









声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站:https://space.bilibili.com/1523287361 点击打开链接
微博地址: https://weibo.com/luoyepiaoxue2014 点击打开链接
title: Flink系列
一、Flink流式计算引擎基础理论
1.1 官网解读
官网解释: https://flink.apache.org/
Apache Flink® — Stateful Computations over Data Streams
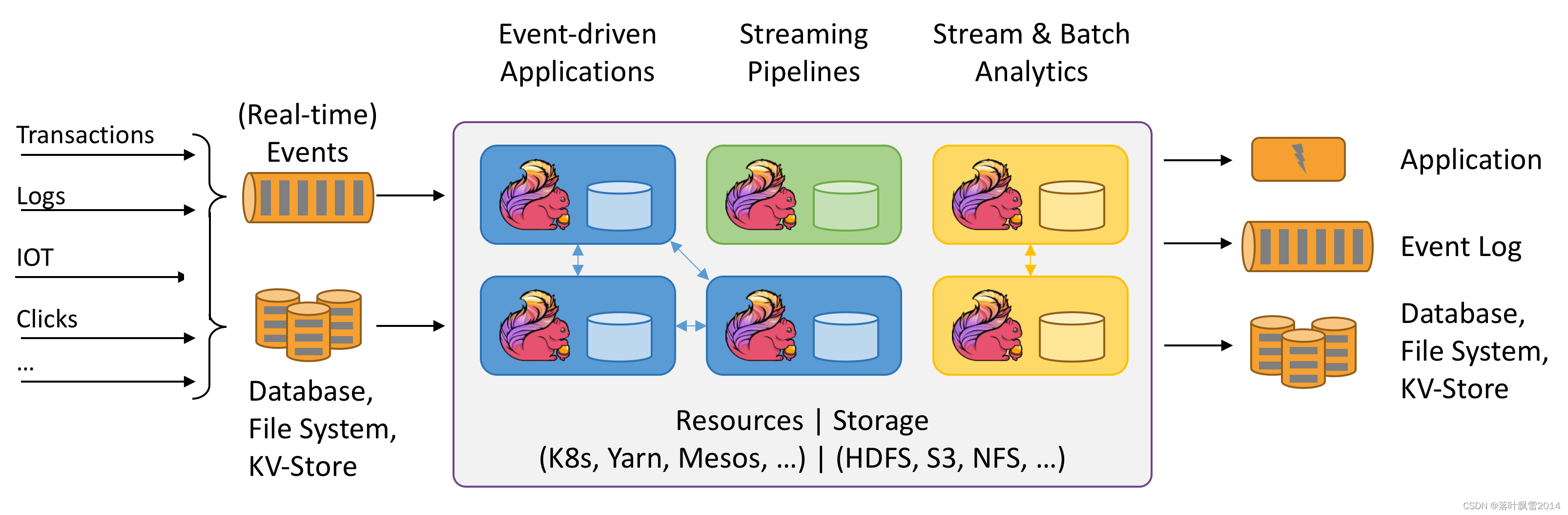
看详细介绍:
| 优势 | 细节 | 官网链接 |
|---|---|---|
| 所有流式场景 | 1、数据驱动的应用 2、批流数据分析 3、数据通道和ETL | https://flink.apache.org/zh/usecases.html |
| 正确性保证 | 1、Exactly-once状态一致性保证 2、事件时间处理 3、复杂的late date处理 | https://flink.apache.org/zh/flink-applications.html#building-blocks-for-streaming-applications |
| 分层 API | SQL on Stream & Batch Data DataStream API & DataSet API ProcessFunction (Time & State) | https://flink.apache.org/zh/flink-applications.html#layered-apis |
| 聚焦运维 | 灵活部署 高可用 保存点 | https://flink.apache.org/zh/flink-operations.html |
| 大规模计算 | 水平扩展架构 支持超大状态 增量检查点机制 | https://flink.apache.org/zh/flink-architecture.html#run-applications-at-any-scale |
| 性能卓越 | 低延迟 高吞吐 内存计算 | https://flink.apache.org/zh/flink-architecture.html#leverage-in-memory-performance |
英文版本:
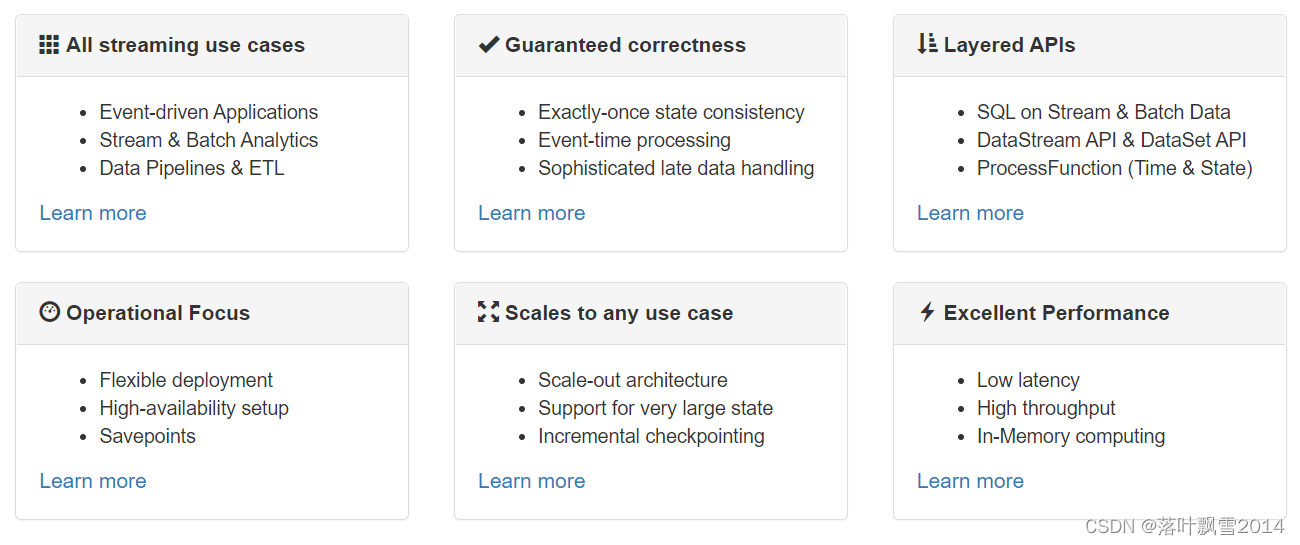
中文版本:

Flink 各种特性介绍:https://flink.apache.org/
What is Apache Flink?:https://flink.apache.org/flink-architecture.html
Flink 应用场景:https://flink.apache.org/usecases.html
Flink 应用企业:https://flink.apache.org/poweredby.html
Flink 版本升级迭代:https://flink.apache.org/downloads.html
Flink Quick Start:https://nightlies.apache.org/flink/flink-docs-release-1.14//docs/try-flink/local_installation/
Flink 架构:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/flink-architecture/
Flink 核心概念:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/glossary/
Flink 流式应用程序开发相关:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/overview/
Flink Checkpoint:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/ops/state/checkpoints/
Flink State 和 StateBackend:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/ops/state/state_backends/
Flink 部署:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/overview/
要点01:Flink 处理无界数据流:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/learn-flink/overview/#stream-processing
要点02:Flink 关于并行数据流的处理方案:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/learn-flink/overview/#parallel-dataflows
要点03:Flink 的有状态计算和状态管理:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/learn-flink/overview/#stateful-stream-processing
要点04:Flink Operator 和 Task:https://nightlies.apache.org/flink/flink-docs-release-1.14/fig/levels_of_abstraction.svg
要点05:Flink 资源管理 和 Solot:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/flink-architecture/#task-slots-and-resources
要点06:Flink 应用程序运行模式:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/flink-architecture/#flink-application-execution
Flink 设计目的和初衷:
无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性,无界流的处理称为流处理。
无界流有一个开始,但没有定义的结束。它们不会在生成数据时终止并提供数据。必须连续处理无边界流,即,事件在被摄入后必须立即处理。等待所有输入数据到达是不可能的,因为输入是无界的,并且不会在任何时间点完成。处理无界数据通常需要以特定的顺序接收事件,例如事件发生的顺序,以便能够推断出结果的完整性。
一种不断增长的,本质上无限的数据集。这些通常被称为“流数据”。然而,当应用于数据集时,术语流或批量是有问题的,这种数据往往意味着使用某种类型的执行引擎来处理这些数据集。两种类型的数据集之间的关键区别在于现实中它们的有限性,因此最好用表示这种区别的术语来表述它们。因此,我将无限的“流”数据集称为无限数据,有限的“批处理”数据集作为有限数据。
有界数据流和无界数据流的区别:
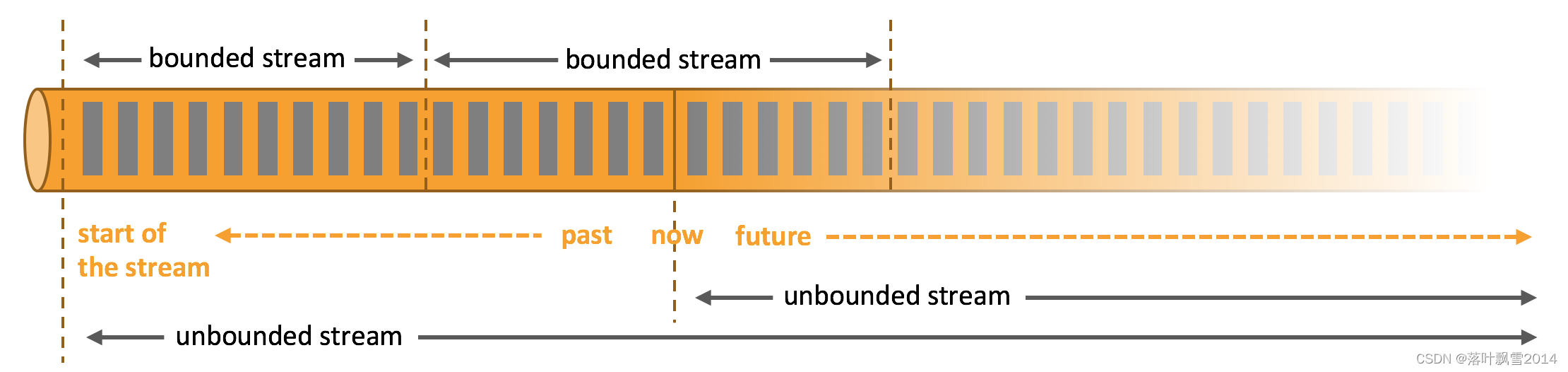
一种持续的数据处理模式,适用于无限数据流。低延迟,近似和/或推测结果通常与流式引擎联系在一起。事实上,批处理系统传统上没有实现低延迟或推测性的结果。
从这里开始,任何时候使用术语“流”,意思都是设计用于无限数据集的执行引擎。当没有附加任何其他术语时,将明确表示无限数据,无限数据处理或低延迟/近似/推测结果。这些是在Google Dataflow中采用的术语。
最终总结:
离线和实时应该指的是:数据处理的延迟;
批量和流式指的是:数据处理的方式。
批处理的特点是有界、持久、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
1.2 Flink 架构设计实现和应用模块分工
Flink 整体架构设计实现:https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/concepts/flink-architecture/
架构图:
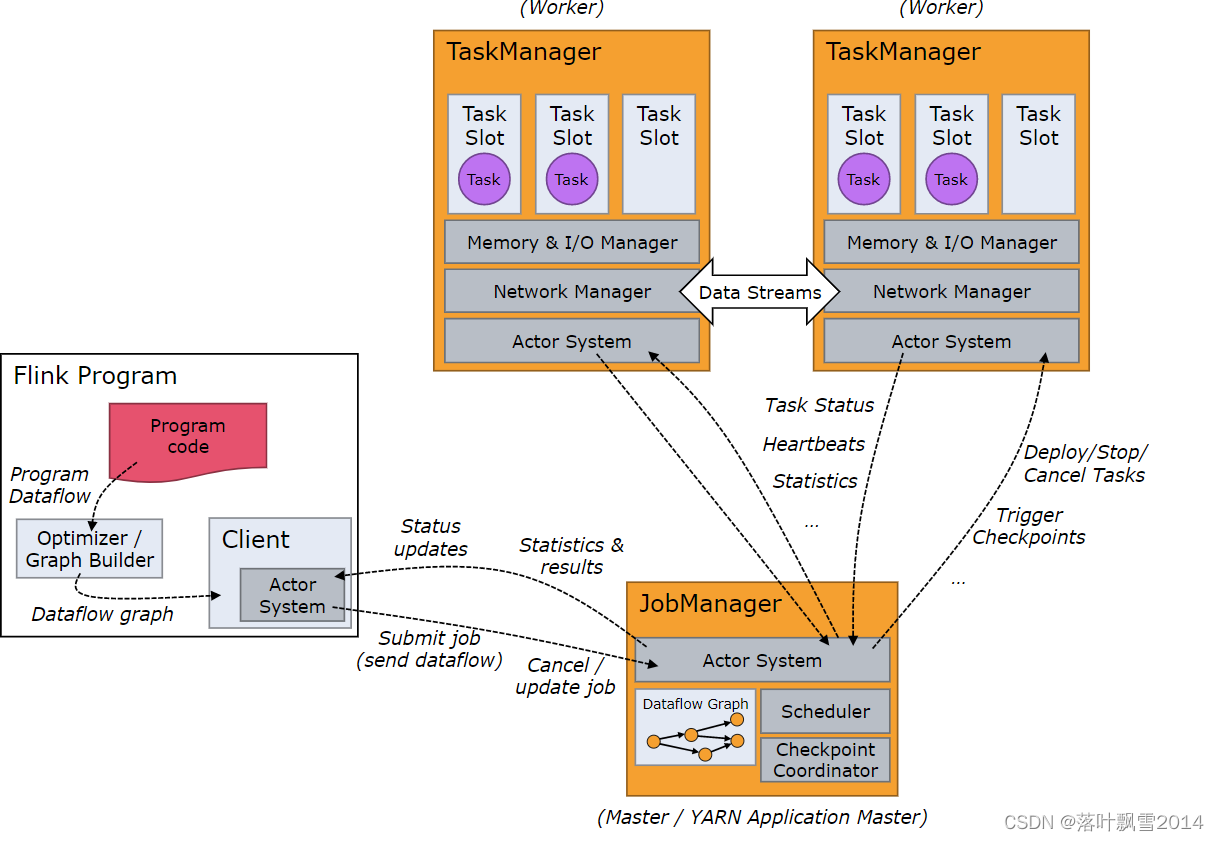
RestClient(ActorSystem RPC 通信 HTTP 的提交 App) +
StreamGraph(一个算子/一个Operator 就是这个 DataFlow 中的一个顶点 流图 原始图) +
JobGraph (提交到服务集群中的数据结构抽象对象,在 StreamGraph 基础之上做了优化:把满足一定条件的相邻 Operator 合并成一个 OperatorChain)
JobManager( ResourceManager 管理和调度资源 + WebMonitorEndpoint 接收 客户端 rest 请求 + Dispatcher 做任务分发 )
- JobGraph(当 Dispatcher 去给这个Job 启动一个 JobMaster 的时候,会让 JobMaster(类似于 YARN 中的 AM 角色) 把这个 JobGraph 转换成 ExecutionGraph
- ExecutionGraph: 并行化(Operator 根据并行度运行成多个 Task)) + ExecutionGraph
TaskManager: Memory、NetWork 、IO Manager ActorSystem, TaskSlotTable
关于 ResourceManager 的解释:
1、YARN 中的 主节点
2、Flink 的 JobManager / Standalone 集群的主节点 的一个内部组件: 资源管理
主节点:逻辑概念: JobManager
Standalone: 主节点:物理概念: StandaloneSessionClusterEntrypoint
YARN Session Cluster: 主节点: YARNSessionClusterEntrypoint
Flink API 设计:https://nightlies.apache.org/flink/flink-docs-release-1.14/fig/levels_of_abstraction.svg
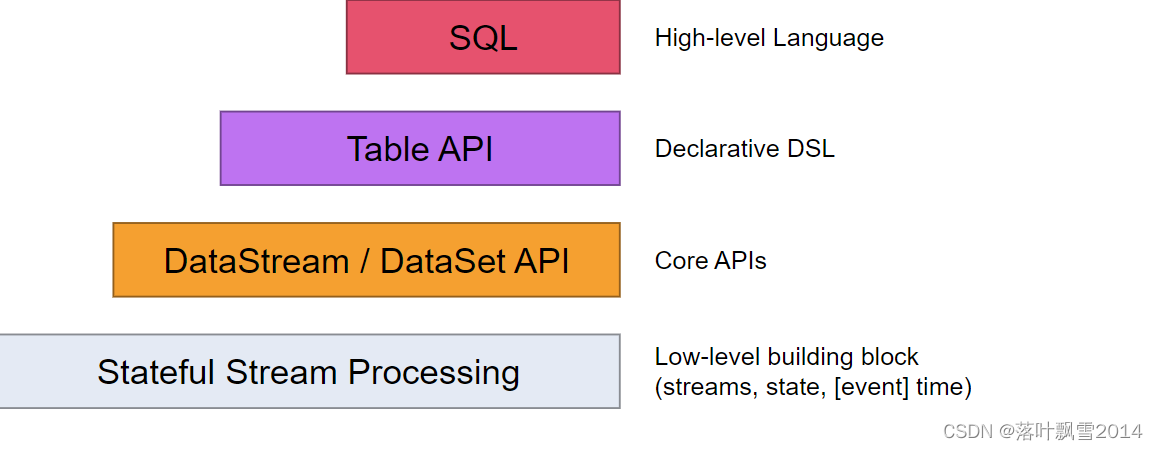
Flink 整体架构体系:API 和 Libaries 体系
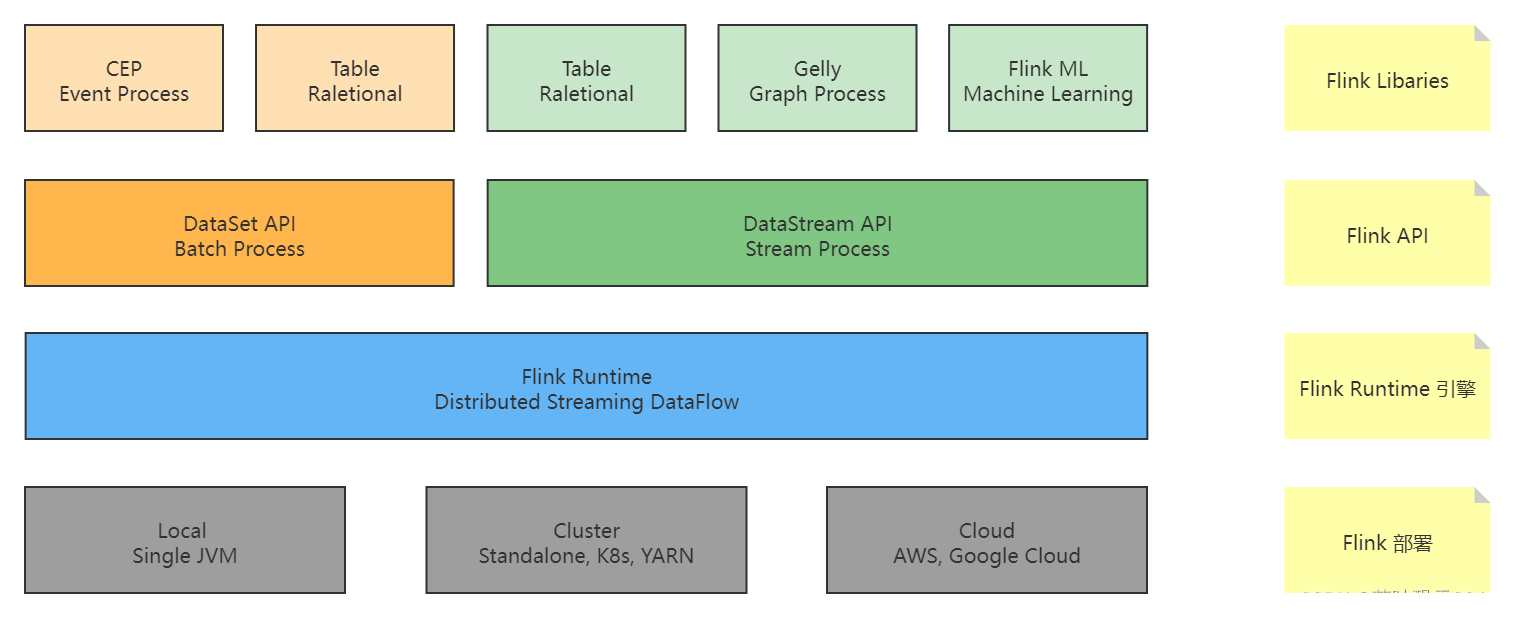
阿里的 Flink 流式平台负责人: 阿里云栖大会的时候,在 Flink-1.13 的完全支持 流批一体的 API
批处理:Spark
流处理:Flink
很多公司,自己实现!搞一个平台,封装这两个东西
Spark =》 SparkSession :SparkContext + SQLContext + HiveContext



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









