







 本文聚焦图像描述的训练方法,指出传统方法存在exposure bias及训练与测试度量不一致的问题。提出advantage actor - critic algorithm估计per - token advantage,利用图像描述特性简化优势函数表达,使用n - step reformulated advantage function增加状态值均值、减小方差,还介绍了两种估计状态动作值函数的方法。
本文聚焦图像描述的训练方法,指出传统方法存在exposure bias及训练与测试度量不一致的问题。提出advantage actor - critic algorithm估计per - token advantage,利用图像描述特性简化优势函数表达,使用n - step reformulated advantage function增加状态值均值、减小方差,还介绍了两种估计状态动作值函数的方法。
Self-critical n-step Training for Image Captioning
时间:2019 CVPR
Intro
image caption 传统训练方法有两个问题
- exposure bias,训练的时候使用ground truth词,测试的时候使用自己预测的词,不一致的预测方法,可能导致错误累积,称为exposure bias
- 训练时以交叉熵为损失函数,测试时使用metric度量,两者的不一致性
最近的研究表表明可以使用RL来直接优化metric,从而解决第二个问题
本文提出了advantage actor-critic algorithm来估计per-token advantage,且不引入有偏差的参数值估计
本文的贡献包括
- 利用image caption的特性,我们发现了状态值函数和它之前的状态动作值函数的关系,从而简化了优势函数的表达形式
- 在简化的优势函数上,我们使用了n-step reformulated advantage function 来逐渐增加状态值函数的绝对值的均值,并减小方差
- 我们使用了两个rollout方法来估计状态动作值函数并进行self-critical训练
Methodology
使用交叉熵训练
a
t
∈
A
a_t\in A
at∈A是序列中的词,
T
T
T是序列长度,
I
I
I是图片,
I
F
I_F
IF是图片特征,最小化交叉熵
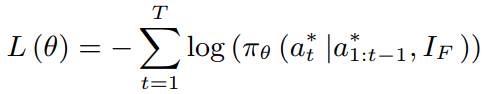
其中
π
\pi
π是概率分布函数
使用策略梯度训练
问题形式化
- 马尔科夫过程(MDP) { S , A , P , R , γ } \{S,A,P,R,\gamma\} {S,A,P,R,γ}
- agent,captioning model
- S S S,state space
- A A A,action space,字典
- P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t,a_t) P(st+1∣st,at)状态转移概率
- R ( s t , a t ) R(s_t,a_t) R(st,at)是回报函数
- γ ∈ ( 0 , 1 ] \gamma\in(0,1] γ∈(0,1]是衰减系数
agent选择一个action,就对应于生成一个token,从一个条件概率分布
π
(
a
∣
s
)
\pi(a|s)
π(a∣s)中,称为策略,策略梯度算法中,我们考虑被
θ
\theta
θ参数化的策略
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
πθ(a∣s),状态
s
t
∈
S
s_t\in S
st∈S是图片特征
I
F
I_F
IF和到目前为止的tokens/actions
{
a
0
,
a
1
,
a
2
,
.
.
.
,
a
t
−
1
}
\{a_0,a_1,a_2,...,a_{t-1}\}
{a0,a1,a2,...,at−1}:
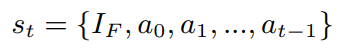
这个过程中,状态转移矩阵是确定的,因此
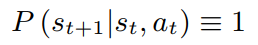
通常采取动作后,我们可以得到一个奖励值,但是在image caption问题中,奖励值只能在最终句子生成完时计算
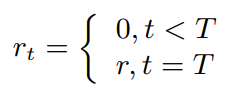
状态值函数和状态动作值函数定义如下
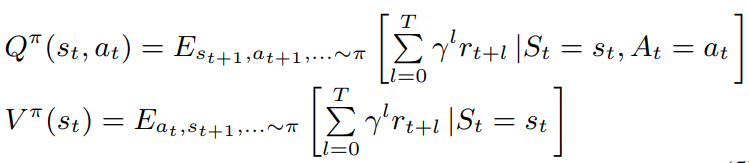
强化学习的目的是通过估计策略梯度来最大化累积回报值
V
π
(
s
0
)
=
E
π
[
∑
t
=
1
T
γ
t
−
1
r
t
]
V^\pi(s_0)=E_\pi[\sum^T_{t=1}\gamma^{t-1}r_t]
Vπ(s0)=Eπ[∑t=1Tγt−1rt],策略梯度算法中,梯度为
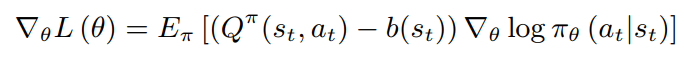
其中
b
b
b可以是任意函数,只要它不依赖
a
t
a_t
at,使用
V
s
t
π
V^\pi_{s_t}
Vstπ作为baseline,就可以得到A2C算法
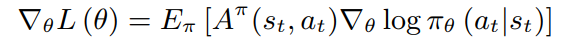
这个算法鼓励agent采用比平均动作好的动作,而抑制比平均动作差的动作
1-step reformulated advantage function,image caption是一个特殊的强化学习任务,它的状态转移矩阵是确定的,因此可以reformulate一些公式,首先
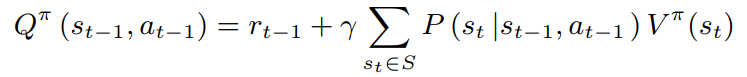
因为
P
P
P是确定的,所以
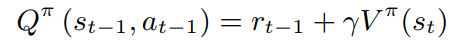
因为当
t
<
=
T
t<=T
t<=T时,
r
t
−
1
=
0
r_{t-1}=0
rt−1=0所以

从而对于
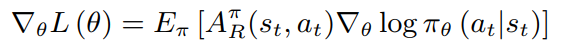
有
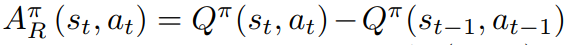
因此每个状态动作值函数用它上一步的状态动作值函数作为baseline,因此称为1-step,这个方程鼓励更大的期望累积回报,抑制少的期望累积回报
最直接的模拟环境的方法就是使用Monte Carlo 轨迹
{
(
s
t
,
a
t
,
r
t
)
}
t
=
1
T
\{(s_t,a_t,r_t)\}^T_{t=1}
{(st,at,rt)}t=1T,采样自多项分布,从而策略梯度为
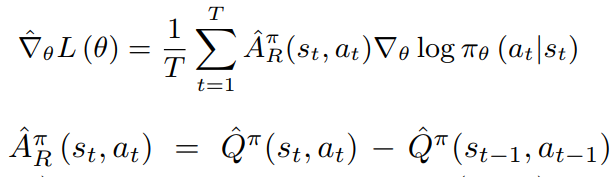
其中
Q
Q
Q是
Q
^
\hat{Q}
Q^的经验估计
n-step reformulated function,之前的两个方法,第一个方差较大,第二个会引入估计误差,因此我们使用n-step reformulated advantage function,使用n-step的优势函数
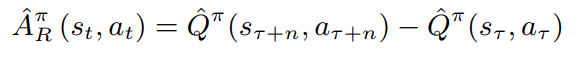
随着n的增加,per-token的优势逐渐损失了,直到
n
=
T
n=T
n=T,得到一个sequence level的损失
估计状态动作值函数,这里有两种估计方法,使用K Monte Carlo rollouts,或者使用inference algorithm,
在
K
K
K Monte Carlo rollouts中,我们以序列
{
s
t
,
a
t
}
\{s_t,a_t\}
{st,at}为起始采样
K
K
K个连续序列来得到
{
a
t
+
1
,
a
t
+
2
,
.
.
.
,
a
T
}
\{a_{t+1},a_{t+2},...,a_T\}
{at+1,at+2,...,aT},利用多项分布来采样,当
γ
=
1
\gamma=1
γ=1时,状态动作值函数可计算为
K
K
K个回报函数的均值
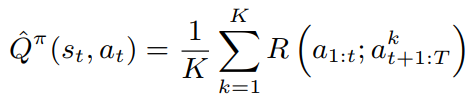
在max-probability rollout中,我们采样一个序列来得到
{
a
t
+
1
,
a
t
+
2
,
.
.
.
,
a
T
}
\{a_{t+1},a_{t+2},...,a_T\}
{at+1,at+2,...,aT},然后得到
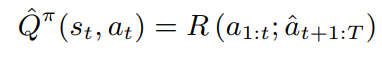
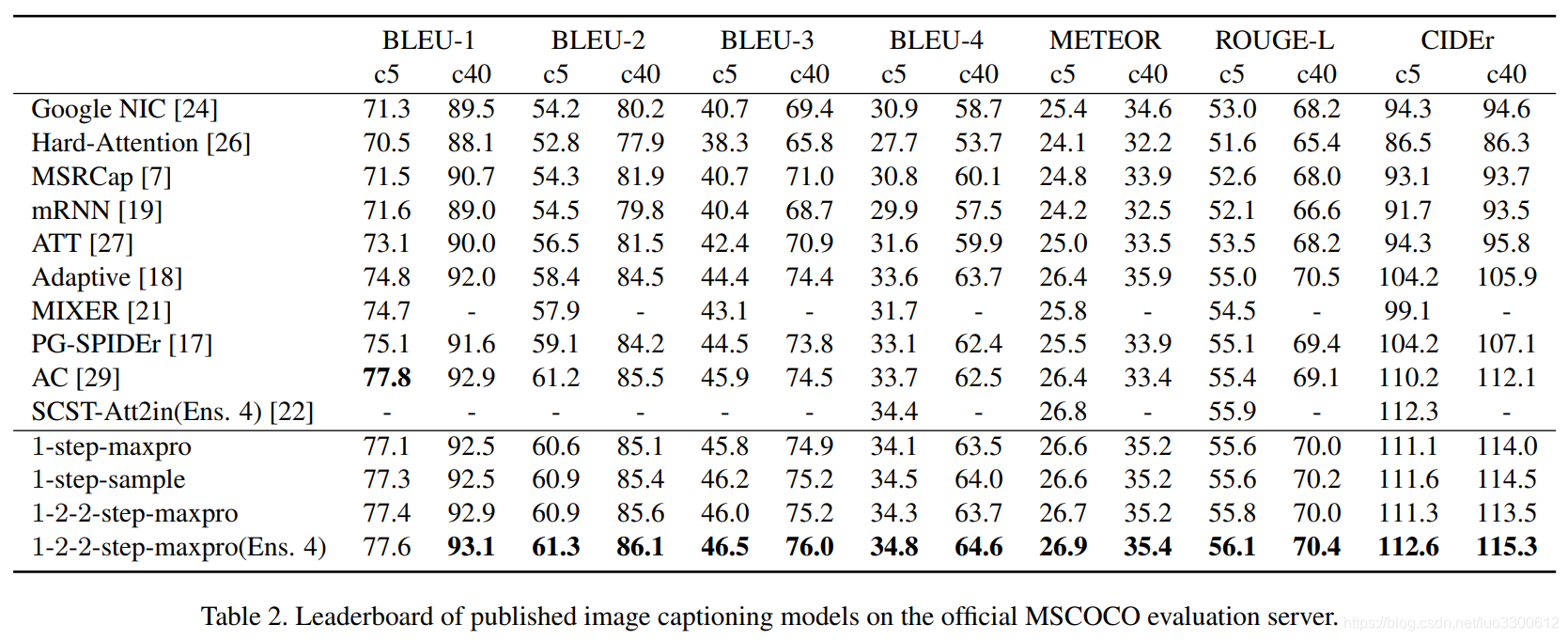
Results

结论
本文reformulate了image caption的优势函数,并提出了n-step的优势函数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









