







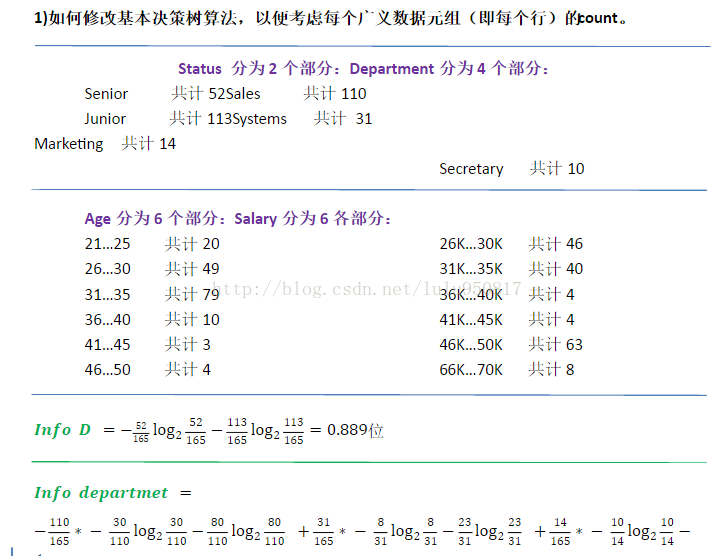
1.4 给出一个例子,其中数据挖掘对于一种商务的成功至关重要的。这种商务需要什么数据挖掘功能?他们能够由数据查询处理或简单的统计分析来实现吗?
可以挖掘什么类型的模式:特征化与区分、频繁模式、分类与回归、聚类、离群点分析。可以航空公司为例,为提高用户体验度,最大限度提高乘客登机时的效率,减少登机所用时间。这就需要进行回归分析,比如以近几个月登机时的数据进行回归分析,来判断某时刻客户登机时的人流量符合哪种分布情况,以预测未来人流量从而提前做出相应改进措施提高用户登机效率。在这种情况下,简单的查询统计是满足不了该航空公司的。
它们不能由数据查询处理或简单的统计分析来实现,因为数据查询处理以及简单的统计分析只能在数据库中进行一些简单的数据查询和更新以及一些简单的数据计算操作,却无法从现有的大量数据中挖掘潜在的价值数据,查询处理主要应用于数据的查询和信息检索方面,无法实现频繁项集发现功能。同样的,简单的统计技术无法完成大规模数据的分析。
1.5 解释区分和分类、特征化和聚类、分类和回归之间的区别和相似之处。
区分和分类:数据区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较;而分类则是找出描述和区分数据类或概念的模型,以便能够使用模型对未知类标号的样例进行预测。
特征化和聚类:数据特征化是目标类数据的一般特性或特征的汇总,即在进行数据特征化时很清楚特征化的这些数据的特点是什么;而聚类则只是分析数据对象,按照“最大化类内相似度、最小化类间相似度”的原则进行聚类或分组。
分类在第一点时已经说过;回归主要是建立连续值的函数模型,回归主要用来预测缺失的或难以获得的数值数据值,而不是离散的类标号,同时回归也包含基于可用数据的分布趋势识别。
2.2 假设所分析的的数据包括属性age,它在数据元组中的值(以递增序)为13,15,16,16,19,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70.
1. 该数的均值是多少?中位数是什么?
该数的均值为29.963,中位数是25。
2. 该数据的众数是什么?讨论数据的模态(即二模、三模等)。
该数据的众数为25和35,即该数据是一个双峰的分布,即二模。
3. 该数据的中列数是多少?
该数据的中列数为(70+13)/2=41.5。
4. 你能粗略的找出该数据的第一个四分位数(Q1)和第三个四分位数(Q3)吗?
第一个四分位数为:⌈27/4⌉=7处,Q1=20,第三个四分位数为:7∗3=21处,Q3=35。
5. 给出该数据的五数概括。
五数:最小值,第一个四分位数,中位数,第三个四分位数,最大值
根据以上,得到了最小观测值、Q1、Q2、Q3、最大观测值,所以画出其盒图如下:Q1=20,Q3=35 中位数=25
IQR=35-20=15;
1.5IQR=22.5;

最大观测值=Q3+22.5=57.5;
最小观测值=Q1-22.5=-7.5;
6、分位数-分位数图与分位数图有什么区别?
分位数图(quantile plot)是一种观察单变量数据分布的简单有效方法。首先它显示给定属性的所有数据的分布情况;其次,它绘出了分位数信息(即对于某序数或数值属性X,设xi(i=1,...,N)是按照递增排序的数据,使得x1是最小的观测值,xN是最大的观测值)。
分位数-分位数图(q-q图)则是反映了同一 个属性的不同样本的数据分布情况,使得用户可以很方便的比较这两个样本之间的区别或者联系。
3.3



6.6




6.8


6.14


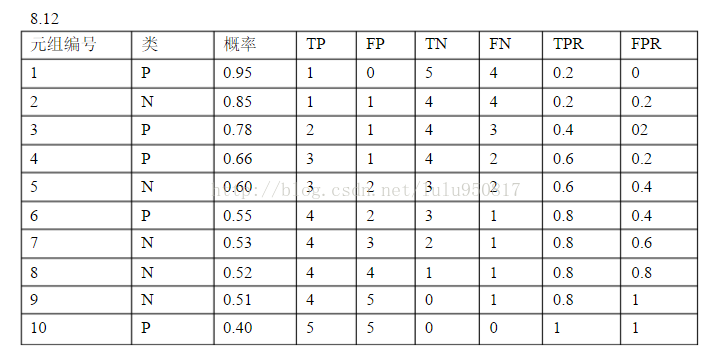
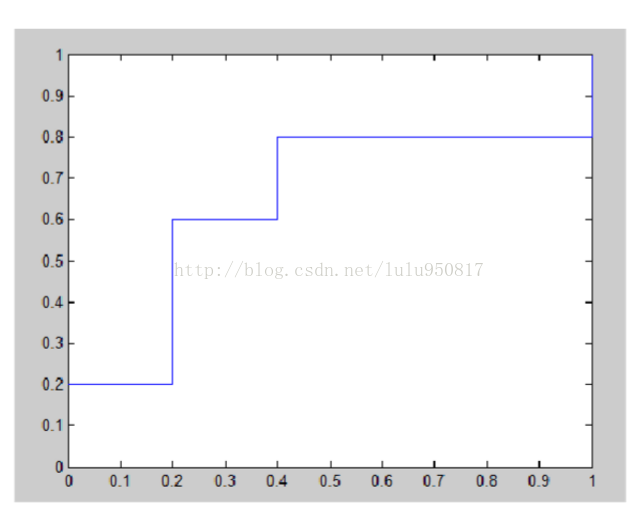
8.7

(b)

(c)


9.8
1、
半监督分类(Semi-SupervisedClassification):在无类标签的样例的帮助下训练有类标签的样本,获得比只用有类标签的样本训练得到的分类器性能更优的分类器,弥补有类标签的样本不足的缺点,其中类标签取有限离散值 ;
半监督分类在20世纪70年代就已出现,它属于半监督学 习的范畴,从有监督学习的角度出发,着重于研究离散数据的分 类问题,其最初的研究工作开始于Shahshahani的文献H J。由于 此分类方法有较高的准确性,且能省去许多为获得标记样本所花费的人工成本,人们对它的研究兴趣也就逐渐高涨。目前,所 研究出的基本分类方法大致有以下六类胪1:基于生成模型的半监督分类方法、基于自训练的半监督分类方法、基于协同训练的 半监督分类方法、基于图的半监督分类方法、基于支持向量机的 半监督分类方法和基于流形正则化的半监督分类方法。半监督分类方法的应用范围很宽广,如文本分类、信息检 索、图像处理、安全监测、特征识别、疾病诊断等∞1,能够在数据挖掘、机器学习和生物信息学等领域中发挥积极的作用。
在利用半监督分类建模中,标记样本的数目是非常有 限的,如果标记样本的类别标记是错误标记或是标记样本处于异常分布区时,分类模型将会因为标记样本的错误引导和未标 记样本的近邻传播产生分类偏差。虽然在文献[5]中加入了后验概率对模型定位,减少模糊异常标记样本对分类结果的影响, 但分类误差是不可避免的,而且后验概率的获得也是研究中的 难题。在后续的研究中,不妨改进基本的分类算法,在算法中设定某种阈值,若错误的标记样本不满足阈值则会被自动淘汰,满 足阈值的样本将继续训练分类器。但该想法暂不完备,能否实 现仍需仔细探讨。
2、在人类的学习过程中,通常利用已有的经验来学习新的知识,又依靠获得的知识来总结和积累经验,经验与知识不断交互。同样,机器学习模拟人类学习的过程,利用已有的知识训练出模型去获取新的知识,并通过不断积累的信息去修正模型,以得到更加准确有用的新模型。不同于被动学习被动的接受知识,主动学习能够选择性地获取知识,
主动学习的模型如下:
A=(C,Q,S,L,U),
其中C为一组或者一个分类器,L是用于训练已标注的样本。Q 是查询函数,用于从未标注样本池U中查询信息量大的信息,S是督导者,可以为U中样本标注正确的标签。学习者通过少量初始标记样本L开始学习,通过一定的查询函数Q选择出一个或一批最有用的样本,并向督导者询问标签,然后利用获得的新知识来训练分类器和进行下一轮查询。主动学习是一个循环的过程,直至达到某一停止准则为止。
主动学习已逐步投入具体的应用,其中包括文档分类及信息提取、图像检索、入侵检测、Web分析和视频分析等广大领域的实际问题,相对于文本,图像中蕴含的信息量更大因此图像检索也是主动学习的一个重要应用领域。
问题:1)学习器不知道样例如何分布的情况;2)低误差率情况下的均匀或任意分布的有高样本复杂度边界的高效学习算法;3)空间和时间复杂度不能随着可见样例和错误上升而上升的情况;4)针对其他概念类或者一般概念类的学习问题
3、
迁移学习典型应用方面的研究主要包含有文本分类、文本聚类、情感分类、图像分类、协同过滤、基于传感器的定位估计、人工智能规划等。

关于迁移学习算法有效性的理论研究还很缺乏,研究可迁移学习条件,获取实现正迁移的本质属性,避免负迁移.最后,在大数据环境下,研究高效的迁移学习算法尤为重要.目前的研究主要还是集中在研究领域,数据量小而且测试数据非常标准,应把研究的算法瞄准实际应用数据,以适应目前大数据挖掘研究浪潮。
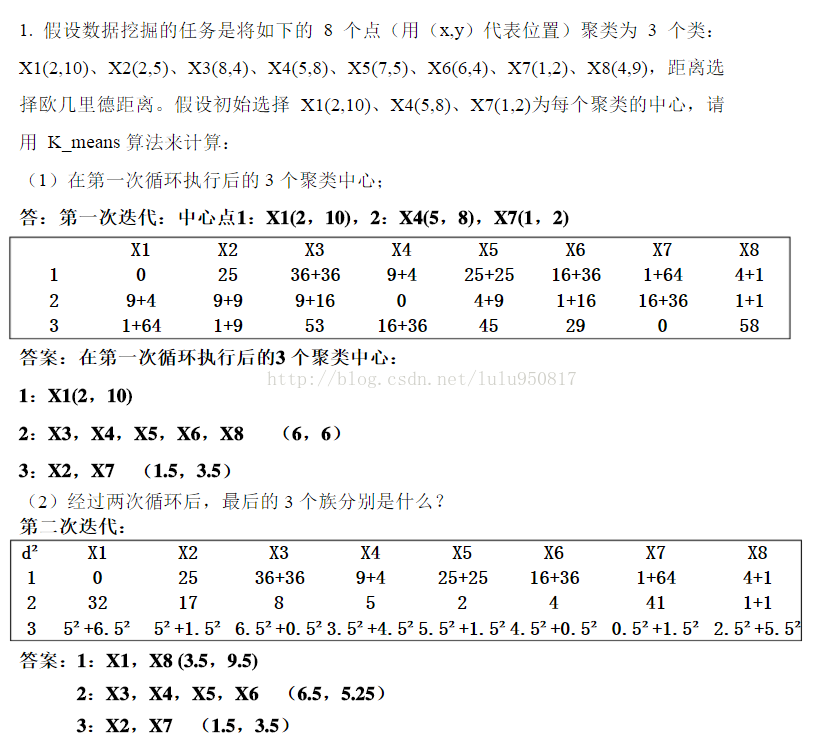
10.2

10.4
















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









