







常见的特征筛选算法
- 方差筛选
- 皮尔逊相关系数筛选
- lasso筛选
- 树模型重要性
- shap重要性
- 递归特征消除REF
作业:对心脏病数据集完成特征筛选,对比精度
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression, Lasso
from sklearn.feature_selection import VarianceThreshold, SelectKBest, f_classif, RFE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import shap
import matplotlib.pyplot as plt
# 加载数据
data = pd.read_csv('/mnt/heart.csv')
X = data.drop('target', axis=1)
y = data['target']
# 数据划分与标准化
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 定义逻辑回归模型
model = LogisticRegression(random_state=42)
# 原始数据模型精度
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
original_accuracy = accuracy_score(y_test, y_pred)
print(f"原始数据模型精度: {original_accuracy}")
# 1. 方差筛选
selector_var = VarianceThreshold(threshold=0.1)
X_train_var = selector_var.fit_transform(X_train_scaled)
X_test_var = selector_var.transform(X_test_scaled)
model.fit(X_train_var, y_train)
y_pred_var = model.predict(X_test_var)
var_accuracy = accuracy_score(y_test, y_pred_var)
print(f"方差筛选后模型精度: {var_accuracy}")
# 2. 皮尔逊相关系数筛选
selector_corr = SelectKBest(score_func=f_classif, k=5)
X_train_corr = selector_corr.fit_transform(X_train_scaled, y_train)
X_test_corr = selector_corr.transform(X_test_scaled)
model.fit(X_train_corr, y_train)
y_pred_corr = model.predict(X_test_corr)
corr_accuracy = accuracy_score(y_test, y_pred_corr)
print(f"皮尔逊相关系数筛选后模型精度: {corr_accuracy}")
# 3. Lasso 筛选
lasso = Lasso(alpha=0.01)
lasso.fit(X_train_scaled, y_train)
non_zero_indices = np.where(lasso.coef_ != 0)[0]
X_train_lasso = X_train_scaled[:, non_zero_indices]
X_test_lasso = X_test_scaled[:, non_zero_indices]
model.fit(X_train_lasso, y_train)
y_pred_lasso = model.predict(X_test_lasso)
lasso_accuracy = accuracy_score(y_test, y_pred_lasso)
print(f"Lasso 筛选后模型精度: {lasso_accuracy}")
# 4. 树模型重要性筛选
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train_scaled, y_train)
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
top_features = indices[:5]
X_train_tree = X_train_scaled[:, top_features]
X_test_tree = X_test_scaled[:, top_features]
model.fit(X_train_tree, y_train)
y_pred_tree = model.predict(X_test_tree)
tree_accuracy = accuracy_score(y_test, y_pred_tree)
print(f"树模型重要性筛选后模型精度: {tree_accuracy}")
# 5. SHAP 重要性筛选
explainer = shap.Explainer(rf)
shap_values = explainer(X_train_scaled)
shap_importance = np.abs(shap_values.values).mean(0)
shap_indices = np.argsort(shap_importance)[::-1]
shap_top_features = shap_indices[:5]
X_train_shap = X_train_scaled[:, shap_top_features]
X_test_shap = X_test_scaled[:, shap_top_features]
model.fit(X_train_shap, y_train)
y_pred_shap = model.predict(X_test_shap)
shap_accuracy = accuracy_score(y_test, y_pred_shap)
print(f"SHAP 重要性筛选后模型精度: {shap_accuracy}")
# 6. 递归特征消除(RFE)
rfe = RFE(estimator=model, n_features_to_select=5)
X_train_rfe = rfe.fit_transform(X_train_scaled, y_train)
X_test_rfe = rfe.transform(X_test_scaled)
model.fit(X_train_rfe, y_train)
y_pred_rfe = model.predict(X_test_rfe)
rfe_accuracy = accuracy_score(y_test, y_pred_rfe)
print(f"递归特征消除(RFE)筛选后模型精度: {rfe_accuracy}")
# 可视化结果
methods = ['Original', 'Variance', 'Correlation', 'Lasso', 'Tree', 'SHAP', 'RFE']
accuracies = [original_accuracy, var_accuracy, corr_accuracy, lasso_accuracy, tree_accuracy, shap_accuracy, rfe_accuracy]
plt.bar(methods, accuracies)
plt.xlabel('Feature Selection Methods')
plt.ylabel('Accuracy')
plt.title('Comparison of Model Accuracies after Feature Selection')
plt.xticks(rotation=45)
plt.show()
print("不同特征选择方法下模型的精度:")
result_df = pd.DataFrame({'特征选择方法': methods, '精度': accuracies})
print(result_df)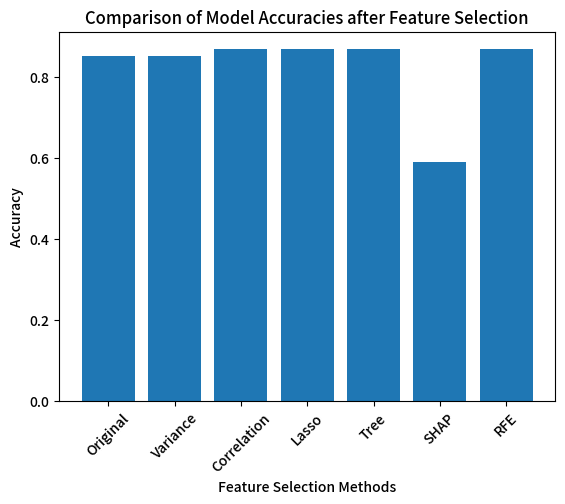
| Original | 0.852459 |
| Variance | 0.852459 |
| Correlation | 0.868852 |
| Lasso | 0.868852 |
| Tree | 0.868852 |
| SHAP | 0.590164 |
| RFE | 0.868852 |
除了 SHAP 重要性筛选后的模型精度明显较低(0.590164)外,其他几种特征选择方法(方差筛选、皮尔逊相关系数筛选、Lasso 筛选、树模型重要性筛选和递归特征消除)的模型精度相近且较高,都在 0.85 以上,其中皮尔逊相关系数筛选、Lasso 筛选、树模型重要性筛选和递归特征消除的精度达到了 0.868852。
@浙大疏锦行

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









