







一、场景
在mysql数据同步到ES中,发现第一次同步时需要全量的数据,之后则需要定时去同步增量数据,使用logstash需要了解一下事项(注意:更新周期最快是1分钟)
1、凡是SQL可以实现的logstash均可以实现(本就是通过sql查询数据)
2、支持每次全量同步或按照特定字段(如递增ID、修改时间)增量同步;
3、同步频率可控,最快同步频率每分钟一次(如果对实效性要求较高,慎用);
4、不支持被物理删除的数据同步物理删除ES中的数据(可在表设计中增加逻辑删除字段IsDelete标识数据删除)。
二、全量更新
1、前提:
数据库名为:test
test下表名为:student
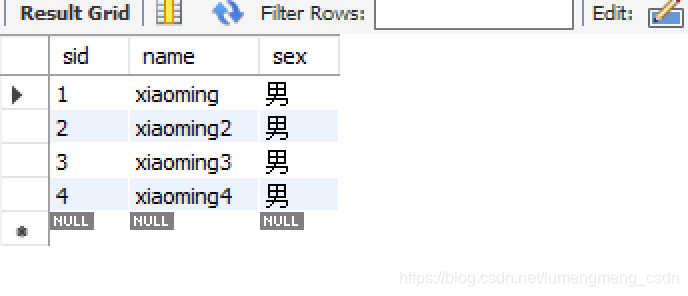
表中数据如下图:
2.在logstash-6.5.1文件夹下创建totalJdbc.conf,totalStudent.sql两个文件
totalJdbc.conf文件如下:
input {
stdin {
}
jdbc {
# 驱动
jdbc_driver_library => "/home/mysql-connector-java-5.1.42.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql://192.168.31.240:3306/test"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "Aa123456~"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
# 执行的sql 文件路径+名称
statement_filepath => "/home/logstash-6.5.1/t 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7461
7461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









