







Look Back and Predict Forward in Image Captioning
时间:2019 CVPR
Intro
一般的attention方法单纯地使用上一个词的隐层状态来进行attention加权来得到下一个隐层状态,这种attention机制忽略了相邻词的视觉相关性,比如"a blue bike"其实是三个词表示一个物体
exposure bias的问题
为了解决这两个问题,我们提出 Look Back and Predict Forward method(LBPF),包括Look Back和Predict Forward两个部分
Method
首先,得到图片特征
V
=
{
v
1
,
v
2
,
.
.
.
,
v
k
}
,
v
i
∈
R
D
V=\{v_1,v_2,...,v_k\},v_i\in R^D
V={v1,v2,...,vk},vi∈RD,使用它们的平均
v
ˉ
\bar{v}
vˉ作为全局信息,然后使用LBPF模型作为decoder,本文的模型是基于Bottom-Up and Top-Down Attention模型的,整个模型如图所示

Look Back Model
给定
k
k
k个空间特征向量
V
=
{
v
1
,
.
.
.
,
v
k
}
∈
R
D
×
k
V=\{v_1,...,v_k\}\in R^{D\times k}
V={v1,...,vk}∈RD×k以及当前的隐藏状态
h
t
∈
R
d
h_t\in R^d
ht∈Rd,传统的注意力机制计算加权向量为
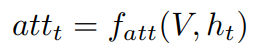
一般,加权向量最终和
h
t
h_t
ht连接起来预测下一个词,然而attention的区域应当有视觉的连贯性,且能够为之后的time step提供信息,因此我们提出了Look Back方法,来将之前的attention考虑进来,如图所示

我们使用之前的attention和隐藏状态concat起来,来计算之后的
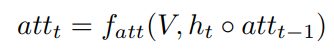
记
H
t
H_t
Ht为concat的结果,具体的,加权向量和attention向量计算为

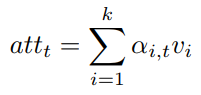
我们仅仅使用了
a
t
t
t
−
1
att_{t-1}
attt−1而没有让梯度往前传,因为这会使得模型过于复杂且难以收敛
Predict Forward Model
通常的序列生成方法中,当前的word embedding将被喂给RNN然后来生成下一个词,使得
y
t
+
1
y_{t+1}
yt+1严重依赖于
y
t
y_{t}
yt,在测试时可能导致错误的累积(exposure bias),因此我们提出了Predict Forward方法,来在一步中预测
y
t
+
1
y_{t+1}
yt+1和
y
t
+
2
y_{t+2}
yt+2,如图所示

记attention function为
f
a
t
t
f_{att}
fatt,LSTM2为
F
2
F_2
F2,则
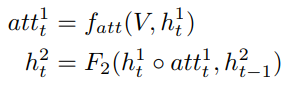

因为
h
t
2
h^2_t
ht2能直接预测
y
t
+
1
y_{t+1}
yt+1,所以我们认为它是
y
t
+
1
y_{t+1}
yt+1的一个特殊的embedding,从而能够预测下一个词,于是,
h
t
2
h_t^2
ht2继续通过Att和LSTM2得到
h
t
3
h^3_t
ht3,

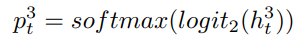
损失函数计算为

然后利用两者的和来计算最终预测的词
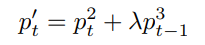
这样
y
t
+
1
y_{t+1}
yt+1就不会严重依赖
y
t
y_{t}
yt,从而减小累积错误
为了和SoTA结果进行比较,我们同时采用了SCST的训练方法,具体的是,对于一步预测的结果使用强化学习训练,对于两步学习的结果,以第一步学习的结果为标签计算交叉熵损失
Experiments


Conclusion
本文提出了Look Back来利用之前的attention信息,以及Predict Forward来预测以后的词,其动机来源于object与seq的一对多关系以及attention与seq的一对一关系的矛盾性
Idea
- 生成词的时候是一个一个生成,那可以是一个一个object短语来生成吗?
- 对于整幅图的caption来说,图片的各个proposal和caption本质上属于unpaired的数据,可以借鉴2019CVPR的几篇论文
- 本文告诉我们能提供信息的地方就能建立起连接















 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









