










第四章 -- 表
表就是关于特定实体的数据集合,这也是关系型数据库模型的核心。
零、参数
KEY_BLOCK_SIZE:压缩页的大小,可选 2K, 4K, 8K,则每个区中页的个数变成了:512, 256, 128
innodb_page_size:默认页的大小从 16 K 改为 4K or 8K,非压缩。
- 注意:在设置完了新的页大小之后,就不可以再次对其进行更改。除非通过 mysqldump 导入和导出操作来产生新的库
innodb_checksum_algorithm:更改检测 checksum 的算法,默认crc32,可选 innodb、crc32、none、strict_innodb、strict_crc32(推荐)、strict_none
sql_mode:设置为 STRICT_TRANS_TABLES 的时候,非法的输入就不会被记录,即对于输入值的合法性进行了约束。其他值见官方手册
一、索引组织表
根据主键顺序组织存放的表称为索引组织表(index organized table)。如果创建表的时候没有显示地定义主键,InnoDB 就会按照西面的方法选择或创建主键:
- 首先判断是否有非空的唯一索引(Unique NOT NULL),如果有,该列就是主键
- 如果不符合上述条件,InnoDB 自动创建一个 6 字节大小的指针
如果有多个非空唯一索引,会选择建表时的第一个非空唯一索引作为主键
使用 _rowid 可以查看主键(只有一个索引的时候)
二、InnoDB 逻辑存储结构
InnoDB 的所有数据都存放在一个空间中,这个空间被称为表空间(table space)。表空间由段(segment)、区(extent)、页(page/block)组成,如下图所示:
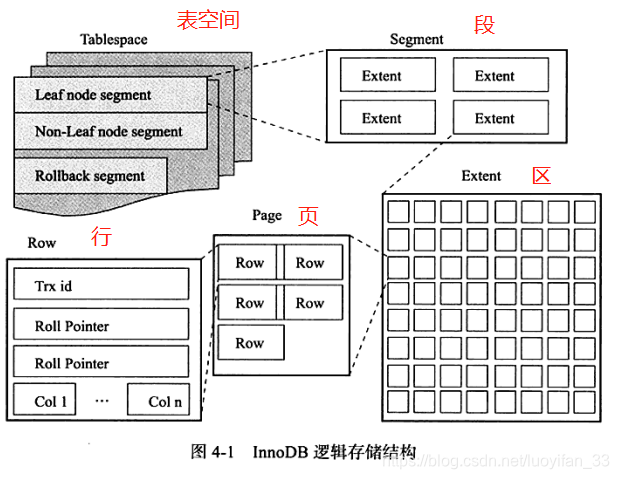
1、表空间 — tabale space
表空间可以看作是 InnoDB 逻辑结构的做高层,所有的数据都存放在这里面。在第三章中写过,有两个表空间,一个是默认表空间 ibdata1,另一个是用参数 innodb_file_per_table 定义的表空间。但是要注意:
- 自定义的表空间内只存放数据、索引和插入缓冲 Bitmap 页
- 其他的数据,如回滚(undo)信息、插入缓冲索引页、系统事务信息、二次写缓冲还是存放在默认的共享表空间里面;
从上面的观察可以看出,即便是启用了这个参数,ibdata1 还是会不断增大(P94 实验)
并且就算进行了回滚,ibdata1 的大小还是不会减少,只不过会自动判断这些 undo 信息是否需要,如果不需要,就会被标记为可用空间,供下次 undo 使用
2、段 — segment
由 InnoDB 自动管理。常见的段有数据段、索引段、回滚段等。
数据段几位B+树的叶子节点,索引段即为B+树的非叶子节点。
因为 InnoDB 是索引组织的,所以数据即索引,索引即数据。
3、区 — extent
区是由连续页组成的空间,在任何情况下每个区的大小都是 1MB.为了保证区中页的连续性,InnoDB 一次性从磁盘申请 4~5 个区。默认情况下一个页大小为 16KB,因此一个区中有64个连续的页。
可以通过KEY_BLOCK_SIZE(压缩页)和 innodb_page_size(非压缩)设置页的大小为 2K, 4K, 8K(压缩)和 4K, 8K
3.1、参数 innodb_file_per_table 的区为什么是 96K
因为在每个段开始的时候,先用 32 个页大小的碎片页(fragment page)来存放数据,在使用完这些页之后才是 64 个连续页的申请。
好处:
- 对于一些小表,或者是 undo 这类的段,可以在开始时申请较少的空间,节省磁盘容量的开销。
(P96 - 100 有作者做的实验,测试碎片页是否存在)
4、页 — page
页是 InnoDB 管理的最小单位,默认大小 16KB。
常见的页类型:
- 数据页 (B-tree Node)
- undo 页(undo log page)
- 系统页(system page)
- 事务数据页(transaction system page)
- 插入缓冲位图页(insert buffer bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页(compressed BLOB Page)
5、行 — row
InnoDB 存储引擎是面向列的(row-oriented)也就是说数据是一行一行存放的。
每页最多存放 16KB / 2 -200 行记录,即 7992 行记录
注意,存在 column-oriented 的数据库,例如 MySQL infobright 存储引擎,Google Bit Table 等
三、InnoDB 行记录格式
有两种格式来存放行记录数据:Compact 和 Redundant。可以通过下面的命令来查看:
SHOW TABALE STATUS like 'table_name' //table_name 是自己的表名字
其中的 Row_format 就是行记录格式
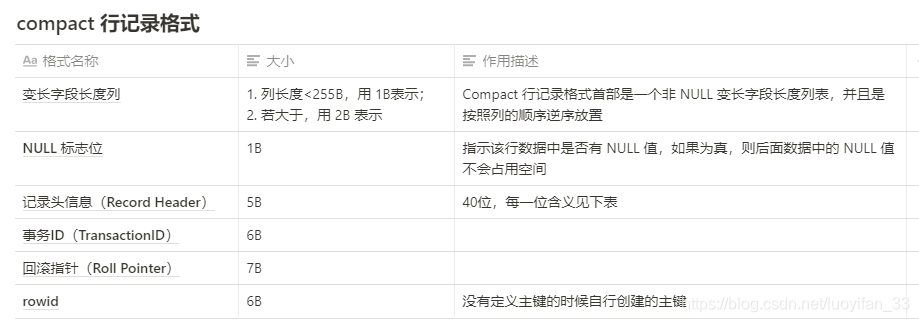
1、Compact 行记录格式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mIW9wb3P-1615087905193)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/716d645f-d934-48d6-ac70-ea9dd7f0b0d6/Untitled.png)]
如上图所示,有三个固定格式 + 数据段。同时,还有两个隐藏列,事务 ID 列和回滚指针列。同时,如果没有定义主键,还会增加一个rowid列:
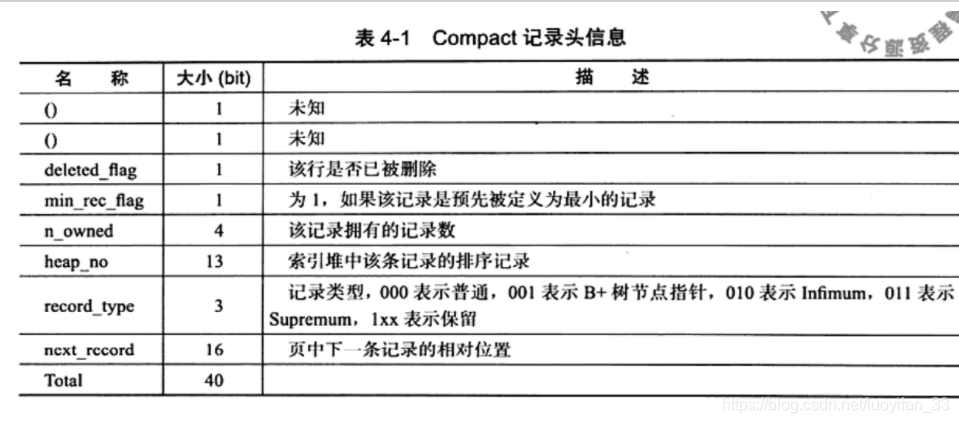
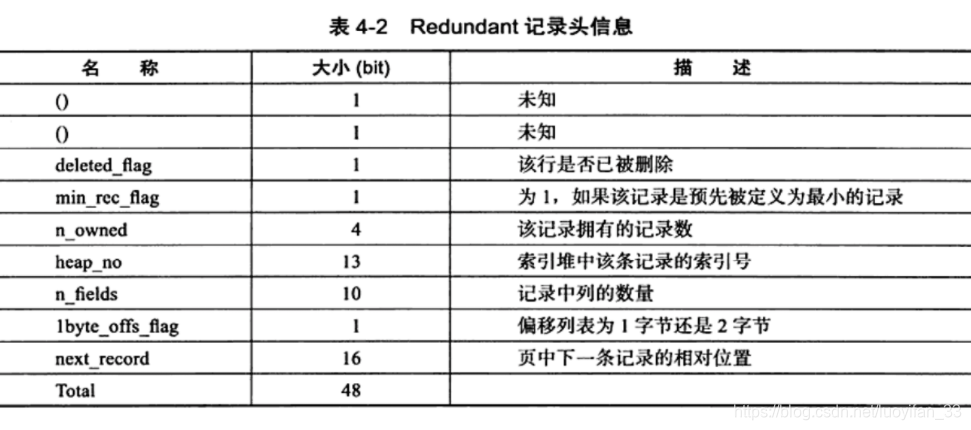
2、Redundant 行记录格式
这是 MySQL 5.0 之前的存储方法,继续保留是为了兼容之前的版本。

与 compact 不同之处:
- 记录头占 6 字节,见下表
- 没有 NULL 标志位
- 对于 VARCHAR 类型的 NULL 值,Redundant 行记录格式不占用任何存储空间,但是 CHAR 类型的 NULL 值要占用空间
3、行溢出数据
InnoDB 可以将一条记录中的某些数据存储在真正的数据页面之外:
- BLOB, LOB 这类的大对象列
- 有时候即便是 VARCHAR 也有可能被存放为行溢出数据
这是因为对于VARCHAR有很多理解,都会有一些细微的差别:
3.1、VARCHAR 最大可存放65535字节?
VARCHAR(N)
错误,首先,由于存在着其他开销,VARCHAR 类型能存放的最大长度为 65532。
其次,VARCHAR 里面的长度与字符集有关,如果是 GKB,则最大为 32767 的长度,如果是 UTF-8,则最大为 21845 的长度;因此 VARCHAR(N) 里面的 N 指的是字符的长度。
最后,最大字节是所有 VARCHAR 长度的总和,如果三四个 VARCHAR 加起来超过了最大长度,也一样的会在创建时候报错。
3.2、行溢出数据怎么存放
正常情况下,InnoDB 存储的数据都是存放在页类型为 B-tree node 中,而行溢出的时候,就放在 Uncompress BLOB 里面。
如下图所示,如果发生了行溢出,会在数据页面里面存放前 768 字节的前缀数据,之后就是偏移量,指向行溢出页:
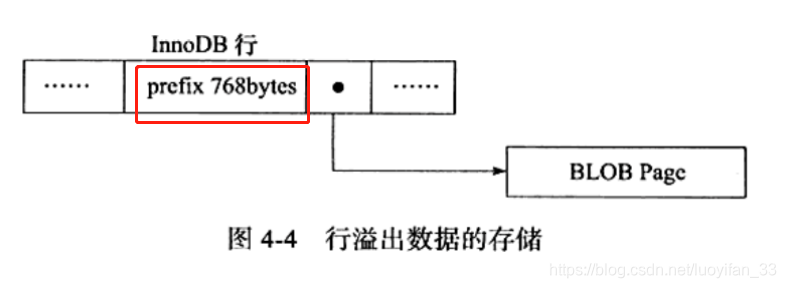
3.3、多长的 VARCHAR 开始就会保存在 BLOB 中?
我们知道,正常情况下,VARCHAR 是放在 B+ tree 里面的,所以每一个页中应该至少有两条数据(否则就不是 B+tree 了,而是链表)。因此,如果每个页中只能存放一条记录,那么 InnoDB 就会将行数据存放到溢出页中。
临界长度为 8098,即 VARCHAR(8098) 的情况下,刚好可以放两条 VARCHAR 数据到一个页中,而不会放到 BLOB 里面
4、Compressed 和 Dynamic 行记录格式
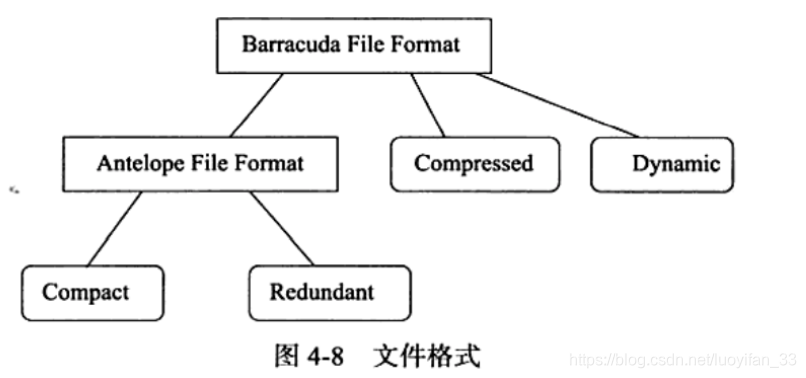
之前讨论的 Compact 和 Redundant 行文件格式统称为 Antelope 格式,属于老格式。新格式叫 Barracuda,由 Compressed 和 Dynamic 两种行记录格式组成。
区别:
- 新的格式对于 BLOB 采用了完全溢出的方式,即数据页中仅存放 20 B 的指针,实际的数据放在off page 里面
- compressed:会用 zlib 算法对存储的行数据进行压缩,所以对于 BLOB, TEXT, VARCHAR 可以很有效的存储
5、CHAR 的行结构存储
注意:CHAR 类型列内部存储的可能不是定长的数据。
还是和之前一样,CHR(N) 指的是字符长度,而不同字符,例如 latin1、GBK、UTF-8 都是不同的字符,具备不同的长度(字节数)。这也就造成了 CHAR 可能不是定长的数据了。
四、InnoDB 数据页结构
从前面的描述可以知道,页是InnoDB 管理数据库的最小磁盘单位,页类型为 B-tree node 的页存放的即是表中行的实际数据了。
如下图所示,数据页由 7 个部分组成:
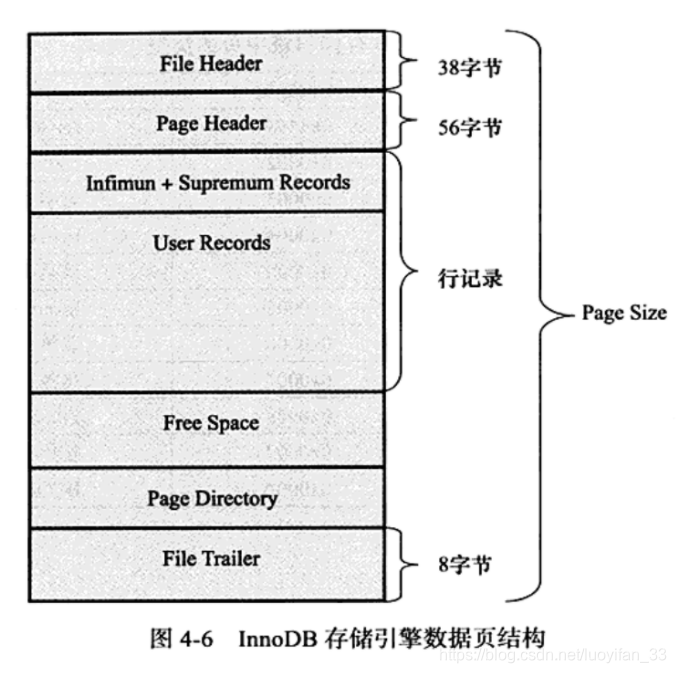
1、File Header(文件头)
用来记录页的一些头信息,占用 38 字节,如下表所示:
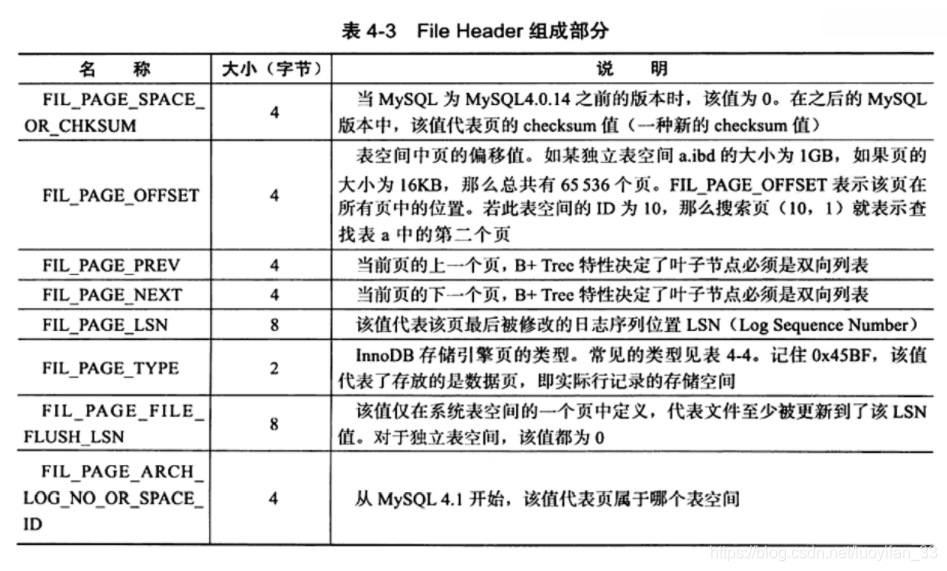
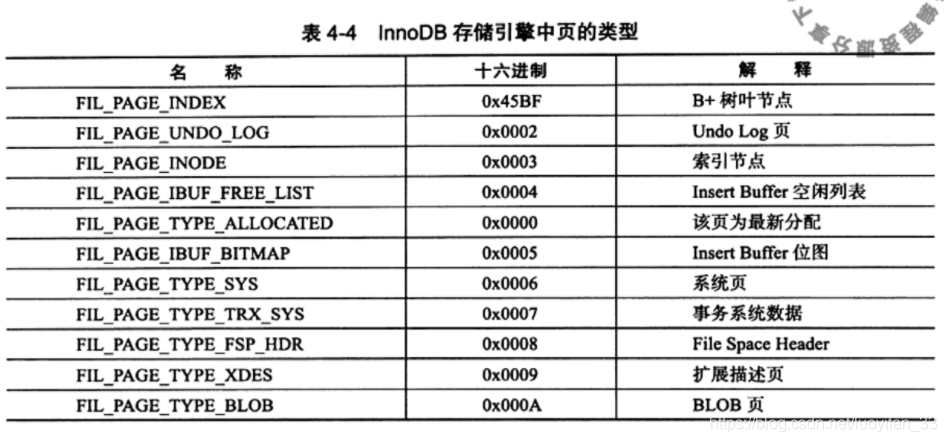
其中的 FILE_PAGE_TYPE 见下表:
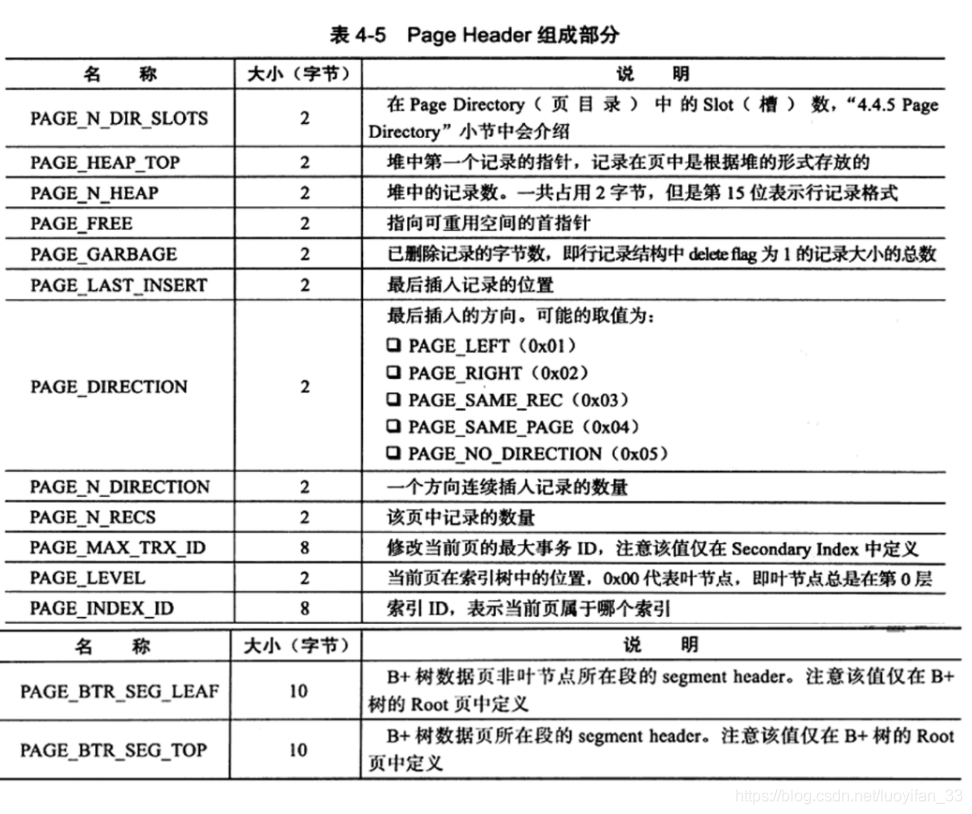
2、Page Header(页头)
用来记录数据页的状态信息,占用 56 字节,由 14 个部分组成:
3、Infimum + Supremum Record
数据页的下界(infimum)和上界(supremum),数据页的虚拟行记录,用来限定记录的边界,如下图所示: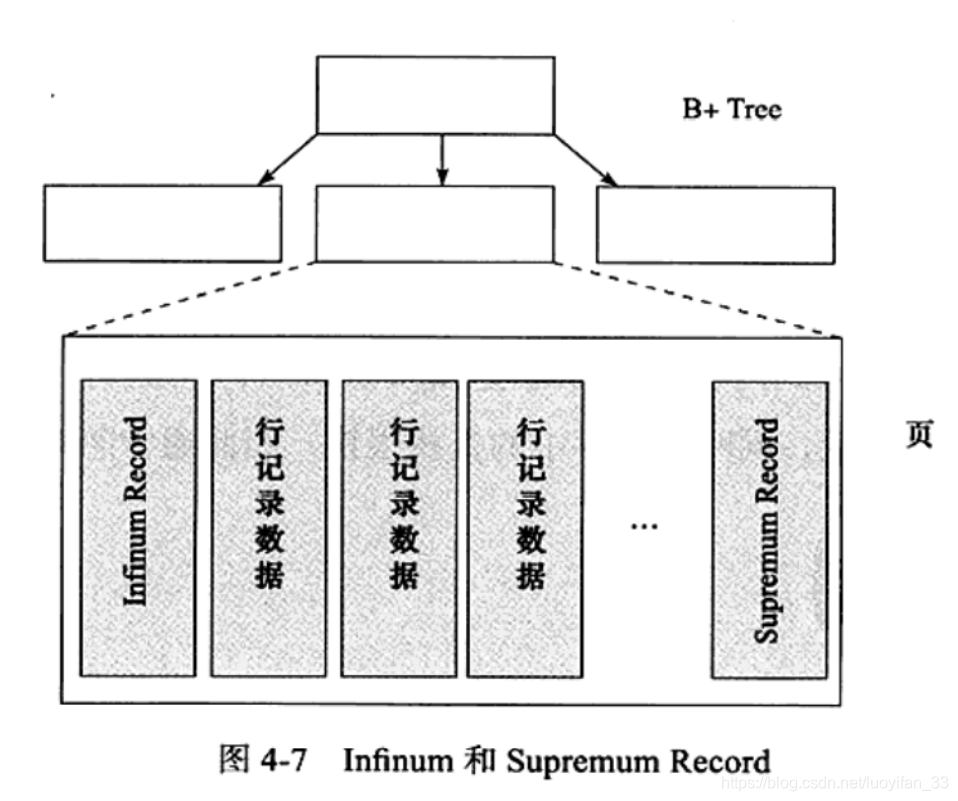
4、User Records(用户记录,即行记录)和 Free Space
User Record 就是之前讨论过的实际存储行记录的内容。InnoDB 总是B+tree索引组织的。
Free Space 就是空闲空间,也是个链表数据结构。在一条记录被删除之后,该空间就会被加入到空闲链表。
5、Page Directory(页目录)
存放记录的相对位置(注意,相对位置不是offset 偏移量),有时候这些记录指针称为 Slots(槽)or 目录槽(Directory slots)
B+tree 索引本身并不能找到具体的一条记录,能找到的只是该记录所在的页。数据库把页载入道内存,然后通过 Page Directory 再进行二叉查找。
6、File Trailer(文件结尾信息)
用于检测页是否已经完整的写入磁盘(如果发生磁盘损坏、宕机等,则不会完整写入)
只有一个 FIL_PAGE_END_LSN,占 8 个字节,前4个字节是 checksum 值,后四个字节和 File Header 的 FIL_PAGE_LSN 相同。需要满足以下条件:
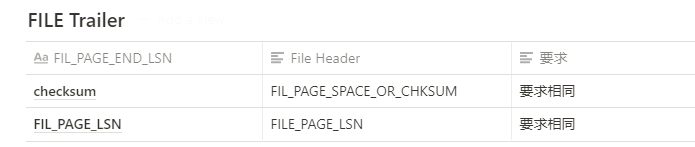
File Header 和 File Trailer 的两个参数相同,才能说明这一页完整(not corrupted)
使用参数 innodb_checksum_algorithm 来更换检查checksum 的算法
五、Named File Formats 机制
即前面提到的 Antelope 和 Barracuda 等的包含关系,如下图:
六、约束
1、数据完整性
关系型数据库和文件系统的一个不同点是,关系数据库本身就能保证存储数据的完整性,不需要应用程序的控制,而文件系统一般需要在程序端进行控制。为了保证完整性,就有了**约束(constraint)**机制。
1.1、实体完整性
保证表中有一个主键。
- 通过 Primary Key 或者 Unique Key 约束来保证实体完整性
- 或者是编写触发器来保证
1.2、域完整性
保证数据每列的值满足特定的条件。通过以下途径保证:
- 选择合适的数据类型,确保一个数据值满足特定的条件
- 外键约束
- 编写触发器
- DEFAULT 约束作为强制域完整性的一个方面
1.3、参照完整性
保证两张表之间的关系。
可以通过外键或编译器来保证。
1.4、InnoDB 约束类型
- primary key(主键)
- unique key(唯一索引)
- foreign key
- default
- not null
2、数据的创建和查找
那么,怎么来创建约束呢?有下面两种方式:
- 在创建表的时候,就对约束进行定义
- 利用 ALTER TABLE 命令来创建约束
对于主键而言,还可以使用 CREATE UNIQUE INDEX 来建立。
3、约束和索引区别
- 约束是一个逻辑上的概念,用来保证数据的完整性
- 索引是一个数据结构,既有逻辑上的概念,在数据库中还代表物理存储的方式
用户创建了一个唯一索引的同时,就创建了一个唯一的约束
4、对错误数据的约束
某些情况下,允许非法 or 不正确的数据的插入或更新,或者是在内部将其转化为合法的值。例如对于 NOT NULL 的字段,插入 NULL 的时候,会将其转为 0 再进行插入。
使用 sql_mode = STRICT_TRANS_TABLES 可以约束这种输入值的合法性。
5、ENUM 和 SET 约束
对于 CHECK 约束,通过 ENUM 和 SET 进行曲线救国。CHECK 约束指的是在某一个范围内合法。但是 ENUM 只能提供离散的样本空间,因此对于一段连续的区间,还需要触发器来实现对值域的约束。
CREATE TABLE a(
id INT,
gender ENUM('male', 'female')
);
6、触发器与约束
完整性的约束也可以用触发器实现。其实就是用 SQL 语句实现函数。
它的作用是在执行 INSERT、DELETE 和 UPDATE 命令之前(BEFORE)或之后(AFTER)自动调用SQL 命令(函数)或者是存储。
使用 CREATE TRIGGER 创建触发器(需要 super 权限)
(案例见 P 140)
7、外键约束
InnoDB 完整支持外键约束,MyISAM 不支持外键。外键的定义如下:
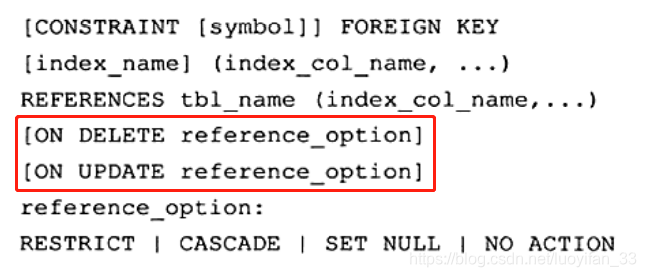
一般而言,被引用的表称为父表,引用的表称为子表。定义的时候,上面红框中的操作表示对父表 DELETE | UPDATE 的时候,子表相对的反应,有下面四种:
- CASCADE:子表也相应的 UPDATE | DELETE
- SET NULL:子表设置为 NULL(前提是允许设置为 NULL)
- NO ACTION:抛出错误,不允许这类操作发生
- RESTRICT(默认):抛出错误,不允许这类操作发生
外键对参照性约束作用很大,单数对于数据的导入则会花费大量时间。因为 MySQL 是即时检查数据库的。设置 SET foreign_key_checks = 0 可以不进行检查
七、视图
视图是一个命名的虚表,它由一个 SQL 查询来定义,可以当作表使用。与持久表(permanent table)不同的是,视图中的数据没有实际的物理存储。
1、视图的作用(重要)
视图的主要作用是被用作一个抽象装置,特别是对于一些应用程序,程序本身不用关心基表(base table)的结构,只需要按照试图定义来取数据或更新数据。因此视图在一定程度上起到了安全层的作用。创建视图的语法如下:
CREATE
[OR REPLACE]
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
[DEFINER = { user | CURRENT_USER}]
[SQL SECURITY {DEFINER | INVOKER}]
VIEW view_name [{column_list}]
AS selec_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
虽然视图是基于 base table 的一个虚拟表,但是用户可以对某些视图进行更新操作,其本质就是通过视图的定义来更新 base table。
如何展示视图?
SHOW TABLE
这个命令会将所有表,包括视图(虚表)显示出来
如果只要查看基表(base table),用下面的语句:
SELECT * FROM information_schema.TABLES
WHERE table_type = 'BASE TABLE'
AND table_schema = database()
如果要查看视图的元数据 meta data,就访问 VIEWS 表:
SELECT * FROM information_schema.VIEWS
AND table_schema = database()
2、物化视图
物化视图指的是该视图不是基于 base table 存在的虚表,而是根据 base table 实际存在的实表,物化视图可以用于预先计算并保存多表的链接(JOIN)或聚集(GROUP BY)等耗时较多的 SQL 操作结果。这样在执行复杂查询时,就可以避免进行这些耗时的操作,从而快速得到结果。
MySQL 不支持物化视图。
八、分区表(重点)
1、分区概述
分区不是在存储引擎层完成的,但也不是所有的引擎都支持分区。
分区的过程是将一个表或索引分解为多个更小、更可管理的部分。
就访问数据库的应用而言,从逻辑上讲,只有一个表或一个索引,但是在物理上这个表或索引可能由数十个物理分区组成。每个分区都是独立的对象。
1.1、垂直分区与水平分区
- 垂直分区,指的是将同一表中不同列的记录分配到不同的物理文件中(MySQL 不支持)
- 水平分区,指的是将同一表中不同行的记录分配到不同的物理文件中
1.2、局部分区和全局分区
- 局部分区索引是指一个分区中既存放了数据又存放了索引,这也是MySQL 支持的分区
- 全局分区是指数据存放在各个分区中,但是所有数据的索引放在一个对象中,MySQL 不支持
1.3、查看分区的SQL语句
SHOW VARIABLES LIKE '%partition%'
SHOW PLUGINS
注意:
如果表中存在主键或唯一索引时,分区列必须是唯一索引的一个组成部分。
2、分区类型
2.1、RANGE 分区
行数据基于属于一个给定连续区间的列值被放入分区。
启用了分区之后,表就不再是一个单独的 ibd 文件了,而是会由建立分区时的各个分区 idb 文件组成。可以通过以下语句查询分区具体信息:
SELECT * FROM information_schema.PARTITIONS
WHERE table_schema=database() AND table_name='TABLE NAME' //TABLE NAME 是自己的表名
RANGE 分区常用于日期列的分区,可以对 YEAR(),TO_DAYS(),TO_SECONDS(),UNIX_TIMESTAMP() 等函数进行优化选择,如下代码:
CREATE TABLE sales (
money INT UNSIGNED NOT NULL,
date DATETIME
) ENGINE = INNODB
PARTITION BY RANGE (YEAR(date)) (
PARTITION p2008 VALUES LESS THEN (2008),
PARTITION p2009 VALUES LESS THEN (2009),
PARTITION p2010 VALUES LESS THEN (2010)
);
// 查询语句
EXPLAIN PARTITION
SELECT * FROM sales
WHERE date >='2008-01-01' AND date <='2008-12-31';
这样做有几个好处:
- 删除 2008 年的数据的时候,不需要 DELETE FROM sales WHERE XXX,只需要删除2008所在的分区即可:ALTER TABLE sales DROP PARTITION p2008;
- 另一个好处就是可以加快查询。利用上面代码块的查询语句,就可以只在 p2008 分区里面进行查询,而不会去搜索所有的分区。这叫做 Partion Pruning(分区修剪),所以查询速度得到了大幅度的提升。
同时注意:如果插入的值不在分区的范围之内,就会报错。
2.2、LIST 分区
和 RANGE 相同,只是 LIST 分区面向的是离散的值。可以理解为 ENUM,创建的语句如下:
CREATE TABLE t (
a INT,
b INT
) ENGINE = INNODB
PARTITION BY LIST (b) (
PARTITION p0 VALUES IN (1, 3, 5, 7, 9),
PARTITION p1 VALUES IN (2, 4, 6, 8)
);
可以很明显的看出,RANGE 分区里面的 LESS THAN 语句被换成了 IN。因为 LIST 每个分区的值是离散的,因此只能定义值。
- 同样,如果插入表中的值超出了范围,也会报错
- 如果插入多个行数据,MyISAM 会将出问题的行之前的数据都插入,之后的不插入。而 InnoDB 则是将其视为一个事务,都不进行插入
2.3、HASH 分区
根据 MySQL 数据库提供的哈希函数进行分区。它的目的是将数据均匀地分布到预先定义的各个分区中,保证各分区的数据数量大致相同。
HASH 分区的定义代码如下:
CREATE TABLE t (
a INT,
b DATETIME
) ENGINE = INNODB
PARTITION BY HASH (YEAR(b))
PARTITION 4;
其中,HASH 后面的括号里面是一个返回整数的表达式/函数,最后一行代表需要 4 个分区。HASH 算法就是简单的取模
还有个延申分区:LINEAR HASH 分区,算法是位操作,见 P165
优缺点比较:
- LINEAR HASH 分区的增加、删除、合并和拆分更快捷,适合处理含有大量数据的表
- HASH 分区得到的数据更加均匀(特别是对于连续数据)
2.4、KEY 分区
根据MySQL数据库提供的函数来进行分区。
2.5、COLUMNS 分区
上面的四种分区,都要求数据必须是整型(integer),如果不是整型,就需要用函数:YEAR(),TO_DAYS() 等来转换成整型。
但是 COLUMNS 可以视为 RANGE, LIST 的一种进化,因为它可以直接使用非整型的数据进行分区,分区根据类型直接比较。它支持以下类型的数据:
- 所有的整型数据:INT,SMALLINT, TINYINT, BIGINT 等,但是 FLOAT, DECIMAL 则不支持
- 日期类型:支持 DATE 和 DATETIME
- 字符串类型:支持 CHAR,VARCHAR,BINARY 和 VARBINARY。BLOB 和 TEXT 不支持
同时,还可以使用多个列进行分区:
PARTITION BY RANGE COLUMNS (a, b, c) (
PARTITION p0 VALUES LESS THAN (5, 10, 'GGG'),
.....
);
3、子分区
子分区(subpartitioning)指的是在分区的基础上再次分区,又称为复合分区(composite partitioning)。
MySQL 允许对于 RANGE 和 LIST 的分区上再进行 HASH 或 KEY 的子分区。可以不设置子分区的名字,也可以指定子分区名字,见 P169.
使用子分区的时候,要注意以下问题:
- 每个子分区的数量必须相同
- 要在一个分区表的任何分区上使用 SUBPARTITION 来明确定义任何子分区,就必须定义所有的子分区。
- 每个 SUBPARTITION 子句(明确定义)必须包括子分区的一个名字
- 子分区的名字必须是唯一的
子分区可以用于特别大的表,在多个磁盘之间分配数据和索引。
4、分区中的 NULL 值
MySQL 总是认为 NULL 值小于任何 NOT NULL 的值。对于不同的分区:
- RANGE 分区插入 NULL 值,会将其放入最左边的分区
- LIST 分区必须在定义的时候说明哪个分区可以接受 NULL 值
- HASH 和 KEY 分区会将 NULL 视为 0 值,但是不等于 0,所以插入 0 和 NULL 是有两条记录
5、分区和性能
对于不同的数据库应用,分区有着不同的性能。
5.1、OLAP(在线分析处理)应用
分区可以很好的提升查询性能,因为 OLAP 需要很频繁地扫描一张很大的表。而使用分区之后,可以只扫描相应的分区。即 Partition Pruning 技术
5.2、OLTP(在线事务处理)应用
这就需要很慎重的考虑了。因为在这种情况下,一般不会需要一张大表 10% 的数据,而只需要通过索引返回几条数据即可。但我们知道,根据 B+tree 的索引,只需要 2~3 次磁盘 IO 即可找到数据。
但是设计不好的分区,查询主键的时候分区有意义,其他的数据查询反而会变慢,因为需要查找所有的分区,原本的2~3次 IO(未分区之前) 可能变成了 20~30 次磁盘 IO(分了10个区之后B+tree 仍然是2~3层的情况)。见 P 179.
6、在表和分区之间交换数据
可以使用 ALTER TABLE … EXCHANGE PARTITION 来交换分区与另一个非分区的表中的数据。
- 如果分区表为空,则相当于外部表中的数据导入到了分区之中
- 如果非分区表为空,相当于将分区中的数据移动出去
但是使用这个语句,也需要满足一些条件,见 P180


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









