 1
1 1 3
1 3
3
===================================我是无奈的分割线===================================
写本文参考的资料有:
《算法竞赛入门经典》 刘汝佳。
《STL 源码剖析》 侯捷。
《ACM竞赛常用模板》 吉林大学。
写本文参考的网络资料:
http://thankshelen.blog.hexun.com/list.aspx?tag=%d7%e9%ba%cf%ca%fd%d1%a7
http://blog.csdn.net/goal00001111/archive/2008/11/18/3326619.aspx
感谢所有被我参考的书籍和网络资料!














 1398
1398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









