







Fast, Diverse and Accurate Image Captioning Guided By Part-of-Speech
时间:2019年
概括
本文致力于建立一个fast,accurate,diverse的image caption模型,首先提出了传统beam search的慢、diversity不足,以及基于GAN、VAE方法的准确率不足的缺陷,然后提出了根据词性序列生成caption的方法,这样做保证了caption的多样性,同时相比beam search又更快,具体的,captioner接受一个词性序列(比如none verb none)作为生成句子的全局信息,在对应的位置生成对应词性的词来得到一条caption,通过以多个不同的part-of-speech seq作为条件,生成多个不同的caption
Intro
本文通过以图片不同的high-level summary为条件,来生成多样的caption,主要步骤是
- (a)从图片中预测出一系列summaries
- (b)以每个summary为条件得到caption
这个方法有以下的特点
- accurate,因为它可以引导窄的beam search来更有效地搜索caption的空间
- fast,因为每个beam都是窄的
- diverse,因为caption根据summary会生成或多或少的形容词,从而避免生成generic的结果
因为一副图片有多个caption,直接训练可能使得系统只会产生一些含糊的caption,我们模型的目的就是生成多样的且正确的caption。
使用beam search来得到多样的caption是很慢的,且这样做通常在多样性度量上不及VAE和GAN表现的好,但VAE和GAN却在caption的度量上不及beam search
我们发现使用part of speech(POS) tag 序列是非常有效的summary,它能促使captioner在某些位置产生形容词。
本文的主要贡献是说明了使用POS tag 序列来进行image captioning可以得到fast,diverse和accurate的结果,相比beam search,它更块,更多样,且比基于GAN和VAE的方法也更多样
Approach
本文引入了POS tag序列
t
t
t,来作为RNN产生caption的条件,
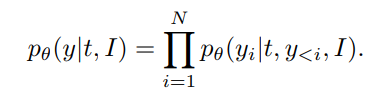
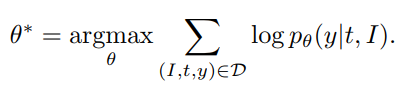
注意到其中这个
t
t
t作为了条件,这是为了在全局上控制句子的结构
给定一张测试图片 I I I,我们首先根据图片获得 k k k个quantized POS tag序列, t 1 , t 2 , . . . , t k t^1,t^2,...,t^k t1,t2,...,tk,然后我们使用LSTM来编码每个POS tag序列,编码后的POS tag序列和物体向量,image faeature以及之前的词构成输入,输入到基于卷积网络的caption网络中,然后输出下一个词
Image to Part-of-Speech Classification
获得POS tag的方法有多种:
- 手动选择
- 从数据集中选一个
- 利用图片预测一个
本文采用了第三种方法
quantizing POS tag sequences:
使用k-medoids聚类将210K种POS tag sequences聚类为1024类,并使用各类的中心作为quantized POS tag sequence,并对于一个POS tag seq
t
t
t,记
q
=
Q
(
t
)
q=\mathcal{Q}(t)
q=Q(t)为它的所属类的中心,最后的目标函数为
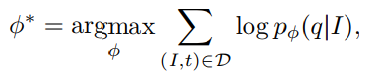
其中
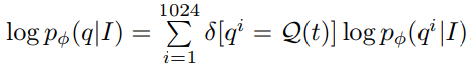
separate vs. Joint Training
训练需要找到最优的参数 θ ⋆ \theta^\star θ⋆和 ϕ ⋆ \phi^\star ϕ⋆,我们可以分别训练这两个网络,这个方法称为POS,也可以同时训练两个网络,但在同时训练时,采样的POS sequence和caption y的不兼容会引入噪声,因此在每次迭代时,我们在多个tag seq中选择一个和y对齐最好的结果,并将同时训练的方法称为POS+Joint,
Result


结论
本文致力于建立一个fast,accurate,diverse的image caption模型,利用POS tag seq进行caption生成,得到的结果既比基于VAE和GAN的模型更具多样性,也比beam search更快
问题
本文提出了传统beam search在速度和多样性上的不足,的确beam search得到的句子几乎都相差不大,为了改进,本文通过生成caption的part of speech的限制的确可以得到更快更多样的caption结果,但是我觉得这终究不是一个好的image caption的方法,限制句子中的词性是一个过于aggressive的先验信息,这大大限制了生成句子的可能性,也不符合人类描述图片的思维过程,但这也是一个比较有趣的结合先验和深度学习方法的模型,这一点也是值得借鉴和学习的















 4105
4105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









