






目录
awk
awk(Aho, Weinberger, Kernighan):报告生成器,格式化文本输出,GNU/Linux发布的AWK目前由自由软件基金会(FSF)进行开发和维护,通常也称它为 GNU AWK。在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,默认以空格或tab键作为分隔符作为分隔,并按模式或者条件执行编辑命令。而awk比较倾向于将一行分成多个字段然后进行处理。AWK信息的读入也是逐行。指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,可以在无交互的情况下实现相当复杂的文本操作,被广泛应用于 Shell 脚本,完成各种自动化配置任务。
版本类型:
- AWK:原先来源于 AT & T 实验室的的AWK。
- NAWK:New awk,AT & T 实验室的AWK的升级版。
- GAWK:即GNU AWK。所有的GNU/Linux发布版都自带GAWK,它与AWK和NAWK完全兼容。
GNU AWK 用户手册文档
https://www.gnu.org/software/gawk/manual/gawk.html
区别:
- gawk:模式扫描和处理语言,可以实现下面功能
- vim: 是将整个文件加载到内存中 再进行编辑, 受限你的内存
- awk(语言): 读取一行处理一行,
awk 工作过程

第一步:执行BEGIN{action;… }语句块中的语句
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,
从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{action;…}语句块
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块
pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
工作原理
awk 将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。
awk 格式
awk 选项 “表达式{处理动作}”
选项:
-F 指定分隔符
-v 自定义变量表达式:awk的语言的表达式。
处理动作:print 打印,printf升级版打印。
内置变量
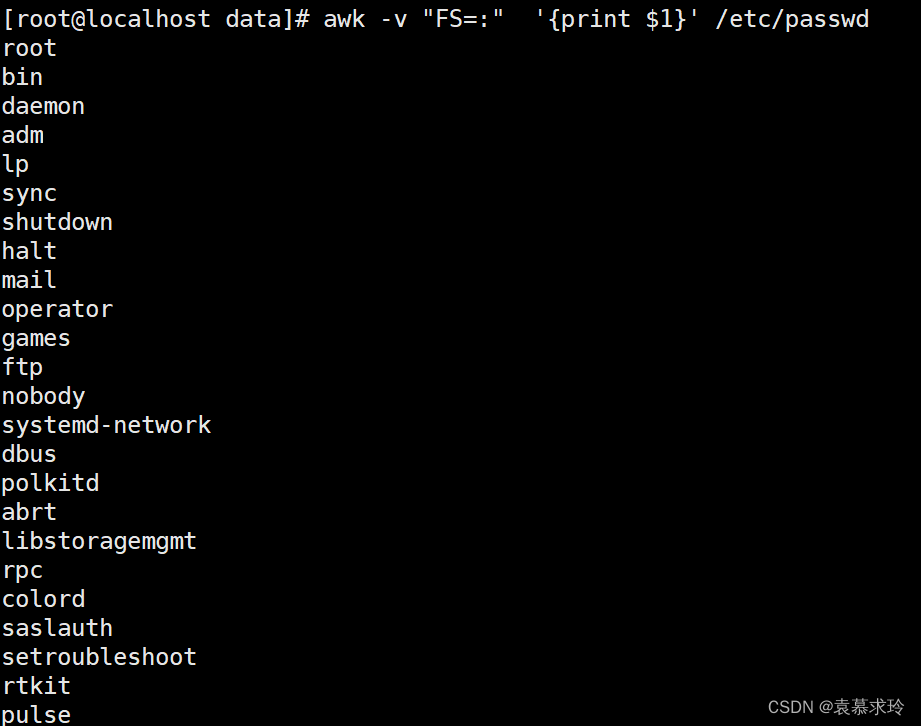
- FS :指定每行文本的字段分隔符,缺省为空格或制表符(tab)。与 “-F”作用相同 -v "FS=:"
- OFS:输出时的分隔符
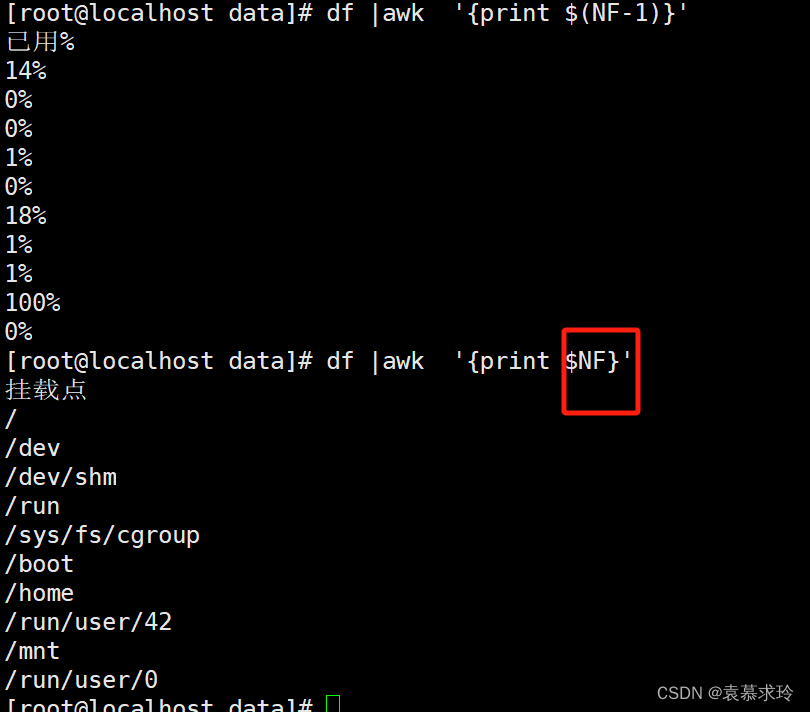
- NF:当前处理的行的字段个数
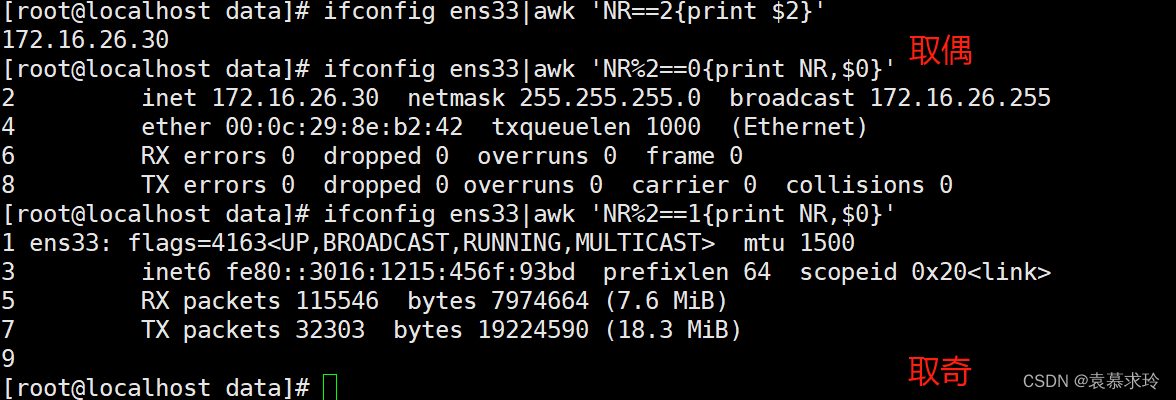
- NR:当前处理的行的行号(序数)
- $0:当前处理的行的整行内容
- $n:当前处理行的第n个字段(第n列) 如 awk '{print $n}' 以空格为分隔符,取第n列。
- FILENAME:被处理的文件名
- RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n




自定义变量
[root@localhost ~]#awk -v test='hello' 'BEGIN{print test}'
hello
awk -v test1=test2="hello" 'BEGIN{test1=test2="hello";print test1,test2}'awk -v test='hello gawk' '{print test}' /etc/fstab
awk -v test='hello gawk' 'BEGIN{print test}'
awk 'BEGIN{test="hello,gawk";print test}'
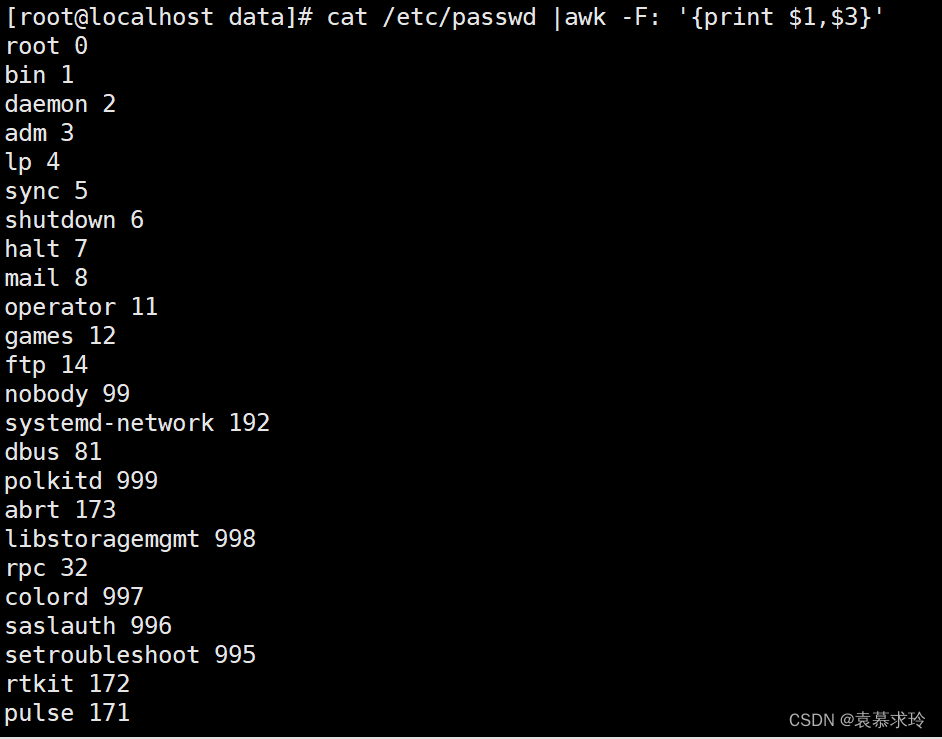
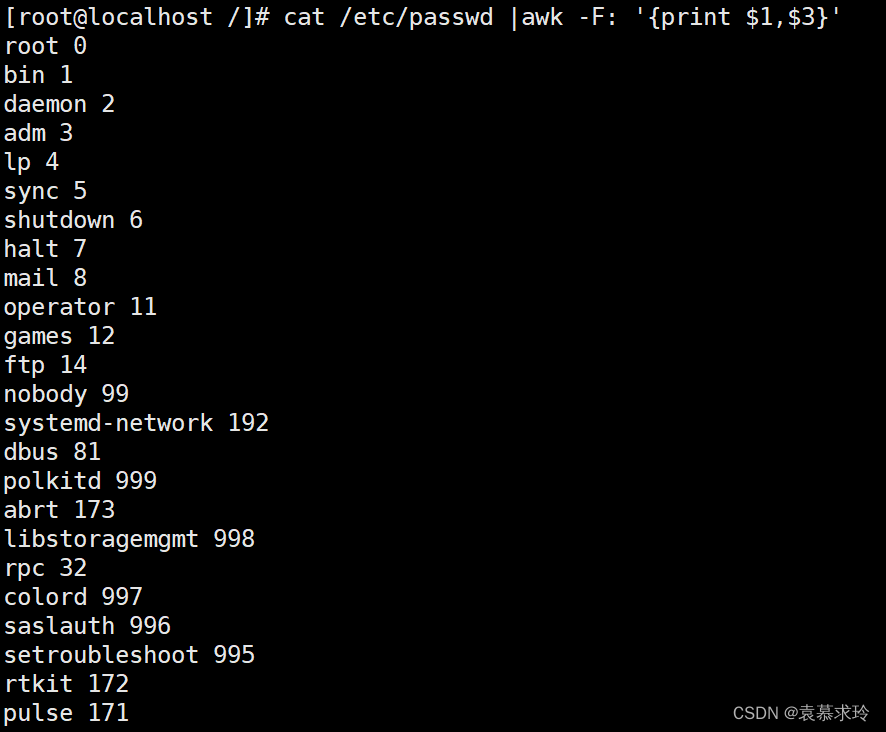
awk -F: '{sex="male";print $1,sex,age;age=18}' /etc/passwd
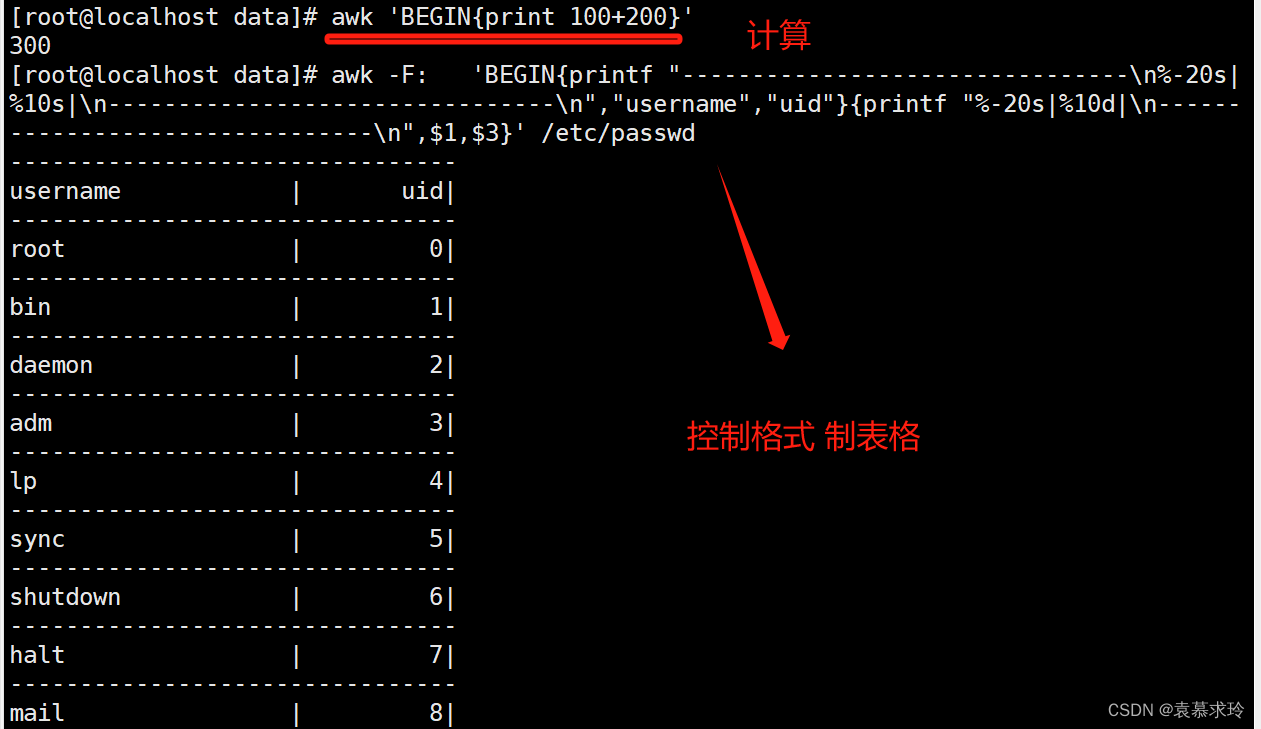
printf
awk -F: 'BEGIN{printf "--------------------------------\n%-20s|%10s|\n--------------------------------\n","username","uid"}{printf "%-20s|%10d|\n--------------------------------\n",$1,$3}' /etc/passwd
模式 PATTERN
awk '模式{处理动作}'
PATTERN:根据pattern条件,过滤匹配的行,再做处理
模式为空
如果模式为空表示每一行都匹配成功,相当于没有额外条件。
awk -F: '{print $1,$3}' /etc/passwd

正则匹配
/regular expression/:仅处理能够模式匹配到的行,需要用/ /括起来。
awk '/^UUID/{print $1}' /etc/fstab

line ranges:行范围
不支持使用行号,但是可以使用变量NR 间接指定行号加上比较操作符 或者逻辑关系。
比较操作符:
==, !=, >, >=, <, <=
#####逻辑
与:&&,并且关系
或:||,或者关系
非:!,取反
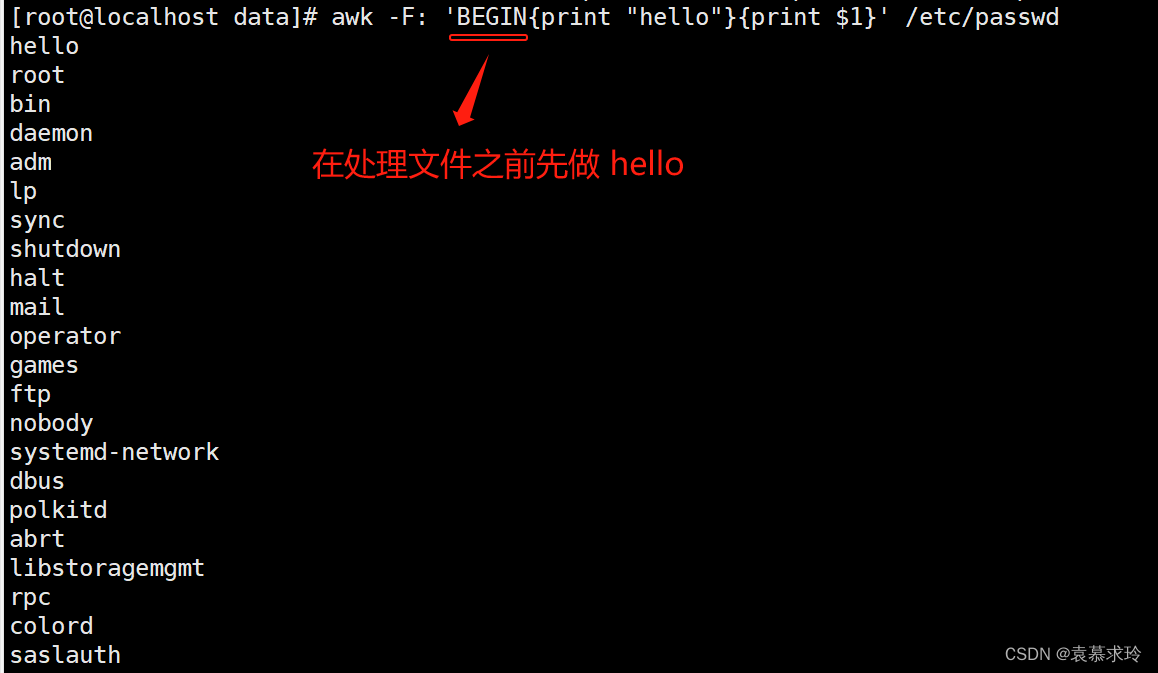
BEGIN END
- BEGIN{}:仅在开始处理文件中的文本之前执行一次
- END{}:仅在文本处理完成之后执行一次
数组
awk数组特性:
- awk的数组是关联数组(即key/value方式的hash数据结构),索引下标可为数值(甚至是负数、小数等),也可为字符串 。在内部,awk数组的索引全都是字符串,即使是数值索引在使用时内部也会转换成字符串;awk的数组元素的顺序和元素插入时的顺序很可能是不相同的。
- awk数组支持数组的数组
访问,赋值数组元素
索引可以是整数、负数、0、小数、字符串。如果是数值索引,会按照CONVFMT变量指定的格式先转换成字符串。
arr[idx]
arr[idx] = value

数组长度
awk提供了 length() 函数来获取数组的元素个数,它也可以用于获取字符串的字符数量。还可以获取数值转换成字符串后的字符数量。

数组

遍历数组
格式:
for(var in array) {for-body}


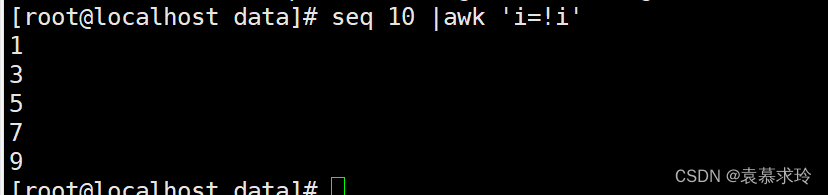
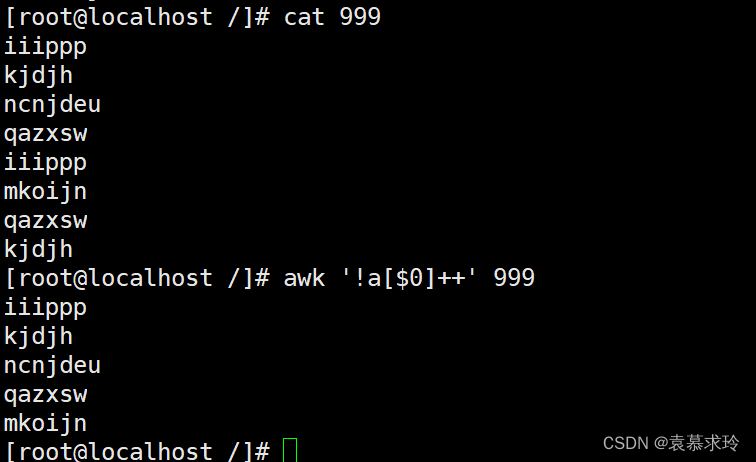
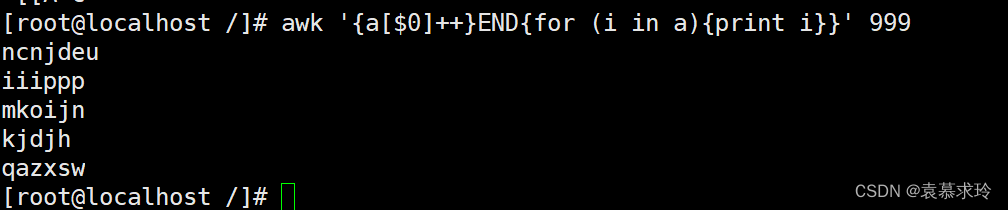
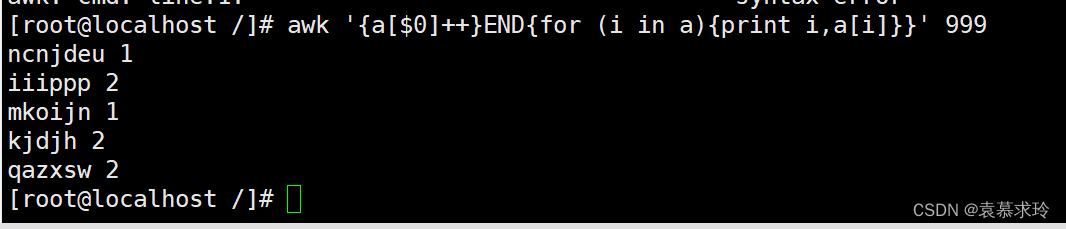
去重复行
如:
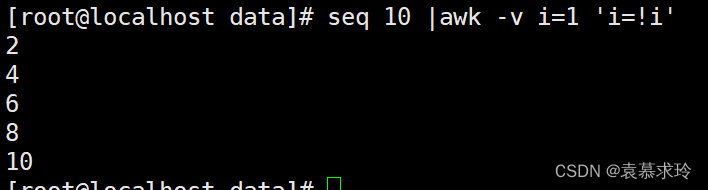
- awk '{a[$1]++}END{for (i in a){print i}}' test.txt
- awk '!a[$0]++' test.txt
sed
sed 即 Stream EDitor,和 vi 不同,sed是行编辑器。
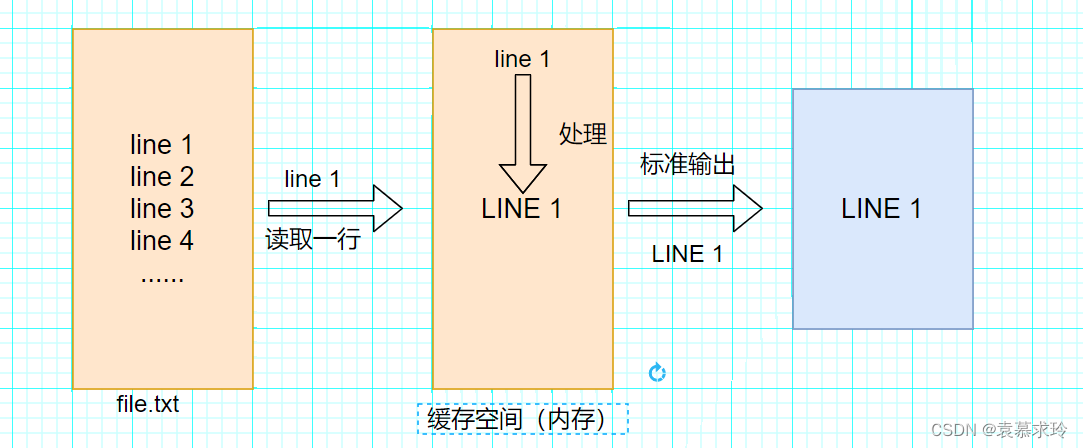
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为模式空间(PatternSpace),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。如果使用vi命令打开几十M上百M的文件,明显会出现有卡顿的现象,这是因为vi命令打开文件是一次性将文件加载到内存,然后再打开。Sed就避免了这种情况,一行一行的处理,打开速度非常快,执行速度也很快。
sed格式
sed [选项]... {脚本(如果没有其他脚本)} [输入文件]...
常用选项:
-n 不输出模式空间内容到屏幕,即不自动打印
-e 多点编辑[root@www data]#sed -n -e '/^r/p' -e'/^b/p' /etc/passwd
-f (FILE) 从指定文件中读取编辑脚本
-r, -E 使用扩展正则表达式
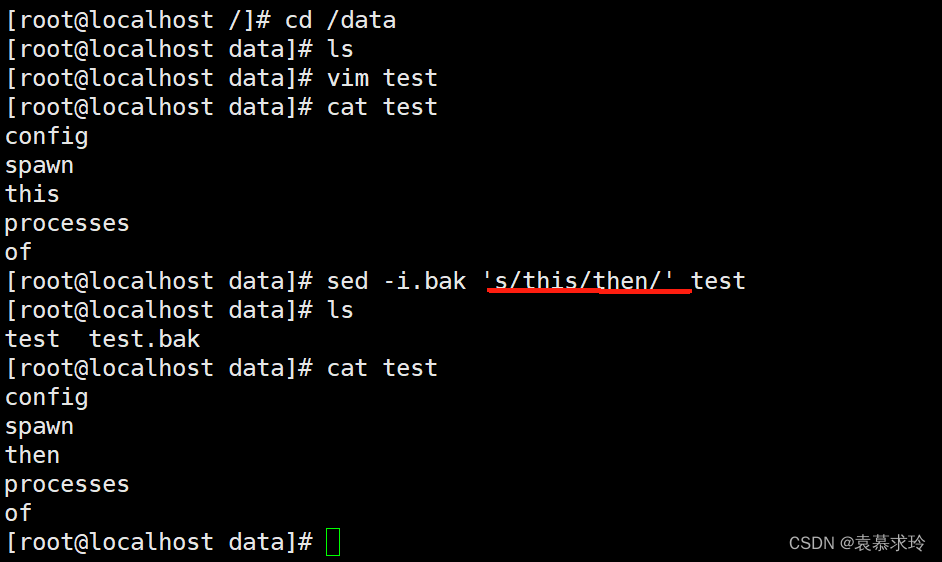
-i.bak 备份文件并原处编辑注:
-ir 不支持
-i -r 支持
-ri 支持
-ni 会清空文件

脚本格式
'地址+命令' 组成,没有地址,即对全文处理。
命令:
p 打印当前模式空间内容,追加到默认输出之后
Ip 忽略大小写输出
d 删除模式空间匹配的行,并立即启用下一轮循环
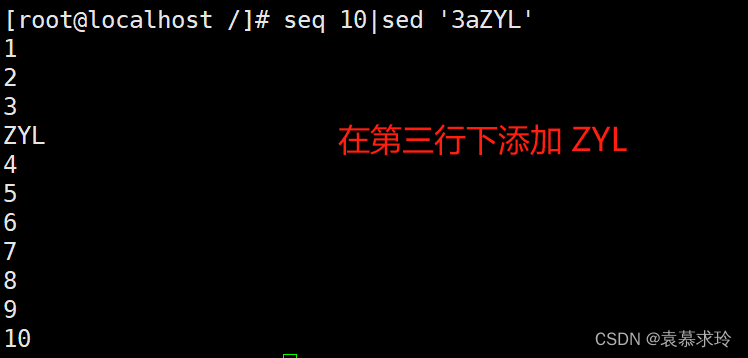
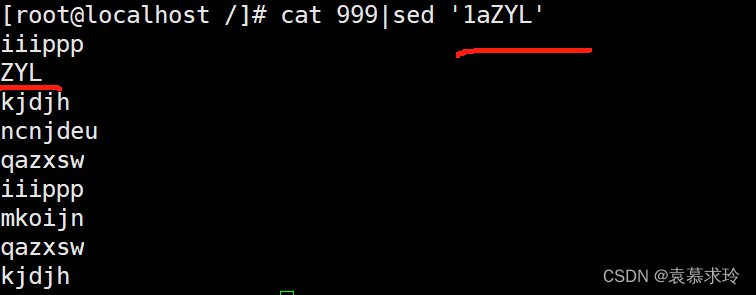
a [\]text 在指定行后面追加文本,支持使用\n实现多行追加
i [\]text 在行前面插入文本
c [\]text 替换行为单行或多行文本
w file 保存模式匹配的行至指定文件 seq 10 |sed -n '2wa.txt'
r file 读取指定文件的文本至模式空间中匹配到的行后 seq 10|sed '2r /etc/issue'
= 为模式空间中的行打印行号 sed '2=' /etc/passwd sed -n -e '=;p' /etc/passwd
! 模式空间中匹配行取反处理seq 10 |sed -n '1~2!p'
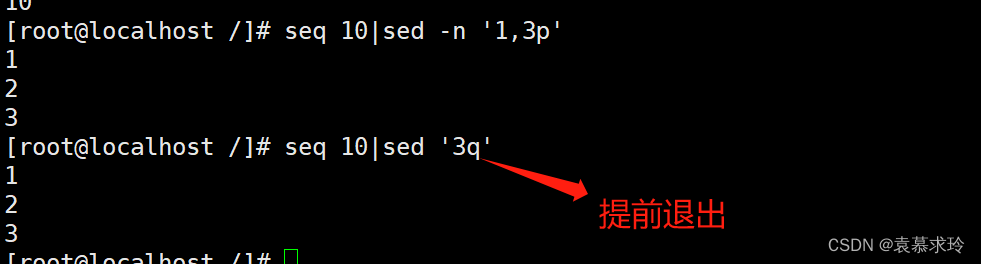
q 结束或退出sed seq 10 | sed '3q'



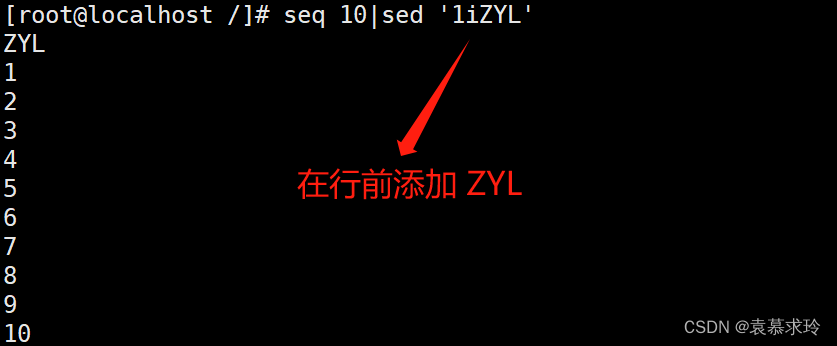


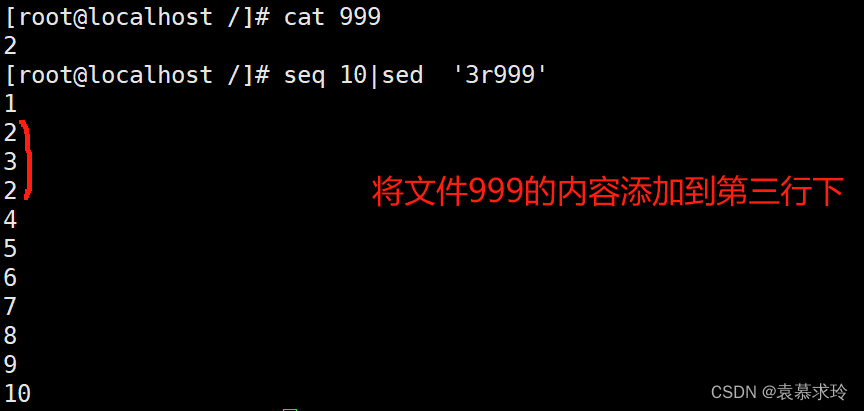
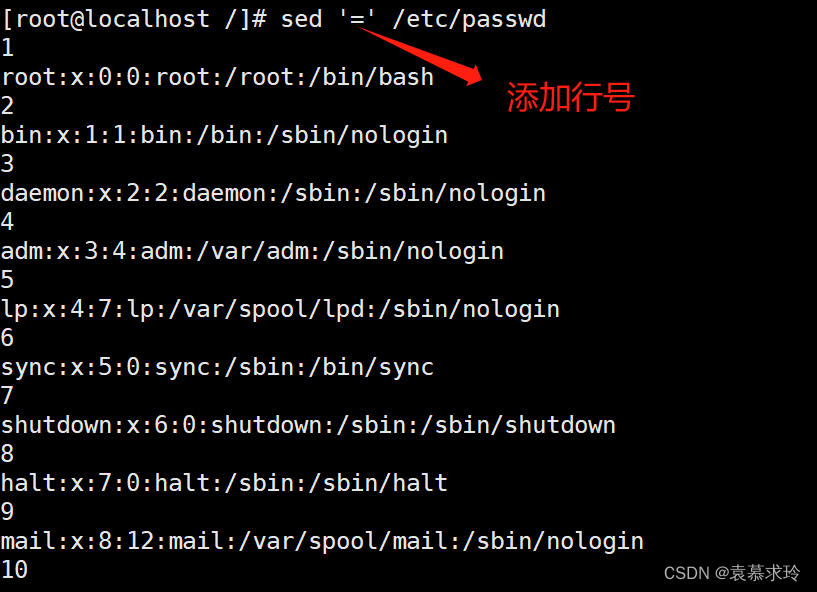


单地址:
#:指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行,正则表达式
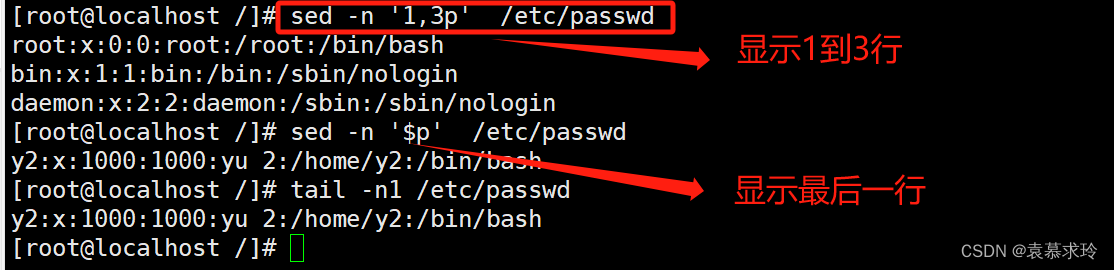
地址范围:
#,# #从#行到第#行,3,6 从第3行到第6行
#,+# #从#行到+#行,3,+4 表示从3行到第7行
/pat1/,/pat2/ 第一个正则表达式到第二个正则表达式之间的行
#,/pat/ 从#号行为开始找到 pat为止
/pat/,# 找到#号个pat为止
步进:~
1~2 奇数行
2~2 偶数行
sed -n 'n;p' testfile1 #打印偶数行
ed -n '2,${n;p}' testfile1
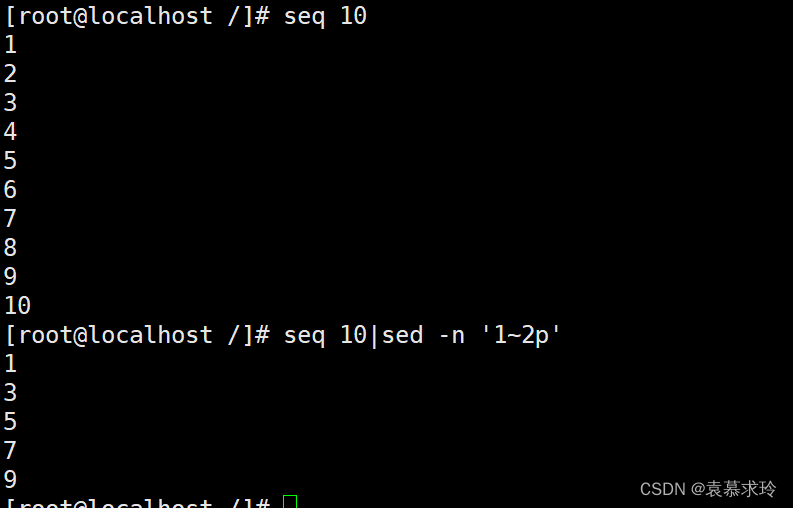

搜索替代
s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
替换修饰符:
g 行内全局替换
p 显示替换成功的行
w /PATH/FILE 将替换成功的行保存至文件中
I,i 忽略大小写
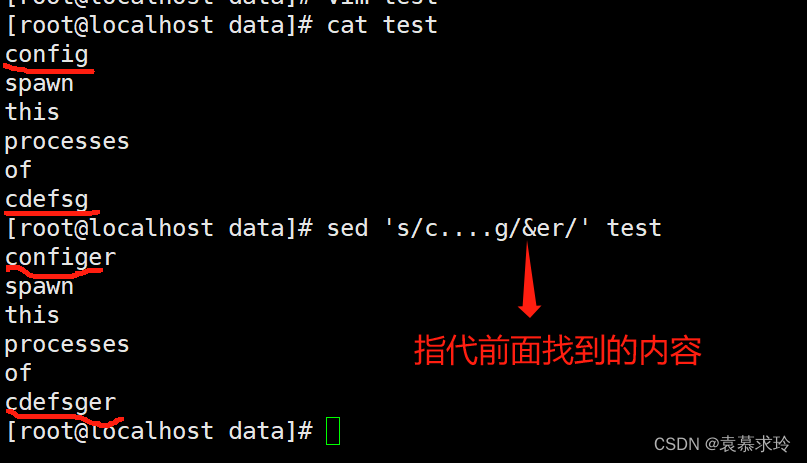
分组后项引用
sed 's//\/'
提取IP地址
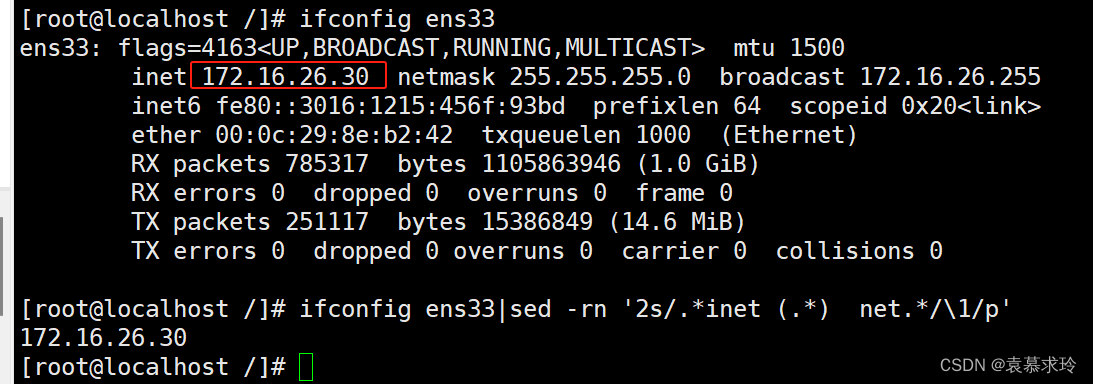

练习
找到10:00到11:00之间的日志
awk '/10:00/,/11:00/' log
sed -n '/2018:11:56:41/,/2018:11:56:44/p' access_log查看设备的连接状态 ss -nat

















 1839
1839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









