









标签(空格分隔): hadoop
转自:https://www.cnblogs.com/qingyunzong/p/8692430.html
前言
我们前面啊已经有了安装和hbase ddl 和dml的相关api操作,那么现在我们来了解下,hbase的执行原理是什么。这节我们采用看图找逻辑的形式去挨个了解下,各个环节的执行逻辑。
原理介绍
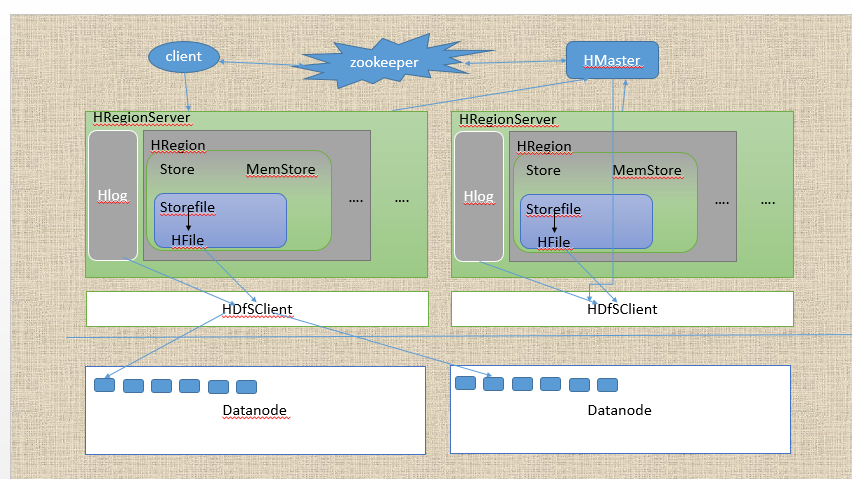
先来一张图look一下
![image_1dg23e0ri1pc510ud1rpq4csumo19.png-345.8kB][1]
我们按图索骥,分角色看看挨个介绍下对应的职责和相互间的关系。
client
client有是连接hbase和读写用的客户端,那么client有怎么读取呢。
1.我们先说下Hbase有两张特殊的表
.META.表这张表是记录我们对应的表信息存放在哪个机器的哪个Region上。该表可分裂成多个Region
-ROOT- 这张表是在0.96之前的版本有,其实就是在META之上再构建了一层索引,查询.META.的Region信息。该表只有一个Region。
2.读:client端通过zk获取到-ROOT-表的Region所在位置,之后通过-ROOT-和.META.找到对应的table所在的Region和位置,就可以进行读取到对应的数据了。另外client端会做数据缓存,增加速度嘛。
3.我们来介绍下Region的概念,Region就是存储了许多表当这些表的大小超过了一定数据后,会将数据做拆分管理,这样就分裂成了两个region。我的理解就是Region类比mysql的库,当数据超一定量后横向拆成两个库。(个人浅见,如有错误欢迎指正)。
zookeeper
我们知道zk一般做注册中心,在hbase zk的角色与职责(和其他角色的交互职责啊)。
1.我们在client中说到了,它需要记录去哪找-ROOT-表,-ROOT-表所在位置。
2.图中没有体现Hmaster是可以HA的,所以提供了Failover 机制,选举Hmaster用。
3.这里实时监控RegionServer的信息,一旦下线通知HMaster(监视器,监视家里的二哈是否在撕沙发,撕了立马报警给主人)。
4.记录table的schema信息,就是有神马表,表中有什么列族。
HMaster
1.从zk的第三条我们知道HMater有被通知RegionServer的下线,所以HMater接到通知要干什么呢,它需要根据之前的Hlog等信息,重新分配下线RegionServer上的Region,给其他的RegionServer,并做信息还原。
2.其实跟1类似,它需要给RegionServer分配Region。
3.zk的第四条,schema信息,需要通过HMaster去维护。
4.1,2中的分配其实是根据一定算法去分配的,也就是说HMaster需要去考虑负载,所以它有负载均衡的功能。
5.Hdfs上的文件垃圾回收(hbase),后续会介绍到文件的压缩。
HRegionServer
1.既然HMaster给它分配了Region,那HRegionServer就需要处理这些Region的请求。
2.HRegionServer包含多个HRegion,我们看下啊,client请求中涉及到的.META.的表做Region信息的记录用于client的查找,那么.META.信息得在什么时候变更呢,就是当HRegion到达一定量之后,人家需要splict和compact 分裂和压缩,这个是Hregionserver的职责。既然需要splict那就需要用Hmaster做分配,需要记录.META.信息等。结合master的职责我们可以发现,client端寻址的过程中都涉及不到HMaster,在Hregion膨胀了才会用到(所以,我们常说的Hmaster死一段时间就死了,我们的读写还是可以正常的操作影响不大),还有就是DDL语言涉及到table的定义也会用到。
HRegion
看图我们知道RegionServer有多个Region。我们来看下Region的职责,每个table在行的方向上会拆分为多个Regin(区域),一般一个table是一个region,但是当table的某个列族达到一个阀值的时候,region就会splict两个新的Region。这个region信息会存储在-ROOT-表和.META.表上。每个region由以下信息标识:< 表名,startRowkey,创建时间>,由目录表(-ROOT-和.META.)记录该region的endRowkey。
Store
我们看完了Hregion看看Region的Store,Region是由1至多个Store组成滴。每个Store其实就是一个table的ColumnFamily组成给的,所以Store可能有多个,其中Store由一个MemStore和0至多个StoreFile组成。(0至多个就是有没有序列化,还没开始序列化就是0个)。
MemStore
从命名来看就知道是内存版本的store,用于存储数据(keyvalues)在内存中,当达到阀值(默认128M)就会有线程完成flush到文件生成快照。
storefile
从memstore中flush的数据文件就是storefile,底层是hfile来保存的。说一下storefile是0到多个的图中画的少了… 将就看下。
hfile
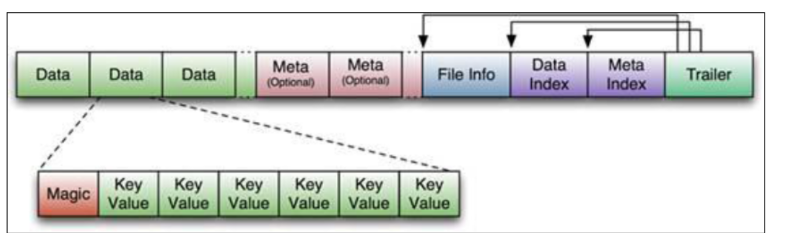
hfile是hadoop的二进制文件,storefile是其的包装类,是hbase keyvalues的存储格式。
![image_1dg2efuh81hdr10lm94q1uh21k5d1m.png-122.1kB][2]
上图是hfile的保存再hdfs上的数据格式。
有以下几个元素需要解释下:
data block: 存储数据的block快,可以被压缩。
meta block:保存用户自定义的kv对,可被压缩。
file info:就是元信息,不可被压缩
data index: 就是data block的索引,通过其可以达到快速查找的目的
meta index: 顾名思义就是meta block的索引。
trailer :用于跟踪,保存每个段的其实位置,我们通过这个文件获取其实位置,再加载data index就可以快速的查找到需要的信息了。
Hlog
Hlog(wal) write ahead log 是用于灾备用的。类似mysql中的binlog。Hlog其实就是Hadoop中的普通sequence file ,当其值是key的时候就是Hlogkey对象,这个对象包含了sequence number和timestamp,value就是hfile中的keyvalues。
关于寻址
寻址的逻辑有两种,是在HBase-0.96这个版本做分水岭的,之前的寻址方式有-ROOT-表,之后的寻址方式木有这个表。
第 1 步:Client 请求 ZooKeeper 获得-ROOT-所在的 RegionServer 地址
第 2 步:Client 请求-ROOT-所在的 RS 地址,获取.META.表的地址,Client 会将-ROOT-的相关 信息 cache 下来,以便下一次快速访问
第 3 步:Client 请求.META.表的 RegionServer 地址,获取访问数据所在 RegionServer 的地址, Client 会将.META.的相关信息 cache 下来,以便下一次快速访问
第 4 步:Client 请求访问数据所在 RegionServer 的地址,获取对应的数据
这个是有原因的,我们按一个region为128M来算,一各meta信息1kb来算,那么我们坐下除法会为131072 = 2^17, ,再乘以每个meta信息就是一个region一个region128M,别忘了.META.表是可以有多个Region的,所以集群的数据是PB级别的。
所以之后的流程就少了一个-ROOT-查询的流程。
hbase的读写流程
hbase读流程
1、客户端通过 ZooKeeper 以及-ROOT-表和.META.表找到目标数据所在的 RegionServer(就是 数据所在的 Region 的主机地址)
2、联系 RegionServer 查询目标数据
3、RegionServer 定位到目标数据所在的 Region,发出查询请求
4、Region 先在 Memstore 中查找,命中则返回
5、如果在 Memstore 中找不到,则在 Storefile 中扫描 为了能快速的判断要查询的数据在不在这个 StoreFile 中,应用了 BloomFilter(其实就是一个用位图和hash结合的一个大的hashmap,用于判定当前这个数据是否存在)。
hbase写流程
1、Client 先根据 RowKey 找到对应的 Region 所在的 RegionServer
2、Client 向 RegionServer 提交写请求
3、RegionServer 找到目标 Region
4、Region 检查数据是否与 Schema 一致
5、如果客户端没有指定版本,则获取当前系统时间作为数据版本
6、将更新写入 WAL Log
7、将更新写入 Memstore
8、判断 Memstore 的是否需要 flush 为 StoreFile 文件。
因为写的过程中,直接是进内存的,而读的过程是由可能走文件的所以写比读快,另外在我理解rowkey找region与之前的读数据其实一致都需要判定到哪个region,而且client端还有缓存。
这里介绍些压缩和分裂流程:
当memstore写入的文件达到4个的时候,会合并文件会去合并之前的一些版本垃圾数据,当合并完之后,达到设定值加入256之后,HRegion达到阀值,会进行splict。
[1]: http://static.zybuluo.com/luochengyue/pdkr1edi39f5x0asapu9rvpb/image_1dg23e0ri1pc510ud1rpq4csumo19.png
[2]: http://static.zybuluo.com/luochengyue/frp9xo92506o713cge361laj/image_1dg2efuh81hdr10lm94q1uh21k5d1m.png















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}