对于每一个线程会有工作内存,多个线程共享一个主内存,例如对象实例就在主内存会多个线程共享,而引用这个对象的变量实际在每个线程的工作内存,工作内存拥有主内存实例的副本拷贝,通过它来对实例进行,读取与赋值都在工作内存,并且线程之间无法读取对方的变量,都是通过主内存做一个过渡作用。(这里工作内存与主内存跟堆内存与栈内存不是一个概念,这是为了好理解)
接下来工作内存与主内存怎么进行交互?虚拟机定义了8种原子操作,包括lock(锁定主内存的变量,使其被某一线程独占),unlock(同理),read(把一个主内存的变量传递到工作内存中,以便load),load(将从主内存传递的值传递到工作内存的变量副本中),store(将工作内存中变量副本传递到主内存中去,以便write),write(将工作内存传递过来的值赋到主内存中变量),use(将工作内存的值传递给执行引擎),assign(将执行引擎的值传递到工作内存),这8中操作可以用来确定你的访问是否安全。
下面介绍一下volatile,经常被问到的一个关键字,他的作用主要有两个,我们一一说明:1 保证变量在各个线程的可见性,意思就是说这个变量的值一修改,其他线程可以立即得知。而一个普通变量需要先写回主内存,然后其他线程去读取这个值。2:禁止指令重排序优化。然而它并不能保证原子性,以及运算的线程安全,下面代码来解释一下第一个特性。
public class VolatileTest extends Thread{
public static volatile int a=0;
public void run() {
a++;
}
public static void main(String[] args) {
// TODO Auto-generated method stub
VolatileTest array[]=new VolatileTest[10000];
for (int i = 0; i < array.length; i++) {
array[i]=new VolatileTest();
array[i].start();
}
System.out.println(VolatileTest.a);
}
}
我们希望结果会是10000,然而并不是,原因就是a++这一条指令并不是原子操作,volatile的确保证从主内存获得的数据是最正确的,但是当你运算的时候,其他线程很有可能会把一个值穿进去,导致值会变小。
那么什么情况下用volatile呢?一定要明白,它的开销一定会小与同步块。下面就是使用的情况,不符合这两条就要用同步块了。
1:运算结果并不依赖与当前值。
2:变量不需要与其他变量参与不变约束。
同样用代码解释一下。
public class VolatileTest extends Thread{
public static volatile int a=0;
public void run() {
a=2;
}
public static void main(String[] args) {
// TODO Auto-generated method stub
VolatileTest array[]=new VolatileTest[100];
for (int i = 0; i < array.length; i++) {
array[i]=new VolatileTest();
array[i].start();
System.out.print(array[i].a+" ");
}
}}
个人理解就是a的值不依赖与现在在主内存a的实际值,不管a是几,都变成1,而其他线程也会立即受到通知,因为也没有运算,也会直接变为1.
接下来讲一下指令重排序优化的东东,其实指令重排序对于单线程来说有利无害,反正最后的结果是一样的,而且还提高了效率,但是对于多线程,可能会出现一些问题,而volatile修饰的变量,会在操作的时候,设置一个屏障,后面的操作,肯定不会比这个提前。否则后面的操作先执行,从而提前影响其他的线程。
好的,下面介绍几个概念1:原子性 就像前面说的那8张操作就是,粒度小到多线程也不可能拆开它,而用synchronized,内部的东西其实就是一个组装的“大原子”,但是记住volatile是不可以的 2 可见性 意思就是线程修改了值之后会立即同步到主内存,并且获取值会从主内存直接获取,而非缓存,volatile和synchronized都可以保证 3有序性 意思是保证线程内部执行顺序,volatile可以保证禁止指令重排序,而synchronized,直接就锁上了,所以它能解决几乎所有同步问题,造成了滥用。
线程是cpu调度的基本单位,粒度比进程小,Thread的类很多方法是native,可能会为了效率,然而同时可能会平台相关,注意线程的优先级不太靠谱,以为可能与平台线程的优先级不一样,造成冲突。再次补充一个线程状态模型(本文章主要介绍java多线程模型,以及volatile,线程基础不再赘述)
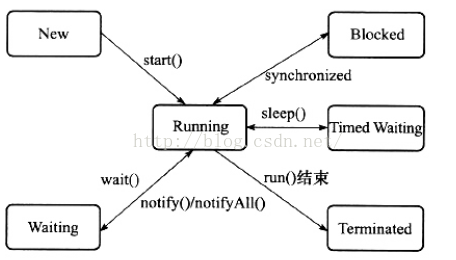
阻塞状态与挂起状态的区别在于阻塞在等待一个排它锁,而挂起是等待时间到,或者是唤醒。
更多细节请查看我的线程基础的这篇博客,多谢大家支持
本博客知识来源于深入理解java虚拟机,值得一看,强力 推荐,特别底层!!!
TTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTT
问题来源于编码规范的一个例子
一. 关于server模式下的主存和工作内存
规则40 多线程访问同一个可变变量,需增加同步机制
说明:根据Java Language Specification中对Java内存模型的定义, JVM中存在一个主内存(Java Heap Memory),Java中所有变量都储存在主存中,对于所有线程都是共享的。每个线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是在工作内存中进行,线程之间无法相互直接访问,变量传递均需要通过主存完成。根据上述内存模型的定义,要在多个线程间安全的同步共享数据就必须使用锁机制,将某线程中更新的数据从其工作内存中刷新至主内存,并确保其他线程从主内存获取此数据更新后的值再使用。
示例:
不好:下面的代码中,没有对可变数据stopRequested的访问做同步。程序期望在一秒钟后线程能停止。但在用java 1.6的server模式运行此程序(Java –server StopThread)时,程序陷入死循环,不能结束。
public class StopThread
{
private static boolean stopRequested;
public static void main(String[] args) throws InterruptedException
{
Thread backgroundThread = new Thread(new Runnable()
{
public void run()
{
int i = 0;
while (!stopRequested)
{
i++;
}
}
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
stopRequested = true;
}
}
这里为什么会陷入死循环,永远不会停止呢?
参考两篇文章
http://m.blog.csdn.net/blog/lyy5682077/17588155
http://www.cnblogs.com/trytocatch/archive/2013/01/07/2850002.html
JIT或HotSpot编译器在server模式和client模式编译不同,server模式为了使线程运行更快,如果其中一个线程更改了变量boolean flag 的值,那么另外一个线程会看不到,因为另外一个线程为了使得运行更快所以从寄存器或者本地cache中取值,而不是从内存中取值,那么使用volatile后,就告诉不论是什么线程,被volatile修饰的变量都要从内存中取值。《内存栅栏》
java在server模式下,各个线程使用各自的工作内存,一个线程改变了变量的值,另外一个线程并不会从主存中取
上面例子中的问题,变量
stopRequested前加上volatile可以解决:
增加了
synchronized
同步机制后,程序就能正确地在
1
秒后终止。另一个方案是在变量前增加
volatile
关键字。
public class StopThread
{
private static boolean stopRequested;
private static synchronized void requestStop()
{
stopRequested = true;
}
private static synchronized boolean isStopRequested()
{
return stopRequested;
}
public static void main(String[] args) throws InterruptedException
{
Thread backgroundThread = new Thread(new Runnable()
{
public void run()
{
int i = 0;
while (!isStopRequested())
{
i++;
}
}
});
backgroundThread.start();
TimeUnit.SECONDS.sleep(1);
requestStop();
}
}
二. static和volatile的区别
参考http://blog.sina.com.cn/s/blog_4e1e357d0101i486.html
1. volatile是告诉编译器,每次取这个变量的值都需要从主存中取,而不是用自己线程工作内存中的缓存.
2. static 是说这个变量,在主存中所有此类的实例用的是同一份,各个线程创建时需要从主存同一个位置拷贝到自己工作内存中去(而不是拷贝此类不同实例中的这个变量的值),也就是说只能保证线程创建时,变量的值是相同来源的,运行时还是使用各自工作内存中的值,依然会有不同步的问题.
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
synchronized
关键字,代表这个方法加锁,相当于不管哪一个线程(例如线程A),运行到这个方法时,都要检查有没有其它线程B(或者C、 D等)正在用这个方法(或者该类的其他同步方法),有的话要等正在使用synchronized方法的线程B(或者C 、D)运行完这个方法后再运行此线程A,没有的话,锁定调用者,然后直接运行。它包括两种用法:synchronized 方法和 synchronized 块。
Java语言的关键字,可用来给对象和方法或者代码块加锁,当它锁定一个方法或者一个代码块的时候,同一时刻最多只有一个线程执行这段代码。当两个并发线程访问同一个对象object中的这个加锁同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。然而,当一个线程访问object的一个加锁代码块时,另一个线程仍可以访问该object中的非加锁代码块。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
volatile是一个类型
修饰符(type specifier),就像大家更熟悉的const一样,它是被设计用来修饰被不同线程访问和修改的
变量。
volatile的作用是作为指令
关键字,确保本条指令不会因
编译器的优化而省略,且要求每次直接读值。
volatile的变量是说这变量可能会被意想不到地改变,这样,
编译器就不会去假设这个变量的值了。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
volatile这个关键字可能很多朋友都听说过,或许也都用过。在Java 5之前,它是一个备受争议的关键字,因为在程序中使用它往往会导致出人意料的结果。在Java 5之后,volatile关键字才得以重获生机。
volatile关键字虽然从字面上理解起来比较简单,但是要用好不是一件容易的事情。由于volatile关键字是与Java的内存模型有关的,因此在讲述volatile关键之前,我们先来了解一下与内存模型相关的概念和知识,然后分析了volatile关键字的实现原理,最后给出了几个使用volatile关键字的场景。
以下是本文的目录大纲:
一.内存模型的相关概念
二.并发编程中的三个概念
三.Java内存模型
四..深入剖析volatile关键字
五.使用volatile关键字的场景
若有不正之处请多多谅解,并欢迎批评指正。
请尊重作者劳动成果,转载请标明原文链接:
http://www.cnblogs.com/dolphin0520/p/3920373.html
一.内存模型的相关概念
大家都知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
也就是,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核CPU为例。
比如同时有2个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。
最终结果i的值是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
也就是说,如果一个变量在多个CPU中都存在缓存(一般在多线程编程时才会出现),那么就可能存在缓存不一致的问题。
为了解决缓存不一致性问题,通常来说有以下2种解决方法:
1)通过在总线加LOCK#锁的方式
2)通过缓存一致性协议
这2种方式都是硬件层面上提供的方式。
在早期的CPU当中,是通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。比如上面例子中 如果一个线程在执行 i = i +1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从变量i所在的内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题。
但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。

二.并发编程中的三个概念
在并发编程中,我们通常会遇到以下三个问题:原子性问题,可见性问题,有序性问题。我们先看具体看一下这三个概念:
1.原子性
原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
一个很经典的例子就是银行账户转账问题:
比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元。
试想一下,如果这2个操作不具备原子性,会造成什么样的后果。假如从账户A减去1000元之后,操作突然中止。然后又从B取出了500元,取出500元之后,再执行 往账户B加上1000元 的操作。这样就会导致账户A虽然减去了1000元,但是账户B没有收到这个转过来的1000元。
所以这2个操作必须要具备原子性才能保证不出现一些意外的问题。
同样地反映到并发编程中会出现什么结果呢?
举个最简单的例子,大家想一下假如为一个32位的变量赋值过程不具备原子性的话,会发生什么后果?
假若一个线程执行到这个语句时,我暂且假设为一个32位的变量赋值包括两个过程:为低16位赋值,为高16位赋值。
那么就可能发生一种情况:当将低16位数值写入之后,突然被中断,而此时又有一个线程去读取i的值,那么读取到的就是错误的数据。
2.可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
举个简单的例子,看下面这段代码:
|
1
2
3
4
5
6
|
int
i =
0
;
i =
10
;
j = i;
|
假若执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10.
这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。
3.有序性
有序性:即程序执行的顺序按照代码的先后顺序执行。举个简单的例子,看下面这段代码:
|
1
2
3
4
|
int
i =
0
;
boolean
flag =
false
;
i =
1
;
flag =
true
;
|
上面代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
下面解释一下什么是指令重排序,一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
比如上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。
但是要注意,虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢?再看下面一个例子:
|
1
2
3
4
|
int
a =
10
;
int
r =
2
;
a = a +
3
;
r = a*a;
|
这段代码有4个语句,那么可能的一个执行顺序是:

那么可不可能是这个执行顺序呢: 语句2 语句1 语句4 语句3
不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。
虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子:
|
1
2
3
4
5
6
7
8
9
|
context = loadContext();
inited =
true
;
while
(!inited ){
sleep()
}
doSomethingwithconfig(context);
|
上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时context并没有被初始化,就会导致程序出错。
从上面可以看出,指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。
也就是说,要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
三.Java内存模型
在前面谈到了一些关于内存模型以及并发编程中可能会出现的一些问题。下面我们来看一下Java内存模型,研究一下Java内存模型为我们提供了哪些保证以及在java中提供了哪些方法和机制来让我们在进行多线程编程时能够保证程序执行的正确性。
在Java虚拟机规范中试图定义一种Java内存模型(Java Memory Model,JMM)来屏蔽各个硬件平台和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果。那么Java内存模型规定了哪些东西呢,它定义了程序中变量的访问规则,往大一点说是定义了程序执行的次序。注意,为了获得较好的执行性能,Java内存模型并没有限制执行引擎使用处理器的寄存器或者高速缓存来提升指令执行速度,也没有限制编译器对指令进行重排序。也就是说,在java内存模型中,也会存在缓存一致性问题和指令重排序的问题。
Java内存模型规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
举个简单的例子:在java中,执行下面这个语句:
执行线程必须先在自己的工作线程中对变量i所在的缓存行进行赋值操作,然后再写入主存当中。而不是直接将数值10写入主存当中。
那么Java语言 本身对 原子性、可见性以及有序性提供了哪些保证呢?
1.原子性
在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。
上面一句话虽然看起来简单,但是理解起来并不是那么容易。看下面一个例子i:
请分析以下哪些操作是原子性操作:
|
1
2
3
4
|
x =
10
;
y = x;
x++;
x = x +
1
;
|
咋一看,有些朋友可能会说上面的4个语句中的操作都是原子性操作。其实只有语句1是原子性操作,其他三个语句都不是原子性操作。
语句1是直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中。
语句2实际上包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及 将x的值写入工作内存 这2个操作都是原子性操作,但是合起来就不是原子性操作了。
同样的,x++和 x = x+1包括3个操作:读取x的值,进行加1操作,写入新的值。
所以上面4个语句只有语句1的操作具备原子性。
也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
不过这里有一点需要注意:在32位平台下,对64位数据的读取和赋值是需要通过两个操作来完成的,不能保证其原子性。但是好像在最新的JDK中,JVM已经保证对64位数据的读取和赋值也是原子性操作了。
从上面可以看出,Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
2.可见性
对于可见性,Java提供了volatile关键字来保证可见性。
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
3.有序性
在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
在Java里面,可以通过volatile关键字来保证一定的“有序性”(具体原理在下一节讲述)。另外可以通过synchronized和Lock来保证有序性,很显然,synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。
另外,Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则。如果两个操作的执行次序无法从happens-before原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
下面就来具体介绍下happens-before原则(先行发生原则):
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
- 锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
这8条原则摘自《深入理解Java虚拟机》。
这8条规则中,前4条规则是比较重要的,后4条规则都是显而易见的。
下面我们来解释一下前4条规则:
对于程序次序规则来说,我的理解就是一段程序代码的执行在单个线程中看起来是有序的。注意,虽然这条规则中提到“书写在前面的操作先行发生于书写在后面的操作”,这个应该是程序看起来执行的顺序是按照代码顺序执行的,因为虚拟机可能会对程序代码进行指令重排序。虽然进行重排序,但是最终执行的结果是与程序顺序执行的结果一致的,它只会对不存在数据依赖性的指令进行重排序。因此,在单个线程中,程序执行看起来是有序执行的,这一点要注意理解。事实上,这个规则是用来保证程序在单线程中执行结果的正确性,但无法保证程序在多线程中执行的正确性。
第二条规则也比较容易理解,也就是说无论在单线程中还是多线程中,同一个锁如果出于被锁定的状态,那么必须先对锁进行了释放操作,后面才能继续进行lock操作。
第三条规则是一条比较重要的规则,也是后文将要重点讲述的内容。直观地解释就是,如果一个线程先去写一个变量,然后一个线程去进行读取,那么写入操作肯定会先行发生于读操作。
第四条规则实际上就是体现happens-before原则具备传递性。
四.深入剖析volatile关键字
在前面讲述了很多东西,其实都是为讲述volatile关键字作铺垫,那么接下来我们就进入主题。
1.volatile关键字的两层语义
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
先看一段代码,假如线程1先执行,线程2后执行:
|
1
2
3
4
5
6
7
8
|
boolean
stop =
false
;
while
(!stop){
doSomething();
}
stop =
true
;
|
这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效,然后线程1读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。
那么线程1读取到的就是最新的正确的值。
2.volatile保证原子性吗?
从上面知道volatile关键字保证了操作的可见性,但是volatile能保证对变量的操作是原子性吗?
下面看一个例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public
class
Test {
public
volatile
int
inc =
0
;
public
void
increase() {
inc++;
}
public
static
void
main(String[] args) {
final
Test test =
new
Test();
for
(
int
i=
0
;i<
10
;i++){
new
Thread(){
public
void
run() {
for
(
int
j=
0
;j<
1000
;j++)
test.increase();
};
}.start();
}
while
(Thread.activeCount()>
1
)
Thread.yield();
System.out.println(test.inc);
}
}
|
大家想一下这段程序的输出结果是多少?也许有些朋友认为是10000。但是事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。
可能有的朋友就会有疑问,不对啊,上面是对变量inc进行自增操作,由于volatile保证了可见性,那么在每个线程中对inc自增完之后,在其他线程中都能看到修改后的值啊,所以有10个线程分别进行了1000次操作,那么最终inc的值应该是1000*10=10000。
这里面就有一个误区了,volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。
在前面已经提到过,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现:
假如某个时刻变量inc的值为10,
线程1对变量进行自增操作,线程1先读取了变量inc的原始值,然后线程1被阻塞了;
然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,所以线程2会直接去主存读取inc的值,发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值,注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11,然后将11写入工作内存,最后写入主存。
那么两个线程分别进行了一次自增操作后,inc只增加了1。
解释到这里,可能有朋友会有疑问,不对啊,前面不是保证一个变量在修改volatile变量时,会让缓存行无效吗?然后其他线程去读就会读到新的值,对,这个没错。这个就是上面的happens-before规则中的volatile变量规则,但是要注意,线程1对变量进行读取操作之后,被阻塞了的话,并没有对inc值进行修改。然后虽然volatile能保证线程2对变量inc的值读取是从内存中读取的,但是线程1没有进行修改,所以线程2根本就不会看到修改的值。
根源就在这里,自增操作不是原子性操作,而且volatile也无法保证对变量的任何操作都是原子性的。
把上面的代码改成以下任何一种都可以达到效果:
采用synchronized:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public
class
Test {
public
int
inc =
0
;
public
synchronized
void
increase() {
inc++;
}
public
static
void
main(String[] args) {
final
Test test =
new
Test();
for
(
int
i=
0
;i<
10
;i++){
new
Thread(){
public
void
run() {
for
(
int
j=
0
;j<
1000
;j++)
test.increase();
};
}.start();
}
while
(Thread.activeCount()>
1
)
Thread.yield();
System.out.println(test.inc);
}
}
|
采用Lock:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
public
class
Test {
public
int
inc =
0
;
Lock lock =
new
ReentrantLock();
public
void
increase() {
lock.lock();
try
{
inc++;
}
finally
{
lock.unlock();
}
}
public
static
void
main(String[] args) {
final
Test test =
new
Test();
for
(
int
i=
0
;i<
10
;i++){
new
Thread(){
public
void
run() {
for
(
int
j=
0
;j<
1000
;j++)
test.increase();
};
}.start();
}
while
(Thread.activeCount()>
1
)
Thread.yield();
System.out.println(test.inc);
}
}
|
采用AtomicInteger:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public
class
Test {
public
AtomicInteger inc =
new
AtomicInteger();
public
void
increase() {
inc.getAndIncrement();
}
public
static
void
main(String[] args) {
final
Test test =
new
Test();
for
(
int
i=
0
;i<
10
;i++){
new
Thread(){
public
void
run() {
for
(
int
j=
0
;j<
1000
;j++)
test.increase();
};
}.start();
}
while
(Thread.activeCount()>
1
)
Thread.yield();
System.out.println(test.inc);
}
}
|
在java 1.5的java.util.concurrent.atomic包下提供了一些原子操作类,即对基本数据类型的 自增(加1操作),自减(减1操作)、以及加法操作(加一个数),减法操作(减一个数)进行了封装,保证这些操作是原子性操作。atomic是利用CAS来实现原子性操作的(Compare And Swap),CAS实际上是利用处理器提供的CMPXCHG指令实现的,而处理器执行CMPXCHG指令是一个原子性操作。
3.volatile能保证有序性吗?
在前面提到volatile关键字能禁止指令重排序,所以volatile能在一定程度上保证有序性。
volatile关键字禁止指令重排序有两层意思:
1)当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2)在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
可能上面说的比较绕,举个简单的例子:
|
1
2
3
4
5
6
7
8
|
x =
2
;
y =
0
;
flag =
true
;
x =
4
;
y = -
1
;
|
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会讲语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
并且volatile关键字能保证,执行到语句3时,语句1和语句2必定是执行完毕了的,且语句1和语句2的执行结果对语句3、语句4、语句5是可见的。
那么我们回到前面举的一个例子:
|
1
2
3
4
5
6
7
8
9
|
context = loadContext();
inited =
true
;
while
(!inited ){
sleep()
}
doSomethingwithconfig(context);
|
前面举这个例子的时候,提到有可能语句2会在语句1之前执行,那么久可能导致context还没被初始化,而线程2中就使用未初始化的context去进行操作,导致程序出错。
这里如果用volatile关键字对inited变量进行修饰,就不会出现这种问题了,因为当执行到语句2时,必定能保证context已经初始化完毕。
4.volatile的原理和实现机制
前面讲述了源于volatile关键字的一些使用,下面我们来探讨一下volatile到底如何保证可见性和禁止指令重排序的。
下面这段话摘自《深入理解Java虚拟机》:
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
五.使用volatile关键字的场景
synchronized关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。通常来说,使用volatile必须具备以下2个条件:
1)对变量的写操作不依赖于当前值
2)该变量没有包含在具有其他变量的不变式中
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
事实上,我的理解就是上面的2个条件需要保证操作是原子性操作,才能保证使用volatile关键字的程序在并发时能够正确执行。
下面列举几个Java中使用volatile的几个场景。
1.状态标记量
|
1
2
3
4
5
6
7
8
9
|
volatile
boolean
flag =
false
;
while
(!flag){
doSomething();
}
public
void
setFlag() {
flag =
true
;
}
|
|
1
2
3
4
5
6
7
8
9
10
|
volatile
boolean
inited =
false
;
context = loadContext();
inited =
true
;
while
(!inited ){
sleep()
}
doSomethingwithconfig(context);
|
2.double check
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class
Singleton{
private
volatile
static
Singleton instance =
null
;
private
Singleton() {
}
public
static
Singleton getInstance() {
if
(instance==
null
) {
synchronized
(Singleton.
class
) {
if
(instance==
null
)
instance =
new
Singleton();
}
}
return
instance;
}
}
|
至于为何需要这么写请参考:
HHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
volatile这个关键字可能很多朋友都听说过,或许也都用过。在Java 5之前,它是一个备受争议的关键字,因为在程序中使用它往往会导致出人意料的结果。在Java 5之后,volatile关键字才得以重获生机。
volatile关键字虽然从字面上理解起来比较简单,但是要用好不是一件容易的事情。由于volatile关键字是与Java的内存模型有关的,因此在讲述volatile关键之前,我们先来了解一下与内存模型相关的概念和知识,然后分析了volatile关键字的实现原理,最后给出了几个使用volatile关键字的场景。
以下是本文的目录大纲:
一.内存模型的相关概念
二.并发编程中的三个概念
三.Java内存模型
四..深入剖析volatile关键字
五.使用volatile关键字的场景
若有不正之处请多多谅解,并欢迎批评指正。
请尊重作者劳动成果,转载请标明原文链接:
http://www.cnblogs.com/dolphin0520/p/3920373.html
一.内存模型的相关概念
大家都知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
也就是,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核CPU为例。
比如同时有2个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。
最终结果i的值是1,而不是2。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
也就是说,如果一个变量在多个CPU中都存在缓存(一般在多线程编程时才会出现),那么就可能存在缓存不一致的问题。
为了解决缓存不一致性问题,通常来说有以下2种解决方法:
1)通过在总线加LOCK#锁的方式
2)通过缓存一致性协议
这2种方式都是硬件层面上提供的方式。
在早期的CPU当中,是通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。比如上面例子中 如果一个线程在执行 i = i +1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从变量i所在的内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题。
但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
二.并发编程中的三个概念
在并发编程中,我们通常会遇到以下三个问题:原子性问题,可见性问题,有序性问题。我们先看具体看一下这三个概念:
1.原子性
原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
一个很经典的例子就是银行账户转账问题:
比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元。
试想一下,如果这2个操作不具备原子性,会造成什么样的后果。假如从账户A减去1000元之后,操作突然中止。然后又从B取出了500元,取出500元之后,再执行 往账户B加上1000元 的操作。这样就会导致账户A虽然减去了1000元,但是账户B没有收到这个转过来的1000元。
所以这2个操作必须要具备原子性才能保证不出现一些意外的问题。
同样地反映到并发编程中会出现什么结果呢?
举个最简单的例子,大家想一下假如为一个32位的变量赋值过程不具备原子性的话,会发生什么后果?
假若一个线程执行到这个语句时,我暂且假设为一个32位的变量赋值包括两个过程:为低16位赋值,为高16位赋值。
那么就可能发生一种情况:当将低16位数值写入之后,突然被中断,而此时又有一个线程去读取i的值,那么读取到的就是错误的数据。
2.可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
举个简单的例子,看下面这段代码:
|
1
2
3
4
5
6
|
int
i =
0
;
i =
10
;
j = i;
|
假若执行线程1的是CPU1,执行线程2的是CPU2。由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到CPU1的高速缓存中,然后赋值为10,那么在CPU1的高速缓存当中i的值变为10了,却没有立即写入到主存当中。
此时线程2执行 j = i,它会先去主存读取i的值并加载到CPU2的缓存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10.
这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。
3.有序性
有序性:即程序执行的顺序按照代码的先后顺序执行。举个简单的例子,看下面这段代码:
|
1
2
3
4
|
int
i =
0
;
boolean
flag =
false
;
i =
1
;
flag =
true
;
|
上面代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
下面解释一下什么是指令重排序,一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
比如上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。
但是要注意,虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢?再看下面一个例子:
|
1
2
3
4
|
int
a =
10
;
int
r =
2
;
a = a +
3
;
r = a*a;
|
这段代码有4个语句,那么可能的一个执行顺序是:
那么可不可能是这个执行顺序呢: 语句2 语句1 语句4 语句3
不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。
虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子:
|
1
2
3
4
5
6
7
8
9
|
context = loadContext();
inited =
true
;
while
(!inited ){
sleep()
}
doSomethingwithconfig(context);
|
上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时context并没有被初始化,就会导致程序出错。
从上面可以看出,指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。
也就是说,要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
三.Java内存模型
在前面谈到了一些关于内存模型以及并发编程中可能会出现的一些问题。下面我们来看一下Java内存模型,研究一下Java内存模型为我们提供了哪些保证以及在java中提供了哪些方法和机制来让我们在进行多线程编程时能够保证程序执行的正确性。
在Java虚拟机规范中试图定义一种Java内存模型(Java Memory Model,JMM)来屏蔽各个硬件平台和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果。那么Java内存模型规定了哪些东西呢,它定义了程序中变量的访问规则,往大一点说是定义了程序执行的次序。注意,为了获得较好的执行性能,Java内存模型并没有限制执行引擎使用处理器的寄存器或者高速缓存来提升指令执行速度,也没有限制编译器对指令进行重排序。也就是说,在java内存模型中,也会存在缓存一致性问题和指令重排序的问题。
Java内存模型规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
举个简单的例子:在java中,执行下面这个语句:
执行线程必须先在自己的工作线程中对变量i所在的缓存行进行赋值操作,然后再写入主存当中。而不是直接将数值10写入主存当中。
那么Java语言 本身对 原子性、可见性以及有序性提供了哪些保证呢?
1.原子性
在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。
上面一句话虽然看起来简单,但是理解起来并不是那么容易。看下面一个例子i:
请分析以下哪些操作是原子性操作:
|
1
2
3
4
|
x =
10
;
y = x;
x++;
x = x +
1
;
|
咋一看,有些朋友可能会说上面的4个语句中的操作都是原子性操作。其实只有语句1是原子性操作,其他三个语句都不是原子性操作。
语句1是直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中。
语句2实际上包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及 将x的值写入工作内存 这2个操作都是原子性操作,但是合起来就不是原子性操作了。
同样的,x++和 x = x+1包括3个操作:读取x的值,进行加1操作,写入新的值。
所以上面4个语句只有语句1的操作具备原子性。
也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
不过这里有一点需要注意:在32位平台下,对64位数据的读取和赋值是需要通过两个操作来完成的,不能保证其原子性。但是好像在最新的JDK中,JVM已经保证对64位数据的读取和赋值也是原子性操作了。
从上面可以看出,Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
2.可见性
对于可见性,Java提供了volatile关键字来保证可见性。
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
3.有序性
在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
在Java里面,可以通过volatile关键字来保证一定的“有序性”(具体原理在下一节讲述)。另外可以通过synchronized和Lock来保证有序性,很显然,synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。
另外,Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则。如果两个操作的执行次序无法从happens-before原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
下面就来具体介绍下happens-before原则(先行发生原则):
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
- 锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
这8条原则摘自《深入理解Java虚拟机》。
这8条规则中,前4条规则是比较重要的,后4条规则都是显而易见的。
下面我们来解释一下前4条规则:
对于程序次序规则来说,我的理解就是一段程序代码的执行在单个线程中看起来是有序的。注意,虽然这条规则中提到“书写在前面的操作先行发生于书写在后面的操作”,这个应该是程序看起来执行的顺序是按照代码顺序执行的,因为虚拟机可能会对程序代码进行指令重排序。虽然进行重排序,但是最终执行的结果是与程序顺序执行的结果一致的,它只会对不存在数据依赖性的指令进行重排序。因此,在单个线程中,程序执行看起来是有序执行的,这一点要注意理解。事实上,这个规则是用来保证程序在单线程中执行结果的正确性,但无法保证程序在多线程中执行的正确性。
第二条规则也比较容易理解,也就是说无论在单线程中还是多线程中,同一个锁如果出于被锁定的状态,那么必须先对锁进行了释放操作,后面才能继续进行lock操作。
第三条规则是一条比较重要的规则,也是后文将要重点讲述的内容。直观地解释就是,如果一个线程先去写一个变量,然后一个线程去进行读取,那么写入操作肯定会先行发生于读操作。
第四条规则实际上就是体现happens-before原则具备传递性。
四.深入剖析volatile关键字
在前面讲述了很多东西,其实都是为讲述volatile关键字作铺垫,那么接下来我们就进入主题。
1.volatile关键字的两层语义
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
先看一段代码,假如线程1先执行,线程2后执行:
|
1
2
3
4
5
6
7
8
|
boolean
stop =
false
;
while
(!stop){
doSomething();
}
stop =
true
;
|
这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效,然后线程1读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。
那么线程1读取到的就是最新的正确的值。
2.volatile保证原子性吗?
从上面知道volatile关键字保证了操作的可见性,但是volatile能保证对变量的操作是原子性吗?
下面看一个例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public
class
Test {
public
volatile
int
inc =
0
;
public
void
increase() {
inc++;
}
public
static
void
main(String[] args) {
final
Test test =
new
Test();
for
(
int
i=
0
;i<
10
;i++){
new
Thread(){
public
void
run() {
for
(
int
j=
0
;j<
1000
;j++)
test.increase();
};
}.start();
}
while
(Thread.activeCount()>
1
)
Thread.yield();
System.out.println(test.inc);
}
}
|
大家想一下这段程序的输出结果是多少?也许有些朋友认为是10000。但是事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。
可能有的朋友就会有疑问,不对啊,上面是对变量inc进行自增操作,由于volatile保证了可见性,那么在每个线程中对inc自增完之后,在其他线程中都能看到修改后的值啊,所以有10个线程分别进行了1000次操作,那么最终inc的值应该是1000*10=10000。
这里面就有一个误区了,volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。
在前面已经提到过,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现:
假如某个时刻变量inc的值为10,
线程1对变量进行自增操作,线程1先读取了变量inc的原始值,然后线程1被阻塞了;
然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,所以线程2会直接去主存读取inc的值,发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值,注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11,然后将11写入工作内存,最后写入主存。
那么两个线程分别进行了一次自增操作后,inc只增加了1。
解释到这里,可能有朋友会有疑问,不对啊,前面不是保证一个变量在修改volatile变量时,会让缓存行无效吗?然后其他线程去读就会读到新的值,对,这个没错。这个就是上面的happens-before规则中的volatile变量规则,但是要注意,线程1对变量进行读取操作之后,被阻塞了的话,并没有对inc值进行修改。然后虽然volatile能保证线程2对变量inc的值读取是从内存中读取的,但是线程1没有进行修改,所以线程2根本就不会看到修改的值。
根源就在这里,自增操作不是原子性操作,而且volatile也无法保证对变量的任何操作都是原子性的。
把上面的代码改成以下任何一种都可以达到效果:
采用synchronized:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public
class
Test {
public
int
inc =
0
;
public
synchronized
void
increase() {
inc++;
}
public
static
void
main(String[] args) {
final
Test test =
new
Test();
for
(
int
i=
0
;i<
10
;i++){
new
Thread(){
public
void
run() {
for
(
int
j=
0
;j<
1000
;j++)
test.increase();
};
}.start();
}
while
(Thread.activeCount()>
1
)
Thread.yield();
System.out.println(test.inc);
}
}
|
采用Lock:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
public
class
Test {
public
int
inc =
0
;
Lock lock =
new
ReentrantLock();
public
void
increase() {
lock.lock();
try
{
inc++;
}
finally
{
lock.unlock();
}
}
public
static
void
main(String[] args) {
final
Test test =
new
Test();
for
(
int
i=
0
;i<
10
;i++){
new
Thread(){
public
void
run() {
for
(
int
j=
0
;j<
1000
;j++)
test.increase();
};
}.start();
}
while
(Thread.activeCount()>
1
)
Thread.yield();
System.out.println(test.inc);
}
}
|
采用AtomicInteger:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public
class
Test {
public
AtomicInteger inc =
new
AtomicInteger();
public
void
increase() {
inc.getAndIncrement();
}
public
static
void
main(String[] args) {
final
Test test =
new
Test();
for
(
int
i=
0
;i<
10
;i++){
new
Thread(){
public
void
run() {
for
(
int
j=
0
;j<
1000
;j++)
test.increase();
};
}.start();
}
while
(Thread.activeCount()>
1
)
Thread.yield();
System.out.println(test.inc);
}
}
|
在java 1.5的java.util.concurrent.atomic包下提供了一些原子操作类,即对基本数据类型的 自增(加1操作),自减(减1操作)、以及加法操作(加一个数),减法操作(减一个数)进行了封装,保证这些操作是原子性操作。atomic是利用CAS来实现原子性操作的(Compare And Swap),CAS实际上是利用处理器提供的CMPXCHG指令实现的,而处理器执行CMPXCHG指令是一个原子性操作。
3.volatile能保证有序性吗?
在前面提到volatile关键字能禁止指令重排序,所以volatile能在一定程度上保证有序性。
volatile关键字禁止指令重排序有两层意思:
1)当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2)在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
可能上面说的比较绕,举个简单的例子:
|
1
2
3
4
5
6
7
8
|
x =
2
;
y =
0
;
flag =
true
;
x =
4
;
y = -
1
;
|
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会讲语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
并且volatile关键字能保证,执行到语句3时,语句1和语句2必定是执行完毕了的,且语句1和语句2的执行结果对语句3、语句4、语句5是可见的。
那么我们回到前面举的一个例子:
|
1
2
3
4
5
6
7
8
9
|
context = loadContext();
inited =
true
;
while
(!inited ){
sleep()
}
doSomethingwithconfig(context);
|
前面举这个例子的时候,提到有可能语句2会在语句1之前执行,那么久可能导致context还没被初始化,而线程2中就使用未初始化的context去进行操作,导致程序出错。
这里如果用volatile关键字对inited变量进行修饰,就不会出现这种问题了,因为当执行到语句2时,必定能保证context已经初始化完毕。
4.volatile的原理和实现机制
前面讲述了源于volatile关键字的一些使用,下面我们来探讨一下volatile到底如何保证可见性和禁止指令重排序的。
下面这段话摘自《深入理解Java虚拟机》:
“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
五.使用volatile关键字的场景
synchronized关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。通常来说,使用volatile必须具备以下2个条件:
1)对变量的写操作不依赖于当前值
2)该变量没有包含在具有其他变量的不变式中
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
事实上,我的理解就是上面的2个条件需要保证操作是原子性操作,才能保证使用volatile关键字的程序在并发时能够正确执行。
下面列举几个Java中使用volatile的几个场景。
1.状态标记量
|
1
2
3
4
5
6
7
8
9
|
volatile
boolean
flag =
false
;
while
(!flag){
doSomething();
}
public
void
setFlag() {
flag =
true
;
}
|
|
1
2
3
4
5
6
7
8
9
10
|
volatile
boolean
inited =
false
;
context = loadContext();
inited =
true
;
while
(!inited ){
sleep()
}
doSomethingwithconfig(context);
|
2.double check
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class
Singleton{
private
volatile
static
Singleton instance =
null
;
private
Singleton() {
}
public
static
Singleton getInstance() {
if
(instance==
null
) {
synchronized
(Singleton.
class
) {
if
(instance==
null
)
instance =
new
Singleton();
}
}
return
instance;
}
}
|
至于为何需要这么写请参考:
《Java 中的双重检查(Double-Check)》http://blog.csdn.net/dl88250/article/details/5439024
和http://www.iteye.com/topic/652440
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
为何要使用同步?
java允许多线程并发控制,当多个线程同时操作一个可共享的资源变量时(如数据的增删改查),
将会导致数据不准确,相互之间产生冲突,因此加入同步锁以避免在该线程没有完成操作之前,被其他线程的调用,
从而保证了该变量的唯一性和准确性。
同步的方式
1.同步方法
即有synchronized关键字修饰的方法。
由于java的每个对象都有一个内置锁,当用此关键字修饰方法时,
内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。
代码如:
public synchronized void save(){}
注: synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类
2.同步代码块
即有synchronized关键字修饰的语句块。
被该关键字修饰的语句块会自动被加上内置锁,从而实现同步
代码如:
synchronized(object){
}
注:同步是一种高开销的操作,因此应该尽量减少同步的内容。
通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
package com.xhj.thread;
/**
* 线程同步的运用
*
* @author XIEHEJUN
*
*/
public class SynchronizedThread {
class Bank {
private int account = 100;
public int getAccount() {
return account;
}
/**
* 用同步方法实现
*
* @param money
*/
public synchronized void save(int money) {
account += money;
}
/**
* 用同步代码块实现
*
* @param money
*/
public void save1(int money) {
synchronized (this) {
account += money;
}
}
}
class NewThread implements Runnable {
private Bank bank;
public NewThread(Bank bank) {
this.bank = bank;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
bank.save(10);
System.out.println(i + "账户余额为:" + bank.getAccount());
}
}
}
/**
* 建立线程,调用内部类
*/
public void useThread() {
Bank bank = new Bank();
NewThread new_thread = new NewThread(bank);
System.out.println("线程1");
Thread thread1 = new Thread(new_thread);
thread1.start();
System.out.println("线程2");
Thread thread2 = new Thread(new_thread);
thread2.start();
}
public static void main(String[] args) {
SynchronizedThread st = new SynchronizedThread();
st.useThread();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
3.使用特殊域变量(volatile)实现线程同步
a.volatile关键字为域变量的访问提供了一种免锁机制,
b.使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新,
c.因此每次使用该域就要重新计算,而不是使用寄存器中的值
d.volatile不会提供任何原子操作,它也不能用来修饰final类型的变量
例如:
在上面的例子当中,只需在account前面加上volatile修饰,即可实现线程同步。
代码实例:
class Bank {
private volatile int account = 100;
public int getAccount() {
return account;
}
public void save(int money) {
account += money;
}
}
多线程中的非同步问题主要出现在对域的读写上,如果让域自身避免这个问题,则就不需要修改操作该域的方法。
4.使用重入锁实现线程同步
在JavaSE5.0中新增了一个java.util.concurrent包来支持同步。
ReentrantLock类是可重入、互斥、实现了Lock接口的锁,
它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力
ReenreantLock类的常用方法有:
ReentrantLock() : 创建一个ReentrantLock实例
lock() : 获得锁
unlock() : 释放锁
class Bank {
private int account = 100;
private Lock lock = new ReentrantLock();
public int getAccount() {
return account;
}
public void save(int money) {
lock.lock();
try{
account += money;
}finally{
lock.unlock();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
注:关于Lock对象和synchronized关键字的选择:
a.最好两个都不用,使用一种java.util.concurrent包提供的机制,
能够帮助用户处理所有与锁相关的代码。
b.如果synchronized关键字能满足用户的需求,就用synchronized,因为它能简化代码
c.如果需要更高级的功能,就用ReentrantLock类,此时要注意及时释放锁,否则会出现死锁,通常在finally代码释放锁
5.使用局部变量实现线程同步
如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,
副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响。
ThreadLocal 类的常用方法
ThreadLocal() : 创建一个线程本地变量
get() : 返回此线程局部变量的当前线程副本中的值
initialValue() : 返回此线程局部变量的当前线程的"初始值"
set(T value) : 将此线程局部变量的当前线程副本中的值设置为value
例如:
在上面例子基础上,修改后的代码为:
代码实例:
public class Bank{
private static ThreadLocal<Integer> account = new ThreadLocal<Integer>(){
@Override
protected Integer initialValue(){
return 100;
}
};
public void save(int money){
account.set(account.get()+money);
}
public int getAccount(){
return account.get();
}
}
注:ThreadLocal与同步机制
a.ThreadLocal与同步机制都是为了解决多线程中相同变量的访问冲突问题。
b.前者采用以”空间换时间”的方法,后者采用以”时间换空间”的方式
PPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPP
后来,随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了。于是就发明了线程,线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。而进程由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成。
进程间通信
1 无名管道通信
2 高级管道通信
3 有名管道通信
4 消息队列通信
5 信号量通信
6 信号
7 共享内存通信
8 套接字通信
TTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTT
每个进程有自己的地址空间。两个进程中的地址即使值相同,实际指向的位置也不同。进程间通信一般通过操作系统的公共区进行。
同一进程中的线程因属同一地址空间,可直接通信。
不仅是系统内部独立运行的实体,而且是独立竞争资源的实体。
线程也被称为轻权进程,同一进程的线程共享全局变量和内存,使得线程之间共享数据很容易也很方便,但会带来某些共享数据的互斥问题。
许对程序为了提高效率也都是用了线程来编写。
父子进程的派生是非常昂贵的,而且父子进程的通讯需要ipc或者其他方法来实现,比较麻烦。而线程的创建就花费少得多,并且同一进程内的线程共享全局存储区,所以通讯方便。
线程的缺点也是由它的优点造成的,主要是同步,异步和互斥的问题,值得在使用的时候小心设计。
只有进程间需要通信,同一进程的线程share地址空间,没有通信的必要,但要做好同步/互斥mutex,保护共享的全局变量。线程拥有自己的栈。同步/互斥是原语primitives.
而进程间通信无论是信号,管道pipe还是共享内存都是由操作系统保证的,是系统调用.
线程间通信:由于多线程共享地址空间和数据空间,所以多个线程间的通信是一个线程的数据可以直接提供给其他线程使用,而不必通过操作系统(也就是内核的调度)。
进程间的通信则不同,它的数据空间的独立性决定了它的通信相对比较复杂,需要通过操作系统。以前进程间的通信只能是单机版的,现在操作系统都继承了基于套接字(socket)的进程间的通信机制。这样进程间的通信就不局限于单台计算机了,实现了网络通信。
一、进程间的通信方式
# 管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
# 有名管道 (namedpipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
# 信号量(semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
# 消息队列( messagequeue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
# 信号 (sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
# 共享内存(shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
# 套接字(socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
二、线程间的通信方式
# 锁机制:包括互斥锁、条件变量、读写锁
*互斥锁提供了以排他方式防止数据结构被并发修改的方法。
*读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
*条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
# 信号量机制(Semaphore):包括无名线程信号量和命名线程信号量
# 信号机制(Signal):类似进程间的信号处理
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
路漫漫其修远兮,吾将上下而求索
EEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEE
Linux进程类别
虽然我们在区分Linux进程类别, 但是我还是想说Linux下只有一种类型的进程,那就是task_struct,当然我也想说linux其实也没有线程的概念, 只是将那些与其他进程共享资源的进程称之为线程。
-
一个进程由于其运行空间的不同, 从而有内核线程和用户进程的区分, 内核线程运行在内核空间, 之所以称之为线程是因为它没有虚拟地址空间, 只能访问内核的代码和数据, 而用户进程则运行在用户空间, 但是可以通过中断, 系统调用等方式从用户态陷入内核态。
-
用户进程运行在用户空间上, 而一些通过共享资源实现的一组进程我们称之为线程组, Linux下内核其实本质上没有线程的概念, Linux下线程其实上是与其他进程共享某些资源的进程而已。但是我们习惯上还是称他们为线程或者轻量级进程
因此, Linux上进程分3种,内核线程(或者叫核心进程)、用户进程、用户线程, 当然如果更严谨的,你也可以认为用户进程和用户线程都是用户进程。
关于轻量级进程这个概念, 其实并不等价于线程
不同的操作系统中依据其实现的不同, 轻量级进程其实是一个不一样的概念
详细信息参见 维基百科-LWP轻量级进程
或者本人的另外一篇博客内核线程、轻量级进程、用户线程三种线程概念解惑(线程≠轻量级进程)
In computer operating systems, a light-weight process (LWP) is a means of achieving multitasking. In the traditional meaning of the term, as used in Unix System V and Solaris, a LWP runs in user space on top of a single kernel thread and shares its address space and system resources with other LWPs within the same process. Multiple user level threads, managed by a thread library, can be placed on top of one or many LWPs - allowing multitasking to be done at the user level, which can have some performance benefits.[1]
In some operating systems there is no separate LWP layer between kernel threads and user threads. This means that user threads are implemented directly on top of kernel threads. In those contexts, the term “light-weight process” typically refers to kernel threads and the term “threads” can refer to user threads.[2] On Linux, user threads are implemented by allowing certain processes to share resources, which sometimes leads to these processes to be called “light weight processes”.[3][4] Similarly, in SunOS version 4 onwards (prior to Solaris) “light weight process” referred to user threads.
进程与线程
进程是一个具有独立功能的程序关于某个数据集合的一次运行活动。它可以申请和拥有系统资源,是一个动态的概念,是一个活动的实体。它不只是程序的代码,还包括当前的活动,通过程序计数器的值和处理寄存器的内容来表示。进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时,它才能成为一个活动的实体,我们称其为进程。
通常在一个进程中可以包含若干个线程,它们可以利用进程所拥有的资源。在引入线程的操作系统中,通常都是把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位。由于线程比进程更小,基本上不拥有系统资源,故对它的调度所付出的开销就会小得多,能更高效的提高系统内多个程序间并发执行的程度。
线程和进程的区别在于,子进程和父进程有不同的代码和数据空间,而多个线程则共享数据空间,每个线程有自己的执行堆栈和程序计数器为其执行上下文。多线程主要是为了节约CPU时间,发挥利用,根据具体情况而定。线程的运行中需要使用计算机的内存资源和CPU。
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
线程与进程的区别归纳:
-
地址空间和其它资源:进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。
-
通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。
-
调度和切换:线程上下文切换比进程上下文切换要快得多。
-
在多线程OS中,进程不是一个可执行的实体。
内核线程
内核线程就是内核的分身,一个分身可以处理一件特定事情。这在处理异步事件如异步IO时特别有用。内核线程的使用是廉价的,唯一使用的资源就是内核栈和上下文切换时保存寄存器的空间。支持多线程的内核叫做多线程内核(Multi-Threads kernel )。
linux进程的创建流程
线程机制式现代编程技术中常用的一种抽象概念。该机制提供了同一个程序内共享内存地址空间,打开文件和资源的一组线程。
进程的复制fork和加载execve
我们在Linux下进行进行编程,往往都是通过fork出来一个新的程序,fork从化字面意义上理解就是说”分叉”, 这其实就意味着我们的fork进程并不是真正从无到有被创建出来的。
一个进程,包括代码、数据和分配给进程的资源,它其实是从现有的进程(父进程)复制出的一个副本(子进程),fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,然后如果我们通过execve为子进程加载新的应用程序后,那么新的进程将开始执行新的应用
简单来说,新的进程是通过fork和execve创建的,首先通过fork从父进程分叉出一个基本一致的副本,然后通过execve来加载新的应用程序镜像
- fork生成当前进程的的一个相同副本,该副本成为子进程
原进程(父进程)的所有资源都以适当的方法复制给新的进程(子进程)。因此该系统调用之后,原来的进程就有了两个独立的实例,这两个实例的联系包括:同一组打开文件, 同样的工作目录, 进程虚拟空间(内存)中同样的数据(当然两个进程各有一份副本, 也就是说他们的虚拟地址相同, 但是所对应的物理地址不同)等等。
- execve从一个可执行的二进制程序镜像加载应用程序, 来代替当前运行的进程
换句话说, 加载了一个新的应用程序。因此execv并不是创建新进程
所以我们在linux要创建一个应用程序的时候,其实执行的操作就是
-
首先使用fork复制一个旧的进程
-
然后调用execve在为新的进程加载一个新的应用程序
写时复制技术
有人认为这样大批量的复制会导致执行效率过低。其实在复制过程中,linux采用了写时复制的策略。
写入时复制(Copy-on-write)是一个被使用在程式设计领域的最佳化策略。其基础的观念是,如果有多个呼叫者(callers)同时要求相同资源,他们会共同取得相同的指标指向相同的资源,直到某个呼叫者(caller)尝试修改资源时,系统才会真正复制一个副本(private copy)给该呼叫者,以避免被修改的资源被直接察觉到,这过程对其他的呼叫只都是通透的(transparently)。此作法主要的优点是如果呼叫者并没有修改该资源,就不会有副本(private copy)被建立。
第一代Unix系统实现了一种傻瓜式的进程创建:当发出fork()系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程。这种行为是非常耗时的,这种创建地址空间的方法涉及许多内存访问,消耗许多CPU周期,并且完全破坏了高速缓存中的内容。在大多数情况下,这样做常常是毫无意义的,因为许多子进程通过装入一个新的程序开始它们的执行,这样就完全丢弃了所继承的地址空间。
现在的Linux内核采用一种更为有效的方法,称之为写时复制(Copy On Write,COW)。这种思想相当简单:父进程和子进程共享页帧而不是复制页帧。然而,只要页帧被共享,它们就不能被修改,即页帧被保护。无论父进程还是子进程何时试图写一个共享的页帧,就产生一个异常,这时内核就把这个页复制到一个新的页帧中并标记为可写。原来的页帧仍然是写保护的:当其他进程试图写入时,内核检查写进程是否是这个页帧的唯一属主,如果是,就把这个页帧标记为对这个进程是可写的。
当进程A使用系统调用fork创建一个子进程B时,由于子进程B实际上是父进程A的一个拷贝,
因此会拥有与父进程相同的物理页面.为了节约内存和加快创建速度的目标,fork()函数会让子进程B以只读方式共享父进程A的物理页面.同时将父进程A对这些物理页面的访问权限也设成只读.
这样,当父进程A或子进程B任何一方对这些已共享的物理页面执行写操作时,都会产生页面出错异常(page_fault int14)中断,此时CPU会执行系统提供的异常处理函数do_wp_page()来解决这个异常.
do_wp_page()会对这块导致写入异常中断的物理页面进行取消共享操作,为写进程复制一新的物理页面,使父进程A和子进程B各自拥有一块内容相同的物理页面.最后,从异常处理函数中返回时,CPU就会重新执行刚才导致异常的写入操作指令,使进程继续执行下去.
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值(比如PID)不同。相当于克隆了一个自己。
关于进程创建的
参见 Linux中fork,vfork和clone详解(区别与联系)
不同操作系统线程的实现机制
专门线程支持的系统-LWP机制
线程更好的支持了并发程序设计技术, 在多处理器系统上, 他能保证真正的并行处理。Microsoft Windows或是Sun Solaris等操作系统都对线程进行了支持。
这些系统中都在内核中提供了专门支持线程的机制, Unix System V和Sun Solaris将线程称作为轻量级进程(LWP-Light-weight process),在这些系统中, 相比较重量级进程, 线程被抽象成一种耗费较少资源, 运行迅速的执行单元。
Linux下线程的实现机制
但是Linux实现线程的机制非常独特。从内核的角度来说, 他并没有线程这个概念。Linux把所有的进程都当做进程来实现。内核中并没有准备特别的调度算法或者定义特别的数据结构来表示线程。相反, 线程仅仅被视为一个与其他进程共享某些资源的进程。每个线程都拥有唯一隶属于自己的task_struct, 所以在内核看来, 它看起来就像式一个普通的进程(只是线程和同组的其他进程共享某些资源)
在之前Linux进程描述符task_struct结构体详解–Linux进程的管理与调度(一)和Linux进程ID号–Linux进程的管理与调度(三)中讲解进程的pid号的时候我们就提到了, 进程task_struct中pid存储的是内核对该进程的唯一标示, 即对进程则标示进程号, 对线程来说就是其线程号, 那么对于线程来说一个线程组所有线程与领头线程具有相同的进程号,存入tgid字段
因此getpid()返回当前进程的进程号,返回的应该是tgid值而不是pid的值, 对于用户空间来说同组的线程拥有相同进程号即tpid, 而对于内核来说, 某种成都上来说不存在线程的概念, 那么pid就是内核唯一区分每个进程的标示。
正是linux下组管理, 写时复制等这些巧妙的实现方式
-
linux下进程或者线程的创建开销很小
-
既然不管是线程或者进程内核都是不加区分的,一组共享地址空间或者资源的线程可以组成一个线程组, 那么其他进程即使不共享资源也可以组成进程组, 甚至来说一组进程组也可以组成会话组, 进程组可以简化向所有组内进程发送信号的操作, 一组会话也更能适应多道程序环境
实现机制的区别
总而言之, Linux中线程与专门线程支持系统是完全不同的
Unix System V和Sun Solaris将用户线程称作为轻量级进程(LWP-Light-weight process), 相比较重量级进程, 线程被抽象成一种耗费较少资源, 运行迅速的执行单元。
而对于linux来说, 用户线程只是一种进程间共享资源的手段, 相比较其他系统的进程来说, linux系统的进程本身已经很轻量级了
举个例子来说, 假如我们有一个包括了四个线程的进程,
在提供专门线程支持的系统中, 通常会有一个包含只想四个不同线程的指针的进程描述符。该描述符复制描述像地址空间, 打开的文件这样的共享资源。线程本身再去描述它独占的资源。
相反, Linux仅仅创建了四个进程, 并分配四个普通的task_struct结构, 然后建立这四个进程时制定他们共享某些资源。
内核线程
Linux内核可以看作一个服务进程(管理软硬件资源,响应用户进程的种种合理以及不合理的请求)。内核需要多个执行流并行,为了防止可能的阻塞,多线程化是必要的。
内核线程就是内核的分身,一个分身可以处理一件特定事情。Linux内核使用内核线程来将内核分成几个功能模块,像kswapd、kflushd等,这在处理异步事件如异步IO时特别有用。内核线程的使用是廉价的,唯一使用的资源就是内核栈和上下文切换时保存寄存器的空间。支持多线程的内核叫做多线程内核(Multi-Threads kernel )。内核线程的调度由内核负责,一个内核线程处于阻塞状态时不影响其他的内核线程,因为其是调度的基本单位。这与用户线程是不一样的。
内核线程只运行在内核态,不受用户态上下文的拖累。
内核线程与普通进程的异同
-
跟普通进程一样,内核线程也有优先级和被调度。
当和用户进程拥有相同的static_prio 时,内核线程有机会得到更多的cpu资源
-
内核线程的bug直接影响内核,很容易搞死整个系统, 但是用户进程处在内核的管理下,其bug最严重的情况也只会把自己整崩溃
-
内核线程没有自己的地址空间,所以它们的”current->mm”都是空的;
-
内核线程只能在内核空间操作,不能与用户空间交互;
内核线程不需要访问用户空间内存,这是再好不过了。所以内核线程的task_struct的mm域为空
但是刚才说过,内核线程还有核心堆栈,没有mm怎么访问它的核心堆栈呢?这个核心堆栈跟task_struct的thread_info共享8k的空间,所以不用mm描述。
但是内核线程总要访问内核空间的其他内核啊,没有mm域毕竟是不行的。
所以内核线程被调用时, 内核会将其task_strcut的active_mm指向前一个被调度出的进程的mm域, 在需要的时候,内核线程可以使用前一个进程的内存描述符。
因为内核线程不访问用户空间,只操作内核空间内存,而所有进程的内核空间都是一样的。这样就省下了一个mm域的内存。
内核线程创建
在内核中,有两种方法可以生成内核线程,一种是使用kernel_thread()接口,另一种是用kthread_create()接口
kernel_thread
先说kernel_thread接口,使用该接口创建的线程,必须在该线程中调用daemonize()函数,这是因为只有当线程的父进程指向”Kthreadd”时,该线程才算是内核线程,而恰好daemonize()函数主要工作便是将该线程的父进程改成“kthreadd”内核线程;默认情况下,调用deamonize()后,会阻塞所有信号,如果想操作某个信号可以调用allow_signal()函数。
int kernel_thread(int (*fn)(void *), void *arg, unsigned long flags);
void daemonize(const char * name,...);
kthread_create
而kthread_create接口,则是标准的内核线程创建接口,只须调用该接口便可创建内核线程;默认创建的线程是存于不可运行的状态,所以需要在父进程中通过调用wake_up_process()函数来启动该线程。
struct task_struct *kthread_create(int (*threadfn)(void *data),void *data,
const char namefmt[], ...);
线程创建后,不会马上运行,而是需要将kthread_create() 返回的task_struct指针传给wake_up_process(),然后通过此函数运行线程。
kthread_run
当然,还有一个创建并启动线程的函数:kthread_run
struct task_struct *kthread_run(int (*threadfn)(void *data),
void *data,
const char *namefmt, ...);
线程一旦启动起来后,会一直运行,除非该线程主动调用do_exit函数,或者其他的进程调用kthread_stop函数,结束线程的运行。
int kthread_stop(struct task_struct *thread);
kthread_stop() 通过发送信号给线程。
如果线程函数正在处理一个非常重要的任务,它不会被中断的。当然如果线程函数永远不返回并且不检查信号,它将永远都不会停止。
```c
int wake_up_process(struct task_struct *p);
struct task_struct *kthread_run(int (*threadfn)(void *data),void *data,
const char namefmt[], ...);
因为线程也是进程,所以其结构体也是使用进程的结构体”struct task_struct”。
内核线程的退出
当线程执行到函数末尾时会自动调用内核中do_exit()函数来退出或其他线程调用kthread_stop()来指定线程退出。
总结
Linux使用task_struct来描述进程和线程
-
一个进程由于其运行空间的不同, 从而有内核线程和用户进程的区分, 内核线程运行在内核空间, 之所以称之为线程是因为它没有虚拟地址空间, 只能访问内核的代码和数据, 而用户进程则运行在用户空间, 不能直接访问内核的数据但是可以通过中断, 系统调用等方式从用户态陷入内核态,但是内核态只是进程的一种状态, 与内核线程有本质区别
-
用户进程运行在用户空间上, 而一些通过共享资源实现的一组进程我们称之为线程组, Linux下内核其实本质上没有线程的概念, Linux下线程其实上是与其他进程共享某些资源的进程而已。但是我们习惯上还是称他们为线程或者轻量级进程
因此, Linux上进程分3种,内核线程(或者叫核心进程)、用户进程、用户线程, 当然如果更严谨的,你也可以认为用户进程和用户线程都是用户进程。
内核线程拥有 进程描述符、PID、进程正文段、核心堆栈
用户进程拥有 进程描述符、PID、进程正文段、核心堆栈 、用户空间的数据段和堆栈
用户线程拥有 进程描述符、PID、进程正文段、核心堆栈,同父进程共享用户空间的数据段和堆栈
用户线程也可以通过exec函数族拥有自己的用户空间的数据段和堆栈,成为用户进程。
EEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEE
JJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJ
进程间通信(IPC,InterProcess Communication)是指在不同进程之间传播或交换信息。
IPC的方式通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享存储、Socket、Streams等。其中 Socket和Streams支持不同主机上的两个进程IPC。
以Linux中的C语言编程为例。
一、管道
管道,通常指无名管道,是 UNIX 系统IPC最古老的形式。
1、特点:
-
它是半双工的(即数据只能在一个方向上流动),具有固定的读端和写端。
-
它只能用于具有亲缘关系的进程之间的通信(也是父子进程或者兄弟进程之间)。
-
它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write 等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
一、管道
管道,通常指无名管道,是 UNIX 系统IPC最古老的形式。
1、特点:
-
它是半双工的(即数据只能在一个方向上流动),具有固定的读端和写端。
-
它只能用于具有亲缘关系的进程之间的通信(也是父子进程或者兄弟进程之间)。
-
它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write 等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
2、原型:
1 #include <unistd.h>
2 int pipe(int fd[2]); // 返回值:若成功返回0,失败返回-1
当一个管道建立时,它会创建两个文件描述符:fd[0]为读而打开,fd[1]为写而打开。如下图:

要关闭管道只需将这两个文件描述符关闭即可。
3、例子
单个进程中的管道几乎没有任何用处。所以,通常调用 pipe 的进程接着调用 fork,这样就创建了父进程与子进程之间的 IPC 通道。如下图所示:

若要数据流从父进程流向子进程,则关闭父进程的读端(fd[0])与子进程的写端(fd[1]);反之,则可以使数据流从子进程流向父进程。
1 #include<stdio.h>
2 #include<unistd.h>
3
4 int main()
5 {
6 int fd[2]; // 两个文件描述符
7 pid_t pid;
8 char buff[20];
9
10 if(pipe(fd) < 0) // 创建管道
11 printf("Create Pipe Error!\n");
12
13 if((pid = fork()) < 0) // 创建子进程
14 printf("Fork Error!\n");
15 else if(pid > 0) // 父进程
16 {
17 close(fd[0]); // 关闭读端
18 write(fd[1], "hello world\n", 12);
19 }
20 else
21 {
22 close(fd[1]); // 关闭写端
23 read(fd[0], buff, 20);
24 printf("%s", buff);
25 }
26
27 return 0;
28 }
二、FIFO
FIFO,也称为命名管道,它是一种文件类型。
1、特点
-
FIFO可以在无关的进程之间交换数据,与无名管道不同。
-
FIFO有路径名与之相关联,它以一种特殊设备文件形式存在于文件系统中。
2、原型
1 #include <sys/stat.h>
2 // 返回值:成功返回0,出错返回-1
3 int mkfifo(const char *pathname, mode_t mode);
其中的 mode 参数与open函数中的 mode 相同。一旦创建了一个 FIFO,就可以用一般的文件I/O函数操作它。
当 open 一个FIFO时,是否设置非阻塞标志(O_NONBLOCK)的区别:
3、例子
FIFO的通信方式类似于在进程中使用文件来传输数据,只不过FIFO类型文件同时具有管道的特性。在数据读出时,FIFO管道中同时清除数据,并且“先进先出”。下面的例子演示了使用 FIFO 进行 IPC 的过程:
write_fifo.c
1 #include<stdio.h>
2 #include<stdlib.h> // exit
3 #include<fcntl.h> // O_WRONLY
4 #include<sys/stat.h>
5 #include<time.h> // time
6
7 int main()
8 {
9 int fd;
10 int n, i;
11 char buf[1024];
12 time_t tp;
13
14 printf("I am %d process.\n", getpid()); // 说明进程ID
15
16 if((fd = open("fifo1", O_WRONLY)) < 0) // 以写打开一个FIFO
17 {
18 perror("Open FIFO Failed");
19 exit(1);
20 }
21
22 for(i=0; i<10; ++i)
23 {
24 time(&tp); // 取系统当前时间
25 n=sprintf(buf,"Process %d's time is %s",getpid(),ctime(&tp));
26 printf("Send message: %s", buf); // 打印
27 if(write(fd, buf, n+1) < 0) // 写入到FIFO中
28 {
29 perror("Write FIFO Failed");
30 close(fd);
31 exit(1);
32 }
33 sleep(1); // 休眠1秒
34 }
35
36 close(fd); // 关闭FIFO文件
37 return 0;
38 }
read_fifo.c
1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<errno.h>
4 #include<fcntl.h>
5 #include<sys/stat.h>
6
7 int main()
8 {
9 int fd;
10 int len;
11 char buf[1024];
12
13 if(mkfifo("fifo1", 0666) < 0 && errno!=EEXIST) // 创建FIFO管道
14 perror("Create FIFO Failed");
15
16 if((fd = open("fifo1", O_RDONLY)) < 0) // 以读打开FIFO
17 {
18 perror("Open FIFO Failed");
19 exit(1);
20 }
21
22 while((len = read(fd, buf, 1024)) > 0) // 读取FIFO管道
23 printf("Read message: %s", buf);
24
25 close(fd); // 关闭FIFO文件
26 return 0;
27 }
在两个终端里用 gcc 分别编译运行上面两个文件,可以看到输出结果如下:
1 [cheesezh@localhost]$ ./write_fifo
2 I am 5954 process.
3 Send message: Process 5954's time is Mon Apr 20 12:37:28 2015
4 Send message: Process 5954's time is Mon Apr 20 12:37:29 2015
5 Send message: Process 5954's time is Mon Apr 20 12:37:30 2015
6 Send message: Process 5954's time is Mon Apr 20 12:37:31 2015
7 Send message: Process 5954's time is Mon Apr 20 12:37:32 2015
8 Send message: Process 5954's time is Mon Apr 20 12:37:33 2015
9 Send message: Process 5954's time is Mon Apr 20 12:37:34 2015
10 Send message: Process 5954's time is Mon Apr 20 12:37:35 2015
11 Send message: Process 5954's time is Mon Apr 20 12:37:36 2015
12 Send message: Process 5954's time is Mon Apr 20 12:37:37 2015
1 [cheesezh@localhost]$ ./read_fifo
2 Read message: Process 5954's time is Mon Apr 20 12:37:28 2015
3 Read message: Process 5954's time is Mon Apr 20 12:37:29 2015
4 Read message: Process 5954's time is Mon Apr 20 12:37:30 2015
5 Read message: Process 5954's time is Mon Apr 20 12:37:31 2015
6 Read message: Process 5954's time is Mon Apr 20 12:37:32 2015
7 Read message: Process 5954's time is Mon Apr 20 12:37:33 2015
8 Read message: Process 5954's time is Mon Apr 20 12:37:34 2015
9 Read message: Process 5954's time is Mon Apr 20 12:37:35 2015
10 Read message: Process 5954's time is Mon Apr 20 12:37:36 2015
11 Read message: Process 5954's time is Mon Apr 20 12:37:37 2015
上述例子可以扩展成 客户进程—服务器进程 通信的实例,write_fifo的作用类似于客户端,可以打开多个客户端向一个服务器发送请求信息,read_fifo类似于服务器,它适时监控着FIFO的读端,当有数据时,读出并进行处理,但是有一个关键的问题是,每一个客户端必须预先知道服务器提供的FIFO接口,下图显示了这种安排:

三、消息队列
消息队列,是消息的链接表,存放在内核中。一个消息队列由一个标识符(即队列ID)来标识。
1、特点
-
消息队列是面向记录的,其中的消息具有特定的格式以及特定的优先级。
-
消息队列独立于发送与接收进程。进程终止时,消息队列及其内容并不会被删除。
-
消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取。
2、原型
1 #include <sys/msg.h>
2 // 创建或打开消息队列:成功返回队列ID,失败返回-1
3 int msgget(key_t key, int flag);
4 // 添加消息:成功返回0,失败返回-1
5 int msgsnd(int msqid, const void *ptr, size_t size, int flag);
6 // 读取消息:成功返回消息数据的长度,失败返回-1
7 int msgrcv(int msqid, void *ptr, size_t size, long type,int flag);
8 // 控制消息队列:成功返回0,失败返回-1
9 int msgctl(int msqid, int cmd, struct msqid_ds *buf);
在以下两种情况下,msgget将创建一个新的消息队列:
- 如果没有与键值key相对应的消息队列,并且flag中包含了
IPC_CREAT标志位。 - key参数为
IPC_PRIVATE。
函数msgrcv在读取消息队列时,type参数有下面几种情况:
type == 0,返回队列中的第一个消息;type > 0,返回队列中消息类型为 type 的第一个消息;type < 0,返回队列中消息类型值小于或等于 type 绝对值的消息,如果有多个,则取类型值最小的消息。
可以看出,type值非 0 时用于以非先进先出次序读消息。也可以把 type 看做优先级的权值。(其他的参数解释,请自行Google之)
3、例子
下面写了一个简单的使用消息队列进行IPC的例子,服务端程序一直在等待特定类型的消息,当收到该类型的消息以后,发送另一种特定类型的消息作为反馈,客户端读取该反馈并打印出来。
msg_server.c

1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <sys/msg.h>
4
5 // 用于创建一个唯一的key
6 #define MSG_FILE "/etc/passwd"
7
8 // 消息结构
9 struct msg_form {
10 long mtype;
11 char mtext[256];
12 };
13
14 int main()
15 {
16 int msqid;
17 key_t key;
18 struct msg_form msg;
19
20 // 获取key值
21 if((key = ftok(MSG_FILE,'z')) < 0)
22 {
23 perror("ftok error");
24 exit(1);
25 }
26
27 // 打印key值
28 printf("Message Queue - Server key is: %d.\n", key);
29
30 // 创建消息队列
31 if ((msqid = msgget(key, IPC_CREAT|0777)) == -1)
32 {
33 perror("msgget error");
34 exit(1);
35 }
36
37 // 打印消息队列ID及进程ID
38 printf("My msqid is: %d.\n", msqid);
39 printf("My pid is: %d.\n", getpid());
40
41 // 循环读取消息
42 for(;;)
43 {
44 msgrcv(msqid, &msg, 256, 888, 0);// 返回类型为888的第一个消息
45 printf("Server: receive msg.mtext is: %s.\n", msg.mtext);
46 printf("Server: receive msg.mtype is: %d.\n", msg.mtype);
47
48 msg.mtype = 999; // 客户端接收的消息类型
49 sprintf(msg.mtext, "hello, I'm server %d", getpid());
50 msgsnd(msqid, &msg, sizeof(msg.mtext), 0);
51 }
52 return 0;
53 }
msg_client.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <sys/msg.h>
4
5 // 用于创建一个唯一的key
6 #define MSG_FILE "/etc/passwd"
7
8 // 消息结构
9 struct msg_form {
10 long mtype;
11 char mtext[256];
12 };
13
14 int main()
15 {
16 int msqid;
17 key_t key;
18 struct msg_form msg;
19
20 // 获取key值
21 if ((key = ftok(MSG_FILE, 'z')) < 0)
22 {
23 perror("ftok error");
24 exit(1);
25 }
26
27 // 打印key值
28 printf("Message Queue - Client key is: %d.\n", key);
29
30 // 打开消息队列
31 if ((msqid = msgget(key, IPC_CREAT|0777)) == -1)
32 {
33 perror("msgget error");
34 exit(1);
35 }
36
37 // 打印消息队列ID及进程ID
38 printf("My msqid is: %d.\n", msqid);
39 printf("My pid is: %d.\n", getpid());
40
41 // 添加消息,类型为888
42 msg.mtype = 888;
43 sprintf(msg.mtext, "hello, I'm client %d", getpid());
44 msgsnd(msqid, &msg, sizeof(msg.mtext), 0);
45
46 // 读取类型为777的消息
47 msgrcv(msqid, &msg, 256, 999, 0);
48 printf("Client: receive msg.mtext is: %s.\n", msg.mtext);
49 printf("Client: receive msg.mtype is: %d.\n", msg.mtype);
50 return 0;
51 }
四、信号量
信号量(semaphore)与已经介绍过的 IPC 结构不同,它是一个计数器。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
1、特点
-
信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。
-
信号量基于操作系统的 PV 操作,程序对信号量的操作都是原子操作。
-
每次对信号量的 PV 操作不仅限于对信号量值加 1 或减 1,而且可以加减任意正整数。
-
支持信号量组。
2、原型
最简单的信号量是只能取 0 和 1 的变量,这也是信号量最常见的一种形式,叫做二值信号量(Binary Semaphore)。而可以取多个正整数的信号量被称为通用信号量。
Linux 下的信号量函数都是在通用的信号量数组上进行操作,而不是在一个单一的二值信号量上进行操作。
1 #include <sys/sem.h>
2 // 创建或获取一个信号量组:若成功返回信号量集ID,失败返回-1
3 int semget(key_t key, int num_sems, int sem_flags);
4 // 对信号量组进行操作,改变信号量的值:成功返回0,失败返回-1
5 int semop(int semid, struct sembuf semoparray[], size_t numops);
6 // 控制信号量的相关信息
7 int semctl(int semid, int sem_num, int cmd, ...);
当semget创建新的信号量集合时,必须指定集合中信号量的个数(即num_sems),通常为1; 如果是引用一个现有的集合,则将num_sems指定为 0 。
在semop函数中,sembuf结构的定义如下:
1 struct sembuf
2 {
3 short sem_num; // 信号量组中对应的序号,0~sem_nums-1
4 short sem_op; // 信号量值在一次操作中的改变量
5 short sem_flg; // IPC_NOWAIT, SEM_UNDO
6 }
其中 sem_op 是一次操作中的信号量的改变量:
-
若sem_op > 0,表示进程释放相应的资源数,将 sem_op 的值加到信号量的值上。如果有进程正在休眠等待此信号量,则换行它们。
-
若sem_op < 0,请求 sem_op 的绝对值的资源。
- 如果相应的资源数可以满足请求,则将该信号量的值减去sem_op的绝对值,函数成功返回。
- 当相应的资源数不能满足请求时,这个操作与
sem_flg有关。
- sem_flg 指定
IPC_NOWAIT,则semop函数出错返回EAGAIN。 - sem_flg 没有指定
IPC_NOWAIT,则将该信号量的semncnt值加1,然后进程挂起直到下述情况发生:
- 当相应的资源数可以满足请求,此信号量的semncnt值减1,该信号量的值减去sem_op的绝对值。成功返回;
- 此信号量被删除,函数smeop出错返回EIDRM;
- 进程捕捉到信号,并从信号处理函数返回,此情况下将此信号量的semncnt值减1,函数semop出错返回EINTR
-
若sem_op == 0,进程阻塞直到信号量的相应值为0:
- 当信号量已经为0,函数立即返回。
- 如果信号量的值不为0,则依据
sem_flg决定函数动作:
- sem_flg指定
IPC_NOWAIT,则出错返回EAGAIN。 - sem_flg没有指定
IPC_NOWAIT,则将该信号量的semncnt值加1,然后进程挂起直到下述情况发生:
- 信号量值为0,将信号量的semzcnt的值减1,函数semop成功返回;
- 此信号量被删除,函数smeop出错返回EIDRM;
- 进程捕捉到信号,并从信号处理函数返回,在此情况将此信号量的semncnt值减1,函数semop出错返回EINTR
在semctl函数中的命令有多种,这里就说两个常用的:
SETVAL:用于初始化信号量为一个已知的值。所需要的值作为联合semun的val成员来传递。在信号量第一次使用之前需要设置信号量。IPC_RMID:删除一个信号量集合。如果不删除信号量,它将继续在系统中存在,即使程序已经退出,它可能在你下次运行此程序时引发问题,而且信号量是一种有限的资源。
3、例子
1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<sys/sem.h>
4
5 // 联合体,用于semctl初始化
6 union semun
7 {
8 int val; /*for SETVAL*/
9 struct semid_ds *buf;
10 unsigned short *array;
11 };
12
13 // 初始化信号量
14 int init_sem(int sem_id, int value)
15 {
16 union semun tmp;
17 tmp.val = value;
18 if(semctl(sem_id, 0, SETVAL, tmp) == -1)
19 {
20 perror("Init Semaphore Error");
21 return -1;
22 }
23 return 0;
24 }
25
26 // P操作:
27 // 若信号量值为1,获取资源并将信号量值-1
28 // 若信号量值为0,进程挂起等待
29 int sem_p(int sem_id)
30 {
31 struct sembuf sbuf;
32 sbuf.sem_num = 0; /*序号*/
33 sbuf.sem_op = -1; /*P操作*/
34 sbuf.sem_flg = SEM_UNDO;
35
36 if(semop(sem_id, &sbuf, 1) == -1)
37 {
38 perror("P operation Error");
39 return -1;
40 }
41 return 0;
42 }
43
44 // V操作:
45 // 释放资源并将信号量值+1
46 // 如果有进程正在挂起等待,则唤醒它们
47 int sem_v(int sem_id)
48 {
49 struct sembuf sbuf;
50 sbuf.sem_num = 0; /*序号*/
51 sbuf.sem_op = 1; /*V操作*/
52 sbuf.sem_flg = SEM_UNDO;
53
54 if(semop(sem_id, &sbuf, 1) == -1)
55 {
56 perror("V operation Error");
57 return -1;
58 }
59 return 0;
60 }
61
62 // 删除信号量集
63 int del_sem(int sem_id)
64 {
65 union semun tmp;
66 if(semctl(sem_id, 0, IPC_RMID, tmp) == -1)
67 {
68 perror("Delete Semaphore Error");
69 return -1;
70 }
71 return 0;
72 }
73
74
75 int main()
76 {
77 int sem_id; // 信号量集ID
78 key_t key;
79 pid_t pid;
80
81 // 获取key值
82 if((key = ftok(".", 'z')) < 0)
83 {
84 perror("ftok error");
85 exit(1);
86 }
87
88 // 创建信号量集,其中只有一个信号量
89 if((sem_id = semget(key, 1, IPC_CREAT|0666)) == -1)
90 {
91 perror("semget error");
92 exit(1);
93 }
94
95 // 初始化:初值设为0资源被占用
96 init_sem(sem_id, 0);
97
98 if((pid = fork()) == -1)
99 perror("Fork Error");
100 else if(pid == 0) /*子进程*/
101 {
102 sleep(2);
103 printf("Process child: pid=%d\n", getpid());
104 sem_v(sem_id); /*释放资源*/
105 }
106 else /*父进程*/
107 {
108 sem_p(sem_id); /*等待资源*/
109 printf("Process father: pid=%d\n", getpid());
110 sem_v(sem_id); /*释放资源*/
111 del_sem(sem_id); /*删除信号量集*/
112 }
113 return 0;
114 }
上面的例子如果不加信号量,则父进程会先执行完毕。这里加了信号量让父进程等待子进程执行完以后再执行。
五、共享内存
共享内存(Shared Memory),指两个或多个进程共享一个给定的存储区。
1、特点
-
共享内存是最快的一种 IPC,因为进程是直接对内存进行存取。
-
因为多个进程可以同时操作,所以需要进行同步。
-
信号量+共享内存通常结合在一起使用,信号量用来同步对共享内存的访问。
2、原型
1 #include <sys/shm.h>
2 // 创建或获取一个共享内存:成功返回共享内存ID,失败返回-1
3 int shmget(key_t key, size_t size, int flag);
4 // 连接共享内存到当前进程的地址空间:成功返回指向共享内存的指针,失败返回-1
5 void *shmat(int shm_id, const void *addr, int flag);
6 // 断开与共享内存的连接:成功返回0,失败返回-1
7 int shmdt(void *addr);
8 // 控制共享内存的相关信息:成功返回0,失败返回-1
9 int shmctl(int shm_id, int cmd, struct shmid_ds *buf);
当用shmget函数创建一段共享内存时,必须指定其 size;而如果引用一个已存在的共享内存,则将 size 指定为0 。
当一段共享内存被创建以后,它并不能被任何进程访问。必须使用shmat函数连接该共享内存到当前进程的地址空间,连接成功后把共享内存区对象映射到调用进程的地址空间,随后可像本地空间一样访问。
shmdt函数是用来断开shmat建立的连接的。注意,这并不是从系统中删除该共享内存,只是当前进程不能再访问该共享内存而已。
shmctl函数可以对共享内存执行多种操作,根据参数 cmd 执行相应的操作。常用的是IPC_RMID(从系统中删除该共享内存)。
3、例子
下面这个例子,使用了【共享内存+信号量+消息队列】的组合来实现服务器进程与客户进程间的通信。
- 共享内存用来传递数据;
- 信号量用来同步;
- 消息队列用来 在客户端修改了共享内存后 通知服务器读取。
server.c
1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<sys/shm.h> // shared memory
4 #include<sys/sem.h> // semaphore
5 #include<sys/msg.h> // message queue
6 #include<string.h> // memcpy
7
8 // 消息队列结构
9 struct msg_form {
10 long mtype;
11 char mtext;
12 };
13
14 // 联合体,用于semctl初始化
15 union semun
16 {
17 int val; /*for SETVAL*/
18 struct semid_ds *buf;
19 unsigned short *array;
20 };
21
22 // 初始化信号量
23 int init_sem(int sem_id, int value)
24 {
25 union semun tmp;
26 tmp.val = value;
27 if(semctl(sem_id, 0, SETVAL, tmp) == -1)
28 {
29 perror("Init Semaphore Error");
30 return -1;
31 }
32 return 0;
33 }
34
35 // P操作:
36 // 若信号量值为1,获取资源并将信号量值-1
37 // 若信号量值为0,进程挂起等待
38 int sem_p(int sem_id)
39 {
40 struct sembuf sbuf;
41 sbuf.sem_num = 0; /*序号*/
42 sbuf.sem_op = -1; /*P操作*/
43 sbuf.sem_flg = SEM_UNDO;
44
45 if(semop(sem_id, &sbuf, 1) == -1)
46 {
47 perror("P operation Error");
48 return -1;
49 }
50 return 0;
51 }
52
53 // V操作:
54 // 释放资源并将信号量值+1
55 // 如果有进程正在挂起等待,则唤醒它们
56 int sem_v(int sem_id)
57 {
58 struct sembuf sbuf;
59 sbuf.sem_num = 0; /*序号*/
60 sbuf.sem_op = 1; /*V操作*/
61 sbuf.sem_flg = SEM_UNDO;
62
63 if(semop(sem_id, &sbuf, 1) == -1)
64 {
65 perror("V operation Error");
66 return -1;
67 }
68 return 0;
69 }
70
71 // 删除信号量集
72 int del_sem(int sem_id)
73 {
74 union semun tmp;
75 if(semctl(sem_id, 0, IPC_RMID, tmp) == -1)
76 {
77 perror("Delete Semaphore Error");
78 return -1;
79 }
80 return 0;
81 }
82
83 // 创建一个信号量集
84 int creat_sem(key_t key)
85 {
86 int sem_id;
87 if((sem_id = semget(key, 1, IPC_CREAT|0666)) == -1)
88 {
89 perror("semget error");
90 exit(-1);
91 }
92 init_sem(sem_id, 1); /*初值设为1资源未占用*/
93 return sem_id;
94 }
95
96
97 int main()
98 {
99 key_t key;
100 int shmid, semid, msqid;
101 char *shm;
102 char data[] = "this is server";
103 struct shmid_ds buf1; /*用于删除共享内存*/
104 struct msqid_ds buf2; /*用于删除消息队列*/
105 struct msg_form msg; /*消息队列用于通知对方更新了共享内存*/
106
107 // 获取key值
108 if((key = ftok(".", 'z')) < 0)
109 {
110 perror("ftok error");
111 exit(1);
112 }
113
114 // 创建共享内存
115 if((shmid = shmget(key, 1024, IPC_CREAT|0666)) == -1)
116 {
117 perror("Create Shared Memory Error");
118 exit(1);
119 }
120
121 // 连接共享内存
122 shm = (char*)shmat(shmid, 0, 0);
123 if((int)shm == -1)
124 {
125 perror("Attach Shared Memory Error");
126 exit(1);
127 }
128
129
130 // 创建消息队列
131 if ((msqid = msgget(key, IPC_CREAT|0777)) == -1)
132 {
133 perror("msgget error");
134 exit(1);
135 }
136
137 // 创建信号量
138 semid = creat_sem(key);
139
140 // 读数据
141 while(1)
142 {
143 msgrcv(msqid, &msg, 1, 888, 0); /*读取类型为888的消息*/
144 if(msg.mtext == 'q') /*quit - 跳出循环*/
145 break;
146 if(msg.mtext == 'r') /*read - 读共享内存*/
147 {
148 sem_p(semid);
149 printf("%s\n",shm);
150 sem_v(semid);
151 }
152 }
153
154 // 断开连接
155 shmdt(shm);
156
157 /*删除共享内存、消息队列、信号量*/
158 shmctl(shmid, IPC_RMID, &buf1);
159 msgctl(msqid, IPC_RMID, &buf2);
160 del_sem(semid);
161 return 0;
162 }
client.c
1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<sys/shm.h> // shared memory
4 #include<sys/sem.h> // semaphore
5 #include<sys/msg.h> // message queue
6 #include<string.h> // memcpy
7
8 // 消息队列结构
9 struct msg_form {
10 long mtype;
11 char mtext;
12 };
13
14 // 联合体,用于semctl初始化
15 union semun
16 {
17 int val; /*for SETVAL*/
18 struct semid_ds *buf;
19 unsigned short *array;
20 };
21
22 // P操作:
23 // 若信号量值为1,获取资源并将信号量值-1
24 // 若信号量值为0,进程挂起等待
25 int sem_p(int sem_id)
26 {
27 struct sembuf sbuf;
28 sbuf.sem_num = 0; /*序号*/
29 sbuf.sem_op = -1; /*P操作*/
30 sbuf.sem_flg = SEM_UNDO;
31
32 if(semop(sem_id, &sbuf, 1) == -1)
33 {
34 perror("P operation Error");
35 return -1;
36 }
37 return 0;
38 }
39
40 // V操作:
41 // 释放资源并将信号量值+1
42 // 如果有进程正在挂起等待,则唤醒它们
43 int sem_v(int sem_id)
44 {
45 struct sembuf sbuf;
46 sbuf.sem_num = 0; /*序号*/
47 sbuf.sem_op = 1; /*V操作*/
48 sbuf.sem_flg = SEM_UNDO;
49
50 if(semop(sem_id, &sbuf, 1) == -1)
51 {
52 perror("V operation Error");
53 return -1;
54 }
55 return 0;
56 }
57
58
59 int main()
60 {
61 key_t key;
62 int shmid, semid, msqid;
63 char *shm;
64 struct msg_form msg;
65 int flag = 1; /*while循环条件*/
66
67 // 获取key值
68 if((key = ftok(".", 'z')) < 0)
69 {
70 perror("ftok error");
71 exit(1);
72 }
73
74 // 获取共享内存
75 if((shmid = shmget(key, 1024, 0)) == -1)
76 {
77 perror("shmget error");
78 exit(1);
79 }
80
81 // 连接共享内存
82 shm = (char*)shmat(shmid, 0, 0);
83 if((int)shm == -1)
84 {
85 perror("Attach Shared Memory Error");
86 exit(1);
87 }
88
89 // 创建消息队列
90 if ((msqid = msgget(key, 0)) == -1)
91 {
92 perror("msgget error");
93 exit(1);
94 }
95
96 // 获取信号量
97 if((semid = semget(key, 0, 0)) == -1)
98 {
99 perror("semget error");
100 exit(1);
101 }
102
103 // 写数据
104 printf("***************************************\n");
105 printf("* IPC *\n");
106 printf("* Input r to send data to server. *\n");
107 printf("* Input q to quit. *\n");
108 printf("***************************************\n");
109
110 while(flag)
111 {
112 char c;
113 printf("Please input command: ");
114 scanf("%c", &c);
115 switch(c)
116 {
117 case 'r':
118 printf("Data to send: ");
119 sem_p(semid); /*访问资源*/
120 scanf("%s", shm);
121 sem_v(semid); /*释放资源*/
122 /*清空标准输入缓冲区*/
123 while((c=getchar())!='\n' && c!=EOF);
124 msg.mtype = 888;
125 msg.mtext = 'r'; /*发送消息通知服务器读数据*/
126 msgsnd(msqid, &msg, sizeof(msg.mtext), 0);
127 break;
128 case 'q':
129 msg.mtype = 888;
130 msg.mtext = 'q';
131 msgsnd(msqid, &msg, sizeof(msg.mtext), 0);
132 flag = 0;
133 break;
134 default:
135 printf("Wrong input!\n");
136 /*清空标准输入缓冲区*/
137 while((c=getchar())!='\n' && c!=EOF);
138 }
139 }
140
141 // 断开连接
142 shmdt(shm);
143
144 return 0;
145 }
注意:当scanf()输入字符或字符串时,缓冲区中遗留下了\n,所以每次输入操作后都需要清空标准输入的缓冲区。但是由于 gcc 编译器不支持fflush(stdin)(它只是标准C的扩展),所以我们使用了替代方案:
1 while((c=getchar())!='\n' && c!=EOF);
参考资料:http://songlee24.github.io/2015/04/21/linux-IPC/
ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
3.临界区同步速度很快,但却只能用来同步本进程内的线程,而不可用来同步多个进程中的线程。
4. 临界区是用户态下的对象,非内核对象,所以在使用时无需再用户态和内核态之间切换,效率明显要比其他用户互斥的内核对象高。
111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111
首先让我们来了解一下什么是内核对象。内核对象通过API来创建,每个内核对象是一个数据结构,它对应一块内存,由操作系统内核分配,并且只能由操作系统内核访问。在此数据结构中少数成员如安全描述符和使用计数是所有对象都有的,但其他大多数成员都是不同类型的对象特有的。内核对象的数据结构只能由操作系统提供的API访问,应用程序在内存中不能访问。调用创建内核对象的函数后,该函数会返回一个句柄,它标识了所创建的对象。它可以由进程的任何线程使用。在32位系统中,句柄是一个32位值。64位系统中则是64位值。
很多人对句柄到底是什么东西很疑惑。有人说是指针有人说是索引。其实句柄仅仅是独立于每个进程的句柄表的一个索引。在每个进程中都存在一个句柄表,列出了所有本进程内可以使用的句柄。它只是一个有数据结构组成的数组,每个结构都包含一个指向内核对象的指针、访问掩码、继承标识等,而句柄仅仅是句柄表数组的下标。由于每个进程都存在句柄表,因此句柄是独立于进程的,虽然将一个进程的句柄传给另一个进程不一定会失败,但是它引用的是另一个进程完全不同的内核对象。
内核对象的所有者是操作系统内核,而非进程。也就是说多个进程可以共享一个内核对象。内核对象数据结构内有一个使用计数成员,它是所有对象都有的一个成员,标识该内核对象被引用的次数。刚创建时使用计数被初始化为1,如果有另一个进程获得对此内核对象的访问后,使用计数就会递增。一个使用此内核对象的进程终止后或是对此内核对象调用CloseHandle,操作系统内核会自动递减内核对象的使用计数。一旦计数变为0,操作系统内核就会销毁对象。
安全描述符用以描述内核对象的安全性。它描述了内核对象的拥有者,那组用户可以访问此对象,那组用户无访问权限。安全描述符对应一个数据结构:SECURITY_ATTRIBUTES结构,几乎内核对象在创建时都需要传入此结构,但是大部分情况下都是传入NULL,表示使用默认的安全性。
除了使用内核对象,应用程序还需要使用其他类型的对象,如菜单、窗口、鼠标光标等,这些属于用户对象或GDI对象,而非内核对象。要判断一个对象是不是内核对象,最简单的方法就是查看创建这个对象的函数,几乎所有的创建内核对象的函数都需要指定安全属性信息的参数,而用于创建用户对象的函数都不需要使用安全描述符。
一个进程在刚被创建时,它的句柄表是空的。当进程内的一个线程调用创建内核对象的函数时,内核将为这个对象分配并初始化一个内存块,然后扫描进程的句柄表,查找一个空白的记录项,并对其进行初始化。指针成员将会被初始化为内核对象的地址,继承标志也会被设置。
用于创建内核对象的函数都会返回一个与进程相关的句柄,此句柄可由属于该进程的所有线程引用。调用一个函数,如果它需要一个内核对象句柄的参数,就必须为它传递一个句柄。在内部,这个函数会查找进程的句柄表,获得目标内核对象的地址然后对此数据结构进行操作。如果我们直接使用其他进程的的句柄,那么实际引用的只是那个进程句柄表中位于同一索引的内核对象,它们仅仅是索引值相同而已。创建内核对象的函数在失败时会返回NULL。但有时也有的函数会返回-1,如CreateFile,它返回的是INVALID_HANDLE_VALUE而不是NULL。失败的原因可能是内存不足或是没有权限。这在检查内核对象是否创建成功时要特别注意。
当进程不再使用某内核对象时应该调用CloseHandle来向系统表明我们已经结束使用此对象。在内部该函数会扫描进程的句柄表,如果句柄是有效的,系统就获得此内核对象的数据结构的地址,并将此结构的使用计数成员递减1。如果使用计数变为0,句柄表对应的记录项将会被清除,内核对象将被销毁,所占内存将会被释放。此后再在此进程内使用此句柄将会发生未知错误。因为调用CloseHandle后此内核对象不知是否已经被销毁,如果没有销毁那么此次对此句柄的使用将没有问题。如果此内核对象已被销毁,且句柄表对应项已经被其他项占据,此时操作的将是另一个内核对象,可能发生无法预知的错误。因此在调用CloseHandle后要最好将原来的变量赋值为NULL。
即使在进程结束了对内核对象的访问后,没有调用CloseHandle,进程终止时,操作系统也会确保进程所使用的所有资源都被释放。系统自动扫描进程句柄表,将所有内核对象的使用计数都减1。同样如存在使用计数为0的内核对象,它就会被释放。但是这毕竟不是个好习惯,如果我们开发的程序是长时间运行的程序,由于没有主动调用CloseHandle,进程已经不再使用的内核对象仍然得不到释放,越往后运行系统所占内存就越大。这跟内存泄露很类似,自己开辟的堆空间不再使用时要自己主动释放。对于内核对象这也同样适用。在任务管理器的Handle列可以查看每个进程占用的内核对象数。
前面说到另一个进程不能直接使用一个进程的内核对象的句柄。注意这里使用直接二字,这并不意味着其他进程不能使用此内核对象,虽然句柄是独立于进程的,但是内核对象是归系统内核所有,各个进程都可以使用,只是要使用还需要费一番周折。接下来将介绍跨进程边界共享内核对象。
跨进程共享内核对象是必要的,1:是利用文件映射对象可以在两个进程间共享数据块。2:互斥量、信号量和事件允许不同进程的线程同步执行。
222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222
222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222
前言
内核对象用于管理进程、线程和文件等诸多种类的大量资源。
3.1 何为内核对象
内核对象包括访问令牌对象、事件对象、文件对象、文件映像对象、I/O完成端口对象、作业对象、邮件槽对象、互斥量对象、管道对象、进程对象、信号量对象、线程对象、可等待的计时器对象以及线程池工厂对象等。每个内核对象都只是一个内存块,它由操作系统内核分配,并只能由操作系统内核访问。这个内存块是一个数据结构,其成员维护着与对象相关的信息。少数成员(安全描述符和使用计数等)是所有对象都有的,但其他大多数成员都是不同类型的对象特有的。应用程序不能在内存中定位这些数据结构并直接更改其内容,应用程序应该利用Windows提供的一组函数,这组函数会以最恰当的方式来操作这些结构。用户始终可以使用这些函数来访问这些内核对象。
调用一个会创建内核对象的函数后,函数会返回一个句柄(handle),它标识了所创建的对象,句柄其实就是一个32位的数值或64位的数值。可以将这个句柄想象为一个不透明的值,它可由进程中的任何线程使用。为了增强操作系统的可靠性,这些句柄值是与进程相关的。
3.1.1 使用计数(可以想象成智能指针)
内核对象的所有者是操作系统内核,而非进程。因此内核对象的生命周期大于等于进程的生命周期。操作系统内核知道当前有多少个进程正在使用一个特定的内核对象,因为每个内核对象都包含一个使用计数。使用计数是所有内核对象类型都有的一个数据成员。
3.1.2 内核对象的安全性
内核对象可以用一个安全描述符(Security Descriptor,SD)来保护。安全描述符描述了谁(通常是对象的创建者)拥有对象;哪些组和用户被允许访问或使用此对象;哪些组和用户被拒绝访问此对象。用于创建内核对象的所有函数几乎都有指向一个SECURITY_ATTRIBUTES结构的指针作为参数,而用于创建用户对象或GDI对象的函数都没有该参数。
文件对象:
文件对象是IO管理器用来在内存中表示一个已打开的对象的数据结构。例如:如果打开磁盘上一个文件的操作成功执行了,IO管理器就创建一个文件对象结构来表示这个打开操作的特定实例。
注意:如果针对同一个文件,执行了另一个打开操作,IO管理器将创建一个新的文件对象来代表第二个打开实例。
文件对象结构由IO管理器在传递IRP_MJ_CREATE给FSD之前创建。对应的IRP内部包含这个新创建的文件对象的指针。
可以用dt _FILE_OBJECT 来查看文件对象的结构。
文件流:
保存在磁盘上的文件中数据被定义为文件流。例如:文件流包括这个文件的真实数据、文件目录,还有文件系统元数据、访问控制列表以及这个文件的扩展属性。
3.2 进程内核对象句柄表
一个进程在初始化时,系统将为它分配一个句柄表。这个句柄表仅供内核对象使用,不适用于用户对象或GDI对象。下图显示了一个进程的句柄表,它只是一个由数据结构组成的数组。

3.2.1 创建一个内核对象
一个进程首次初始化的时候,其句柄表为空。当进程内的一个线程调用一个会创建内核对象的函数时,内核将为这个对象分配并初始化一个内存块。然后,内核扫描进程的句柄表,查找一个空白的记录项。由于表3-1展示的是一个空白句柄表,所以内核在索引1位置找到空白的记录项,并对其进行初始化。具体地说,指针成员会被设置成内核对象的数据结构的内部内存地址,访问掩码将被设置成拥有完全访问权限,标志也会设置。索引值为句柄值/4。用于创建内核对象的所有函数都会返回一个与进程相关的句柄,这个句柄可由同一个进程中的所有线程所使用。系统用索引来表示内核对象的信息保存在进程句柄中的具体位置。
只有在调用CreateFile时,才能将它的返回值与INVALID_HANDLE_VALUE比较,其他的都与NULL比较。
3.2.2 关闭内核对象(CloseHandle)
无论以什么方式创建内核对象,用户都应该调用CloseHandle向系统表明我们已经结束使用对象,在内部,该函数首先检查主调函数进程的句柄表,验证“传给函数的句柄值”标识的是“进程确实有权访问的一个对象”。如果句柄是有效的,系统就将获得内核对象的数据结构的地址,并将结构中的“使用计数”成员递减。如果使用计数变成0,内核对象将被销毁,并从内存中移除。

对于内核对象,操作系统执行的是以下操作:进程终止时,系统自动扫描该进程的句柄表。如果这个表中有任何有效的记录项(即进程终止前没有关闭的对象),操作系统会为我们关闭这些对象句柄。只要这些对象中有一个的使用计数递减到0,内核就会销毁对象。
3.3 跨进程边界共享内核对象
内核对象是受安全性保护的,进程在试图操作一个对象之前,必须先申请操作它的权限。对象的创建者为了阻止一个未经许可的用户“碰”自己的对象,只需拒绝该用户访问它。可以利用三种不同的机制来允许进程共享内核对象:使用对象句柄继承;为对象命名;复制对象句柄。
3.3.1 使用对象句柄继承(只能在父子进程时使用)
Windows支持的是“对象句柄的继承”;换言之,只有句柄才是可以继承的,对象本身是不能继承的。
使用这种方式时,父进程必须执行的几个步骤:
首先,当父进程创建一个内核对象时,父进程必须向系统指出它希望这个对象的句柄是可以继承的。
其次,由父进程创建子进程,并将bInheritHandles设置为true。

内核对象的内容被保存在内核地址空间中——系统上运行的所有进程都共享这个空间。对象句柄的继承只会在生成子进程的时候发生。子进程并不知道自己继承了任何句柄。句柄继承只所以能够实现,唯一的原因就是“共享的内核对象”的句柄值在父进程和子进程中是完全一样的。这正是父进程能将句柄值作为命令行参数来传递的原因。
3.3.2 改变句柄的标志(SetHandleInformation)
3.3.3 为对象命名(进程可不为父子关系,跨进程边界共享内核对象的第二个方法)
微软没有提供任何专门的机制来保证为内核对象指定名称的唯一的,所有的内核对象都共享同一个命名空间,即使它们的类型并不相同。

3.3.4 终端服务命名空间

3.3.6 复制对象句柄(跨进程边界共享内核对象的第三种方法)(DuplicateHandle)
该函数获得一个进程的句柄表中的一个记录项,然后在另一个进程的句柄表中创建这个记录项的一个副本。该函数最常见的一种用法可能涉及系统中同时运行的三个不同的进程。同样这种方法的缺点是目标进程不知道它现在能访问一个新的内核对象。






















 8560
8560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









