







 本文详细介绍了openlava服务器集群管理系统在集成电路设计中的应用,包括基本命令、配置策略、机器监控、用户信息展示以及自研工具的开发。重点讲解了配置队列以提高资源利用率,以及如何通过定制工具提升用户体验和数据分析效率。
本文详细介绍了openlava服务器集群管理系统在集成电路设计中的应用,包括基本命令、配置策略、机器监控、用户信息展示以及自研工具的开发。重点讲解了配置队列以提高资源利用率,以及如何通过定制工具提升用户体验和数据分析效率。
出于并行运算和负载均衡的需求,服务器集群管理系统在集成电路设计的各个流程均中具有重要应用(试想,验证跑个 regression,如何做到几万个 test case 并行?)。
现在主流的服务器集群管理系统包括 lsf,openlava,SkyForm,三者都属于 lsf 一系。lsf 是 IBM 公司开发的服务器集群管理系统,性能优异,且有商业支持,平台组件丰富,十分易用,唯一的问题就是价格昂贵。openlava 是兼容 lsf 的开源软件,最终版本为 openlava4.0,相当于早期的 lsf,其主要的用法和功能类似于 lsf,因而 lsf 用户基本可以无缝切换到 openlava,并且它开源免费免费,受到广大 IC 厂商的欢迎。SkyForm 脱胎于 openlava,后来经过天云软件的重新开发,也避免了重用 IBM 原始代码的侵权问题,其用法兼容 lsf 和 openlava,有商业支持,平台组件丰富,收费(价格应该不太贵,没有咨询过),属于一种折中的选择。
由于 lsf 和 SkyForm 收费,考虑到国内 IC 公司一贯勤俭节约的传统,openlava 的用户体量应该是最大的,所以本文主要针对 openlava 来讲,其它服务器集群管理系统有共通之处。
对 IC-CAD 工程师而言,对 openlava 需要关注一下几点。
1. openlava 基本命令
2. openlava 配置。
3. 硬件状况采集,机器 / 服务异常报警。
4. 针对用户的 openlava 状态(job/host/queue)信息展示系统(最好为 GUI 界面工具或者网页,lsf 的收费信息展示系统为网页)
5. 基本数据采集、存储、分析,通过更多个性化的插件化工具辅助将 openlava 的应用效率和便捷性提升到更高的层次。
1. openlava 基本命令
| Basic Command | Usage |
| bsub | Submits a batch job to openlava |
| bjobs | See the status of jobs in the LSF queue |
| bkill | Kill a running job (’bkill 0’ kills all the job one user submits) |
| bqueues | Displays information about queues |
| bhosts | Displays hosts and their job condition. |
| lshosts | Display hosts and their resource condition (cpu/memory). |
| lsload | Display host and their load condition (cpu/memory). |
•bsub
%bsub -o [fileName] : Save bsub standard output into the log file (for debug).
%bsub -e [fileName] : Save bsub standard error into the log file (for debug).
%bsub -n [number] : Occupied specified number of processor to run the job.
%bsub -q [queueName] : Run the job on the specified queue.
%bsub -m [hostName] : Run the job on the specified host.
%bsub -P [projectName] : Declare which project the job is for.
%bsub -Is : Submit a batch interactive job and creates a terminal with shell mode
Be sure to use this option if you want to start up application with GUI
%bsub -R : Runs the job on a host that meets the specified resource requirements
For more detailed information, please check “man bsub”
Some examples.
====
- Job need 4 cpu slots, every slot need 100G memory (Total 4*100=400G memory).
任务属于项目 PJ123,需要 4 个 cpu 核,为每个核预占 100G 内存(内存默认按照 cpu 核分配,而不是按照 job 分配),总体预留 400G 内存。
bsub -P PJ123 -n 4 -R "rusage[mem=100000]" "COMMAND"
2. Job need 4 cpu slots, and the 4 slots must be on the same host.
任务属于项目 PJ123,需要 4 个 cpu 核,且要求 4 个核在同一台机器上(在设置了 “span [hosts=1]” 的前提下,机器上总共剩余 100G 内存任务即可投递成功)
bsub -P PJ123 -n 4 -R "span[hosts=1] rusage[mem=100000]" "COMMAND"
3. Submit job into pd queue, select the hosts who have 500G+ memory, 100G+ swap, 100G+ tmp.
任务属于项目 PJ123,需要投递到 pd 队列,要求投递的机器剩余内存大于 500G,剩余 swap 大于 100G,剩余 tmp 空间大于 100G。(select 能够选择当前满足条件的机器,但是不能预占机器上的资源,用 rusage 预占资源)
bsub -P PJ123 -q pd -R "select[mem>=500000 && swap>=100000 && tmp>=100000]" "COMMAND"
4. Submit job into pd queue, need 8 cpu slots, reserve 100G memory, 100G swap, select the hosts who have 100G+ tmp.
任务属于项目 PJ123,需要投递到 pd 队列,需要 8 个 cpu 核,选择 tmp 空间大于 100G 的机器,预占 100G 内存和 100Gswap。
bsub -P PJ123 -q pd -n 8 -R "rusage[mem=100000:swap=100000] select[tmp>=100000]" "COMMAND"
====
•bjobs
% bjobs : Display job list of current user
% bjobs -UF [jobId] : Display the detailed job information.
You can get job PEND reason and job memory/swqp usage with this command.
•bkill
% bkill -r [jobId] : Kill specified job by force.
% bkill 0 : Kill all the jobs.
•bqueues
% bqueues : Display job conditions on all queues.
Job limitation, total job number, RUN job number, pend job number, SUSP job number.
•bhosts
% bhosts : Displays hosts and their job condition.
Max job limitation, total job number, RUN job number, pend job number, SUSP job number.
•lshosts
% bhosts : Display hosts and their resource condition (cpu/memory).
cpu/memory/swp resource.
•lsload
% bhosts : Display host and their load condition (cpu/memory).
cpu/memory/swp/tmp load.
2. openlava 配置策略
2.1 基础配置
openlava 配置的核心是 lsb.queues,也就是队列的配置。
先看一个基本的队列设置。
Begin Queue
QUEUE_NAME = normal 队列名称
FAIRSHARE = USER_SHARES[[default,1]] 竞争策略
UJOB_LIMIT = 48 每个用户最大可用 slot 的数目
RUNLIMIT = 168:0 job 最长运行时间限制,单位为 小时:分钟
QJOB_LIMIT = 1500 queue 中最大 job 运行数目限制
HOSTS = normal 队列中机器设置(此处 normal 为 host 组的名称)
DESCRIPTION = Default queue, for normal jobs. 队列描述
End Queue
其中需要注意以下几点:
UJOB_LIMIT 的数值必须合理配置,太小容易造成 queue 中运行的 job 的数目过少,浪费资源,太大则容易造成用户可运行 job 数目太多而快速吃光资源,导致后提交任务的用户总是得不到资源而使 job 处于 PEND 的状态。
FAIRSHARE 用于定义用户新提交的 job 之间的竞争策略,示例中的设置意为,在 queue 负载全满的情况下,所有用户公平竞争,即无论每个用户 PEND 的 job 数目有多少,当有新的 resource 空余出来的时候,所有用户之间公平分配空闲 resource。
HOSTS 部分可以直接定义 host 的名字列标,也可以仅表示 host group name,然后在 lsb.hosts 中定义 host group name 对应的具体的 host name,这样配置更加灵活。示例中采用后者。
2.2 配置策略
按照 job RUNLIMIT(运行时间限制)的区分,建议分出 3 个队列,short/normal/long。short 一般用于运行短时就能完成的 job,RUNLIMIT 很短(比如一天);normal 属于默认队列,RUNLIMIT 中等(比如一周);long 属于运行超长时间的 job(至少一个月,也可以设成更长甚至无时间限制),为了防着用户滥用 long 队列,其 UJOB_LIMIT 需要设置的较小。
按照机器资源也可以分出一些特殊队列,比如有些 EDA 工具需要大量的 cpu,但是对 memory 不敏感,比如 regression,那么可以把 cpu 核数很高的机器分到一个单独队列。有些 EDA 工具需要极大的内存,但是对 cpu 数目要求不高,比如后端工具,可以把 memory 极大地机器分到一个队列。
按照 IC 设计的 flow 也可以分出一些特殊队列。不同 IC 设计流程所需要的运算资源也不一样。比如验证的 regression 需要极大量的 slots,但是 memory 需求不高,而且 job 的运算时间一般较短,所以可以把多 cpu 核数的机器单列一个 regression 的队列;比如后端的工具需要 slot 不多,但是对 memory 需求极大,而且运行时间往往也很长,可以把大内存机器单列一个 pd 的队列。
队列设置的整体思路是:
* 为提高机器利用率的话,队列中尽量采用共享机器。
* 特殊应用,尤其是对资源需求比较大的,为保证效率一般设置队列采用专有机器。
* 如果队列需要接收 job 的时候必须有运算资源,不得不预留一部分专有机器,但是这样有可能会造成一定程度的资源浪费,所以专有机器的数量要控制到合适范围。
* 尽量要预留一部分机动机器,以防备紧急任务没有资源可以调用。
* opelnava 队列的调整策略是一个动态的过程,需要根据 IC 设计运算需求动态调整。
3. 机器状态监控
openlava 的机器需要进行状态监控以防备以下两种异常情况。
* 机器状态异常,比如机器宕机或者网络断线。
* 机器上服务异常,比如 openlava 的 LIM 进程或者 BSD 进程异常中断。
这两种异常都会影响服务器上运行着的 job,同时会减少可用算力,所以需要及时发现,及时解决。一般来说 zabbix 等 IT 运维管理软件就可以实现基础的机器 / 服务状态监控。
另外还有一些更加个性化的监控需求。比如当整的 openlava 队列资源使用率超过 80% 的时候,由于队列设置的原因,一般用户就能明显感觉到 job 投递困难,任务运行缓慢,openlava 的维护者需要能够及时发现这种状况,这样的个性需求可能就需要 CAD 自己开发一些定制化的监控工具来实现。
4. openlava 用户端信息展示系统
由于大多数 ICer 用户都是 openlava 小白,很难要求他们系统地了解 openlava 的各种命令以获取整体状况,包括 job/host/queue,所以一些(图形化)的辅助工具会比较易用。
lsf 有提供网页版的系统展示和信息查询平台(收费,功能比较 common)。openlava 本身没有配套的信息展示平台,但是可以按照企业需求定制化研发信息展示工具,也可以采用开源工具 openlavaMonitor,其包括数据采集和数据展示部分,能够满足基本的企业需求。
openlavaMonitor 的说明见 https://my.oschina.net/liyanqing/blog/1843744,github 下载地址为 https://github.com/liyanqing1987/openlavaMonitor,下面做简要说明,供大家参考。
openlavaMonitor 采集 job/host/load/queue/user 信息,采用 sqlite3 存储数据,采用 PyQt5 编写的图形展示界面,采用 matplotlib 绘制二维图表,其主要展示信息如下所示。
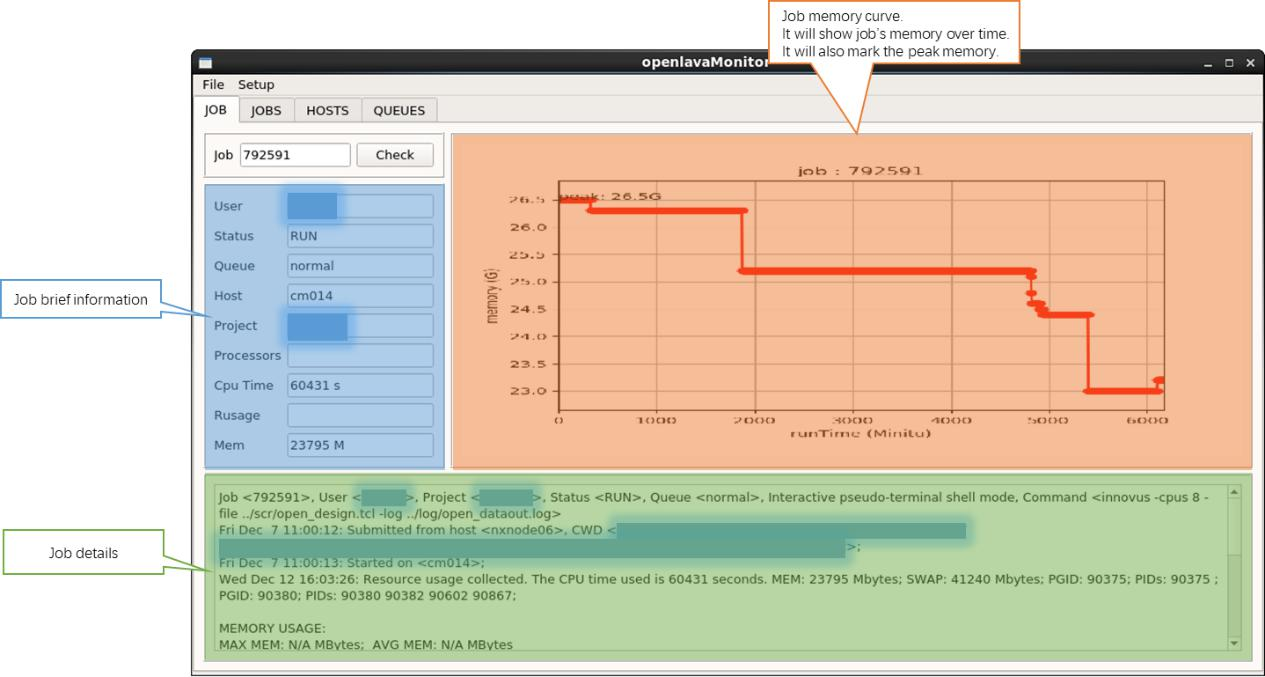
图 1 openlavaMonitor job 信息展示界面
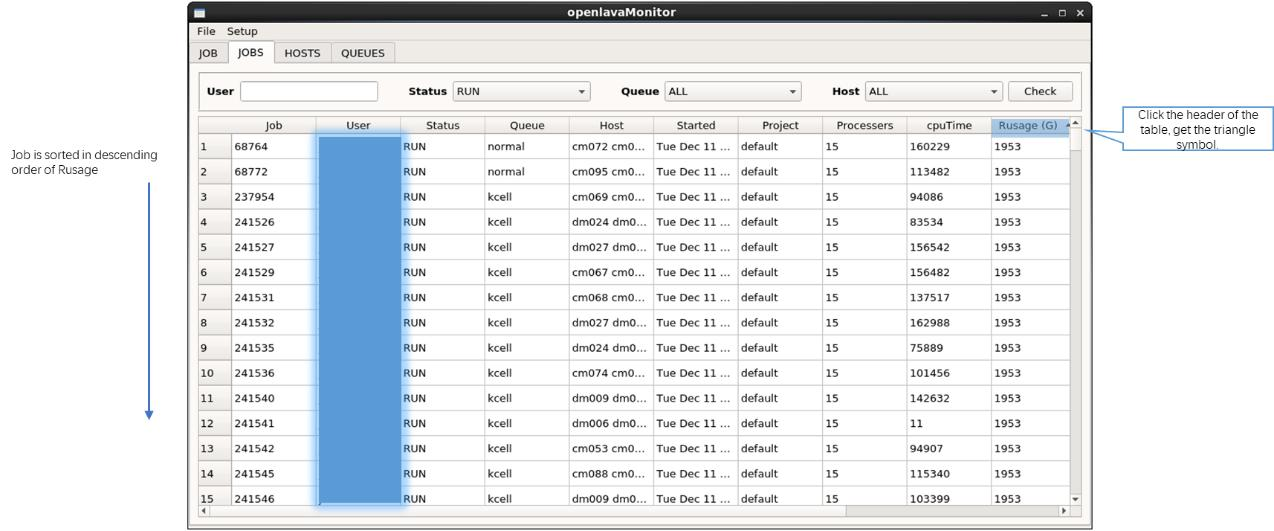
图 2 openlavaMonitor jobs 信息展示界面
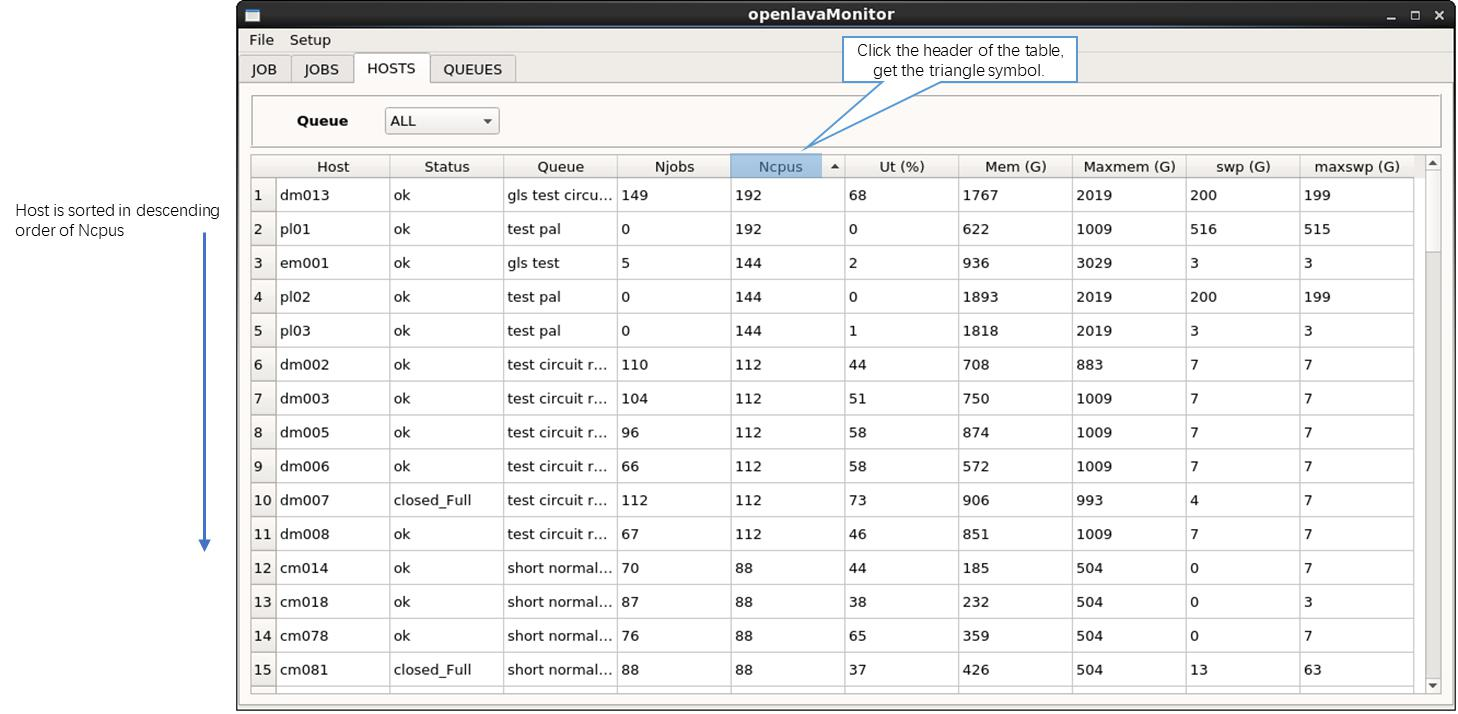
图 3 openlavaMonitor hosts 信息展示界面
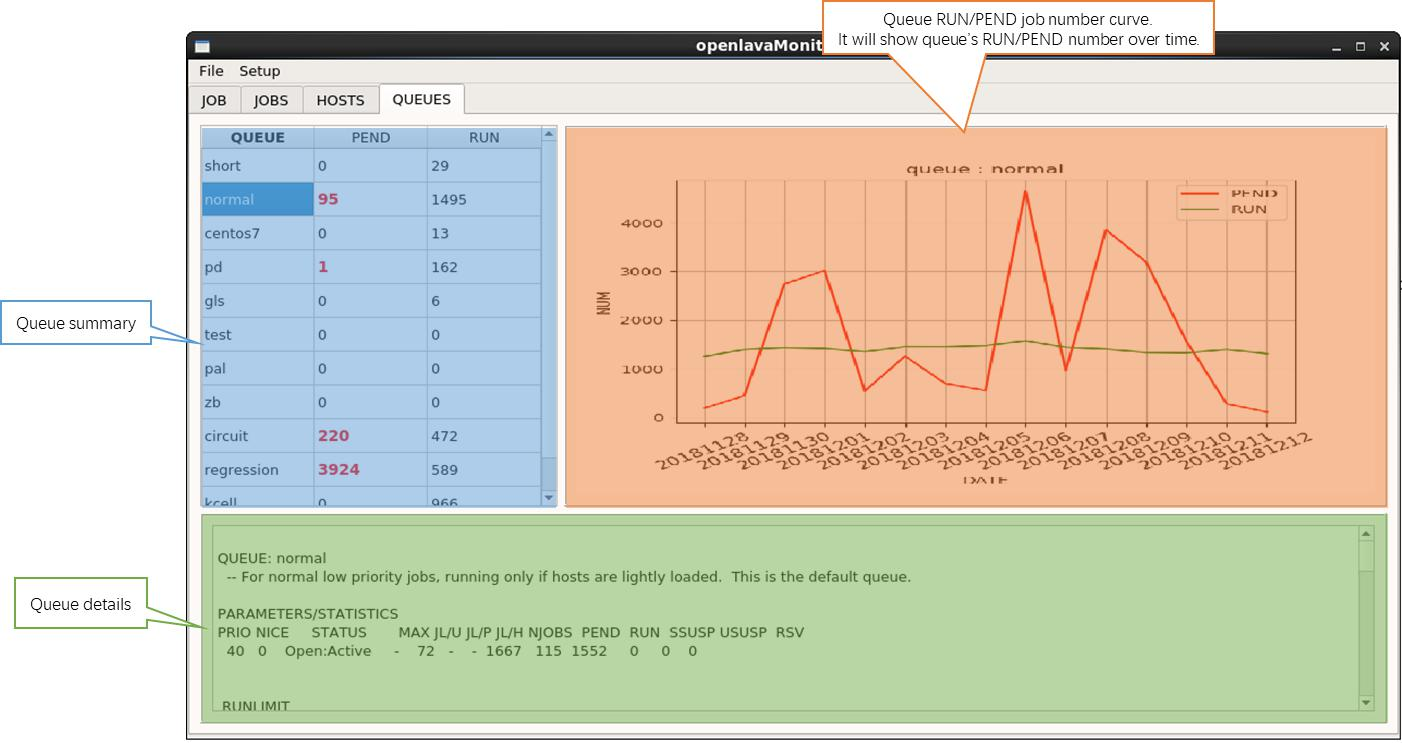
图 4 openlavaMonitor queues 信息展示界面
这个工具可以满足用户如下基本的 openlava 信息获取需求。
* job 基本信息,包括 job 生命周期内内存使用状况(如果 job EXIT,可以分析是不是 memory 使用过量导致的 job 失败)。
* jobs 的基本信息,可以查看所有的 job,也可以按照 user/status/queue/host 选择 jobs。
* hosts 的基本信息,包括 host 的状况,所属 queue,核数,job 数目,cpu/memory/swap 等资源总量和使用量。
* queues 的基本信息,包括 15 天内指定 queue 的 RUN/PEND job 数目变化趋势,用于判断 queueu 间的负载变化情况。
5. openlava 自研工具
为了更加高效地利用利用 openlava 系统,提升机器资源使用率,提升用户使用便捷程度,以及通过大数据分析得到 IC 相关数据(比如项目资源使用量分析,比如 user 工作量分析),还可以通过自研工具,通过 openlava 的数据采集以及数据分析得到。
以下是一些研发方向,按照企业实际需求仅供参考。
* 采集分析 host/queue 的资源使用情况,动态调整 queue-host 设置以进一步提高整体的资源使用率,避免资源浪费。
* 采集分析 user 的任务运行情况(工作量分析)。
* 采集分析 project 相关数据(分析项目资源消耗量)。
* 采集分析所有 job 的资源申请设置以及实际的资源使用情况,得到 job 设置失误程度,通过分析数据,有目的地指导用户合理设置 bsub 指令,合理使用 openlava 系统。
* 直接开发顶层脚本 esub(作为 bsub wrapper 的一种统称),通过数据分析以智能地替代人工经验,提高用户使用便捷度(比如 esub 自动为 bsub 任务添加 project 等标签,自动根据历史记录设置 cpu/memory/swap 等资源请求,通过分析历史记录预估正在运行 job 的运行时间等,从而让用户使用 openlava 更加简易便捷)。
备注:
提供一些干货,下面是一些 openlava 已知问题及解决方法
1. 在使用交互模式时,有些 EDA 工具的输出会出现折行,错行等现象。
这多半是由于运行机器和显示机器显示长宽设置不一致导致的,这属于 openlava 的已知 bug,最终版本(4.0)中没有修复。部分工具的解决方式如下。
1.1 对 dc_shell/pt_shell 而言
如果是在 csh/tcsh 中,执行以下命令。
setenv LINES; unsetenv COLUMNS; setenv LINES `tput lines`; setenv COLUMNS `tput cols`
如果是在 bash 中,执行以下命令。
unset LINES; unset COLUMNS; export LINES=`tput lines`; export COLUMNS=`tput cols`
1.2 对 innovus 而言
执行以下命令
stty columns 279 (tput cols >> 279)
stty rows 25 (tput lines >> 25)
或者在 innovus 中输入长命令时手工用 “\” 换行。
2. 饱和式 job 投递导致 openlava 相应减缓,甚至无 jobid 可用
有时候 openlava 中 bsub job 失败,说没有 jobid 可用,我们在 mbatchd.log.<master> 中可以看到如下警告信息。
Feb 17 02:51:26.139054 47716 3 40 getNextJobId(): Too many jobs in the system; can't accept any new job for the moment
这个信息产生的根源是,openlava 默认会保留一段时间的 job 信息(包括所有未完成的 job 和一段时间内已完成的 job,用于 bjobs -a 或者 bhists 等命令查看),信息存储周期有 lsb.params 中的参数 CLEAN_PERIOD 来决定(默认完成的 job,信息保存一个小时)。如果 CLEAN_PERIOD 时间内完成的 job 和所有未完成的 job 数目之和超过了 openlava MAX_JOBID 的数值,就会导致 openlava 没有可用的 jobid,从而导致新的 job 无法投递。
这个问题的解决方法如下:
1. 增大 lsb.params 中的参数 MAX_JOBID 的值。(这只是个临时解决方法)
2. 减小 CLEAN_PERIOD 的值到合适的时间范围。(保存太长时间的 job 信息,难免导致可用 jobid 不足)
3. 查看下有无 user 大量投递 job 的现象(这就类似于黑客的饱和攻击啊),如果有,暂停起大量投递 job 的行为。
我们遇到过一个实际的案例,用户无法投递新的 job,报告没有 jobid 可用,同时执行 bhosts 等反应极其缓慢。后来最终发现是有用户执行脚本在不停地投递 job,18 小时内投递了 130 万个 job,导致了 jobid 用光。后来解决方案就是关掉用户的脚本,kill 掉无效 job,减小 CLEAN_PERIOD 的值(从 5 天缩减到 1 天),重启 openlava 服务让其删除多余 jobid 信息,然后 openlava 就恢复正常了。
3. lsbatch 目录被写满导致 openlava 无响应
openlava 的配置文件 lsb.params 中 “JOB_SPOOL_DIR” 参数用于控制 openlava job 的 cmd 和 stdout/stderr 临时文件保存路径,当这个目录磁盘使用量超限以后,cmd 和 stdout/stderr 的文件会产生在 bsub 执行主机上的 /tmp 目录下,如果文件尺寸过大,占满了 /tmp 路径,就会影响机器上所有进程的运行。
openlava log 存储目录占满,openlava master/slave 机器 tmp 空间占满,都会导致 openlava 响应速度减慢。
4. 防火墙开启导致 openlava master 机器 bmatchd 进程通讯阻塞
网络防火墙开启有可能影响 openlava 进程通讯,减缓响应速度。
5. openlava debug 设置会导致 sbatchd 进程异常
下述 openlava 的 debug setting 会导致 openlava slave 机器上 sbatchd 服务异常。
lsf.conf
========
LSF_LOG_MASK=LOG_DEBUG3
LSF_DEBUG_RES=...
LSB_DEBUG_SBD=...
LSF_DEBUG_LIM=...
========

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









