






xgboost 逻辑回归:objective参数(reg:logistic,binary:logistic,binary:logitraw,)对比分析
置顶 2018年07月11日 22:26:53 phyllisyuell 阅读数:1755
一、问题
熟悉xgboost的小伙伴都知道,它在训练模型时,有train()方法和fit()方法,两种方法都是用于构建模型的,然而在使用过程中有什么不同的地方呢,这篇文章带领大家一起来看一下。train方法使用如下:
-
params ={'eta': 0.1, -
'max_depth': 4, -
'num_boost_round':20, -
'objective': 'reg:logistic', -
'random_state': 27, -
'silent':0 -
} -
model = xgb.train(params,xgb.DMatrix(x_train, y_train)) -
train_pred=model.predict(xgb.DMatrix(x_test))
而fit方法是直接使用xgboost封装好的XGBClassifier或者XGBRegressor时使用:
-
model = XGBClassifier( -
learning_rate=0.1, -
n_estimators=20, -
max_depth=4, -
objective='binary:logistic', -
seed=27, -
silent=0 -
) -
model.fit(x_train,y_train,verbose=True) -
fit_pred=model.predict(x_test) -
print fit_pred
相同的数据集,相同的参数得到的预测值却是不一样的,fit_pred的值是0,1的具体的预测标签,train_pred的值是0-1之间的概率值;为什么结果是不一样的呢?如何把0-1之间的概率值映射成0,1标签呢?这个后面揭晓,我们先看下,xgboost中用于做逻辑回归的objective的参数都有哪些,得到预测结果有什么不同!
二、objective参数比较
xgboost官方文档关于逻辑回归objective有三个参数,如下:

1、reg:logistic PK binary:logistic
实际上reg:logistic,binary:logistic都是输出逻辑回归的概率值,实验过程如下:
-
params ={'eta': 0.1, -
'max_depth': 4, -
'num_boost_round':20, -
'objective': 'binary:logistic', -
'random_state': 27, -
'silent':0 -
} -
model = xgb.train(params,xgb.DMatrix(x_train, y_train)) -
bin_log_pred=model.predict(xgb.DMatrix(x_test)) -
# print bin_log_pred -
################################### -
params ={'eta': 0.1, -
'max_depth': 4, -
'num_boost_round':20, -
'objective': 'reg:logistic', -
'random_state': 27, -
'silent':0 -
} -
model = xgb.train(params,xgb.DMatrix(x_train, y_train)) -
reg_log_pred=model.predict(xgb.DMatrix(x_test)) -
# print reg_log_pred -
count=0 -
for i in np.arange(0,len(reg_log_pred)): -
if (reg_log_pred[i]==bin_log_pred[i]): -
count+=1 -
print "len:",len(reg_log_pred) -
print "count:",count -
if count==len(reg_log_pred): -
print "true" -
else: -
print "false"
输出结果:

2、reg:logistic PK binary:logitraw
然后我们再来看下binary:logitraw参数,由文档可以看出这个参数得到的是集成树模型最后输出的得分,即转换成概率值之前的值,我们知道xgboost这类集成树算法用到的回归树,这就决定了它本身就是用来做回归的,调整后可以用来做分类,这里的调整是指通过sigmoid函数处理后来做二分类,通过softmax函数处理后来做多分类。于是,我们定义一个sigmoid函数,把binary:logitraw参数输出的得分通过sigmoid函数映射成概率值,对比下是否和reg:logistic参数得到的概率值是一样的。
-
params ={'eta': 0.1, -
'max_depth': 4, -
'num_boost_round':20, -
'objective': 'reg:logistic', -
'random_state': 27, -
'silent':0 -
} -
model = xgb.train(params,xgb.DMatrix(x_train, y_train)) -
reg_log_pred=model.predict(xgb.DMatrix(x_test)) -
# print reg_log_pred -
################################### -
params ={'eta': 0.1, -
'max_depth': 4, -
'num_boost_round':20, -
'objective': 'binary:logitraw', -
# 'n_jobs': 4, -
'random_state': 27, -
'silent':0 -
} -
model = xgb.train(params,xgb.DMatrix(x_train, y_train)) -
logitraw_pred=model.predict(xgb.DMatrix(x_test)) -
print logitraw_pred -
def sigmoid(x): -
return 1./(1.+np.exp(-x)) -
y=sigmoid(logitraw_pred) -
print y -
count=0 -
for i in np.arange(0,len(reg_log_pred)): -
if (reg_log_pred[i]==y[i]): -
count+=1 -
print len(reg_log_pred) -
print count -
if count==len(reg_log_pred): -
print "true" -
else: -
print "false"
输出结果:

3、总结
上述实验,通过使用相同的数据集,相同的参数(除了objective参数,其他相同),研究了逻辑回归的objective的三种不同参数的输出结果,得到如下结论:
1、binary:logistic和 'objective': 'reg:logistic'的输出是一样的,都是预测的概率
2、binary:logitraw是输出的得分,用sigmoid()函数处理后就和上述两个概率值一致
三、XGBClassifier都做了些什么
回到我们一开始的问题,xgboost train()方法得到概率值之后,如何处理成最终的0,1标签呢?
这个工作应该是在XGBClassifier中完成的,我们进行下列实验进行验证:
-
model = XGBClassifier( -
learning_rate=0.1, -
n_estimators=20, -
max_depth=4, -
objective='binary:logistic', -
seed=27, -
silent=0 -
) -
model.fit(x_train,y_train,verbose=True) -
fit_pred=model.predict(x_test) -
print fit_pred -
####################### -
params ={'learning_rate': 0.1, -
'max_depth': 4, -
'objective': 'reg:logistic', -
'random_state': 27, -
'silent':0 -
} -
model = xgb.train(params,xgb.DMatrix(x_train, y_train),num_boost_round=20) -
train_pred=model.predict(xgb.DMatrix(x_test)) -
#概率值的阈值假设为0.5,小于等于0.5的预测为0,否则预测为1 -
for i in np.arange(0,len(train_pred)): -
if train_pred[i]<0.5: -
train_pred[i]=0 -
else: -
train_pred[i]=1 -
print train_pred -
print type(train_pred) -
count=0 -
for i in np.arange(0,len(train_pred)): -
if (train_pred[i]==fit_pred[i]): -
count+=1 -
print len(train_pred) -
print count -
if count==len(train_pred): -
print "true" -
else: -
print "false"
输出的结果:

由此可见我们的假设是成立的,XGBClassifier里就是把预测的概率值,取阈值0.5,小于这个值的为0,大于这个值的为1,实验过程中还发现并没有等于0.5的概率值,我的设想是对于一个二分类问题,把概率预测成0.5没有任何意义o(* ̄︶ ̄*)o
为了增加可信度,我们把训练数据放到模型里进行预测,并对于,train和fit输出的预测结果,结果如下:

通过上述实验,我们对xgboost算法做逻辑回归问题应该有了更加深入的认识,下篇文章我们一起来研究下xgboost在处理多分类问题的过程。
(发现文章中有任何问题请联系:phyllisyuell@163.com)
===============================================================================================================================================================================================================
5.3学习目标参数
这个参数用来控制理想的优化目标和每一步结果的度量方法。
- 这个参数定义需要被最小化的损失函数。最常用的值有:
- binary:logistic 二分类的逻辑回归,返回预测的概率(不是类别)。
- multi:softmax 使用softmax的多分类器,返回预测的类别(不是概率)。
- 在这种情况下,你还需要多设一个参数:num_class(类别数目)。
- multi:softprob 和multi:softmax参数一样,但是返回的是每个数据属于各个类别的概率。
2、eval_metric[默认值取决于objective参数的取值]
- 对于有效数据的度量方法。
- 对于回归问题,默认值是rmse,对于分类问题,默认值是error。
- 典型值有:
- rmse 均方根误差(∑Ni=1ϵ2N−−−−−√)
- mae 平均绝对误差(∑Ni=1|ϵ|N)
- logloss 负对数似然函数值
- error 二分类错误率(阈值为0.5)
- merror 多分类错误率
- mlogloss 多分类logloss损失函数
- auc 曲线下面积
- 随机数的种子
- 设置它可以复现随机数据的结果,也可以用于调整参数
如果你之前用的是Scikit-learn,你可能不太熟悉这些参数。但是有个好消息,Python的XGBoost模块有一个sklearn包,XGBClassifier。这个包中的参数是按sklearn风格命名的。会改变的函数名是:
1、eta -> learning_rate
2、lambda -> reg_lambda
3、alpha -> reg_alpha
你肯定在疑惑为啥咱们没有介绍和GBM中的n_estimators类似的参数。XGBClassifier中确实有一个类似的参数,但是,是在标准XGBoost实现中调用拟合函数时,把它作为num_boosting_rounds参数传入。
XGBoost Guide 的一些部分是我强烈推荐大家阅读的,通过它可以对代码和参数有一个更好的了解:
XGBoost Parameters (official guide)
XGBoost Demo Codes (xgboost GitHub repository)
Python API Reference (official guide)
调参示例
我们从Data Hackathon 3.x AV版的hackathon中获得数据集,和GBM 介绍文章中是一样的。更多的细节可以参考competition page
数据集可以从这里下载。我已经对这些数据进行了一些处理:
City变量,因为类别太多,所以删掉了一些类别。DOB变量换算成年龄,并删除了一些数据。- 增加了
EMI_Loan_Submitted_Missing变量。如果EMI_Loan_Submitted变量的数据缺失,则这个参数的值为1。否则为0。删除了原先的EMI_Loan_Submitted变量。 EmployerName变量,因为类别太多,所以删掉了一些类别。- 因为
Existing_EMI变量只有111个值缺失,所以缺失值补充为中位数0。 - 增加了
Interest_Rate_Missing变量。如果Interest_Rate变量的数据缺失,则这个参数的值为1。否则为0。删除了原先的Interest_Rate变量。 - 删除了
Lead_Creation_Date,从直觉上这个特征就对最终结果没什么帮助。 Loan_Amount_Applied, Loan_Tenure_Applied两个变量的缺项用中位数补足。- 增加了
Loan_Amount_Submitted_Missing变量。如果Loan_Amount_Submitted变量的数据缺失,则这个参数的值为1。否则为0。删除了原先的Loan_Amount_Submitted变量。 - 增加了
Loan_Tenure_Submitted_Missing变量。如果Loan_Tenure_Submitted变量的数据缺失,则这个参数的值为1。否则为0。删除了原先的Loan_Tenure_Submitted变量。 - 删除了
LoggedIn,Salary_Account两个变量 - 增加了
Processing_Fee_Missing变量。如果Processing_Fee变量的数据缺失,则这个参数的值为1。否则为0。删除了原先的Processing_Fee变量。 Source前两位不变,其它分成不同的类别。- 进行了离散化和独热编码(一位有效编码)。
如果你有原始数据,可以从资源库里面下载data_preparation的Ipython notebook 文件,然后自己过一遍这些步骤。
载入必要库:
[python] view plain copy ![]()
![]()
- import pandas as pd
- import numpy as np
- import xgboost as xgb
- from xgboost.sklearn import XGBClassifier
- from sklearn.model_selection import GridSearchCV,cross_val_score
- from sklearn import metrics
- import matplotlib.pylab as plt
读取文件
[python] view plain copy ![]()
![]()
- train_df = pd.read_csv('train_modified.csv')
- train_y = train_df.pop('Disbursed').values
- test_df = pd.read_csv('test_modified.csv')
- train_df.drop('ID',axis=1,inplace=True)
- test_df.drop('ID',axis=1,inplace=True)
- train_X = train_df.values
然后评分函数未下:
[python] view plain copy ![]()
![]()
- def modelMetrics(clf,train_x,train_y,isCv=True,cv_folds=5,early_stopping_rounds=50): (模型监控)
- if isCv:
- xgb_param = clf.get_xgb_params()
- xgtrain = xgb.DMatrix(train_x,label=train_y)
- cvresult = xgb.cv(xgb_param,xgtrain,num_boost_round=clf.get_params()['n_estimators'],nfold=cv_folds,
- metrics='auc',early_stopping_rounds=early_stopping_rounds)#是否显示目前几颗树额
-
clf.set_params(n_estimators=cvresult.shape[0])
- clf.fit(train_x,train_y,eval_metric='auc')
- #预测
- train_predictions = clf.predict(train_x)
- train_predprob = clf.predict_proba(train_x)[:,1]#1的概率
- #打印
- print("\nModel Report")
- print("Accuracy : %.4g" % metrics.accuracy_score(train_y, train_predictions))
- print("AUC Score (Train): %f" % metrics.roc_auc_score(train_y, train_predprob))
- feat_imp = pd.Series(clf.booster().get_fscore()).sort_values(ascending=False)
- feat_imp.plot(kind='bar',title='Feature importance')
- plt.ylabel('Feature Importance Score')
我们测试下:
Model Report Accuracy : 0.9854 AUC Score (Train): 0.851058
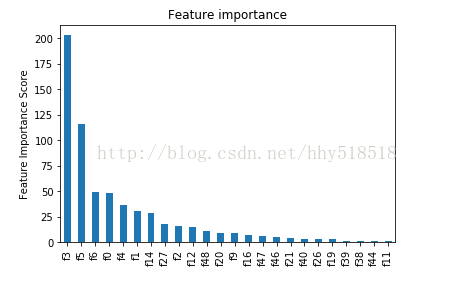
我们看下其中具体的cv结果
cvresult.shape[0]是其中我们用的树的个数
cvresult的结果是一个DataFrame
===============================================================================================================================================================================================================
cvresult.shape[0]是其中我们用的树的个数
揭秘Kaggle神器xgboost
2017年06月07日 13:31:26 CSDN王艺 阅读数:11995
在 Kaggle 的很多比赛中,我们可以看到很多 winner 喜欢用 xgboost,而且获得非常好的表现,今天就来看看 xgboost 到底是什么以及如何应用。
本文结构:
- 什么是 xgboost?
- 为什么要用它?
- 怎么应用?
- 学习资源
什么是 xgboost?
XGBoost :eXtreme Gradient Boosting
项目地址:https://github.com/dmlc/xgboost
是由 Tianqi Chen http://homes.cs.washington.edu/~tqchen/ 最初开发的实现可扩展,便携,分布式 gradient boosting (GBDT, GBRT or GBM) 算法的一个库,可以下载安装并应用于 C++,Python,R,Julia,Java,Scala,Hadoop,现在有很多协作者共同开发维护。
XGBoost 所应用的算法就是 gradient boosting decision tree,既可以用于分类也可以用于回归问题中。
那什么是 Gradient Boosting?
Gradient boosting 是 boosting 的其中一种方法,所谓 Boosting ,就是将弱分离器 f_i(x) 组合起来形成强分类器 F(x) 的一种方法。
所以 Boosting 有三个要素:
-
A loss function to be optimized:
例如分类问题中用 cross entropy,回归问题用 mean squared error。 -
A weak learner to make predictions:
例如决策树。 -
An additive model:
将多个弱学习器累加起来组成强学习器,进而使目标损失函数达到极小。
Gradient boosting 就是通过加入新的弱学习器,来努力纠正前面所有弱学习器的残差,最终这样多个学习器相加在一起用来进行最终预测,准确率就会比单独的一个要高。之所以称为 Gradient,是因为在添加新模型时使用了梯度下降算法来最小化的损失。
第一种 Gradient Boosting 的实现就是 AdaBoost(Adaptive Boosting)。
AdaBoost 就是将多个弱分类器,通过投票的手段来改变各个分类器的权值,使分错的分类器获得较大权值。同时在每一次循环中也改变样本的分布,这样被错误分类的样本也会受到更多的关注。

为什么要用 xgboost?
前面已经知道,XGBoost 就是对 gradient boosting decision tree 的实现,但是一般来说,gradient boosting 的实现是比较慢的,因为每次都要先构造出一个树并添加到整个模型序列中。
而 XGBoost 的特点就是计算速度快,模型表现好,这两点也正是这个项目的目标。
表现快是因为它具有这样的设计:
- Parallelization:
训练时可以用所有的 CPU 内核来并行化建树。 - Distributed Computing :
用分布式计算来训练非常大的模型。 - Out-of-Core Computing:
对于非常大的数据集还可以进行 Out-of-Core Computing。 - Cache Optimization of data structures and algorithms:
更好地利用硬件。
下图就是 XGBoost 与其它 gradient boosting 和 bagged decision trees 实现的效果比较,可以看出它比 R, Python,Spark,H2O 中的基准配置要更快。

另外一个优点就是在预测问题中模型表现非常好,下面是几个 kaggle winner 的赛后采访链接,可以看出 XGBoost 的在实战中的效果。
- Vlad Sandulescu, Mihai Chiru, 1st place of the KDD Cup 2016 competition. Link to the arxiv paper.
- Marios Michailidis, Mathias Müller and HJ van Veen, 1st place of the Dato Truely Native? competition. Link to the Kaggle interview.
- Vlad Mironov, Alexander Guschin, 1st place of the CERN LHCb experiment Flavour of Physics competition. Link to the Kaggle interview.
怎么应用?
先来用 Xgboost 做一个简单的二分类问题,以下面这个数据为例,来判断病人是否会在 5 年内患糖尿病,这个数据前 8 列是变量,最后一列是预测值为 0 或 1。
数据描述:
https://archive.ics.uci.edu/ml/datasets/Pima+Indians+Diabetes
下载数据集,并保存为 “pima-indians-diabetes.csv“ 文件:
https://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data
1. 基础应用
引入xgboost等包
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score分出变量和标签
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
X = dataset[:,0:8]
Y = dataset[:,8]将数据分为训练集和测试集,测试集用来预测,训练集用来学习模型
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)xgboost 有封装好的分类器和回归器,可以直接用 XGBClassifier 建立模型,这里是 XGBClassifier 的文档:
http://xgboost.readthedocs.io/en/latest/python/python_api.html#module-xgboost.sklearn
model = XGBClassifier()
model.fit(X_train, y_train)xgboost 的结果是每个样本属于第一类的概率,需要用 round 将其转换为 0 1 值
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]得到 Accuracy: 77.95%
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))2. 监控模型表现
xgboost可以在模型训练时,评价模型在测试集上的表现,也可以输出每一步的分数,只需要将
model = XGBClassifier()
model.fit(X_train, y_train)变为:
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)那么它会在每加入一颗树后打印出 logloss
[31] validation_0-logloss:0.487867
[32] validation_0-logloss:0.487297
[33] validation_0-logloss:0.487562并打印出 Early Stopping 的点:
Stopping. Best iteration:
[32] validation_0-logloss:0.4872973. 输出特征重要度
gradient boosting还有一个优点是可以给出训练好的模型的特征重要性,
这样就可以知道哪些变量需要被保留,哪些可以舍弃。
需要引入下面两个类:
from xgboost import plot_importance
from matplotlib import pyplot和前面的代码相比,就是在 fit 后面加入两行画出特征的重要性
model.fit(X, y)
plot_importance(model)
pyplot.show()
4. 调参
如何调参呢,下面是三个超参数的一般实践最佳值,可以先将它们设定为这个范围,然后画出 learning curves,再调解参数找到最佳模型:
- learning_rate = 0.1 或更小,越小就需要多加入弱学习器;
- tree_depth = 2~8;
- subsample = 训练集的 30%~80%;
接下来我们用 GridSearchCV 来进行调参会更方便一些:
可以调的超参数组合有:
树的个数和大小 (n_estimators and max_depth).
学习率和树的个数 (learning_rate and n_estimators).
行列的 subsampling rates (subsample, colsample_bytree and colsample_bylevel).
下面以学习率为例:
先引入这两个类
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold设定要调节的 learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3],和原代码相比就是在 model 后面加上 grid search 这几行:
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(X, Y)最后会给出最佳的学习率为 0.1
Best: -0.483013 using {‘learning_rate’: 0.1}
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))我们还可以用下面的代码打印出每一个学习率对应的分数:
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))-0.689650 (0.000242) with: {'learning_rate': 0.0001}
-0.661274 (0.001954) with: {'learning_rate': 0.001}
-0.530747 (0.022961) with: {'learning_rate': 0.01}
-0.483013 (0.060755) with: {'learning_rate': 0.1}
-0.515440 (0.068974) with: {'learning_rate': 0.2}
-0.557315 (0.081738) with: {'learning_rate': 0.3}前面就是关于 xgboost 的一些基础概念和应用实例,下面还有一些学习资源供参考:
学习资源:
Tianqi Chen 的讲座:
https://www.youtube.com/watch?v=Vly8xGnNiWs&feature=youtu.be
讲义:
https://speakerdeck.com/datasciencela/tianqi-chen-xgboost-overview-and-latest-news-la-meetup-talk
入门教程:
https://xgboost.readthedocs.io/en/latest/
安装教程:
http://xgboost.readthedocs.io/en/latest/build.html
应用示例:
https://github.com/dmlc/xgboost/tree/master/demo
最好的资源当然就是项目的 Github 主页:
https://github.com/dmlc/xgboost
参考:
http://machinelearningmastery.com/develop-first-xgboost-model-python-scikit-learn/
https://www.zhihu.com/question/37683881
2017中国人工智能大会(CCAI 2017)| 7月22日-23日 杭州
本届CCAI由中国人工智能学会、蚂蚁金服主办,由CSDN承办,最专业的年度技术盛宴:
- 40位以上实力讲师
- 8场权威专家主题报告
- 4场开放式专题研讨会
- 超过100家媒体报道
- 超过2000位技术精英和专业人士参会
与大牛面对面,到官网报名:http://ccai.caai.cn/
===============================================================================================================================================================================================================
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
2018-12-26 20:01:37
深度学习最大的贡献,个人认为就是表征学习(representation learning),通过端到端的训练,发现更好的features,而后面用于分类(或其他任务)的输出function,往往也只是普通的softmax(或者其他一些经典而又简单的方法)而已,所以,只要特征足够好,分类函数本身并不需要复杂——博主自己在做research的时候也深有同感,以前很多paper其实是误入歧途,采用的feature非常混淆模糊没有区分性,却指望在分类器上获得好的结果,可能么?深度学习可以说是回到了问题的本源上来,representation learning。
目前DL的成功都是建立在多层神经网络的基础上的,那么这种成功能否复刻到其他模型上呢?我相信,是可以的。南京大学的周志华老师尝试提出一种深度的tree模型,叫做gcForest,用文中的术语说,就是“multi-Grained Cascade forest”,多粒度级联森林。此外,还提出了一种全新的决策树集成方法,使用级联结构让 gcForest 做表征学习。
Title:Deep Forest: Towards An Alternative to Deep Neural Networks
作者:Zhi-Hua Zhou and Ji Feng
完整源码下载地址:
摘要
在这篇论文里,我们提出了 gcForest,这是一种决策树集成方法(decision tree ensemble approach),性能较之深度神经网络有很强的竞争力。深度神经网络需要花大力气调参,相比之下 gcForest 要容易训练得多。实际上,在几乎完全一样的超参数设置下,gcForest 在处理不同领域(domain)的不同数据时,也能达到极佳的性能。gcForest 的训练过程效率高且可扩展。在我们的实验中,它在一台 PC 上的训练时间和在 GPU 设施上跑的深度神经网络差不多,有鉴于 gcForest 天然适用于并行的部署,其效率高的优势就更为明显。此外,深度神经网络需要大规模的训练数据,而 gcForest 在仅有小规模训练数据的情况下也照常运转。不仅如此,作为一种基于树的方法,gcForest 在理论分析方面也应当比深度神经网络更加容易。
级联森林(Cascade Forest)

级联森林结构的图示。级联的每个级别包括两个随机森林(蓝色字体标出)和两个完全随机树木森林(黑色)。假设有三个类要预测; 因此,每个森林将输出三维类向量,然后将其连接以重新表示原始输入。注意,要将前一级的特征和这一级的特征连接在一起——在最后会有一个例子,到时候再具体看一下如何连接。
论文中为了简单起见,在实现中,使用了两个完全随机的树森林(complete-random tree forests)和两个随机森林[Breiman,2001]。每个完全随机的树森林包含1000个完全随机树[Liu et al。,2008],每棵树通过随机选择一个特征在树的每个节点进行分割实现生成,树一直生长,直到每个叶节点只包含相同类的实例或不超过10个实例。类似地,每个随机森林也包含1000棵树,通过随机选择sqrt(d) 数量的特征作为候选(d是输入特征的数量),然后选择具有最佳 gini 值的特征作为分割。每个森林中的树的数值是一个超参数。
给定一个实例(就是一个样本),每个森林会通过计算在相关实例落入的叶节点处的不同类的训练样本的百分比,然后对森林中的所有树计平均值,以生成对类的分布的估计。如下图所示,其中红色部分突出了每个实例遍历到叶节点的路径。叶节点中的不同标记表示了不同的类。

被估计的类分布形成类向量(class vector),该类向量接着与输入到级联的下一级的原始特征向量相连接。例如,假设有三个类,则四个森林每一个都将产生一个三维的类向量,因此,级联的下一级将接收12 = 3×4个增强特征(augmented feature)。
为了降低过拟合风险,每个森林产生的类向量由k折交叉验证(k-fold cross validation)产生。具体来说,每个实例都将被用作 k -1 次训练数据,产生 k -1 个类向量,然后对其取平均值以产生作为级联中下一级的增强特征的最终类向量。需要注意的是,在扩展一个新的级后,整个级联的性能将在验证集上进行估计,如果没有显着的性能增益,训练过程将终止;因此,级联中级的数量是自动确定的。与模型的复杂性固定的大多数深度神经网络相反,gcForest 能够适当地通过终止训练来决定其模型的复杂度(early stop)。这使得 gcForest 能够适用于不同规模的训练数据,而不局限于大规模训练数据。
(注:级联数量自动确定可以有助于控制模型的复杂性,实际上在每一级的输出结果都用ground truth label来训练的,这里和CNN的理解不同,CNN认为特征是逐层抽象的,而本文在每一层都直接拿label的高层语义来训练——我本人有一些担忧,直接这样的级联会不会使得收益并不能通过级数的加深而放大?比如CNN目前可以做到上百层的net,而这里会自动确定深度,也就是说可能没办法做的很深。希望随着更多人的分析,可以在这一点上给出一些结论)
多粒度扫描(Multi-Grained Scanning)
深度神经网络在处理特征关系方面是强大的,例如,卷积神经网络对图像数据有效,其中原始像素之间的空间关系是关键的。(LeCun et al., 1998; Krizhenvsky et al., 2012),递归神经网络对序列数据有效,其中顺序关系是关键的(Graves et al., 2013; Cho et al.,2014)。受这种认识的启发,我们用多粒度扫描流程来增强级联森林。

滑动窗口用于扫描原始特征。假设有400个原始特征,并且使用100个特征的窗口大小。对于序列数据,将通过滑动一个特征的窗口来生成100维的特征向量;总共产生301个特征向量。如果原始特征具有空间关系,比如图像像素为400的20×20的面板,则10×10窗口将产生121个特征向量(即121个10×10的面板)。从正/负训练样例中提取的所有特征向量被视为正/负实例;它们将被用于生成类向量:从相同大小的窗口提取的实例将用于训练完全随机树森林和随机森林,然后生成类向量并连接为转换后的像素。如上图的上半部分所示,假设有3个类,并且使用100维的窗口;然后,每个森林产生301个三维类向量,导致对应于原始400维原始特征向量的1,806维变换特征向量。
通过使用多个尺寸的滑动窗口,最终的变换特征矢量将包括更多的特征,如下图所示。

concat成一个3618-dim的原始数据,表示原始的一个数据样本,第一级的输出是12+3618=3630,后面也是一样,直到最后第N级,只有12个输出,然后在每一类别上做avg,然后输出max那一类的label,那就是最终的预测类别。
实验结果
这一部分也是网上大家有疑问的地方,主要是数据集选取都是比较小的实验数据,这个方法能不能火还是要看在real data上能不能做到和DL一样的效果。
下面简单贴几个结果



总结
带着深度学习的关键在于特征学习和巨大模型的能力这一认识,我们在本文中试图赋予树集成这些属性,并提出了 gcForest 方法。与深度神经网络相比,gcForest在我们的实验中表现了极高的竞争力或更好的性能。更重要的是,gcForest 具有少得多的超参数,并且对参数设置不太敏感;实际上在我们的实验中,通过使用相同的参数设置在不同的域中都获得了优异的性能,并且无论是大规模还是小规模的数据,它的工作都很好。
如何利用gcForest为特征打分?
这个算法的确比传统的集成树算法:RandomForest,XGBoost,lightGBM都要优秀,而且引入层的概念后很好的解决了集成树算法容易过拟合的问题。
简单讲他就是借鉴了深度学习分层训练的思路,将机器学习中常用的RandomForest,XGBoost,LogisticRegression等算法进行集成,通过模型和样本的多样性让模型更加优秀。
正是因为它这种集成思想,反而抹杀了传统集成树算法的一大优势,gcForest无法给特征打分。原因很简单,它每层用的基学习器像前面提到的RandomForest,XGBoost提取特征的方式是不一样的:
首先RandomForest作为Bagging的代表,它是通过给指定特征X随机加入噪声,通过加入噪声前后袋外数据误差的差值来衡量该特征的重要程度;而XGBoost作为典型的Boosting算法提取特征的方式和RandomForest有很大的不同,看了下他的打分函数有weight,gain,cover三种方式,其中默认的是weight,这种方式其实就是统计特征X在每棵决策树当中出现的次数,最后特征X出现的次数之和就作为特征X的最后的得分。我们可以看出这两种算法打分方式不同,得到的数值也不是一个量纲的。同样LogisticRegression提取特征的方式也和前两者不一样。
并且gcForst还提供了用户自己添加基学习器的接口(添加方法请了解:gcForest官方代码详解),也就意味着gcForest还可以使用更多的基学习器,如果要封装一个提取重要特征的方法,就要考虑太多太多,每进来一个基学习器都要改变特征打分的方法。
综上所述,我觉得也是gcForest作者没有封装特征打分方法的原因。
基于我的问题,我做了一些思考。我处理的数据用RandomForest,XGBoost都能得到不错的结果,我们知道RandomForest可以很好的减少方差,XGBoost可以很好的减少偏差。为了构建一个低偏差和低方差的模型,我想将这两种算法进行集成。所以在gcForest中我只用了这两个基学习器。

通过对RandomForest,XGBoost打分函数的学习,我和小伙伴shi.chao 对gcForest封装了一个特征打分方法,利用的还是源码里手写数字识别的数据,每层只有RandomForest,XGBoost,为了方便调试,就构建了两层。
大体思想如下:
在源码目录:lib->gcforest->cascade->cascade_classifier.py fit_transform()方法中进行了一些操作。这个方法就是gcForest进行模型训练的函数。上面也提到了不同的算法特征打分的方法是不一样的,所以在这里需要通过变量est_configs["type"]对基学习器类型进行判断。如果是RandomForest,就直接调用RandomForest的打分函数,得到该基学习器返回的一个map,其中包含特征名称和得分,这里用一个临时变量保存,等到下一层获取RandomFores打分函数得到的另一个map,然后将这个两个map合并,相同key的将value累加,最后得到一个final_feature_rf_importance_list,是整个gcForest所有层中RandomFores得到的特征得分。XGBoost,类似操作。具体见代码注释。
感兴趣的小伙伴可以在这个基础上继续对另外的基学习器特征打分算法进行封装。最后gcForest的特征得分:可以是各个基学习器特征得分的一个融合。
比如我的模型中只用到了RandomForest和XGBoost,最后gcForest的第i个特征的得分可以这样表示:
Zi = w1 * Xi/sum(X) + w2 * Yi/sum(Y)
其中Xi代表RandomForest中第i个特征的得分,Yi代表XGBoost中第i个特征的得分,这两个值虽然不是一个量纲,但是通过处以它们全部特征之和就可以得到该特征在它的模型中的相对特征,最后通过设置w1,w2的系数,可以调整两种模型在gcForest中的重要程度。
https://blog.csdn.net/xbinworld/article/details/60466552
https://blog.csdn.net/phyllisyuell/article/details/85258877
==================================================================================================================================================================
gcForest算法理解
2017年03月10日 16:55:03 余音丶未散 阅读数:4403 标签: 算法 gcForest 更多
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/q383700092/article/details/61200405
介绍
gcForest(multi-Grained Cascade forest 多粒度级联森林)是周志华教授最新提出的新的决策树集成方法。这种方法生成一个深度树集成方法(deep forest ensemble method),使用级联结构让gcForest学习。
gcForest模型把训练分成两个阶段:Multi-Grained Scanning和Cascade Forest。Multi-Grained Scanning生成特征,Cascade Forest经过多个森林多层级联得出预测结果。
Cascade Forest(级联森林)
级联森林结构的图示:
1. 级联中的每一级接收到由前一级处理的特征信息,并将该级的处理结果输出给下一级。
2. 级联的每个级别包括两个随机森林(蓝色字体标出)和两个完全随机树木森林(黑色)。[可以是多个,为了简单这里取了2种森林4个弱分类器]
3. 每个完全随机的树森林包含1000(超参数)个完全随机树,通过随机选择一个特征在树的每个节点进行分割实现生成,树一直生长,直到每个叶节点只包含相同类的实例或不超过10个实例。
4. 类似地,每个随机森林也包含1000(超参数)棵树,通过随机选择√d数量(输入特征的数量开方)的特征作为候选,然后选择具有最佳gini值的特征作为分割。(每个森林中的树的数值是一个超参数)
假设有三个类要预测; 因此,每个森林将输出三维类向量,然后将其连接输入特征以重新表示下一次原始输入。
类别概率向量生成:
给定一个实例,每个森林会通过计算在相关实例落入的叶节点处的不同类的训练样本的百分比,然后对森林中的所有树计平均值,以生成对类的分布的估计。即每个森林会输出一个类别概率向量。
为了降低过拟合风险,每个森林产生的类向量由k折交叉验证(k-fold cross validation)产生。
假设有三个类,则四个森林每一个都将产生一个三维的类向量,因此,级联的下一级将接收12 = 3×4个增强特征(augmented feature)
Multi-Grained Scanning(多粒度扫描)
用多粒度扫描流程来增强级联森林,使用滑动窗口扫描的生成实例,输入森林后结果合并,生成新的特征。
假设有400个原始特征,并且使用100个特征的窗口大小。对于序列数据,将通过滑动一个特征的窗口来生成100维的特征向量;总共产生301个实例100维的特征向量。从相同大小的窗口提取的实例将用于训练完全随机树森林和随机森林,然后经过训练后的森林生成类向量并将301实例类别概率维度连接为转换后的特征。
维度变化:1个实例400维->301个实例100维->2棵森林301个实例3维->1806维(2x301x3)
整体流程

阶段1:
1. 利用滑动窗口切分成多实例特征向量,经过森林变换输出类别概率向量。
2. 合并类别概率向量生成新的特征。
阶段2:
3. 输入特征经过森林输出类别概率向量,连接原始输入作为下一层输出。
4. 经过多个级联森林,输出最终的类别概率向量。
5. 对多个森林输出的类别概率向量求类别的均值概率向量,取最大的类别概率为预测结果。
优点
- 性能较之深度神经网络有很强的竞争力。
- gcForest较深度神经网络容易训练得多
- gcForest具有少得多的超参数,并且对参数设置不太敏感,在几乎完全一样的超参数设置下,在处理不同领域的不同数据时,也能达到极佳的性能,即对于超参数设定性能鲁棒性高。
- 训练过程效率高且可扩展,适用于并行的部署,其效率高的优势就更为明显。
- gcForest在仅有小规模训练数据的情况下也表现优异。
参考
Deep Forest: Towards An Alternative to Deep Neural Networks
==================================================================================================================================================================
gcForest - multi-grained cascade forest
周志华先生最近发布了论文Deep Forest: Towards An Alternative to Deep Neural Networks,做一些笔记如下。
一. 优点
- gcForest更易于训练,训练过程更加高效、可扩展;天生地倾向于并行运算:
1.1 相对深度网络更少的hyper-parameters;
1.2 在PC上的训练时间可以与GPU设备相比;
1.3 小规模的训练数据也能达到较好训练效果。 - 比深度网络更易理论分析。
its performance is quite robust to hyperparameter settings, such that in most cases, even across different data from different domains, it is able to get excellent performance by using the default setting.
二. 结构
1. Cascade Forest(级联森林)

`Cascade Forest`结构
每一层都是由决策树森林组成,并且决策树森林越多样越好。为简单起见,我们的决策树森林由两个random forest(blue)和两个complete-random tree forest(black)组成。假设有三个类要预测,因此每个森林输出都是一个三维向量。
每个complete-random tree forest包含1000个complete-random trees,它通过在树的每个节点随机选择feature来让树分支,并且每个树生长直到每个叶节点只包含实例的一个类或者少于10个实例。相似地,通过随机选取根号d个features作为候选(d是输入特征的数目),并选择具备最好gini值的用于切分,可得到具备1000棵树的random forest。每个森林中的树的棵树是一个hyper-parameter。
为了降低过拟合风险,每个森林会做k-fold cross validation,即训练数据会被使用k-1次并求均值,最后的均值才是最终输出给下一层的数据。
每新扩展一层,都会用验证集数据进行性能测试,若性能没有提升,则不会再进行扩展。因此本模型具备自动适应不同数据规模的能力。
每个森林内部的结构如下图所示:

类向量生成器 叶节点不同的形状代表不同的类
2. multi-grained scanning(多粒度扫描)
即 multi sliding window
==================================================================================================================================================================
周志华教授gcForest(多粒度级联森林)算法预测股指期货涨跌
2017年05月03日 13:44:27 数据轨迹 阅读数:1896
cForest Algorithm
对于周志华教授的文章,网上已经有人做出很详细的解释啦。我们对论文进行简单描述之后,然后直接从策略开始讲起。
gcForest(multi-Grained Cascade forest 多粒度级联森林)
是周志华教授最新提出的新的决策树集成方法。这种方法生成一个深度树集成方法(deep forest ensemble method),使用级联结构让gcForest学习。
gcForest模型把训练分成两个阶段:Multi-Grained Scanning和Cascade Forest。
Multi-Grained Scanning生成特征,
Cascade Forest经过多个森林多层级联得出预测结果。
它的表征学习能力可以通过对高维输入数据的多粒度扫描而进行加强。串联的层数也可以通过自适应的决定从而使得模型复杂度不需要成为一个自定义的超参数,而是一个根据数据情况而自动设定的参数。值得注意的是,gcForest会比DNN有更少的超参数,更好的一点在于gcForest对参数是有非常好的鲁棒性,哪怕用默认参数也可以获得很棒的结果。
级联森林(Cascade Forest)

因为决策树其实是在特征空间中不断划分子空间,并且给每个子空间打上标签(分类问题就是一个类别,回归问题就是一个目标值),所以给予一条测试样本,每棵树会根据样本所在的子空间中训练样本的类别占比生成一个类别的概率分布,然后对森林内所有树的各类比例取平均,输出整个森林对各类的比例。例如下图所示,这是根据图1的三分类问题的一个简化森林,每个样本在每棵树中都会找到一条路径去找到自己对应的叶节点,而同样在这个叶节点中的训练数据很可能是有不同类别的,我们可以对不同类别进行统计获取各类的比例,然后通过对所有树的比例进行求均值生成整个森林的概率分布。

多粒度扫描

多粒度扫描其实是引用了类似CNN的一个滑动窗口,例如说我们现在有一个400维的样本输入,现在设定采样窗口是100维的,那我们可以通过逐步的采样,最终获得301个子样本(因此这里默认的采样步长是1,所以得到的子样本个数 = (400-100)/1 + 1)。如果输入的是一个20*20的图片,利用一个10*10的采样窗口,就可以获得121个子样本(对每行和每列都是 (20-10)/1 + 1 = 11,11*11 = 121)。所以,整个多粒度扫描过程就是:先输入一个完整的P维样本,然后通过一个长度为k的采样窗口进行滑动采样,得到S = (P - K)/1+1 个k维特征子样本向量,接着每个子样本都用于完全随机森林和普通随机森林的训练并在每个森林都获得一个长度为C的概率向量,这样每个森林会产生长度为S*C的表征向量(就是经过随机森林转换并拼接的概率向量),最后把每层的F个森林的结果拼接在一起得到本层输出。
算法实现
鉴于此,在Github上,已经有人实现了算法代码。在这里我们提供一个基于python3的代码实现方法。选择采用scikit学习语法以方便使用,下面将介绍如何使用它。
GCForest.py源码如下,首先需要将此模块导入到根目录并命名为GCForest.py,当然最好是从github克隆下来。
gcForest in Python
Status : under development
gcForest is an algorithm suggested in Zhou and Feng 2017. It uses a multi-grain scanning approach for data slicing and a cascade structure of multiple random forests layers (see paper for details).
gcForest has been first developed as a Classifier and designed such that the multi-grain scanning module and the cascade structure can be used separately. During development I’ve paid special attention to write the code in the way that future parallelization should be pretty straightforward to implement.
Prerequisites
The present code has been developed under python3.x. You will need to have the following installed on your computer to make it work :
- Python 3.x
- Numpy >= 1.12.0
- Scikit-learn >= 0.18.1
- jupyter >= 1.0.0 (only useful to run the tuto notebook)
You can install all of them using pip install :
$ pip3 install requirements.txt
Using gcForest
The syntax uses the scikit learn style with a .fit() function to train the algorithm and a .predict() function to predict new values class. You can find two examples in the jupyter notebook included in the repository.
-
from GCForest import * -
gcf = gcForest( **kwargs ) -
gcf.fit(X_train, y_train) -
gcf.predict(X_test)
Notes
I wrote the code from scratch in two days and even though I have tested it on several cases I cannot certify that it is a 100% bug free obviously. Feel free to test it and send me your feedback about any improvement and/or modification!
Known Issues
Memory comsuption when slicing data There is now a short naive calculation illustrating the issue in the notebook. So far the input data slicing is done all in a single step to train the Random Forest for the Multi-Grain Scanning. The problem is that it might requires a lot of memory depending on the size of the data set and the number of slices asked resulting in memory crashes (at least on my Intel Core 2 Duo).
I have recently improved the memory usage (from version 0.1.4) when slicing the data but will keep looking at ways to optimize the code.
OOB score error During the Random Forests training the Out-Of-Bag (OOB) technique is used for the prediction probabilities. It was found that this technique can sometimes raises an error when one or several samples is/are used for all trees training.
A potential solution consists in using cross validation instead of OOB score although it slows down the training. Anyway, simply increasing the number of trees and re-running the training (and crossing fingers) is often enough.
Built With
- PyCharm community edition
- memory_profiler libra
License
This project is licensed under the MIT License (see LICENSE for details)
Early Results
(will be updated as new results come out)
- Scikit-learn handwritten digits classification :
training time ~ 5min
accuracy ~ 98%
部分代码:
-
import itertools -
import numpy as np -
from sklearn.ensemble import RandomForestClassifier -
from sklearn.model_selection import train_test_split -
from sklearn.metrics import accuracy_score -
__author__ = "Pierre-Yves Lablanche" -
__email__ = "plablanche@aims.ac.za" -
__license__ = "MIT" -
__version__ = "0.1.3" -
__status__ = "Development" -
# noinspection PyUnboundLocalVariable -
class gcForest(object): -
def __init__(self, shape_1X=None, n_mgsRFtree=30, window=None, stride=1, -
cascade_test_size=0.2, n_cascadeRF=2, n_cascadeRFtree=101, cascade_layer=np.inf, -
min_samples_mgs=0.1, min_samples_cascade=0.05, tolerance=0.0, n_jobs=1): -
""" gcForest Classifier.
关于规模
目前gcForest实现中的主要技术问题是在输入数据时的内存使用情况。真实的计算实际上可以让您了解算法将处理的对象的数量和规模。
计算C类[l,L]大小N维的问题,初始规模为:

Slicing Step
If my window is of size [wl,wL] and the chosen stride are [sl,sL] then the number of slices per sample is :

Obviously the size of slice is [wl,wL]hence the total size of the sliced data set is :

This is when the memory consumption is its peak maximum.
Class Vector after Multi-Grain Scanning
Now all slices are fed to the random forest to generate class vectors. The number of class vector per random forest per window per sample is simply equal to the number of slices given to the random forest

Hence, if we have Nrfrandom forest per window the size of a class vector is (recall we have N samples and C classes):

And finally the total size of the Multi-Grain Scanning output will be:

This short calculation is just meant to give you an idea of the data processing during the Multi-Grain Scanning phase. The actual memory consumption depends on the format given (aka float, int, double, etc.) and it might be worth looking at it carefully when dealing with large datasets.
预测每根K线涨跌
获取每根k线的交易数据后,把open,close,high,low,volume,ema, macd, linreg, momentum, rsi, var, cycle, atr作为特征指标,下根K线涨跌作为预测指标
-
#获取当前时间 -
from datetime import datetime -
now = datetime.now()
-
startDate = '2010-4-16' -
endDate = now -
#获取沪深300股指期货数据,频率为1分钟 -
df=get_price('IF88', start_date=startDate, end_date=endDate,\ -
frequency='1d', fields=None, country='cn') -
open = df['open'].values -
close = df['close'].values -
volume = df['volume'].values -
high = df['high'].values -
low = df['low'].values

-
import talib as ta -
import pandas as pd -
import numpy as np -
from sklearn import preprocessing -
ema = ta.EMA(close, timeperiod=30).tolist() -
macd = ta.MACD(close, fastperiod=12, slowperiod=26, signalperiod = 9)[0].tolist() -
momentum = ta.MOM(close, timeperiod=10).tolist() -
rsi = ta.RSI(close, timeperiod=14).tolist() -
linreg = ta.LINEARREG(close, timeperiod=14).tolist() -
var = ta.VAR(close, timeperiod=5, nbdev=1).tolist()#获取当前的收盘价的希尔伯特变换 -
cycle = ta.HT_DCPERIOD(close).tolist()#获取平均真实波动范围指标ATR,时间段为14 -
atr = ta.ATR(high, low, close, timeperiod=14).tolist()#把每根k线的指标放入数组X中,并转置 -
X = np.array([open,close,high,low,volume,ema, macd, linreg, momentum, rsi, var, cycle, atr]).T#输出可知数组X包含了ema, macd, linreg等13个指标数值 -
X[2]
array([ 3215. , 3267.2, 3281.2, 3208. , 114531. , nan,
nan, nan, nan, nan, nan, nan,
nan])
-
y=[] -
c=close[0] -
#用i遍历整个数据集 -
for i in range(1, len(X)): -
#如果高点突破参考线的1.0015倍,即上涨 -
if (close[i]>close[i-1]): -
#把参考点加到列表basicLine里,并且新参考点变为原来的1.0015倍, -
y.append(1) -
elif (close[i]<close[i-1]): -
y.append(0) -
elif (close[i]==close[i-1]): -
y.append(2) -
#添加最后一个数据的标签为1 -
y.append(1) -
#把y转化为ndarray数组 -
y=np.array(y) -
#输出验证标签集是否准确 -
print(len(y)) -
for i in range(1, 10): -
print(close[i],y[i],i)
1663
3214.6 1 1
3267.2 0 2
3236.2 0 3
3221.2 0 4
3219.6 0 5
3138.8 0 6
3129.0 0 7
3083.8 1 8
3107.0 0 9
-
#把数据集分解成随机的训练和测试子集, 参数test_size表示测试集所占比例 -
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.33) -
#输出可知测试特征集为维度是50*4的数组ndarray -
X_te.shape
(549, 13)
首先调用和训练算法. 参数shape_1X在这里是指某一样本的维度。
我把维度也作为图像特征输入到机器里. 显然,它与iris数据集并不是很相关,但仍然需要定义 .
0.1.3版本可输入整数作为 shape_1X参数。
gcForest参数说明
shape_1X:
单个样本元素的形状[n_lines,n_cols]。 调用mg_scanning时需要!对于序列数据,可以给出单个int。
n_mgsRFtree:
多粒度扫描期间随机森林中的树木数量。
window:int(default = None)
多粒度扫描期间使用的窗口大小列表。如果“无”,则不进行切片。
stride:int(default = 1)
切片数据时使用的步骤。
cascade_test_size:float或int(default = 0.2)
级联训练集分裂的分数或绝对数。
n_cascadeRF:int(default = 2)
级联层中随机森林的数量,对于每个伪随机森林,创建完整的随机森林,因此一层中随机森林的总数将为2 * n_cascadeRF。
n_cascadeRFtree:int(default = 101)
级联层中单个随机森林中的树数。
min_samples_mgs:float或int(default = 0.1)
节点中执行拆分的最小样本数 在多粒度扫描随机森林训练期间。 如果int number_of_samples = int。 如果float,min_samples表示要考虑的初始n_samples的分数。
min_samples_cascade:float或int(default = 0.1)
节点中执行拆分的最小样本数 在级联随机森林训练期间。 如果int number_of_samples = int。 如果float,min_samples表示要考虑的初始n_samples的分数。
cascade_layer:int(default = np.inf)
允许的最大级联级数。 有用的限制级联的结构。
tolerance:float(default= 0.0)
联生长的精度差,整个级联的性能将在验证集上进行估计, 如果没有显着的性能增益,训练过程将终止
n_jobs:int(default = 1)
任意随机森林适合并预测的并行运行的工作数量。 如果为-1,则将作业数设置为核心数。
-
#shape_1X样本维度,window为多粒度扫描(Multi-Grained Scanning)算法中滑动窗口大小,\ -
#用于扫描原始数据,tolerance为级联生长的精度差,整个级联的性能将在验证集上进行估计,\ -
#如果没有显着的性能增益,训练过程将终止#gcf = gcForest(shape_1X=4, window=2, tolerance=0.0) -
#gcf = gcForest(shape_1X=[13,13], window=2, tolerance=0.0) -
gcf = gcForest(shape_1X=13, n_mgsRFtree=100, window=6, stride=2, -
cascade_test_size=0.2, n_cascadeRF=4, n_cascadeRFtree=101, cascade_layer=np.inf, -
min_samples_mgs=0.1, min_samples_cascade=0.1, tolerance=0.0, n_jobs=1) -
gcf.fit(X_tr, y_tr)
Slicing Sequence…
Training MGS Random Forests…
Adding/Training Layer, n_layer=1
Layer validation accuracy = 0.5577889447236181
Adding/Training Layer, n_layer=2
Layer validation accuracy = 0.521608040201005
-
#shape_1X样本维度,window为多粒度扫描(Multi-Grained Scanning)算法中滑动窗口大小,\ -
#用于扫描原始数据,tolerance为级联生长的精度差,整个级联的性能将在验证集上进行估计,\ -
#如果没有显着的性能增益,训练过程将终止#gcf = gcForest(shape_1X=4, window=2, tolerance=0.0) -
#gcf = gcForest(shape_1X=[13,13], window=2, tolerance=0.0) -
gcf = gcForest(shape_1X=[1,13], window=[1,6],) -
gcf.fit(X_tr, y_tr)
Slicing Sequence…
Training MGS Random Forests…
Slicing Sequence…
Training MGS Random Forests…
Adding/Training Layer, n_layer=1
Layer validation accuracy = 0.5964125560538116
Adding/Training Layer, n_layer=2
Layer validation accuracy = 0.5695067264573991
参数改为shape_1X=[1,13], window=[1,6]后训练集达到0.59,不理想,这里只是抛砖引玉,调参需要大神指导。
Now checking the prediction for the test set:
现在看看测试集的预测值:
-
pred_X = gcf.predict(X_te) -
print(len(pred_X)) -
print(len(y_te)) -
print(pred_X)
Slicing Sequence…
Slicing Sequence…
549
549
[1 1 0 0 0 0 0 0 0 0 1 0 0 0 1 0 1 1 0 1 0 1 0 1 0 0 0 0 0 0 1 1 1 0 0 1 0等
-
#最近预测 -
for i in range(1,len(pred_X)): -
print(y_te[-i],pred_X[-i],-i)
0 1 -1
0 0 -2
1 0 -3
1 0 -4
0 1 -5
等
-
# 保存每一天预测的结果,如果某天预测对了,保存1,如果某天预测错了,保存-1 -
result_list = [] -
# 检查预测是否成功 -
def checkPredict(i): -
if pred_X[i] == y_te[i]: -
result_list.append(1) -
else: -
result_list.append(0) -
#画出最近第k+1个长度为j的时间段准确率 -
k=0j -
=len(y_te) -
#j=100 -
for i in range(len(y_te)-j*(k+1), len(y_te)-j*k): -
checkPredict(i) -
#print(y_pred[i]) -
#return result_list -
print(len(y_te) ) -
print(len(result_list) ) -
import matplotlib.pyplot as plt -
#将准确率曲线画出来 -
x = range(0, len(result_list)) -
y = [] -
#z=[] -
for i in range(0, len(result_list)): -
#y.append((1 + float(sum(result_list[:i])) / (i+1)) / 2) -
y.append( float(sum(result_list[:i])) / (i+1)) -
print('最近',j,'次准确率',y[-1]) -
print(x, y) -
line, = plt.plot(x, y) -
plt.show
549
549
最近 549 次准确率 0.5300546448087432
range(0, 549) [0.0, 0.0, 0.3333333333333333, 0.25等

-
#评估准确率 -
# evaluating accuracy -
accuracy = accuracy_score(y_true=y_te, y_pred=pred_X) -
print('gcForest accuracy : {}'.format(accuracy))
gcForest accuracy : 0.5300546448087432
预测结果很一般,不过还是有效的。
预测涨跌看起不是那么靠谱,但识别手写数字还是相当牛的。
下面只贴出结果:
-
# loading the data -
digits = load_digits() -
X = digits.data -
y = digits.target -
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.4) -
gcf = gcForest(shape_1X=[7,8], window=[4,6], tolerance=0.0, min_samples_mgs=10, min_samples_cascade=7) -
#gcf = gcForest(shape_1X=13, window=13, tolerance=0.0, min_samples_mgs=10, min_samples_cascade=7) -
gcf.fit(X_tr, y_tr)
Slicing Images…
Training MGS Random Forests…
Slicing Images…
Training MGS Random Forests…
Adding/Training Layer, n_layer=1
Layer validation accuracy = 0.9814814814814815
Adding/Training Layer, n_layer=2
Layer validation accuracy = 0.9814814814814815
-
# evaluating accuracy -
accuracy = accuracy_score(y_true=y_te, y_pred=pred_X) -
print('gcForest accuracy : {}'.format(accuracy))
gcForest accuracy : 0.980528511821975
厉害了,简单的参数都能使手写数字识别的准确率高达98%
单独利用多粒度扫描和级联森林
由于多粒度扫描和级联森林模块是相当独立的,因此可以单独使用它们。
如果给定目标“y”,代码将自动使用它进行训练,否则它会调用最后训练的随机森林来分割数据。
-
gcf = gcForest(shape_1X=[8,8], window=5, min_samples_mgs=10, min_samples_cascade=7) -
X_tr_mgs = gcf.mg_scanning(X_tr, y_tr)
Slicing Images…
Training MGS Random Forests…
It is now possible to use the mg_scanning output as input for cascade forests using different parameters. Note that the cascade forest module does not directly return predictions but probability predictions from each Random Forest in the last layer of the cascade. Hence the need to first take the mean of the output and then find the max.
-
gcf = gcForest(tolerance=0.0, min_samples_mgs=10, min_samples_cascade=7) -
_ = gcf.cascade_forest(X_tr_mgs, y_tr)
Adding/Training Layer, n_layer=1
Layer validation accuracy = 0.9722222222222222
Adding/Training Layer, n_layer=2
Layer validation accuracy = 0.9907407407407407
Adding/Training Layer, n_layer=3
Layer validation accuracy = 0.9814814814814815
-
import numpy as np -
pred_proba = gcf.cascade_forest(X_te_mgs) -
tmp = np.mean(pred_proba, axis=0) -
preds = np.argmax(tmp, axis=1) -
accuracy_score(y_true=y_te, y_pred=preds) -
gcf = gcForest(tolerance=0.0, min_samples_mgs=20, min_samples_cascade=10) -
_ = gcf.cascade_forest(X_tr_mgs, y_tr) -
pred_proba = gcf.cascade_forest(X_te_mgs) -
tmp = np.mean(pred_proba, axis=0) -
preds = np.argmax(tmp, axis=1) -
accuracy_score(y_true=y_te, y_pred=preds)
0.97774687065368571
Adding/Training Layer, n_layer=1
Layer validation accuracy = 0.9629629629629629
Adding/Training Layer, n_layer=2
Layer validation accuracy = 0.9675925925925926
Adding/Training Layer, n_layer=3
Layer validation accuracy = 0.9722222222222222
Adding/Training Layer, n_layer=4
Layer validation accuracy = 0.9722222222222222
0.97218358831710705
Skipping mg_scanning
It is also possible to directly use the cascade forest and skip the multi grain scanning step.
-
gcf = gcForest(tolerance=0.0, min_samples_cascade=20) -
_ = gcf.cascade_forest(X_tr, y_tr) -
pred_proba = gcf.cascade_forest(X_te) -
tmp = np.mean(pred_proba, axis=0) -
preds = np.argmax(tmp, axis=1) -
accuracy_score(y_true=y_te, y_pred=preds)
Adding/Training Layer, n_layer=1
Layer validation accuracy = 0.9583333333333334
Adding/Training Layer, n_layer=2
Layer validation accuracy = 0.9675925925925926
Adding/Training Layer, n_layer=3
Layer validation accuracy = 0.9583333333333334
0.94297635605006958
================================================================================================================================================================================================
gcForest算法原理及Python实现
摘要: 1.背景介绍 从目前来看深度学习大多建立在多层的神经网络基础上,也即一些参数化的多层可微的非线性模块,这样就可以通过后向传播去训练,Zhi-Hua Zhou和Ji Feng在Deep Forest论文中基于不可微的模块建立深度模块,这就是gcForest。
1.背景介绍
从目前来看深度学习大多建立在多层的神经网络基础上,也即一些参数化的多层可微的非线性模块,这样就可以通过后向传播去训练,Zhi-Hua Zhou和Ji Feng在Deep Forest论文中基于不可微的模块建立深度模块,这就是gcForest。
传统的深度学习有一定的弊端:
● 超参数个数较多,训练前需要大量初始化,主要靠经验调整,使得DNN更像一门艺术而非科学;
● DNN的训练要求大量的训练数据,数据的标注成本太高;
● DNN是一个黑盒子,训练的结果很难去解释描述,并且学习行为很难用理论去分析解释;
● DNN在训练之前就得确定具体的网络结构,模型的复杂度也是提前设定好的,虽然有一些dropout等的技术。
但是有一点是我们相信的,在处理更复杂的学习问题时,算法的学习模块应该要变的更深,现在的深层网络结构依旧依赖于神经网络(我们这里把像CNN,RNN的基本结构单元也归结为神经网络单元), 周志华团队考虑深度学习的结构可不可以用其他不可微的模块组成:
Can deep learning be realized with non-differentiable modules?
这个问题会使我们想到一些其他问题:
● 深度学习是不是就等同于DNN(深度模型是不是只能通过可微的函数结构去构建?)?
● 是不是可以不通过后向传播训练深度模型?
● 是不是使得在一些RandomForest,XGBoost,lightGBM成功的学习任务上,深度模型能够战胜它们?
下面我们就来看一下,周志华团队是如何从传统的机器学习和深度学习中获得灵感,构建gcForest的。
2.gcForest模型灵感来源
我们本节首先介绍gcForest模型构建的灵感来源,论文提到了两个方面,一个是在DNN中,一个是在集成学习(Ensemble Learning)。
(1) DNN中的灵感来源
深度学习在一些学习任务上之所以成功,关键在于特征的表示学习上(representation learning,不知道翻译的对不对 :)),如下图所示,随着一层一层的处理(layer-by-layer processing),马的图像数据的特征被高度抽象出来用于动物分类任务。

也就是说DNN在做分类任务时最终使用的是生成抽象出来的关键高层特征,而决策树,Boosting等传统机器学习模型只是使用初始的特征表示去学习,换句话说并没有做模型内部的特征变换(in_model feature transformation)。
除此之外,DNN可以设计成任意的复杂度,而决策树和Boosting模型的复杂度是有限的,充足的模型复杂度虽然不是DNN必要的取胜法宝,但是也是非常重要的。
总结在设计gcForest来自DNN的灵感:
● layer-by-layer processing
● in_model feature transformation
● suffcient model complexity
(2) 集成学习中的灵感来源
众所周知,集成学习通常比起单模型往往会有一个比较不错的表现,在构建一个好的集成模型时,要同时考虑子模型预测的准确度和子模型之间的多样性,尽量做到模型之间的互补,即理论上来说,子模型的准确度越高且子模型之间差异性越大(多样性),集成的效果越好。
但是,what is diversity? 怎样去度量模型之间的多样性?
在实践中,多样性增强的基本策略是在训练过程中引入基于启发式的随机性。粗略的说有4个机制:
● 数据样本机制: 它通过产生不同的数据样本来训练子模型;
● 输入特征机制:它通过选取不同特征子空间来训练子模型;
● 学习参数机制:他通过设定不同参数来使得子模型具有多样性;
● 输出表示机制:通过不同的输出表示增加子模型的多样性;
下一节通过本节的一些灵感构建gcForest模型。
3.gcForest模型
(1) 级联森林结构
基于上一节中的一些灵感,gcForest被构造成如下图所示的级联结构

解释:
● 每一个Level包含若干个集成学习的分类器(这里是决策树森林,你可以换成XGBoost,lightGBM等),这是一种集成中的集成的结构;
● 为了体现多样性,黑色和蓝色的Forest代表了若干不同的集成学习器,为了说明这里用了两种,黑色的是完全随机森林:由500棵决策树组成,每棵树随机选取一个特征作为分裂树的分裂节点,然后一直生成长,直到每个叶节点细分到只有一个类或者不多于10个样本,蓝色的表示普通的随机森林:由500棵决策树组成,每棵树通过随机选取sqrt(d)(d表示输入特征的维度)个候选特征然后通过gini系数筛选分裂节点;
● gcForest采用了DNN中的layer-by-layer结构,从前一层输入的数据和输出结果数据做concat作为下一层的输入;
● 为了防止过拟合的情况出现,每个森林的训练都使用了k-折交叉验证,也即每一个训练样本在Forest中都被使用k-1次,产生k-1个类别列表,取平均作为下一个Level级联的输入的一部分;
● 当级联扩展到新的Level后,之前所有级联结构的表现通过验证集去评估,如果评估结果没有太大的改变或提升则训练过程结束,因此级联结构的Level的个数被训练过程决定;
● 这里要注注意的是,当我们想控制训练过程的loss或限制计算资源的时候,我们也可以使用训练误差,而不是交叉验证的误差同样能够用于控制级联的增长;
● 以上这一点就是gcForest和神经网络的区别,gcForest可以通过训练自适应的调整模型的复杂度,并且在恰当的时候停止增加我们的Level;
(2) 多粒度扫描
为了增强级联森林结构我们增加了多粒度扫描,这实际上来源于深度网络中强大的处理特征之间关系能力,多粒度扫描的结构如下图所示

其过程可描述如下:
先输入一个完整的p维样本(p是样本特征的维度),然后通过一个长度为k的采样窗口进行滑动采样,得到s=(p-k)/1+1个k维特征子样本向量(这个过程就类似于CNN中的卷积核的操作,这里假设窗口移动的步长为1);接着每个子样本都用于完全随机森林和普通随机森林的训练,并在每个森林都获得一个长度为c的概率向量(c是分类类别个数,上图中c=3),这样每个森林都产生一个s*c的表征向量,最后把每层的F个森林的结果拼接在一起,得到样本输出。
上图是一个滑动窗口的简单情形,下图我们展示了多滑动窗口的过程:

这里的过程和上图中的过程是一致的,这里要特别注意在每个Level特征维度的变化,并且上图中的结构可以称为级联中的级联,也即每个级联结构中有多个级联子结构。
除了这种结构,我们的多粒度扫描的结构还可以有其他的形式,可以入下图所示:

这也是一种多粒度扫描结构,被称为gcForest_conc结构,即在多粒度扫描后进行了特征的concatenate,然后再去做级联结构,从实验结果上来看,该结构要稍微逊色于第一种结构。
(3) 小结
以上就是gcForset的模型结构和构建过程,我们可以清晰的看到gcForest的主要超参数:
级联结构中的超参数:
● 级联的每层的森林数
● 每个森林的决策树的数量
● 树停止生长的规则
多粒度扫描中的超参数:
● 多粒度扫描的森林数
● 每个森林的决策树数
● 树的停止生长规则
● 滑动窗口的数量和大小
其优点如下:
● 计算开销小,单机就相当于DNN中使用GPU(如果你没有钱购买GPU,可以考虑使用gcForest)
● 模型效果好(周老师的papar中实验对比了不同模型的效果,gcForest在传统的机器学习,图像,文本,语音上都表现不俗)
● 超参数少,模型对超参数不敏感,一套超参数可以用到不同的数据集
● 可以适用于不同大小的数据集,模型复杂度可自适用的伸缩
● 每个级联生成使用交叉验证,避免过拟合
● 相对于DNN,gcForest更容易进行理论分析
4.gcForest模型的Python实现
GitHub上有两个star比较多的gcForest项目,在参考文献中我们已经列出来了,下面我们就使用这两个gcForest的Python模块去尝试使用gcForest模型去解决一些问题,这里要说明的是其中参考文献3是官方提供(由gcForest的作者之一Ji Feng维护)的一个Python版本。目前gcForest并没有相对好用的R语言接口,我们在近期将会推出R语言的gcForest包,敬请期待。这里我们仅介绍参考文献4中的gcForest模块,如果感兴趣,可以自行研究官方提供的gcForest模块(官方模块,集成模型的选择除了随机森林外还可以选择其他的结构像XGBoost,ExtraTreesClassifierLogisticRegression,SGDClassifier等,因此建议使用该模块)。这里就介绍参考文献4中gcForest的模块使用。
Example1: iris数据集预测
from GCForest import gcForest
from sklearn.datasets import load_iris, load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
iris = load_iris()
X = iris.data
y = iris.target
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.33)
print(pd.DataFrame(X_tr).head())
# 注意里边的参数设置,详细的参数意义
# 可以参考源码中的参数解释
gcf = gcForest(shape_1X=4, window=2, tolerance=0.0)
gcf.fit(X_tr, y_tr)
# 类别预测
pred_X = gcf.predict(X_te)
print(pred_X)
pred_X_prob = gcf.predict_proba(X_te)
print(pred_X_prob)
# 模型评估
accuracy = accuracy_score(y_true=y_te, y_pred=pred_X)
print('gcForest accuracy : {}'.format(accuracy))
# 模型保存
from sklearn.externals import joblib
joblib.dump(gcf, 'my_iris_model.sav')
# 模型加载
# joblib.load('my_iris_model.sav')
Example2:Digits数据集预测
from GCForest import gcForest
from sklearn.datasets import load_iris, load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
import numpy as np
digits = load_digits()
X = digits.data
y = digits.target
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.4)
# 注意参数设定
gcf = gcForest(shape_1X=[8,8], window=[4,6], tolerance=0.0, min_samples_mgs=10, min_samples_cascade=7)
gcf.fit(X_tr, y_tr)
# 类别预测
pred_X = gcf.predict(X_te)
print(pred_X)
# 模型评估
accuracy = accuracy_score(y_true=y_te, y_pred=pred_X)
print('gcForest accuracy : {}'.format(accuracy))
Example3:多粒度扫描和级联结构分离
因为多粒度扫描和级联结构是相对独立的模块,因此是可以分开的,如果代码中提供了参数y,则会自动去做训练,如果参数y是None,代码会回调最后训练的随机森林进行数据切片。
# 模型根据y_tr进行训练
gcf = gcForest(shape_1X=[8,8], window=5, min_samples_mgs=10, min_samples_cascade=7)
X_tr_mgs = gcf.mg_scanning(X_tr, y_tr)
# 回调最后训练的随机森林模型
X_te_mgs = gcf.mg_scanning(X_te)
# 使用多粒度扫描的输出作为级联结构的输入,这里要注意
# 级联结构不能直接返回预测,而是最后一层级联Level的结果
# 因此,需要求平均并且取做大作为预测值
gcf = gcForest(tolerance=0.0, min_samples_mgs=10, min_samples_cascade=7)
_ = gcf.cascade_forest(X_tr_mgs, y_tr)
pred_proba = gcf.cascade_forest(X_te_mgs)
tmp = np.mean(pred_proba, axis=0)
preds = np.argmax(tmp, axis=1)
accuracy_score(y_true=y_te, y_pred=preds)
Example4:去除多粒度扫描的级联结构
我们也可以使用最原始的不带多粒度扫描的级联结构进行预测
gcf = gcForest(tolerance=0.0, min_samples_cascade=20)
_ = gcf.cascade_forest(X_tr, y_tr)
pred_proba = gcf.cascade_forest(X_te)
tmp = np.mean(pred_proba, axis=0)
preds = np.argmax(tmp, axis=1)
accuracy_score(y_true=y_te, y_pred=preds)
感兴趣的小伙伴可以研究一下,官方提供(由gcForest的作者之一 Ji Feng维护的)的模块,其实都差不多,如果感兴趣,我们后期也会做相关的介绍。
5.小结
文中我们介绍了gcForest的模型算法和Python代码的实现,目前gcForest算法的官方Python包[参考文献3]并未托管在Pypi,但v1.1.1支持Python3.5,也有大牛实现基于Python3.x的gcForest version0.1.6版本(上一节中已经演示),但其功能要相对弱于参考文献3;如果你喜欢用R语言,我们会在近期推出R语言的gcForest的R包,供R语言用户调用。
原文发布时间为:2018-10-18
本文作者:徐静
本文来自云栖社区合作伙伴“Python爱好者社区”,了解相关信息可以关注“Python爱好者社区”。
====================================================================================================================================================================================================================================================================================================================================================================
gcForest 集成学习方法的 Python 实现
2.8K
在这篇文章中:
-
- 前言
- 一、运行环境要求
- 二、gcForest 实现
- 附件:
前言
看完 gcForest 这篇 paper 有一段时间了,但是一直没有去网上搜集相关的实现代码,去把它调试跑通,并将之应用到实际的项目中。这两天终于抽空做了实现,并和自己项目中常用的集成算法(TreeNet、XGBoost)做了简单对比。下面总结一下整个算法的 Python 实现过程,以及将它应用到自己的数据集上出现的问题和解决办法。
一、运行环境要求
Python 版本:3.6.0 以上;
numpy 版本:1.12.0 以上;
jupyter 版本:1.0.0 以上;
scikit-learn 版本:0.18.1 以上。
解决办法: 可以直接在 Anaconda 官网 去下载对应操作系统的 Python 3.6 version;然后在 pycharm 上去选择对应版本的 project Interpreter;之后可以在 Package 列表中查看上述包对应的版本,不符合要求的可以直接更新。这样,整个 gcForest 算法的 Python 运行环境就 OK 了。
二、gcForest 实现
gcForest 算法在 github 上已经有大神实现了,版本也有好几个,我自己把其中一个版本(地址:https://github.com/pylablanche/gcForest) clone 到本地,并做了调试实现。
1) gcForest 算法实现
gcForest 算法的实现代码相对较多,直接以附件的形式上传,名称:GCForest.py(可以直接将该附件导入工程就可以了)。
2)示例——验证算法能否跑通
为了验证算法的可行性,写一个小的 demo 去测试,至于 model 中的参数(详细说明见具体实现类,12 个参数,一点儿也不多)可以根据自己的要求去调试,代码如下:
# -*- coding:utf-8 -*-
__author__ = 'Administrator'
from python_dailyworking.GCForest import gcForest
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from python_dailyworking.Get_KS import get_ks
import pandas as pd
#loading the iris data
iris = load_iris()
X = iris.data
Y = iris.target
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33)
gcf = gcForest(shape_1X=4, window = 2, tolerance=0.0)
gcf.fit(X_train, Y_train)
#predict 方法预测的是每一条样本的分类类别,结果 pred_X 是一个 [0,1,2...]的 array
pred_X = gcf.predict(X_test)
accuracy = accuracy_score(y_true=Y_test, y_pred=pred_X) #用 test 数据的真实类别和预测类别算准确率
print ('gcForest accuracy:{}'.format(accuracy))
# predict_proba 方法预测的是每一条样本为 0,1,...类别的概率,结果是这样的:
# [[ 概率 1,概率 2,...],[ 概率 1,概率 2,...],...]的 DataFrame
# [:,1]表示取出序号为 1 的列,也就是预测类别为 1 的概率值,结果是一个数组
Y_predict_prod_test = gcf.predict_proba(X_test)[:, 1]
Y_predict_prod_train = gcf.predict_proba(X_train)[:, 1]
#下面是算 KS 值,不理解的可以置之不理
print ('model Y_test ks: ',get_ks(Y_test, Y_predict_prod_test))
print ('model Y_train ks: ',get_ks(Y_train, Y_predict_prod_train))
上面的代码中要导入我们已经实现了的 GCForest 类(第三行),后面的模型训练和预测分类结果,跟正常的 Python 调用 sklearn 中的方法一样,都是 fit(X,Y),predict(X_test) 等;代码最后两句是计算训练样本和测试样本的 KS 值,读者可以不用管,不影响程序的可运行性(运行的时候可以注释掉)。
3)用自己的数据集去跑模型
自己的数据:csv 文件,5000 个样本(有点少,但是不影响测试算法),77 个特征;
代码实现如下:
# -*- coding:utf-8 -*-
__author__ = 'Administrator'
import pandas as pd
import time
import numpy as np
from sklearn.model_selection import train_test_split
from python_dailyworking.GCForest import gcForest
from python_dailyworking.Get_KS import get_ks
from sklearn.metrics import accuracy_score
def train():
input_path = 'D:\\working_temp_file\\final_combine_file_phone_xgb_77X.csv'
input_data = pd.read_csv(input_path)
drop_columns_all = 'bad'
targetName = 'bad'
X1 = input_data.drop(drop_columns_all, axis=1, inplace=False)
X1 = X1.fillna(0)
# 先将 X1 和 Y1(DataFrame)转化成 array
X = np.array(X1)
Y1 = input_data[targetName]
Y1 = Y1.fillna(0)
Y = np.array(Y1)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25)
starttime = time.time()
# gcForest Model
# shape_1X 默认是 None,但是用到 Multi-Grain Scanning 时,需要用到,我理解的是特征的数量(对于序列数据)
# window:滑动窗口的大小
# stride:滑动步长,默认是 1
# tolerance:提升的精度小于 tolerance 时,就停止整个过程。
# n_mgsRFtree=30, cascade_test_size=0.2, n_cascadeRF=2,
# n_cascadeRFtree=101, cascade_layer=np.inf,min_samples_mgs=0.1,
# min_samples_cascade=0.05, tolerance=0.0, n_jobs=1
gcf = gcForest(shape_1X=76, n_mgsRFtree=30, window=20,
stride=1, cascade_test_size=0.2, n_cascadeRF=2,
n_cascadeRFtree=50, cascade_layer=np.inf, min_samples_mgs=0.05,
min_samples_cascade=0.1, tolerance=0.0, n_jobs=1)
gcf.fit(X_train, Y_train)
pred_X = gcf.predict(X_test)
print (pred_X)
accuracy = accuracy_score(y_true=Y_test, y_pred=pred_X)
print ('gcForest accuracy:{}'.format(accuracy))
Y_predict_prod_test = gcf.predict_proba(X_test)[:, 1]
Y_predict_prod_train = gcf.predict_proba(X_train)[:, 1]
print ('model Y_test ks: ',get_ks(Y_test, Y_predict_prod_test))
print ('model Y_train ks: ',get_ks(Y_train, Y_predict_prod_train))
print ('整个模型的训练预测耗时为:',(time.time() - starttime))
if __name__ == '__main__':
train()
用自己的数据集去跑 gcForest 算法的时候,还是会遇到很多问题,特别是数据格式方面,可以根据自己的数据格式去做一系列的调试和格式转换。
4)算法对比
自己通过调参,简单的和线上的算法(XGBoost)以及另外一个集成学习算法 TreeNet 做了对比,由于 gcForest 算法中要做多粒度平滑处理和训练级联森林,所以当参数中的森林数量和对应树的数量较多时,训练模型的时间比 XGBoost 和 TreeNet 都长;效果嘛,gcForest 也稍逊一点。
说明:其实本篇文章的重点是实现测试 gcForest 算法,并对其做一个简单的应用尝试,初衷也不是和其他算法在自己数据集上做性能对比,本身这个算法的优势是做序列数据和图像数据,对于一般的常规数据样本,效果不好也可以理解,加上自己用的样本数量也太少了点,可能或多或少影响了 model 的精度。
写的比较仓促,或许会存在一些问题,希望看到的伙伴能不吝赐教,或者是有兴趣的同事,我们可以一起探讨交流,谢谢!
===========================================================================================================================================================================================================================================================================
如何利用gcForest为特征打分?
2018年12月26日 16:36:41 phyllisyuell 阅读数:197更多
楼主前面有一篇博客提到了周志华老师又一力作:gcForest:探索深度神经网络以外的方法,不了解的小伙伴可以翻前面的博客。
这个算法的确比传统的集成树算法:RandomForest,XGBoost,lightGBM都要优秀,而且引入层的概念后很好的解决了集成树算法容易过拟合的问题。
简单讲他就是借鉴了深度学习分层训练的思路,将机器学习中常用的RandomForest,XGBoost,LogisticRegression等算法进行集成,通过模型和样本的多样性让模型更加优秀。
正是因为它这种集成思想,反而抹杀了传统集成树算法的一大优势,gcForest无法给特征打分。原因很简单,它每层用的基学习器像前面提到的RandomForest,XGBoost提取特征的方式是不一样的:
首先RandomForest作为Bagging的代表,它是通过给指定特征X随机加入噪声,通过加入噪声前后袋外数据误差的差值来衡量该特征的重要程度。具体请参考:随机森林之特征选择;而XGBoost作为典型的Boosting算法提取特征的方式和RandomForest有很大的不同,看了下他的打分函数有weight,gain,cover三种方式,其中默认的是weight,这种方式其实就是统计特征X在每棵决策树当中出现的次数,最后特征X出现的次数之和就作为特征X的最后的得分。我们可以看出这两种算法打分方式不同,得到的数值也不是一个量纲的。同样LogisticRegression提取特征的方式也和前两者不一样。
并且gcForst还提供了用户自己添加基学习器的接口(添加方法请了解:gcForest官方代码详解),也就意味着gcForest还可以使用更多的基学习器,如果要封装一个提取重要特征的方法,就要考虑太多太多,每进来一个基学习器都要改变特征打分的方法。
综上所述,我觉得也是gcForest作者没有封装特征打分方法的原因。
基于我的问题,我做了一些思考。我处理的数据用RandomForest,XGBoost都能得到不错的结果,我们知道RandomForest可以很好的减少方差,XGBoost可以很好的减少偏差。为了构建一个低偏差和低方差的模型,我想将这两种算法进行集成。所以在gcForest中我只用了这两个基学习器。

通过对RandomForest,XGBoost打分函数的学习,我和小伙伴shi.chao 对gcForest封装了一个特征打分方法,利用的还是源码里手写数字识别的数据,每层只有RandomForest,XGBoost,为了方便调试,就构建了两层。
大体思想如下:
在源码目录:lib->gcforest->cascade->cascade_classifier.py fit_transform()方法中进行了一些操作。这个方法就是gcForest进行模型训练的函数。上面也提到了不同的算法特征打分的方法是不一样的,所以在这里需要通过变量est_configs["type"]对基学习器类型进行判断。如果是RandomForest,就直接调用RandomForest的打分函数,得到该基学习器返回的一个map,其中包含特征名称和得分,这里用一个临时变量保存,等到下一层获取RandomFores打分函数得到的另一个map,然后将这个两个map合并,相同key的将value累加,最后得到一个final_feature_rf_importance_list,是整个gcForest所有层中RandomFores得到的特征得分。XGBoost,类似操作。具体见代码注释。
感兴趣的小伙伴可以在这个基础上继续对另外的基学习器特征打分算法进行封装。最后gcForest的特征得分:可以是各个基学习器特征得分的一个融合。
比如我的模型中只用到了RandomForest和XGBoost,最后gcForest的第i个特征的得分可以这样表示:
Zi = w1 * Xi/sum(X) + w2 * Yi/sum(Y)
其中Xi代表RandomForest中第i个特征的得分,Yi代表XGBoost中第i个特征的得分,这两个值虽然不是一个量纲,但是通过处以它们全部特征之和就可以得到该特征在它的模型中的相对特征,最后通过设置w1,w2的系数,可以调整两种模型在gcForest中的重要程度。
代码已经开源到github:https://github.com/phyllisyuell/gcForest-master-feature
欢迎各位交流学习,批评指正。
有问题请联系,一起讨论:285794144.@qq.com















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









