







1.BP神经网络的基本概念和原理
BP神经网络的概念:
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络。是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。BP神经网络的基本模型图如下所示:
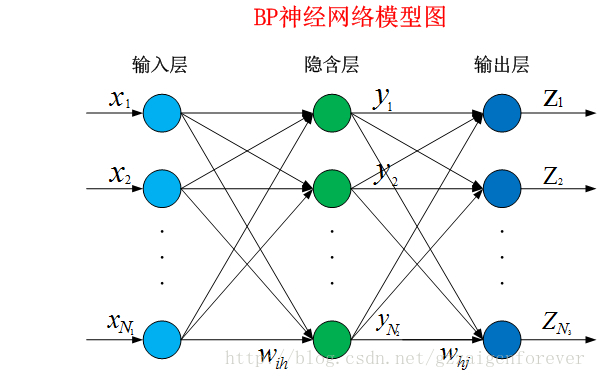
BP网络的三个层次:输入层、隐藏层以及输出层。我们所要做的就是根据自身的需求建立一个属于我们自己的BP神经网络。
2.BP神经网络的原理以及相关公式的推导
2.1、BP网络的基本思想:
BP神经网络学习过程由信息的正向传递与误差的反向传播两个过程组成:
(1) 正向传递:输入样本从输入经隐含层逐层计算传向输出层,若输出层的实际输出和期望输出不符,则计算输出层的误差值,然后转向反向传播过程。
(2) 误差的反向传播:是将输出误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层所有单元,从而获得各层单元的误差信号,此误差做为修正该单元的依据。信号正向传递和误差反向传播反复进行,权值不断得到调整的过程,就是网络的学习/训练过程。当训练达到规定误差或一定训练次数,则结束训练。
BP网络训练学习过程可理解成:样本输入时的理想目标Tk与实际输出Ok之间的误差平方Ep不断趋向于0的一个过程:
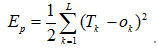
根据误差梯度下降法依次修正输出层权值的修正量 Δ wki ,输出层阈值的修正量 Δa k,隐含层权值的修正量 Δ wij ,隐含层阈值的修正量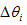
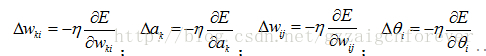
上述公式表明网络输入误差是各层权值wjk、vij的函数,因此调整权值可改变误差E。显然,调整权值的原则是使误差不断地减小,因此应使权值的调整量与误差的梯度下降成正比,故而对BP网络算法的直观解释如下所示:
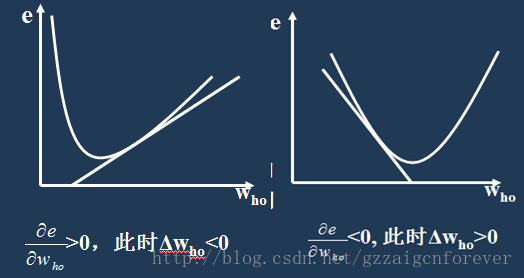
通过上图表明,BP网络算法的核心是在不断调整权值的情况下,使得误差不断的减小。显然无论是在正向梯度还是负向梯度,在离散情况下都需要不断的将权值往误差极小值的地方调整。而调整的速率值eta(也称权值的步进值)关乎着整个神经网络的训练速度。
BP神经网络的公式推导可以参考:http://en.wikipedia.org/wiki/Backpropagation,相关推导公式核心内容如下:
BP网络的算法核心是使用一个刺激函数不断的forward,而这个刺激函数往往使用S型激活函数(logsig)为:






3.BP神经网络算法用C语言的实现
3.1.初始的准备工作,建立三个层的数据结构体:分别表示样本信息、输入层的信息、隐藏层的信息以及输出层的信息,最终归于到一个BP核心算法的结构体bp_alg_core_params;
typedef struct {
unsigned int img_sample_num; //待训练的图像字符、数字样本个数
unsigned int img_width;
unsigned int img_height;
unsigned char *img_buffer;
}img_smaple_params;
typedef img_smaple_params* hd_sample_params;
typedef struct {
unsigned int in_num; //输入层节点数目
double *in_buf; //输入层输出数据缓存
double **weight; //权重,当前输入层一个节点对应到多个隐层
unsigned int weight_size;
double **pri_deltas; //记录先前权重的变化值,用于附加动量
double *deltas; //当前计算的隐层反馈回来的权重矫正
}bp_input_layer_params;
typedef bp_input_layer_params* hd_input_layer_params;
typedef struct {
unsigned int hid_num; //隐层节点数目
double *hid_buf; //隐层输出数据缓存
double **weight; //权重,当前隐层一个节点对应到多个输出层
unsigned int weight_size;
double **pri_deltas; //记录先前权重的变化值,用于附加动量
double *deltas; //当前计算的输出反馈回来的权重矫正值
}bp_hidden_layer_params;
typedef bp_hidden_layer_params* hd_hidden_layer_params;
typedef struct {
unsigned int out_num;//输出层节点数目
double *out_buf; //输出层输出数据缓存
double *out_target;
}bp_out_layer_params;
typedef bp_out_layer_params* hd_out_layer_params;
typedef struct {
unsigned int size; //结构体大小
unsigned int train_ite_num; //训练迭代次数
unsigned int sample_num; //待训练的样本个数
double momentum; //BP阈值调整动量
double eta; //训练步进值,学习效率
double err2_thresh; //最小均方误差
hd_sample_params p_sample; //样本集合参数
hd_input_layer_params p_inlayer; //输入层参数
hd_hidden_layer_params p_hidlayer;//隐藏层参数
hd_out_layer_params p_outlayer;//输出层参数
}bp_alg_core_params; 3.2.参数的初始化,主要包括对计算缓存区的分配。
假设这里分别有M,N,K表示输入、隐藏、输出的节点数目;
那么一个输入缓存区大小:分配大小M+1个;同理隐藏层和输出分别分配:N+1,P+1个;数据量大小默认双精度的double类型。
权值的缓冲区大小:一个根据BP网络的算法,一个节点到下一层的节点分别需要具备一一对应,故这是一个二维数组的形式存在,我们分配输入层权值空间大小为(M+1)(N+1)的大小,隐藏权值空间大小为(N+1)(P+1);
当然对于权值的矫正量,其是一个依据节点的输出值向后反馈的一个变量,实际就是多对1的反馈,而通过公式可以看到我们可以只采用一维数组来表示每一个节点的反馈矫正值(不基于输入节点的数据,即如下的变量:
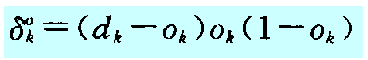
同理最终隐藏层到输出层的反馈矫正、输出层和隐藏层的反馈矫正都以一个一位变量的形式存在,只是在计算权值时要结合节点的输入数据来进行2维矫正。
完成二维数组的动态分配过程函数如下所示:
double** alloc_2d_double_buf(unsigned int m, unsigned int n)
{
unsigned int i;
double **buf = NULL;
double *head;
/*分配一个数组指针空间+ 2维数据缓存空间*/
buf = (double **)malloc(sizeof(double *)*m + m*n*sizeof(double));
if(buf == NULL)
{
ERR("malloc error!");
exit(1);
}
head = (double *)(buf + m);
memset((void *)head, 0x00, sizeof(double)*m*n);//clear 2d buf
for(i = 0; i < m; i++)
{
buf[i] = head + i*n;
DEG("alloc_2d_double_buf, addr = 0x%x", buf[i] );
}
return buf;
} 3.3 BP神经网络训练过程和不断的权值矫正
依次经过forward向前刺激,权值矫正值计算,权值调整,样本均分误差计算。以一次样本数所有样本节点计算完后做均方误差,误差满足一定的阈值就说明BP神经网络训练可以基本结束(一般定义可接受的误差在0.001左右):
int bp_train(bp_alg_core_params *core_params)
{
unsigned int i, j, k;
unsigned int train_num, sample_num;
double err2;//均分误差
DEG("Enter bp_train Function");
if(core_params == NULL)
{
ERR("Null point Entry");
return -1;
}
train_num = core_params->train_ite_num;//迭代训练次数
sample_num = core_params->sample_num;//样本数
hd_sample_params p_sample = core_params->p_sample; //样本集合参数
hd_input_layer_params p_inlayer = core_params->p_inlayer; //输入层参数
hd_hidden_layer_params p_hidlayer = core_params->p_hidlayer; //隐藏层参数
hd_out_layer_params p_outlayer = core_params->p_outlayer; //输出层参数
DEG("The max train_num = %d", train_num);
/*依次按照训练样本数目进行迭代训练*/
for(i = 0; i < train_num; i++)
{
err2 = 0.0;
DEG("current train_num = %d", i);
for(j = 0 ; j < sample_num; j++)
{
DEG("current sample id = %d", j);
memcpy((unsigned char*)(p_inlayer->in_buf+1), (unsigned char*)sample[j], p_inlayer->in_num*sizeof(double));
memcpy((unsigned char*)(p_outlayer->out_target+1), (unsigned char*)out_target[j%10], p_outlayer->out_num*sizeof(double));
/*输入层到隐藏层的向前传递输出*/
bp_layerforward(p_inlayer->in_buf, p_hidlayer->hid_buf, p_inlayer->in_num, p_hidlayer->hid_num, p_inlayer->weight);
/*隐藏层到输出层的向前传递输出*/
bp_layerforward(p_hidlayer->hid_buf, p_outlayer->out_buf, p_hidlayer->hid_num, p_outlayer->out_num, p_hidlayer->weight);
/*输出层向前反馈错误到隐藏层,即权值矫正值*/
bp_outlayer_deltas(p_outlayer->out_buf, p_outlayer->out_target, p_outlayer->out_num, p_hidlayer->deltas);
/*隐藏层向前反馈错误到输入层,权值矫正值依赖于上一层的调整值*/
bp_hidlayer_deltas(p_hidlayer->hid_buf, p_hidlayer->hid_num, p_outlayer->out_num, p_hidlayer->weight, p_hidlayer->deltas, p_inlayer->deltas);
/*调整隐藏层到输出层的权值*/
adjust_layer_weight(p_hidlayer->hid_buf, p_hidlayer->weight, p_hidlayer->pri_deltas, p_hidlayer->deltas, p_hidlayer->hid_num,
p_outlayer->out_num, core_params->eta, core_params->momentum);
/*调整隐藏层到输出层的权值*/
adjust_layer_weight(p_inlayer->in_buf, p_inlayer->weight, p_inlayer->pri_deltas, p_inlayer->deltas, p_inlayer->in_num,
p_hidlayer->hid_num, core_params->eta, core_params->momentum);
err2 += calculate_err2(p_outlayer->out_buf, p_outlayer->out_target, p_outlayer->out_num);//统计所有样本遍历一次后的均分误差
}
/*一次样本处理后的均分误差统计*/
err2 = err2/(double)(p_outlayer->out_num*sample_num);
INFO("err2 =%08f\n",err2 );
if(err2 < core_params->err2_thresh)
{
INFO("BP Train Success by costs vaild iter nums: %d\n", i);
return 1;
}
}
INFO("BP Train %d Num Failured! need to modfiy core params\n", i);
return 0;
} 

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









