






上一篇《字符编码发展史5 — UTF-16和UTF-32》我们讲解了UTF-16和UTF-32编码。本篇我们将继续讲解字符编码中的字节序标记(BOM)。
2.3. 第三个阶段 国际化
2.3.2. Unicode的编码方式
2.3.2.5. BOM
1. 什么是BOM?
BOM是Byte Order Mark的缩写,翻译成中文是:字节序标记,主要用于文本编码中,表示数据存储的字节顺序。
前面我们讲到UTF-16和UTF-32是存在大小端的字节序问题的。以UTF-16为例,要识别一个文件是以大端(Big-endian)字节序还是小端(Little-endian)字节序存储的,就需要有一个标识来进行标记。业界统一的做法是:在文件的开头加入一个特殊的字符来表示,该字符就是U+FEFF,因此BOM也可认为是该字符(U+FEFF)的一个别名。
- 在UTF-16BE文件中,BOM是
0xFE 0xFF; - 在UTF-16LE文件中,BOM是
0xFF 0xFE; - 在UTF-32BE文件中,BOM是
0x00 0x00 0xFE 0xFF; - 在UTF-32LE文件中,BOM是
0xFF 0xFE 0x00 0x00。
2. Windows下为什么会有UTF-8和UTF-8BOM?
UTF-8编码本身并不存在字节序的问题,所以UTF-8编码理论上是不需要字节序的。
熟悉Windows的同学应该知道,Windows的“记事本”在保存时可以选择编码方式,编码方式的下拉框里有UTF-8和UTF-8 BOM。我们以UTF-8 BOM保存时,文件的开头三个字节是0xEF 0xBB 0xBF,这就是UTF-8 BOM的标识。
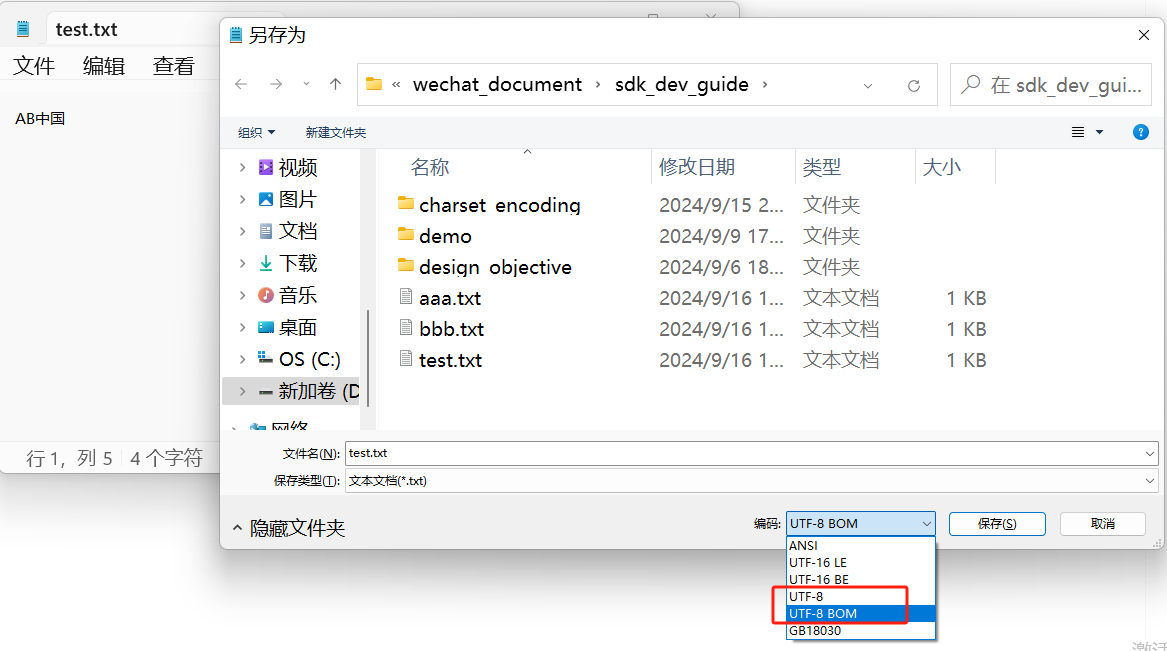 记事本保存的编码格式
记事本保存的编码格式
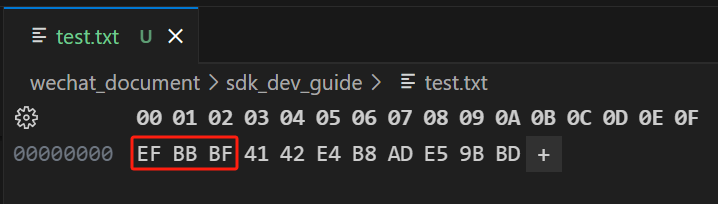 在VSCode中以
在VSCode中以Hex Editor方式打开
为什么Windows下为什么有UTF-8 BOM,这个已经无从查证,很可能是Windows历史发展的遗留产物。猜测可能是为了明确标识某个文件是由UTF-8编码方式存储的。因为字符编码的发展历史来看,UTF-8的出现晚于ANSI系列编码,Windows早期为了适配各个国家的语言,系统默认编码采用了ANSI系列的编码,美国和西欧地区默认编码是ISO-8859-1,中国大陆默认编码编码是GBK。如:在Windows下有一个XXX.txt的纯文本文件,如果不加字节序标记则无法知道这个文件是UTF-8编码的还是GBK编码的。如果UTF-8编码的文件默认加上BOM标识,则可以通过这个标识来区分是UTF-8还是GBK编码。
在Windows11下,我们看到新建的.txt文件,windows的记事本会默认以UTF-8(无BOM)来保存了,说明Windows操作系统新的版本也默认使用UTF-8编码了。
就跨平台的兼容性而言,UTF-8会比UTF-8 BOM更好。
3. 不同编码的字节序总结
| 编码方式 | BOM字节序标识 |
|---|---|
| UTF-8 | 无 |
| UTF-8 BOM | 0xEF 0xBB 0xBF |
| UTF-16BE | 0xFE 0xFF |
| UTF-16LE | 0xFF 0xFE |
| UTF-32BE | 0x00 0x00 0xFE 0xFF |
| UTF-32LE | 0xFF 0xFE 0x00 0x00 |
《字符编码发展史》系列已完结
历史文章推荐:
大家好,我是陌尘。
IT从业10年+, 北漂过也深漂过,目前暂定居于杭州,未来不知还会飘向何方。
搞了8年C++,也干过2年前端;用Python写过书,也玩过一点PHP,未来还会折腾更多东西,不死不休。
感谢大家的关注,期待与你一起成长。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











