







题目
在 Facebook 或者 Twitter 这样的社交应用中,人们经常会发好友申请也会收到其他人的好友申请。
RequestAccepted 表:
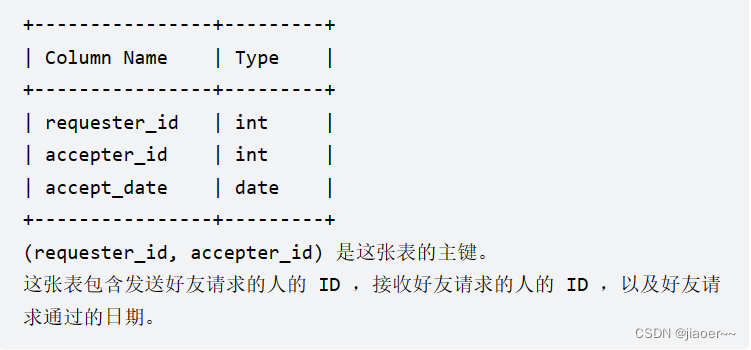
写一个查询语句,找出拥有最多的好友的人和他拥有的好友数目。
生成的测试用例保证拥有最多好友数目的只有 1 个人。
查询结果格式如下例所示。
示例:

解题思路
前置知识
1.row_number()
这段代码是在SQL中使用的窗口函数(window function)`row_number()`。它的作用是为每个分组(通过`partition by`指定的列)中的每一行分配一个序号。
具体来说,`row_number() over (partition by id)`的意思是,根据`id`列进行分组,并为每个分组中的每一行分配一个序号。这个序号是根据每个分组中的行的顺序依次递增的。
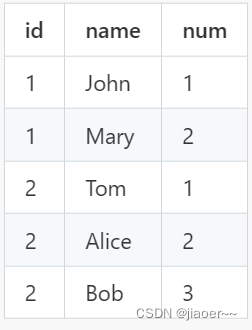
例如,假设有以下数据:
使用`row_number() over (partition by id)`将会得到以下结果:
可以看到,对于每个`id`分组,`num`列依次递增,表示该行在分组中的序号。在这个例子中,`id`为1的分组有2个行,`id`为2的分组有3个行。
2.union all
`UNION ALL`是SQL中的一个操作符,用于将两个或多个SELECT语句的结果合并成一个结果集。与`UNION`操作符不同,`UNION ALL`不会去除重复的行。
具体来说,使用`UNION ALL`时,被合并的SELECT语句必须具有相同数量的列,并且对应的列的数据类型也必须兼容。合并后的结果集将包含所有被合并的SELECT语句的结果,无论是否存在重复的行。
例如,考虑以下两个SELECT语句:
SELECT column1, column2 FROM table1 UNION ALL SELECT column1, column2 FROM table2这个查询将会将`table1`和`table2`中的数据合并成一个结果集,包含两个SELECT语句的结果。如果有重复的行,它们都会被包含在结果集中。
需要注意的是,`UNION ALL`的性能通常比`UNION`要好,因为它不需要进行去重操作。但是,如果需要去除重复的行,应该使用`UNION`操作符。
3.pratition by 和 group by 的区别
`PARTITION BY`和`GROUP BY`都是在SQL中用于对数据进行分组的关键字,但它们有一些区别。
1. 用途:
`PARTITION BY`:用于在窗口函数中指定分组的方式。它将数据划分为不同的分组,以便在每个分组内进行计算和排序。
`GROUP BY`:用于在聚合函数中指定分组的方式。它将数据按照指定的列进行分组,并对每个分组应用聚合函数。2. 函数使用:
`PARTITION BY`:常用于窗口函数中,如`SUM() OVER (PARTITION BY column)`。它将数据划分为多个分组,窗口函数将在每个分组内独立计算。
`GROUP BY`:常用于聚合函数中,如`SELECT column, SUM(value) FROM table GROUP BY column`。它将数据按照指定的列进行分组,然后对每个分组应用聚合函数。3. 结果集:
`PARTITION BY`:在使用窗口函数时,结果集中的每一行都会保留,并在每个分组内分配不同的计算结果。
`GROUP BY`:在使用聚合函数时,结果集中的每个分组将合并为一个行,并计算每个分组的聚合结果。4. 聚合函数:
`PARTITION BY`:窗口函数可以使用各种聚合函数,如`SUM()`、`AVG()`、`ROW_NUMBER()`等。
`GROUP BY`:只能使用聚合函数,如`SUM()`、`AVG()`、`COUNT()`等。总的来说,`PARTITION BY`主要用于窗口函数中对数据进行分组,并在每个分组内进行计算,而`GROUP BY`用于聚合函数中对数据进行分组,并计算每个分组的聚合结果。

明白了以上的函数用法后,让我们一起来解决一下这个问题
1.题目要求查找拥有最多的好友的人,包括自己对他人的好友申请和他人对自己的好友申请。为了统计出申请数最多的人,我们就需要用 union all 函数将 requester_id 和 accepter_id 合并成一个结果集,
2.将合并好的结果集用partition by 函数对 id 进行分组,并利用row_number()函数对每个分组(通过`partition by`指定的列)中的每一行分配一个序号(也就是如果将一个id的requester_id 和accepter_id合并后的结果集越多,对此id分配的序号也就越大 ),然后将这个序号按降序排序,这样我们就可以查找到好友数最多的id。
代码实现
select id, row_number() over (partition by id) as num from
(select requester_id id from requestaccepted
union all
select accepter_id from requestaccepted) ti
order by num desc limit 1测试结果















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









