from:http://blog.csdn.net/xingxingdeyuanwang6/article/details/47401875
- 首先看一下前三行:
. ./cmd.sh
[ -f path.sh ] && . ./path.sh
set -e
(1)cmd.sh脚本文件包含三部分内容:
# "queue.pl" uses qsub. The options to it are
# options to qsub. If you have GridEngine installed,
# change this to a queue you have access to.
# Otherwise, use "run.pl", which will run jobs locally
# (make sure your --num-jobs options are no more than
# the number of cpus on your machine.
#a) JHU cluster options
#export train_cmd="queue.pl -l arch=*64"
#export decode_cmd="queue.pl -l arch=*64,mem_free=2G,ram_free=2G"
#export mkgraph_cmd="queue.pl -l arch=*64,ram_free=4G,mem_free=4G"
#export cuda_cmd=run.pl
#if [[ $(hostname -f) == *.clsp.jhu.edu ]]; then
# export train_cmd="queue.pl -l arch=*64*"
# export decode_cmd="queue.pl -l arch=*64* --mem 3G"
# export mkgraph_cmd="queue.pl -l arch=*64* --mem 4G"
# export cuda_cmd="queue.pl -l gpu=1"
#elif [[ $(hostname -f) == *.fit.vutbr.cz ]]; then
# #b) BUT cluster options
# queue="all.q@@blade,all.q@@speech,all.q@dellgpu*,all.q@supergpu*"
# export train_cmd="queue.pl -q $queue -l ram_free=2500M,mem_free=2500M,matylda5=0.5"
# export decode_cmd="queue.pl -q $queue -l ram_free=3000M,mem_free=3000M,matylda5=0.1"
# export mkgraph_cmd="queue.pl -q $queue -l ram_free=4G,mem_free=4G,matylda5=3"
# export cuda_cmd="queue.pl -q long.q@pcspeech-gpu,long.q@dellgpu1,long.q@pcgpu*,long.q@supergpu1 -l gpu=1"
#else
# echo "$0: you need to define options for your cluster."
# exit 1;
#fi
#c) run locally...
export train_cmd=run.pl
export decode_cmd=run.pl
export cuda_cmd=run.pl
export mkgraph_cmd=run.pl
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
其中a)和b)都是在集群上运行,而c)是在本地运行,因此c)是我们需要的,将a)和b)注释掉,只保留c)。
(2) 若path.sh是常规文件就运行之:-f 判断path.sh是否常规文件,另,常见文件判断命令如下:
-e filename 如果 filename存在,则为真
-d filename 如果 filename为目录,则为真
-f filename 如果 filename为常规文件,则为真
-L filename 如果 filename为符号链接,则为真
-r filename 如果 filename可读,则为真
-w filename 如果 filename可写,则为真
-x filename 如果 filename可执行,则为真
-s filename 如果文件长度不为0,则为真
-h filename 如果文件是软链接,则为真
filename1 -nt filename2 如果 filename1比 filename2新,则为真。
filename1 -ot filename2 如果 filename1比 filename2旧,则为真。
-eq 等于
-ne 不等于
-gt 大于
-ge 大于等于
-lt 小于
-le 小于等于
!非
path.sh内容为:
修改前:
1 export KALDI_ROOT=`pwd`/../../..
2 export PATH=$PWD/utils/:$KALDI_ROOT/src/bin:$KALDI_ROOT/tools/openf
st/bin:$KALDI_ROOT/tools/irstlm/bin/:$KALDI_ROOT/src/fstbin/:$KALDI
_ROOT/src/gmmbin/:$KALDI_ROOT/src/featbin/:$KALDI_ROOT/src/lm/:$KAL
DI_ROOT/src/sgmmbin/:$KALDI_ROOT/src/sgmm2bin/:$KALDI_ROOT/src/fgmm
bin/:$KALDI_ROOT/src/latbin/:$KALDI_ROOT/src/nnetbin:$KALDI_ROOT/sr
c/nnet2bin/:$KALDI_ROOT/src/kwsbin:$PWD:$PATH
3 export LC_ALL=C
4 export IRSTLM=$KALDI_ROOT/tools/irstlm
只修改第一行:(注意,有一些不需要修改也能成功运行)
1 export KALDI_ROOT=/home/wangyongqing/dev/kaldi-git
2 export PATH=$PWD/utils/:$KALDI_ROOT/src/bin:$KALDI_ROOT/tools/openf
st/bin:$KALDI_ROOT/tools/irstlm/bin/:$KALDI_ROOT/src/fstbin/:$KALDI
_ROOT/src/gmmbin/:$KALDI_ROOT/src/featbin/:$KALDI_ROOT/src/lm/:$KAL
DI_ROOT/src/sgmmbin/:$KALDI_ROOT/src/sgmm2bin/:$KALDI_ROOT/src/fgmm
bin/:$KALDI_ROOT/src/latbin/:$KALDI_ROOT/src/nnetbin:$KALDI_ROOT/sr
c/nnet2bin/:$KALDI_ROOT/src/kwsbin:$PWD:$PATH
3 export LC_ALL=C
4 export IRSTLM=$KALDI_ROOT/tools/irstlm
5 export LD_LIBRARY_PATH=$KALDI_ROOT/tools/openfst/lib:$LD_LIBRARY_PATH
修改为kaldi安装目录;
将各种目录设置为环境变量;
LC_ALL它是一个宏,如果该值设置了,则该值会覆盖所有LC_*的设置值。注意,LANG的值不受该宏影响。”C” 这是标准的C Locale。”POSIX”是”C”的别名。它所指定的属性和行为由ISO C标准所指定。
irstlm为开源的语言模型工具包。。
将openfst设为 LD_LIBRARY_PATH 动态库环境变量
(3) set -e 表示告诉bash如果任何语句的执行结果不是true(返回值非零)则应该退出。写每个脚本都应该在开头加上set -e, 这样的好处是防止错误像雪球一样越滚越大。ps: 用set -o errexit也是一样的效果.
2. 然后是声学模型参数设置
export LD_LIBRARY_PATH=/home/wyq/dev/kaldi-git/tools/openfst/lib:$LD_LIBRARY_PATH
numLeavesTri1=2500
numGaussTri1=15000
numLeavesMLLT=2500
numGaussMLLT=15000
numLeavesSAT=2500
numGaussSAT=15000
numGaussUBM=400
numLeavesSGMM=7000
numGaussSGMM=9000
feats_nj=10
train_nj=30
decode_nj=5
这部分基本默认不改,除非自己训练自己的数据库。nj指运行的jobs数目,一般不超过CPU的数量。
3.数据准备
timit=/home/wyq/dev/kaldi-git/egs/timit/s5/timitdata/timit
local/timit_data_prep.sh $timit || exit 1
local/timit_prepare_dict.sh
utils/prepare_lang.sh --sil-prob 0.0 --position-dependent-phones false --num-sil-states 3 data/local/dict "sil" data/local/lang_tmp data/lang
local/timit_format_data.sh
(1) 首先timit数据库原始的wav文件目录赋值给timit,然后运行local目录下的timit_data_prep.sh 脚本,此脚本为数据准备脚本,输入为timit wav文件,输出为data/目录下的:
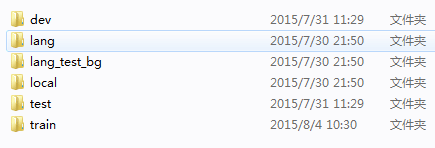
其中关于特征提取的文件夹为dev,test和train,每个文件夹内容都具有相同文件名的文件,如下图所示
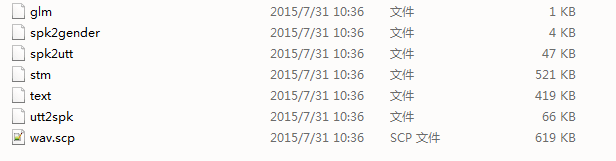
其中四个为必要:wav.scp,text,spk2utt,utt2spk ,这四个文件将作为下一步特征提取的输入。
注: 数据准备详细解析,见博客 (kaldi学习笔记:data_prep.sh详细分析)
4.特征提取
mfccdir=mfcc
for x in train dev test; do
steps/make_mfcc.sh --cmd "$train_cmd" --nj $feats_nj data/$x exp/make_mfcc/$x $mfccdir
steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x $mfccdir
done
(1)mfccdir=mfcc:将mfcc字符串赋值给变量mfccdir
(2)然后运行steps/下的特征提取脚本make_mfcc.sh,其中–cmd
traincmd为脚本cmd.sh中设置的run.pl;−−nj
feats_nj 为运行job数目; data/
x为源数据的目录(data/train,data/dev,data/test为数据准备阶段生成的);exp/makemfcc/
x 为中间生成的.log文件。$mfccdir 为目标目录mfcc文件夹,里面的文件机位提取得分mfcc;
(3)compute_cmvn_stats.sh 是为了计算提取特征的CMVN,即为倒谱方差均值归一化!
注:
MFCC特征提取详细解析,见博客 (kaldi学习笔记:make_mfcc.sh详细分析)
CMVN详细解析,见博客 (kaldi学习笔记:compute_cmvn_stats.sh 详细分析)






















 3870
3870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









