







 本文介绍了从UCS2编码如何转换为UTF-8编码的过程,详细讲解了Unicode编码的基础知识及其在Windows和存储中的应用,同时涉及到C语言环境下进行编码转换的方法。
本文介绍了从UCS2编码如何转换为UTF-8编码的过程,详细讲解了Unicode编码的基础知识及其在Windows和存储中的应用,同时涉及到C语言环境下进行编码转换的方法。
确切的说这里的UNICODE编码指的是UCS2编码,我们开发Windows应用程序所用wchar_t 类型数组所保存的字符应该是UCS2编码的,这很容易让人误以为UNICODE是两个字节编码的。其实UNICODE 代表的是一种字符集,也就是字符编码方案,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何在计算机上存储,而UTF8,UTF16,UCS2这些编码方式则是UNICODE的各种实现方式,规定了UNICODE二进制代码在计算机的表示方式。另外UCS2编码并不能完全表示UNICODE字符集。
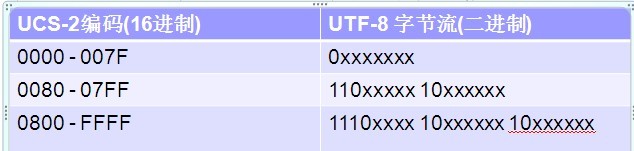
从UCS2到UTF-8编码方式如下:
/*
参数:
strUnicode : Unicode字符串指针
strUnicodeLen : Unicode字符串长度
strUTF8 : UTF8字符串指针
strUTF8Len : UTF8字符串字节数,如需取得转换所需字节数,可向该值传入-1.
返回值 : 转换后所得UTF8字符串字节数, -1 表示转换失败
*/
int UnicodeToUTF_8(wchar_t *strUnicode, int strUnicodeLen, char *strUTF8, int strUTF8Len)
{
if((strUnicode == NULL) || (strUnicodeLen <= 0) || (strUTF8Len <= 0 && strUTF8Len != -1))
{
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









