







Spark3.0解决了超过3400个JIRAs,历时一年多,是整个社区集体智慧的成果。Spark SQL和 Spark Cores是其中的核心模块,其余模块如PySpark等模块均是建立在两者之上。Spark3.0新增 了太多的功能,无法一一列举,下图是其中24个相对来说比较重要的新功能,下文将会围绕这些进行简单介绍。

性能相关的新功能主要有:
Adaptive Query Execution 自适应查询
Dynamic Partition Pruning 动态裁剪分区
Query Complication Speedup 复杂查询提速
Join Hints 连接Hints
(一)Adaptive Query Execution
Adaptive Query Execution(AQE)自适应查询,在之前的>2.4版本里已经有所实现,但是之前的框架存在一些缺陷,导致使用不是很多,在Spark3.0中Databricks(Spark初创团队创建的大数据与AI智能公司) 和Intel的工程师合作,采用英特尔® 优化分析包(OAP)解决了相关的问题。
在Spark1.0中所有的Catalyst Optimizer都是基于规则 (rule) RBO优化的。为了产生比较好的查询规则,优化器需要理解数据的特性,于是在Spark2.0中引入了基于代价的优化器 (cost-based optimizer),也就是所谓的CBO。然而,CBO也无法解决很多问题,比如:
数据统计信息普遍缺失,统计信息的收集代价较高;
储存计算分离的架构使得收集到的统计信息可能不再准确;
Spark部署在某一单一的硬件架构上,cost很难被估计;
Spark的UDF(User-defined Function)简单易用,种类繁多,但是对于CBO来说是个黑盒子,无法估计其cost。
总而言之,由于种种限制,Spark的优化器无法产生最好的Plan。也正是因为上诉原因,运行期的 自适应调整就变得相当重要,对于Spark更是如此,于是有了AQE,其基本方法也非常简单易懂。 如下图所示,在执行完部分的查询规划后,Spark可以收集到结果的统计信息,然后利用这些信息再对查询规划重新进行优化。这个优化的过程不是一次性的,而是自适应的,也就是说随着查询规划的执行会不断的进行优化, 而且尽可能地复用了现有优化器的已有优化规则。让整个查询优化变 得更加灵活和自适应。
AQE基本流程:
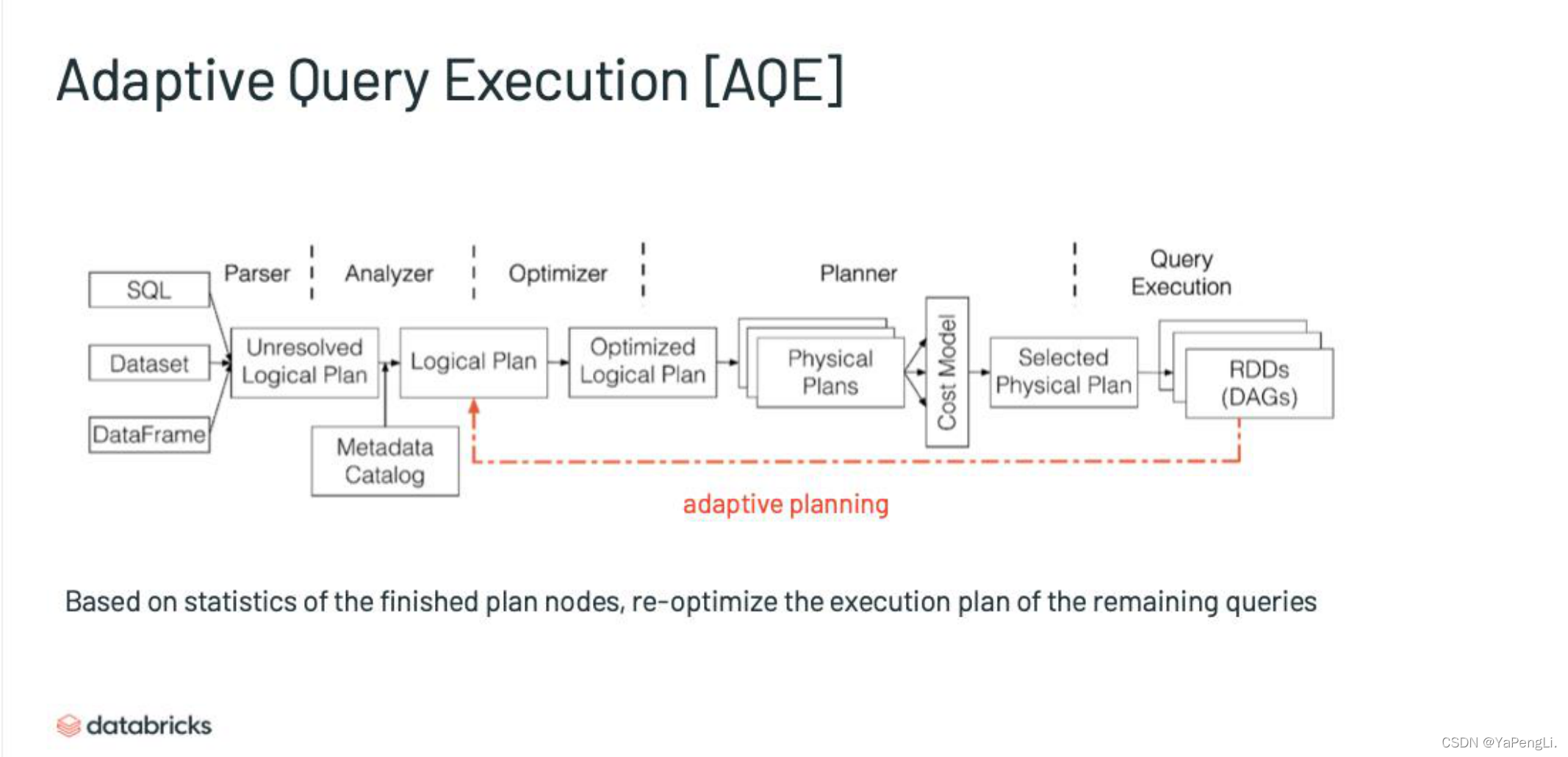
Spark3.0中AQE包括三个主要的运行期自适应功能:
可以基于运行期的统计信息,将Sort Merge Join 转换为Broadcast Hash Join;
可以基于数据运行中间结果的统计信息,减少reducer数量,避免数据在shuffle期间的过量分区导致性能损失;
可以处理数据分布不均导致的skew join。
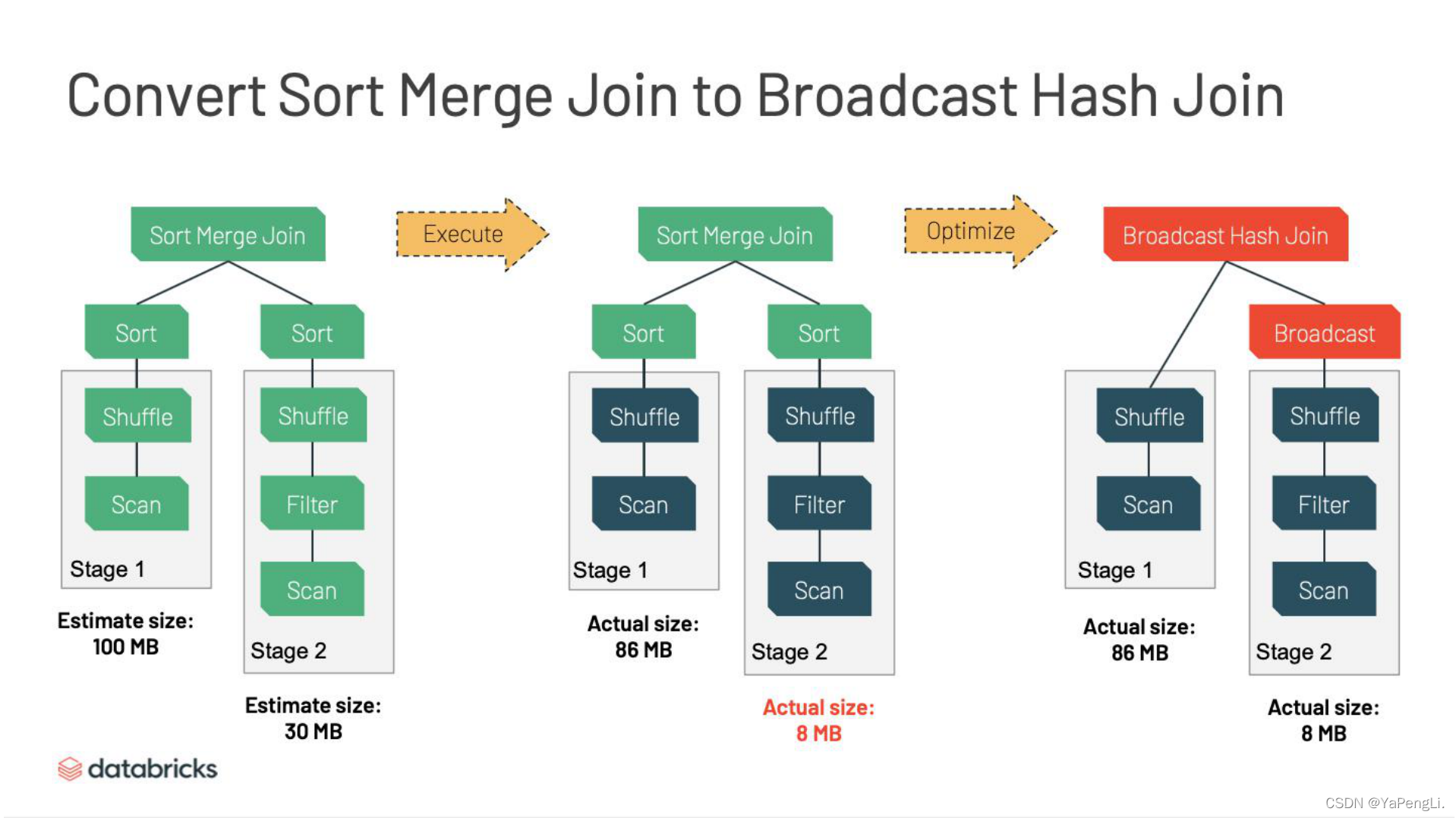
如果你是一个Spark的资深用户,可能你读了很多的调优宝典,其中第一条就是让你的Join变得更 快的方法就是尽可能地使用Broadcast Hash Join。比如你可以增加 spark.sql.autoBroadcastJoinThreshold 阈值,或者使用 broadcast HINT。但是这基本上属于艺高人胆大。首先,这种方法很难调,一不小心就会Out of Memory,甚至性能变得更差,即使现在产生了一定效果,但是随着负载的变化可能调优会完全失败。
也许你会想:Spark为什么不解决这个问题呢?这里有很多挑战,比如:
统计信息的缺失,统计信息的不准确,那么就是默认依据文件大小来预估表的大小,但是文件 往往是压缩的,尤其是列存储格式,比如parquet 和 ORC,而Spark是基于行处理,如果数 据连续重复,file size可能和真实的行存储的真实大小,差别非常之大。这也是为何提高 autoBroadcastJoinThreshold,即使不是太大也可能会导致out of memory;
Filter复杂、UDFs的使用都会使Spark无法准确估计Join输入数据量的大小。当你的query plan异常大和复杂的时候,这点尤其明显。
其中,Spark3.0中基于运行期的统计信息,将Sort Merge Join 转换为Broadcast Hash Join 的过程如下图所示。
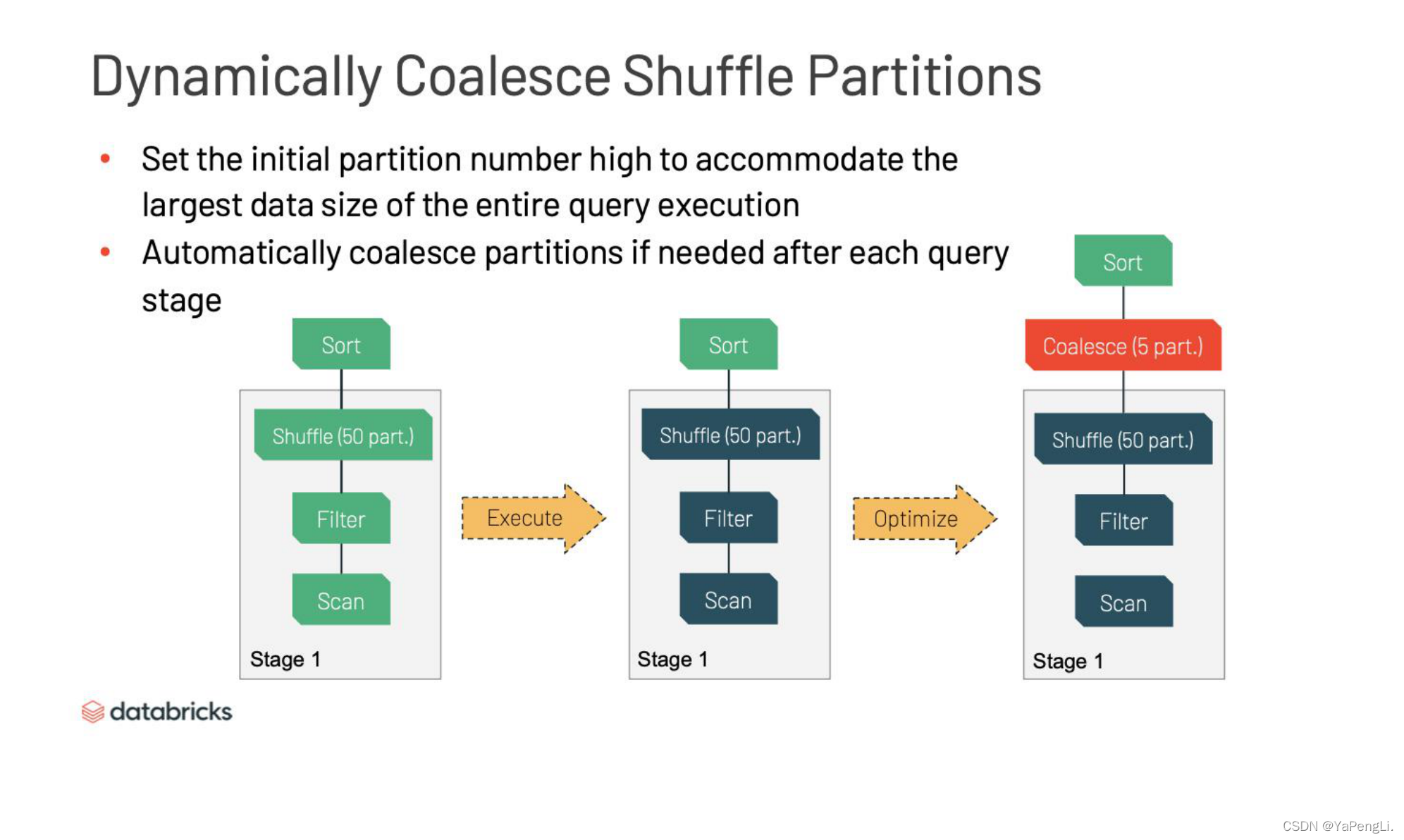
也许你还会看到调优宝典告诉你调整shuffle产生的partitions的数量。而当前默认数量是200,但是这个200为什么就不得而知了。然而,这个值设置为多少都不是最优的。其实在不同shuffle,数据的输入大小和分布绝大多数都是不一样。那么简单地用一个配置,让所有的shuffle来遵循,显然是不好的。要设得太小,每个partition的大小就会太大,那么GC的压力就会很大,aggregation和sort会更有可能的去spill数据到磁盘。但是,要是设太大,partition的大小就会太小,partition的数量会大。这个会导致不必要的IO,也让task调度器的压力剧增。那么调度器会导致所有task都变慢。这一系列问题在query plan复杂的时候变得尤为突出,还可能会影响到其他性能,最后耗时耗力却调优失败。
对于这个问题的解决,AQE就有优势了。如下图所示,AQE可以在运行期动态的调整partition来达到性能最优。
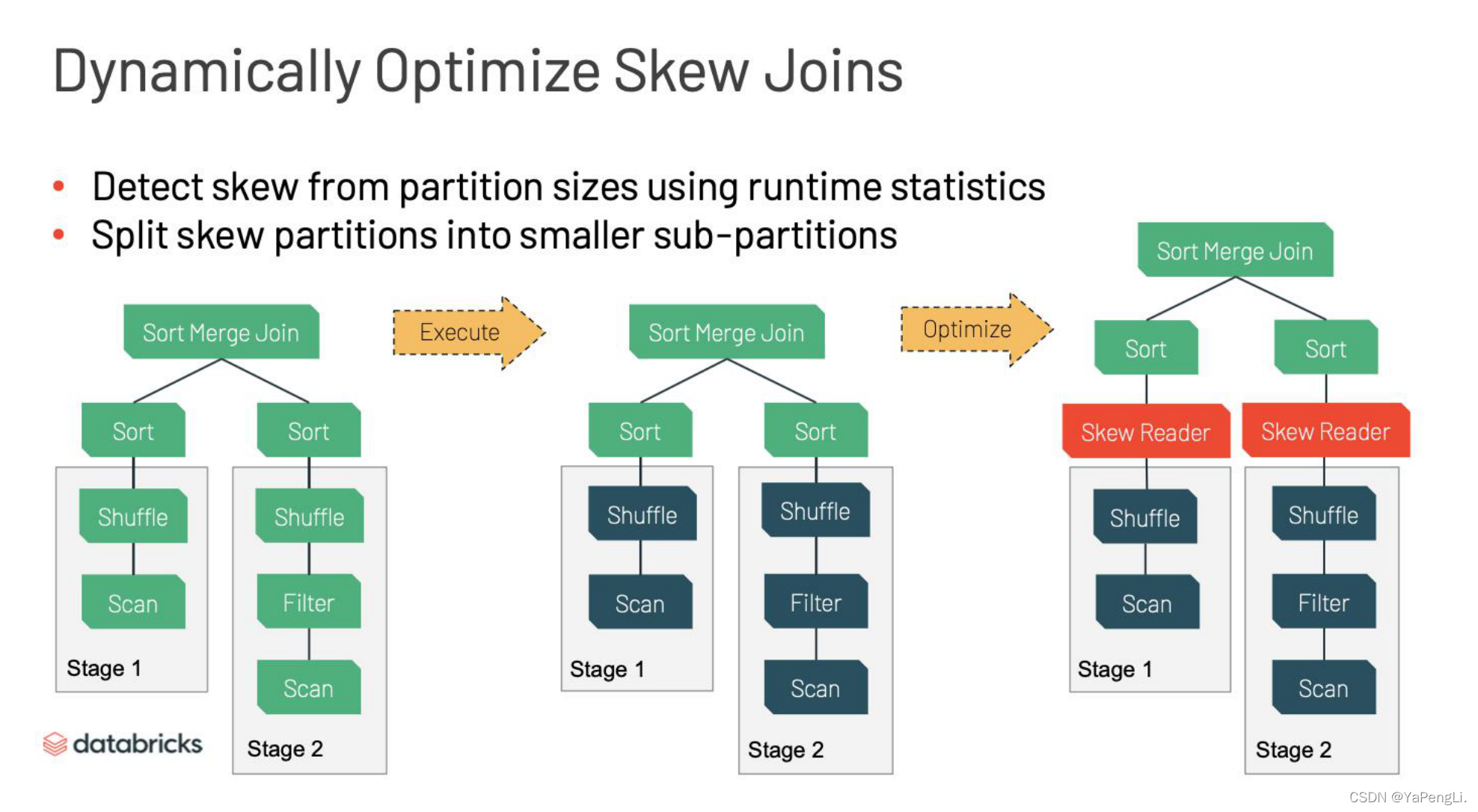
此外,数据分布不均是Spark调优的一个疑难杂症,它的表现有多种,比如若干task停滞不前,像 是出现了bugs,又比如大量的disk spilling会导致很多节点都无事可做。此外,你也许会看到out of memory这种异常。其解决方法也很多,比如找到skew values然后重写query,或者在join的 情况下增加skew keys来消除数据分布不均,但是无论哪种方法,都非常浪费时间,且后期难以维 护。AQE解决问题的方式如下,其通过shuffle落地后的中间数据结果判断哪些partition是skew 的,如果partition过大,就将其分成若干较小partition,通过分而治之,总体性能大幅提升。
AQE的发布可以说是一个时代的开始,未来将会更进一步发展,引入更多自适应规则,让Spark可以随着数据分布和特性的变化自动改变Query plan,让更多的query编译静态优化变成运行时的动态优化。
(二)Dynamic Partition Pruning
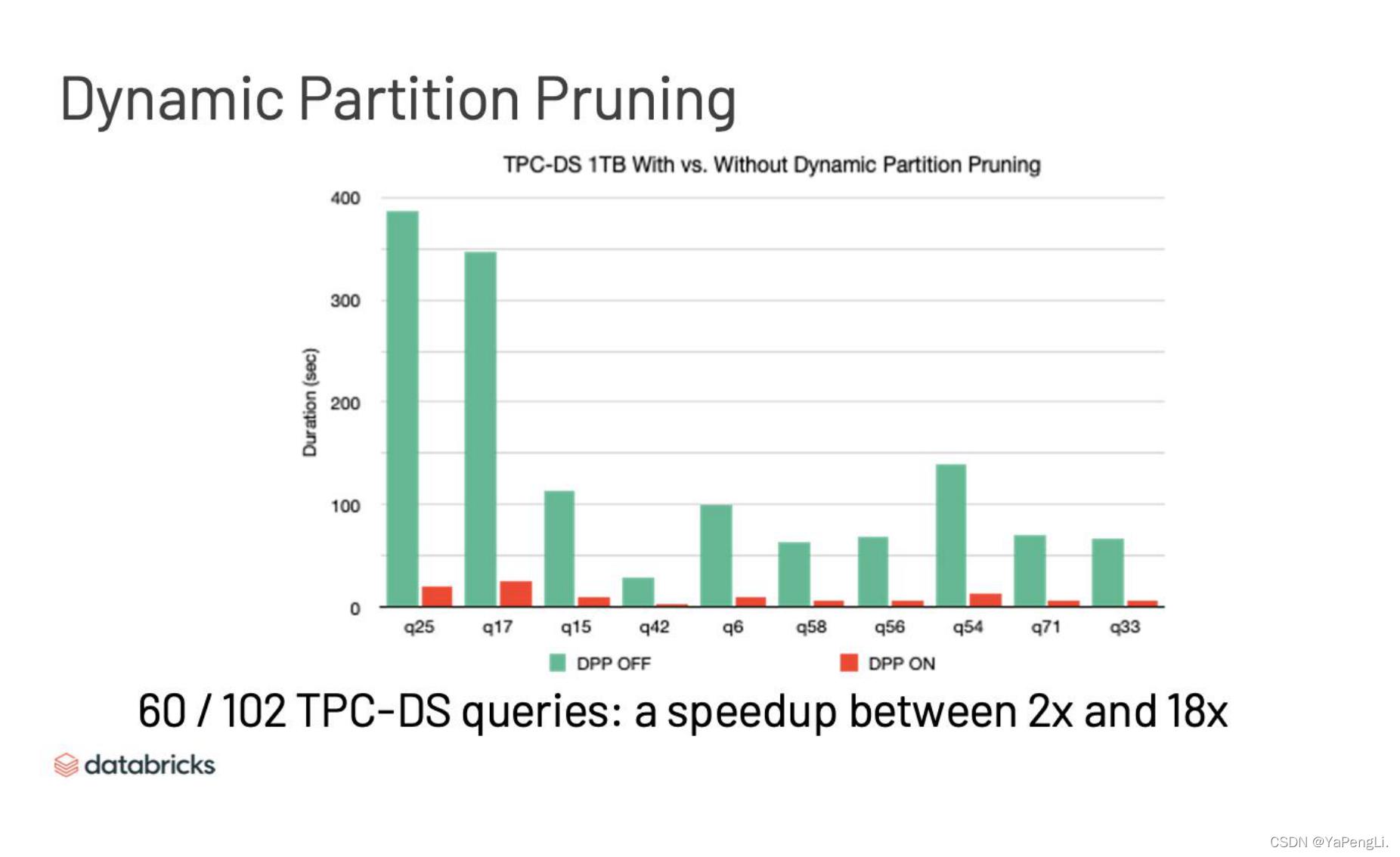
Dynamic Partition Pruning也是一个运行时的动态优化方法,简单来说就是我们可以通过Query的某些分支的中间结果来避免不必要的partition读取,这种方法是无法通过编译期推测出来的,只能在运行时根据结果来判断,这种方法对数据仓库的star-schema效果非常明显,在TPC-DS获得了非常明显的加速,可以加速2-18倍。
(三)Join Hints
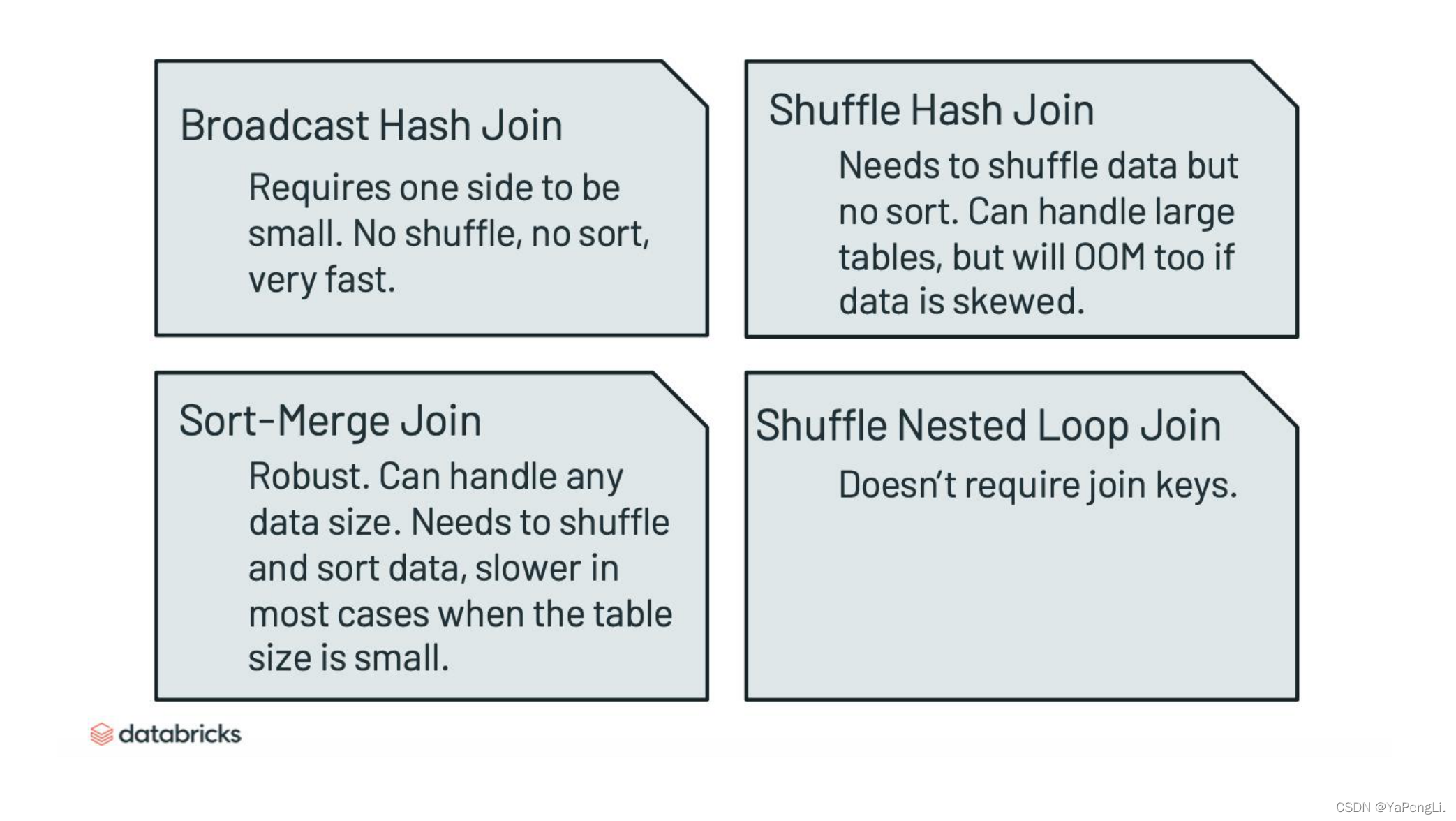
Join Hints是一个非常普遍的数据库的优化策略,在3.0之前已经有了Broadcast hash join,3.0之后的版本加了Sort-merge join、Shuffle hash join和 Shuffle nested loop join,但是要注意谨慎使用,因为数据的特性不同,很难保证一直有效,即使有效,也不代表一直有效,随着时间的变化,你的数据变了,可能会让你的query 变慢,变得不稳定。总体来说上面的四种Join的适用条件和特点如下所示,总而言之,使用Join Hints要谨慎。

















 2278
2278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









