






这周的作业挺简单的其实,我就懒得把代码全部贴上来了,就把思路和笔记都写出来,感觉笔记更重要。
一、初始化
1、W不可以全零初始化,否则传播来传播去都是0,而b可以并且推荐全零初始化
2、直接随机数初始化b不是不可以,但是由于有可能初始化的值比较大,会导致计算的时间会偏长
3、因此最后给出的推荐的初始化w的方法是类似于xavier初始化(多乘一个2):
parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l-1]) * np.sqrt(2 / layers_dims[l-1])就是在原来随机数初始化的基础上,乘上根号下(2/前一层的单元数)
最终这种初始化同样在14000次迭代的情况下,能比直接随机数初始化更快更好地得出结果。
二、正则化(Regularization)
首先要知道正则化的目的就是为了防止过拟合。如果给我们直观的数据集,我们一眼就能看出有一些误差或者偶然性的数据,我们判断的时候肯定知道这个个例不能代表全部,但是如果我们直接用神经网络对有限的样本进行深度的学习训练,让它把数据集分类,那么它肯定很完美地完成任务,把噪音的部分也给分类了:

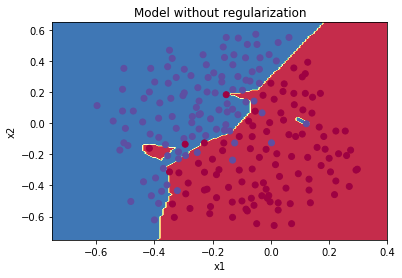
第一张图为目标数据集,第二张图就是没有正则化的训练结果
所以正则化的目的,就是为了让他能正确地给出这样的答案:
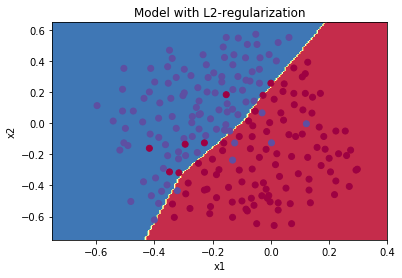
(上面的图全部都是源自课程)
以上就是正则化的介绍了,下面就是具体的正则化的内容
作业里给出了两种正则化的方法:
1、L2正则化:
代价函数中再额外加一项:(所有样本的所有W的所有元素的平方和)*lambda(控制L2正则化的一个超参数)/2m
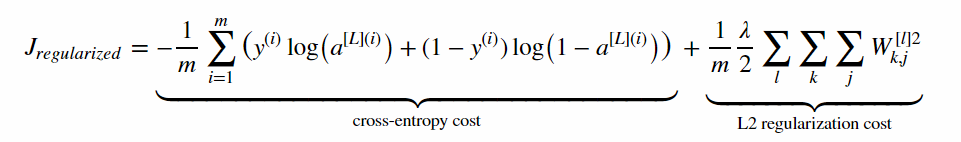
因此计算cost的时候要注意多加一项,并且反向传播的时候,这一项的导数也要算进去(直接求导就知道是W*lambda/m)
L2_regularization_cost = (np.sum(np.square(W1))+np.sum(np.square(W2))+np.sum(np.square(W3)))*(lambd*0.5/m) #作业中的W只有3个 dW3 = np.dot(dZ3, A2.T) / m + lambd*W3/m 以此类推2、Dropout(随机失活)正则化
每次训练的时候都是随机挑选单元来训练,按我理解的话就是避免整体因为记录下某个特殊的偶然的样本造成过拟合,每次都是随机几个参与训练的话,如果出错了也就那几个出错而已,在后面的随机选取里面出错的几个又分别被选到不同的样本参与训练,慢慢也能修正回来。
因此这个的重点就在前向传播时,用一个随机数并且用阈值(超参数)控制挑选的概率,然后反向传播的时候就只用选到的反向传播。
前向传播:
D1= np.random.rand(A1.shape[0],A1.shape[1]) # Step 1: 随机数初始化一个和A1一样shape的矩阵
D1= D1<keep_prob # Step 2: 用阈值控制矩阵D1,这样就能出现只有0和1的矩阵
A1=A1*D1 # Step 3: 对应元素相乘,这样就能把不要的A归零,不参与计算
A1=A1/keep_prob # Step 4: 这里是因为,由于我们把一些单元去掉了,比如去掉了一半的单元,这样的话这一层算出来的总值就会少一半,因此就除以阈值,除回去0.5,就大概保持原有的总值反向传播:
dA2=dA2*D2 # Step 1: 同理,筛选
dA2=dA2/ keep_prob # Step 2: 同理,保持总值 3、结果对比
不进行正则化:训练准确度95%;测试准确度91.5%
L2正则化:训练准确度94%;测试准确度93%
dropout:训练准确度93%;测试准确度95%
不进行正则化的神经网络学习就是虚高的准确度233过分拟合训练集的数据。
对了,dropout和L2正则化不要同时使用,选其一就好。
三、梯度检验
这个就很简单了,梯度检验是用来检验反向传播是否正确。这就是利用导数的定义,按照定义来,要求哪个变量的导数,就对它进行一个微小的变动(1*10-7次方)然后一除就能得到近似导数,通过判断他们之间的差是否小于一个特定的数(1*10-7次方)来判断你的反向传播是否正确。
具体应用的话,定义求导数的时候是分别求左导数和右导数再算,理论上是比较精确
thetaplus = theta + epsilon
thetaminus = theta - epsilon
J_plus = forward_propagation(x, thetaplus)
J_minus = forward_propagation(x, thetaminus)
gradapprox = (J_plus - J_minus) / (2 * epsilon) 最后求的时候是通过矩阵的范数来判断
grad = backward_propagation(x, theta)
numerator = np.linalg.norm(grad - gradapprox)
denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox)
difference = numerator / denominator if difference < 1e-7:
print ("The gradient is correct!")
else:
print ("The gradient is wrong!") 关键的就是这些步骤了。然后就是,用这个来代替反向传播是不现实的,太慢了。















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









