






在VM中首要的普遍概念就是NUMA,对于大型机器而言,内存会分成许多簇,依据簇与处理器“距离”的不同,访问不同的簇会有不同的代价。Linux中的struct pg_data_t 体现了这一概念,在UMA体系结构中亦是如此。系统中每个节点链接到一个以NULL结尾的pgdat_list 链表中。对于UMA结构的机器,只是用了一个contig_page_data 的静态pg_data_t 结构。
在内存中,每个节点被分成很多的称为管理区(zone)的块,用于表示内存中的某个范围。一个管理区由一个struct zone_struct 描述,且每个管理区的类型都是 ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM 中的一种。
系统的内存划分成大小确定的许多块,这些块也称为页面帧。每个物理页面帧由一个struct page 描述,所有的结构都存储在一个全局mem_map 数组中。
page 结构的定义如下:
Node、Zone和Page的关系用下图描述:
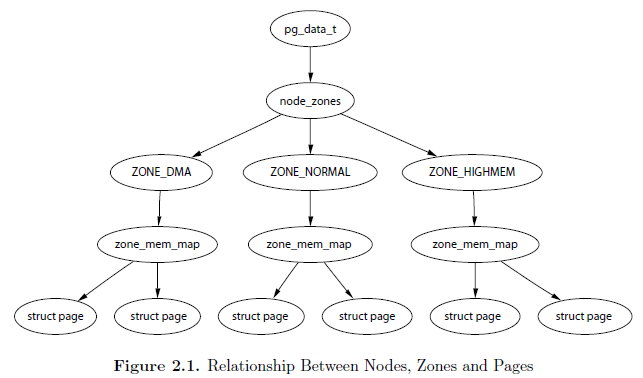
节点
pg_data_t 结构的定义如下:
typedef struct pglist_data{
zone_t node_zones[MAX_NR_ZONES];
zonelist_t node_zonelists[GFP_ZONEMASK+1];
int nr_zones;
struct page *node_mem_map;
unsigned long *valid_addr_bitmap;
struct bootmem_data *bdata;
unsigned long node_start_paddr;
unsigned long node_start_mapnr;
unsigned long node_size;
int node_id;
struct pglist_data *node_next;
}在分配一个页面时,Linux采用节点局部分配策略,从最靠近运行中的CPU的节点分配内存
node_zone:该节点的管理区:ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM
node_zonelists:按分配时管理区顺序排序。在调用free_area_init_core()时,通过build_zonelists()建立顺序
node_mem_map:指向该节点中的物理帧。它被放置在全局mem_map数组中
valid_addr_bitmap:只在Sparc和Sparc64体系结构中使用
bdata:指向内存引导程序
node_start_paddr:节点的起始物理地址
node_start_mapnr:该节点在全局mem_map中的页面偏移
node_size:该节点的页面总数
node_id:节点号,从0开始
所有节点都由一个称为pgdat_list的链表维护。这些节点都放在该链表中,均由函数init_bootmem_core()初始化节点。对该链表操作的代码段基本上如下所示:
pg_data_t *pgdat;
pgdat=pgdat_list;
do{
...
}while(pgdat=pgdat->node_next);管理区
zone_struct 结构的定义如下:
#define ZONE_DMA 0 /* <16MB */
#define ZONE_NORMAL 1 /* 16MB~896MB */
#define ZONE_HIGHMEM 2 /* >896MB */
#define MAX_NR_ZONES 3
typedef struct zone_struct {
spinlock_t lock;
unsigned long free_pages;
zone_watermarks_t watermarks[MAX_NR_ZONES];
unsigned long need_balance;
unsigned long nr_active_pages, nr_inactive_pages;
unsigned long nr_cache_pages;
free_area_t free_area[MAX_ORDER];
wait_queue_head_t *wait_table;
unsigned long wait_table_size;
unsigned long wait_table_shift;
struct pglist_data *zone_pgdat;
struct page *zone_mem_map;
unsigned long zone_start_paddr;
unsigned long zone_start_mapnr;
char *name;
unsigned long size;
unsigned long realsize;
} zone_t;free_pages:该管理区中空闲页面的总数
watermarks:保存了min、low、high这些管理区极值
need_balance:通知页面换出kswapd平衡该管理区,当可用页面的数量达到管理区极值的某一个值时,就需要平衡该管理区了
nr_active_pages:
nr_inactive_pages
nr_cache_pages
free_area:空闲区域位图,由伙伴分配器使用
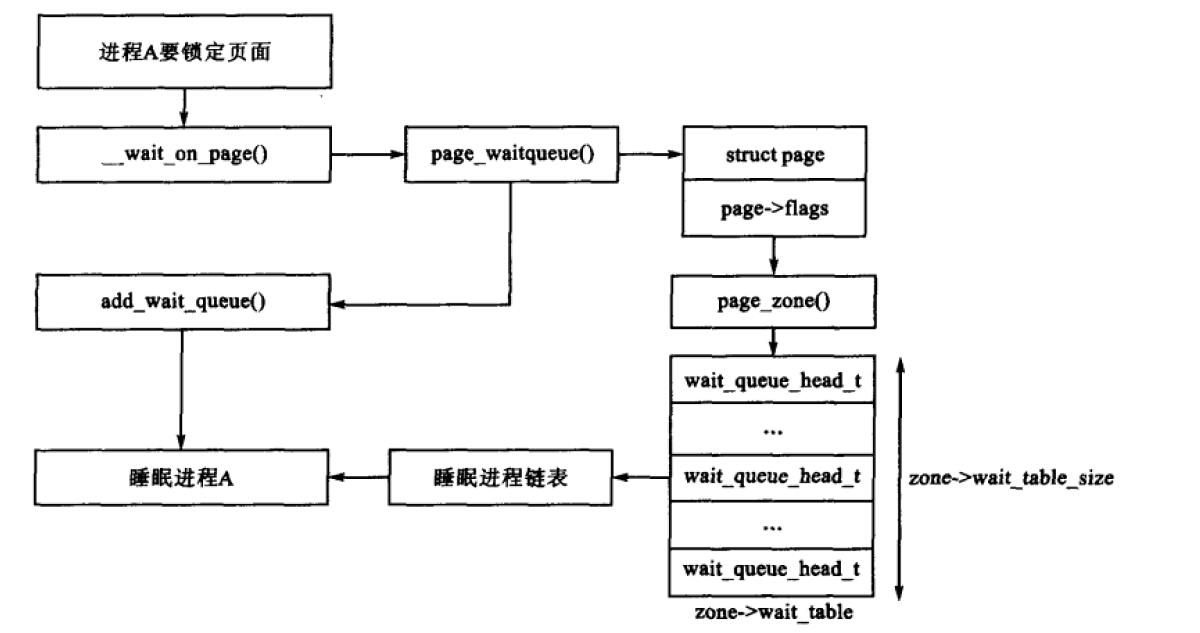
wait_table:等待队列的哈希表,该等待队列由等待页面释放的进程组成。这对wait_on_pages()和unlock_page()非常重要。虽然所有的进程都可以在一个队列中等待,但这可能会导致所有等待进程在被唤醒后,都去竞争依旧被锁的页面。大量的进程像这样去尝试竞争一个共享资源,有时被称为惊群效应
wait_table_size:该哈希表的大小,是2的幂
wait_table_shift:
zone_pgdat:指向父pg_data_t结构
zone_mem_map:涉及的管理区在全局mem_map中的第一页
size:管理区的大小
realsize
当系统的可用内存很少时,守护程序kswapd被唤醒开始释放页面。在watermarks中有管理区的三个极值,分别为min、low、high,其关系如下图所示:
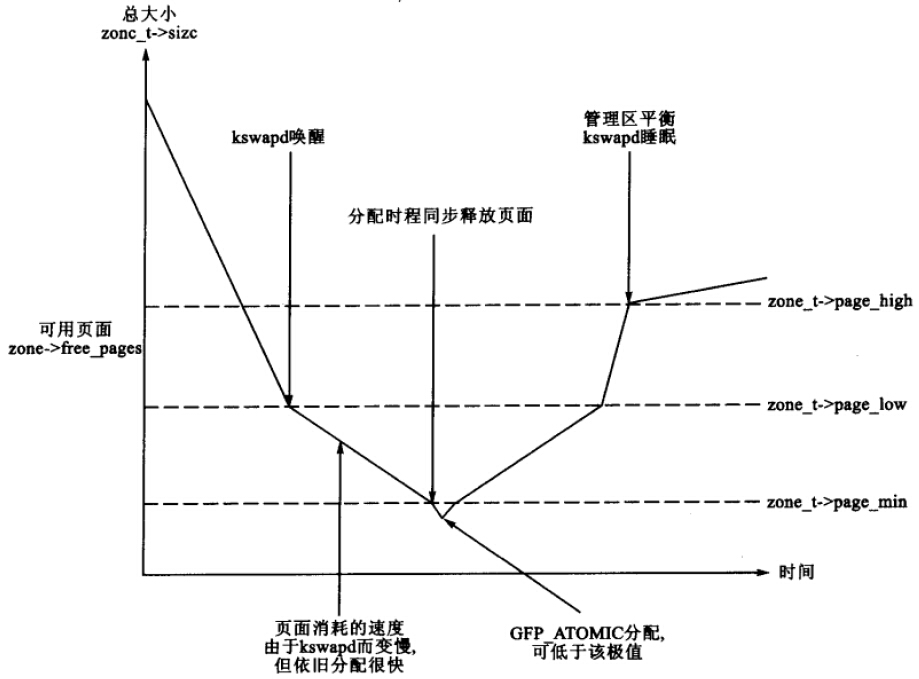
min在内存初始化阶段由函数free_area_init_core()计算出来,是基于页面的管理区大小的一个比率,low的默认值时min的两倍,high的默认值是min的三倍。
各个极值在表示内存不足时,行为互不相同:
low:空闲页面达到low时,伙伴分配器唤醒kswapd释放页面。
min:空闲页面达到min时,分配器以同步方式启动kswapd。
high:kswapd被唤醒并开始释放页面后,在high个页面被释放以前,是不会认为该管理器已经“平衡”的,当达到这个极值后,kswapd就再次睡眠。
- 计算管理区的大小:
函数:
find_max_pfn()
find_max_low_pfn()
量:
min_low_pfn:系统可获得的最小PFN,装载kernel image后的第一页
max_low_pfn:默认情况下,当物理内存大于896MB时,为896M>>12,高端区就从896MB到max_pfn结束,当物理内存小于896MB时,max_pfn=max_low_pfn,高端内存去没有页面
max_pfn:总共的物理内存数 - 管理区等待队列
等待队列的hash表在free_area_init_core()时被初始化了,它的大小通过wait_table_size()计算。等待队列最多有4096个。具体的计算公式如下
wait_table_size=NoPages⋅2PAGE_PER_WAITQUEUE−1
其中NoPages为管理区中的页面数,PAGE_PER_WAITQUEUE定义为256。
page_waitqueue()用于返回某管理区中一个页面对应的等待队列,它一般采用基于已经被哈希的虚拟地址的乘积哈希算法。一般需要用GOLDEN_RATIO_PRIME乘以该地址,并将结果右移zone_t->wait_table_shift位以得到其在哈希表中的索引结果。
管理区初始化
管理区初始化在内核页表通过paging_init()完全建立起来以后进行。
(1)UMA
在函数paging_init()中最后调用zone_sizes_init()。
zone_sizes_init()函数先计算出3个管理区的大小,zone_size[MAX_NR_ZONES],然后将zones_size作为参数传入函数free_area_init(zones_size)。
free_area_init(zones_size)函数调用free_area_init_core()函数
(2)NUMA
在函数paging_init()中调用free_area_init_node()。
free_area_init_node()函数调用free_area_init_core()函数。
核心函数free_area_init_node()用于向每个zone_t填充相关的信息,并为节点分配mem_map数组。其参数有:
nid:节点号
pgdat:节点的pg_data_t结构
pmap:在NUMA中,无效。在UMA中,pmap指向全局mem_map。
zones_size
zone_start_paddr:第一个管理区的起始物理地址
zholes_size:空洞大小
lmem_map
初始化mem_map
(1)NUMA
mem_map被处理为一个起始于PAGE_OFFSET的虚拟数组。free_area_init_node()函数被每一个节点所调用,分别分配此数组在各个节点的部分。
(2)UMA
free_area_init使用contig_page_data作为节点,并将全局mem_map作为该节点的局部mem_map。
核心函数free_area_init_core()为被初始化的节点分配一个本地lmem_map。lmem_map数组的空间通过函数alloc_bootmem_node()分配。对于UMA结构,这个新分配的内存成为全局mem_map,但对于NUMA有轻微的不同。
页面
每一个物理页框在系统中有一个关联的struct page结构体用于记录它的信息。
typedef struct page {
struct list_head list;
struct address_space *mapping;
unsigned long index;
struct page *next_hash;
atomic_t count;
unsigned long flags;
struct list_head lru;
struct page **pprev_hash;
struct buffer_head * buffers;
#if defined(CONFIG_HIGHMEM) || defined(WANT_PAGE_VIRTUAL)
void *virtual;
#endif
} mem_map_t;mapping:当文件或设备是内存映射的,他们的inode有一个关联的address_space。若本页面属于该文件,这个域指向该结构。
index:这个域有两个作用,页面所处的状态决定了它的用处。
若页面是文件映射的一部分,它是在该文件中的偏移;若页面是swap cache的一部分,它是在address_space中的偏移。
若页面内的一块数据被一个进程释放了,该数据的位置被保存在index中
next_hash
count:引用计数
flags:描述页面的状态
lru
pprev_hash
buffers
virtual
将页面映射到管理区
page->flags的高ZONE_SHIFT(x86中为8)位记录该页面所属的管理区。
zone_table是一个管理区表,在mm/page_alloc.c被定义为:
zone_t *zone_table[MAX_NR_ZONES*MAX_NR_NODES];
EXPORT_SYMBOL(zone_table);函数EXPORT_SYMBOL()使得zone_table可以被可加载模块获取到。
在free_area_init_core()函数执行过程中,在节点中的所有页面已经初始化完成。首先,它设置
zone_table[nid*MAX_NR_ZONES+j]=zone;对于每一个页面,函数
set_page_zone(page, nid*MAX_NR_ZONES+j);将zone编号存入flags中。
高端内存空间
32位x86系统中,有两个高端内存阈值:
一个是4GB,4GB的限制与32位物理地址相关。为了访问1GB到4GB的内存,内核需要使用kmap()暂时将高端地址映射到ZONE_NORMAL。
另一个是64GB,64GB同PAE相关,Intel为了允许32位系统能使用更多的RAM,使用额外的4位用于内存地址。
理论上PAE允许一个处理器寻址到64GB,但实际上Linux的进程仍不能访问那么多的内存空间,因为虚拟地址空间仍然只有4GB。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









