






程序存储器
指令寄存器
程序计数器
地址寄存器
=================================================================================================
================================================================================================
=================================================================================================
1. 寄存器是中央处理器内的组成部份。寄存器是有限存贮容量的高速存贮部件,它们可用来暂存指令、数据和位址。在中央处理器的控制部件中,包含的寄存器有指令寄存器(IR)和程序计数器(PC)。在中央处理器的算术及逻辑部件中,包含的寄存器有累加器(ACC)。2. 内存包含的范围非常广,一般分为只读存储器(ROM)、随机存储器(RAM)和高速缓存存储器(cache)。
\3. 寄存器是CPU内部的元件,寄存器拥有非常高的读写速度,所以在寄存器之间的数据传送非常快。
4. Cache :即高速缓冲存储器,是位于CPU与主内存间的一种容量较小但速度很高的存储器。由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,这样就减少了CPU的等待时间,提高了系统的效率。Cache又分为一级Cache(L1 Cache)和二级Cache(L2 Cache),L1 Cache集成在CPU内部,L2 Cache早期一般是焊在主板上,现在也都集成在CPU内部,常见的容量有256KB或512KB L2 Cache。
总结:大致来说数据是通过内存-Cache-寄存器,Cache缓存则是为了弥补CPU与内存之间运算速度的差异而设置的的部件。
http://blog.csdn.net/csuyishuan/article/details/52073421
首先看一下计算机的存储体系(Memory hierarchy)金字塔
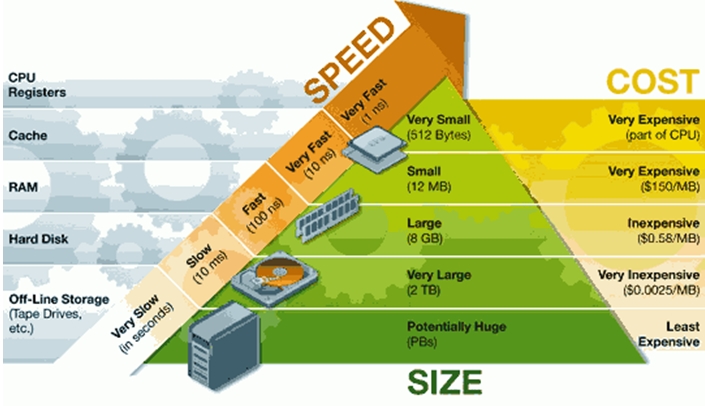
其次我们看看一个计算机的存储体系
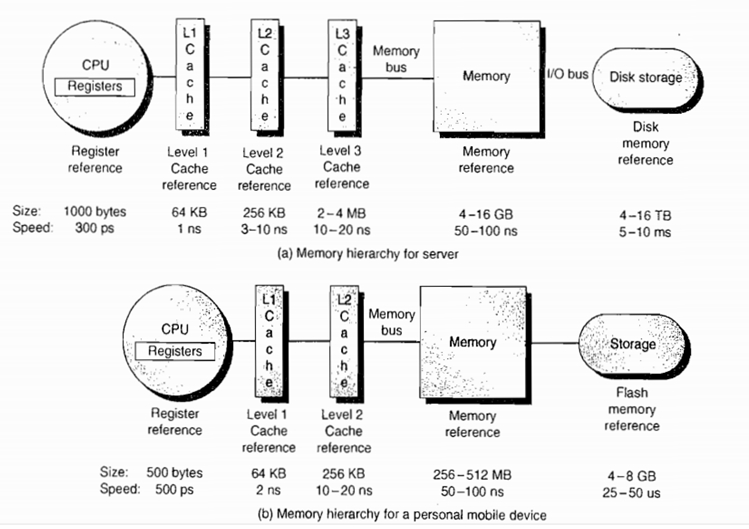
Register
寄存器是CPU的内部组成单元,是CPU运算时取指令和数据的地方,速度很快,寄存器可以用来暂存指令、数据和地址。在CPU中,通常有通用寄存器,如指令寄存器IR;特殊功能寄存器,如程序计数器PC、sp等。
Cache
缓存即就是用于暂时存放内存中的数据,若果寄存器要取内存中的一部分数据时,可直接从缓存中取到,这样可以调高速度。高速缓存是内存的部分拷贝。
CPU <— > 寄存器<— > 缓存<— >内存
寄存器的工作方式很简单,只有两步:(1)找到相关的位,(2)读取这些位。
内存的工作方式就要复杂得多:
(1)找到数据的指针。(指针可能存放在寄存器内,所以这一步就已经包括寄存器的全部工作了。)
(2)将指针送往内存管理单元(MMU),由MMU将虚拟的内存地址翻译成实际的物理地址。
(3)将物理地址送往内存控制器(memory controller),由内存控制器找出该地址在哪一根内存插槽(bank)上。
(4)确定数据在哪一个内存块(chunk)上,从该块读取数据。
(5)数据先送回内存控制器,再送回CPU,然后开始使用。
内存的工作流程比寄存器多出许多步。每一步都会产生延迟,累积起来就使得内存比寄存器慢得多。
为了缓解寄存器与内存之间的巨大速度差异,硬件设计师做出了许多努力,包括在CPU内部设置缓存、优化CPU工作方式,尽量一次性从内存读取指令所要用到的全部数据等等。
RAM-memory
即内存,是用于存放数据的单元。其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。
HardDisk
硬盘
作者:时国怀
链接:http://www.zhihu.com/question/20075426/answer/16354329
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
一条汇编指令大概执行过程是(不是绝对的,不同平台有差异):
取指(取指令)、译码(把指令转换成微指令)、取数(读内存里的操作数)、计算(各种计算的过程,ALU负责)、写回(将计算结果写回内存),有些平台里,前两步会合并成一步,某些指令也不会有取数或者回写的过程。
再提一下CPU主频的概念:首先,主频绝对不等于一秒钟可以执行的指令个数,每个指令的执行成本是不同的,比如x86平台里汇编指令INC就比ADD要快,具体每个指令的时钟周期可以参考intel的手册。
为什么要提主频?因为上面的执行过程中,每个操作都需要占用一个时钟周期,对于一个操作内存的加法,就需要5个时钟周期,换句话说,500Mhz主频的CPU,最多执行100MHz条指令。
仔细观察,上面的步骤里不包括寄存器操作,对于CPU来说读/写寄存器是不需要时间的,或者说如果只是操作寄存器(比如类似mov BX,AX之类的操作),那么一秒钟执行的指令个数理论上说就等于主频,因为寄存器是CPU的一部分。
然后寄存器往下就是各级的cache,有L1 cache,L2,甚至有L3的,以及TLB这些(TLB也可以认为是cache),之后就是内存,前面说寄存器快,现在说为什么这些慢:
对于各级的cache,访问速度是不同的,理论上说L1cache(一级缓存)有着跟CPU寄存器相同的速度,但L1cache有一个问题,当需要同步cache和内存之间的内容时,需要锁住cache的某一块(术语是cache line),然后再进行cache或者内存内容的更新,这段期间这个cache块是不能被访问的,所以L1cache的速度就没寄存器快,因为它会频繁的有一段时间不可用。
L1 cache下面是L2 cache,甚至L3 cache,这些都有跟L1 cache一样的问题,要加锁,同步,并且L2比L1慢,L3比L2慢,这样速度也就更低了。
最后说说内存,内存的主频现在主流是1333左右吧?或者1600,单位是MHz,这比CPU的速度要低的多,所以内存的速度起点就更低,然后内存跟CPU之间通信也不是想要什么就要什么的。
内存不仅仅要跟CPU通信,还要通过DMA控制器与其它硬件通信,CPU要发起一次内存请求,先要给一个信号说“我要访问数据了,你忙不忙?”如果此时内存忙,则通信需要等待,不忙的时候,通信才能正常。并且,这个请求信号的时间代价,就是够执行几个汇编指令了,所以,这是内存慢的一个原因。
另一个原因是:内存跟CPU之间通信的通道也是有限的,就是所谓的“总线带宽”,但,要记住这个带宽不仅仅是留给内存的,还包括显存之类的各种通信都要走这条路,并且由于路是共享的,所以任何请求发起之间都要先抢占,抢占带宽需要时间,带宽不够等待的话也需要时间。
以上两条加起来导致了CPU访问内存更慢,比cache还慢。
举个更容易懂的例子:
CPU要取寄存器AX的值,只需要一步:把AX给我拿来,AX就拿来了。
CPU要取L1 cache的某个值,需要1-3步(或者更多):把某某cache行锁住,把某个数据拿来,解锁,如果没锁住就慢了。
CPU要取L2 cache的某个值,先要到L1 cache里取,L1说,我没有,在L2里,L2开始加锁,加锁以后,把L2里的数据复制到L1,再执行读L1的过程,上面的3步,再解锁。
CPU取L3 cache的也是一样,只不过先由L3复制到L2,从L2复制到L1,从L1到CPU。
CPU取内存则最复杂:通知内存控制器占用总线带宽,通知内存加锁,发起内存读请求,等待回应,回应数据保存到L3(如果没有就到L2),再从L3/2到L1,再从L1到CPU,之后解除总线锁定。
磁盘缓存和内存缓存的区别
内存缓存
高速缓存(英语:cache,英语发音:/kæʃ/ kash [1][2][3],简称缓存),其原始意义是指访问速度比一般随机存取存储器(RAM)快的一种RAM,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。
原理
Cache一词来源于1967年的一篇电子工程期刊论文。其作者将法语词“cache”赋予“safekeeping storage”的涵义,用于电脑工程领域。
当CPU处理数据时,它会先到Cache中去寻找,如果数据因之前的操作已经读取而被暂存其中,就不需要再从随机存取存储器(Main memory)中读取数据——由于CPU的运行速度一般比主内存的读取速度快,主存储器周期(访问主存储器所需要的时间)为数个时钟周期。因此若要访问主内存的话,就必须等待数个CPU周期从而造成浪费。
提供“缓存”的目的是为了让数据访问的速度适应CPU的处理速度,其基于的原理是内存中“程序执行与数据访问的局域性行为”,即一定程序执行时间和空间内,被访问的代码集中于一部分。为了充分发挥缓存的作用,不仅依靠“暂存刚刚访问过的数据”,还要使用硬件实现的指令预测与数据预取技术——尽可能把将要使用的数据预先从内存中取到缓存里。
CPU的缓存曾经是用在超级计算机上的一种高级技术,不过现今电脑上使用的的AMD或Intel微处理器都在芯片内部集成了大小不等的数据缓存和指令缓存,通称为L1缓存(L1 Cache即Level 1 On-die Cache,第一级片上高速缓冲存储器);而比L1更大容量的L2缓存曾经被放在CPU外部(主板或者CPU接口卡上),但是现在已经成为CPU内部的标准组件;更昂贵的CPU会配备比L2缓存还要大的L3缓存(level 3 On-die Cache第三级高速缓冲存储器)。
概念的扩充
如今缓存的概念已被扩充,不仅在CPU和主内存之间有Cache,而且在内存和硬盘之间也有Cache(磁盘缓存),乃至在硬盘与网络之间也有某种意义上的Cache──称为Internet临时文件夹或网络内容缓存等。凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为Cache。
地址镜像与变换
主条目:CPU缓存#组相联
由于主存容量远大于CPU缓存的容量,因此两者之间就必须按一定的规则对应起来。地址镜像就是指按某种规则把主存块装入缓存中。地址变换是指当按某种镜像方式把主存块装入缓存后,每次访问CPU缓存时,如何把主存的物理地址(Physical address)或虚拟地址(Virtual address)变换成CPU缓存的地址,从而访问其中的数据。
缓存置换策略
主条目:CPU缓存#置换策略、分页和缓存文件置换机制
主存容量远大于CPU缓存,磁盘容量远大于主存,因此无论是哪一层次的缓存都面临一个同样的问题:当容量有限的缓存的空闲空间全部用完后,又有新的内容需要添加进缓存时,如何挑选并舍弃原有的部分内容,从而腾出空间放入这些新的内容。解决这个问题的算法有几种,如最久未使用算法(LRU)、先进先出算法(FIFO)、最近最少使用算法(LFU)、非最近使用算法(NMRU)等,这些算法在不同层次的缓存上执行时拥有不同的效率和代价,需根据具体场合选择最合适的一种。
磁盘缓存
磁盘缓存
16MB缓冲区的硬盘
磁盘缓存(Disk Buffer)或磁盘快取(Disk Cache)实际上是将下载到的数据先保存于系统为软件分配的内存空间中(这个内存空间被称之为“内存池”),当保存到内存池中的数据达到一个程度时,便将数据保存到硬盘中。这样可以减少实际的磁盘操作,有效的保护磁盘免于重复的读写操作而导致的损坏。
磁盘缓存是为了减少CPU透过I/O读取磁盘机的次数,提升磁盘I/O的效率,用一块内存来储存存取较频繁的磁盘内容;因为内存的存取是电子动作,而磁盘的存取是I/O动作,感觉上磁盘I/O变得较为快速。
相同的技巧可用在写入动作,我们先将欲写入的内容放入内存中,等到系统有其它空闲的时间,再将这块内存的资料写入磁盘中。
大小
现在的磁盘通常有32MB或64MB缓存。旧的硬盘则有8MB或16MB。
================================================================================================================================================================================================================================================================================================================
昨晚看到了深夜,终于对进程的虚拟地址空间有了个大致的了解,很激动,也很欣慰。回头想来,一个程序员,真的应该知道这些知识,否则还真不太称职。
首先告诉大家,我后面提到的这些知识在《windows核心编程》中都有,强烈建议大家把这本书翻翻,我相信会对你的编程境界拔高好几个层次的。可是我最近没那么多时间,因此就只能了解个大概,然后等今后闲暇时再看这本书吧。昨天我媳妇还反复和我说:学东西必须要有选择,不能对IT行业的所有知识乱学习,而且不要学那种实际意义不大的知识或是容易被淘汰的知识。其实她说的蛮对的,但是我要说,有关《windows核心编程》里的知识永远都不会过时,因为它侵入到底层和内部了,就像C++,你觉得会过时吗?就像windows永远不会被淘汰一样,呵呵。
下面我就来粗略的说说我了解的一些基本知识:
32位机器,每个程序有4G的虚拟地址空间。大致分为4块,从低地址到高地址依次是:NULL区,用户区,隔离区,核心区。用户私有的数据都在用户区(当然这个区里又可以细分,其中也包括一部分可以共享的内容),系统内核等东西都在核心区。总体来说,A进程的虚拟地址空间中的内容和B进程相比,只有各自的用户区不一致。通常用户区中,进程又会将exe文件(由头数据和段数据组成)中定义的代码段、堆栈段、数据段等各个段映射到用户区的特定不同部位。对于这部分区域,用户需要用VirtualAlloc先为自己预留后再提交,最后在自己的页面被cpu访问时再从exe映像中将数据加载到主存,然后将虚拟地址映射为主存的物理地址。基本上这样就可以了,至于系统如何进行页面的管理以及地址映射如何实现等细节请大家再参考别的文献。
我本以为很复杂呢,结果写出来,就这么一小段,呵呵,看来是高估了自己理解的东西了,呵呵。
下面贴出我看的一些资料:
虚拟存储器是一个抽象概念,它为每一个进程提供了一个假象,好像每个进程都在独占的使用主存。每个进程看到的存储器都是一致的,称之为虚拟地址空间。
每个进程看到得虚拟地址空间有大量准确定义的区(area)构成,每个区都有专门的功能。从最低的地址看起:
- 程序代码和数据:代码是从同一固定地址开始,紧接着的是和C全局变量相对应的数据区。 (应该就是所谓的静态存储空间)
- 堆:代码和数据区后紧随着的是运行时堆。作为调用malloc和free这样的C标准库函数,堆可以在运行时动态的扩展和收缩。(应该就是所谓的动态存储区)
- 共享库:在地址空间的中间附近是一块用来存放像C标准库和数学库这样共享库的代码和数据的区域。(C标准库函数的指令,连接阶段把他们加入到编译后的程序)
- 栈:位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数调用。和堆一样每次我们从函数返回时,栈就会收缩。
- 内核虚拟存储器:内核是操作系统总是驻留在存储器中的部分。地址空间顶部的四分之一部分是为内核预留的。(系统函数?这里说的UNIX系统,不知道windows下是不是这样的?)
今天大多数计算机的字长都是32字节,这就限制了虚拟地址空间为4千兆字节(4GB)
引言
Windows的内存结构是深入理解Windows操作系统如何运作的最关键之所在,通过对内存结构的认识可清楚地了解诸如进程间数据的共享、对内存进行有效的管理等问题,从而能够在程序设计时使程序以更加有效的方式运行。Windows操作系统对内存的管理可采取多种不同的方式,其中虚拟内存的管理方式可用来管理大型的对象和结构数组。
在Windows系统中,任何一个进程都被赋予其自己的虚拟地址空间,该虚拟地址空间覆盖了一个相当大的范围,对于32位进程,其地址空间为232=4,294,967,296 Byte,这使得一个指针可以使用从0x00000000到0xFFFFFFFF的4GB范围之内的任何一个值。虽然每一个32位进程可使用4GB的地址空间,但并不意味着每一个进程实际拥有4GB的物理地址空间,该地址空间仅仅是一个虚拟地址空间,此虚拟地址空间只是内存地址的一个范围。进程实际可以得到的物理内存要远小于其虚拟地址空间。进程的虚拟地址空间是为每个进程所私有的,在进程内运行的线程对内存空间的访问都被限制在调用进程之内,而不能访问属于其他进程的内存空间。这样,在不同的进程中可以使用相同地址的指针来指向属于各自调用进程的内容而不会由此引起混乱。下面分别对虚拟内存的各具体技术进行介绍。
地址空间中区域的保留与释放
在进程创建之初并被赋予地址空间时,其虚拟地址空间尚未分配,处于空闲状态。这时地址空间内的内存是不能使用的,必须首先通过VirtualAlloc()函数来分配其内的各个区域,对其进行保留。
LPVOID VirtualAlloc(
LPVOID lpAddress,
DWORD dwSize,
DWORD flAllocationType,
DWORD flProtect
);
其参数lpAddress包含一个内存地址,用于定义待分配区域的首地址。通常可将此参数设置为NULL,由系统通过搜索地址空间来决定满足条件的未保留地址空间。这时系统可从地址空间的任意位置处开始保留一个区域,而且还可以通过向参数flAllocationType设置MEM_TOP_DOWN标志来指明在尽可能高的地址上分配内存。如果不希望由系统自动完成对内存区域的分配而为lpAddress设定了内存地址(必须确保其始终位于进程的用户模式分区中,否则将会导致分配的失败),那么系统将在进行分配之前首先检查在该内存地址上是否存在足够大的未保留空间,如果存在一个足够大的空闲区域,那么系统将会保留此区域并返回此保留区域的虚拟地址,否则将导致分配的失败而返回NULL。这里需要特别指出的是,在指定lpAddress的内存地址时,必须确保是从一个分配粒度的边界处开始。
一般来说,在不同的CPU平台下分配粒度各不相同,但目前所有Windows环境下的CPU如x86、32位Alpha、64位Alpha以及IA-64等均是采用64KB的分配粒度。如果保留区域的起始地址没有遵循从64KB分配粒度的边界开始之一原则,系统将自动调整该地址到最接近的64K的倍数。例如,如果指定的lpAddress为0x00781022,那么此保留区域实际是从0x00780000开始分配的。参数dwSize指定了保留区域的大小。但是系统实际保留的区域大小必须是CPU页面大小的整数倍,如果指定的dwSize并非CPU页面的整数倍,系统将自动对其进行调整,使其达到与之最接近的页面大小整数倍。与分配粒度一样,对于不同的CPU平台其页面大小也是不一样的。在x86平台下,页面大小为4KB,在32位Alpah平台下,页面大小为8KB。在使用时可以通过GetSystemInfo()来决定当前主机的页面大小。参数flAllocationType和flProtect分别定义了分配类型和访问保护属性。由于VirtualAlloc()可用来保留一个区域也可以用来占用物理存储器,因此通过flAllocationType来指定当前是要保留一个区域还是要占用物理存储器。其可能使用的内存分配类型有:
分配类型 | 类型说明 |
MEM_COMMIT | 为特定的页面区域分配内存中或磁盘的页面文件中的物理存储 |
MEM_PHYSICAL | 分配物理内存(仅用于地址窗口扩展内存) |
MEM_RESERVE | 保留进程的虚拟地址空间,而不分配任何物理存储。保留页面可通过继续调用VirtualAlloc()而被占用 |
MEM_RESET | 指明在内存中由参数lpAddress和dwSize指定的数据无效 |
MEM_TOP_DOWN | 在尽可能高的地址上分配内存(Windows 98忽略此标志) |
MEM_WRITE_WATCH | 必须与MEM_RESERVE一起指定,使系统跟踪那些被写入分配区域的页面(仅针对Windows 98) |
分配成功完成后,即在进程的虚拟地址空间中保留了一个区域,可以对此区域中的内存进行保护权限许可范围内的访问。当不再需要访问此地址空间区域时,应释放此区域。由VirtualFree()负责完成。其函数原型为:
BOOL VirtualFree( |
其中,参数lpAddress为指向待释放页面区域的指针。如果参数dwFreeType指定了MEM_RELEASE,则lpAddress必须为页面区域被保留时由VirtualAlloc()所返回的基地址。参数dwSize指定了要释放的地址空间区域的大小,如果参数dwFreeType指定了MEM_RELEASE标志,则将dwSize设置为0,由系统计算在特定内存地址上的待释放区域的大小。参数dwFreeType为所执行的释放操作的类型,其可能的取值为MEM_RELEASE和MEM_DECOMMIT,其中MEM_RELEASE标志指明要释放指定的保留页面区域,MEM_DECOMMIT标志则对指定的占用页面区域进行占用的解除。如果VirtualFree()成功执行完成,将回收全部范围的已分配页面,此后如再对这些已释放页面区域内存的访问将引发内存访问异常。释放后的页面区域可供系统继续分配使用。
下面这段代码演示了由系统在进程的用户模式分区内保留一个64KB大小的区域,并将其释放的过程:
// 在地址空间中保留一个区域
LPBYTE bBuffer = (LPBYTE)VirtualAlloc(NULL, 65536, MEM_RESERVE, PAGE_READWRITE);
……
// 释放已保留的区域
VirtualFree(bBuffer, 0, MEM_RELEASE);
flProtect页面保护属性
我们可以给每个已分配的物理存储页指定不同的页面保护属性。表13-3列出了所有的页面保护属性。
表13-3 内存页面保护属性
保护属性 | 描 述 |
PAGE_NOACCESS | 试图读取页面、写入页面或执行页面中的代码将引发访问违规 |
PAGE_READONLY | 试图写入页面或执行页面中的代码将引发访问违规 |
PAGE_READWRITE | 试图执行页面中的代码将引发访问违规 |
PAGE_EXECUTE | 试图读取页面或写入页面将引发访问违规 |
PAGE_EXECUTE_READ | 试图写入页面将引发访问违规 |
PAGE_EXECUTE_READWRITE | 对页面执行任何操作都不会引发访问违规 |
PAGE_WRITECOPY | 试图执行页面中的代码将引发访问违规。试图写入页面将使系统为进程单独创建一份该页面的私有副本(以页交换文件为后备存储器) |
PAGE_EXECUTE_WRITECOPY | 对页面执行任何操作都不会引发访问违规。试图写入页面将使系统为进程单独创建一份该页面的私有副本(以页交换文件为后备存储器) |
一些恶意软件将代码写入到用于数据的内存区域(比如线程栈上),通过这种方式让应用程序执行恶意代码。Windows的数据执行保护(Data Execution Protection,后面简称为DEP)特性提供了对此类恶意攻击的防护。如果启用了DEP,那么只有对那些真正需要执行代码的内存区域,操作系统才会使用PAGE_EXECUTE_*保护属性。其他保护属性(最常见的就是PAGE_READWRITE)用于只应该存放数据的内存区域(比如线程栈和应用程序的堆)。
如果CPU试图执行某个页面中的代码,而该页又没有PAGE_EXECUTE_*保护属性,那么CPU会抛出访问违规异常。
系统还对Windows支持的结构化异常处理机制(structured exception handling mechanism)做了更进一步的保护,结构化异常处理机制会在第23~25章详细介绍。如果应用程序在链接时使用了/SAFESEH开关,那么异常处理器会被注册到映像文件中一个特殊的表中。这样,当将要执行一个异常处理器时,操作系统会先检查该处理器有没有在表中注册过,然后决定是否允许它执行。
有关DEP的更多信息,请访问http://go.microsoft.com/fwlink/?LinkId=28022,可以在此找到Microsoft白皮书“03_CIF_Memory_Protection.DOC”。
13.6.1 写时复制
在表13.3中列出的保护属性中,除最后两个属性PAGE_WRITECOPY和PAGE_EXECUTE_WRITECOPY之外,其余的都不言自明。这两个保护属性存在的目的是为了节省内存和页交换文件的使用。Windows支持一种机制,允许两个或两个以上的进程共享同一块存储器。因此,如果有10个记事本程序正在运行,所有的进程会共享应用程序的代码页和数据页。让所有的应用程序实例共享相同的存储页极大地提升了系统的性能,但另一方面,这也要求所有的应用程序实例只能读取其中的数据或是执行其中的代码。如果某个应用程序实例修改并写入一个存储页,那么这等于是修改了其他实例正在使用的存储页,最终将导致混乱。
为了避免此类混乱的发生,操作系统会给共享的存储页指定写时复制属性。当系统把一个.exe或.dll映射到一个地址空间的时候,系统会计算有多少页面是可写的。(通常,包含代码的页面被标记为PAGE_EXECUTE_READ,而包含数据的页面被标记为PAGE_READWRITE。)然后系统会从页交换文件中分配存储空间来容纳这些可写页面。除非应用程序真的写入可写页面,否则不会用到页交换文件中的存储器。
当线程试图写入一个共享页面时,系统会介入并执行下面的操作。
(1) 系统在内存中找到一个闲置页面。注意,该闲置页面的后备页面来自页交换文件,它是系统最初将模块映射到进程的地址空间时分配的。由于系统在第一次进行映射的时候分配了所有可能需要的页交换文件空间,这一步不可能失败。
(2) 系统把线程想要修改的页面内容复制到在第1步中找到的闲置页面。系统会给该闲置页面指定PAGE_READWRITE或PAGE_EXECUTE_READWRITE保护属性,系统不会对原始页面的保护属性和数据做任何修改。
(3) 然后,系统更新进程的页面表,这样一来,原来的虚拟地址现在就对应到内存中一个新的页面了。
系统在执行这些步骤之后,进程就可以访问它自己的副本了。第17章将进一步介绍存储器共享和写时复制。
此外,在预订地址空间或调拨物理存储器时,不能使用PAGE_WRITECOPY或PAGE_EXECUTE_WRITECOPY保护属性。这样做会导致调用VirtualAlloc失败,此时调用GetLastError会返回错误码ERROR_INVALID_PARAMETER。这两个属性是操作系统在映射.exe或DLL映像文件时用的。
13.6.2 一些特殊的访问保护属性标志
除了已经介绍过的保护属性之外,另外还有3个保护属性标志:PAGE_NOCACHE,PAGE_WRITECOMBINE和PAGE_GUARD。使用这些标志时,只需将它们与除了PAGE_NOACCESS之外的任何其他保护属性进行按位或操作即可。
第一个保护属性标志PAGE_NOCACHE,用来禁止对已调拨的页面进行缓存。该标志存在的主要目的是为了让需要操控内存缓冲区的驱动程序开发人员使用,不建议将该标志用于除此以外的其他用途。
第二个保护属性标志PAGE_WRITECOMBINE也是给驱动程序开发人员用的。它允许把对单个设备的多次写操作组合在一起,以提高性能。
最后一个保护属性标志PAGE_GUARD,使应用程序能够在页面中的任何一个字节被写入时得到通知。这个标志有一些巧妙的用法。Windows在创建线程栈时会用到它。有关该标志的更多信息,请参阅第16章。
物理存储器的提交与回收
在地址空间中保留一个区域后,并不能直接对其进行使用,必须在把物理存储器提交给该区域后,才可以访问区域中的内存地址。在提交过程中,物理存储器是按页面边界和页面大小的块来进行提交的。若要为一个已保留的地址空间区域提交物理存储器,需要再次调用VirtualAlloc()函数,所不同的是在执行物理存储器的提交过程中需要指定flAllocationType参数为MEM_COMMIT标志,使用的保护属性与保留区域时所用保护属性一致。在提交时,可以将物理存储器提交给整个保留区域,也可以进行部分提交,由VirtualAlloc()函数的lpAddress参数和dwSize参数指明要将物理存储器提交到何处以及要提交多少物理存储器。
与保留区域的释放类似,当不再需要访问保留区域中被提交的物理存储器时,提交的物理存储器应得到及时的释放。该回收过程与保留区域的释放一样也是通过VirtualFree()函数来完成的。在调用时为VirtualFree()的dwFreeType参数指定MEM_DECOMMIT标志,并在参数lpAddress和dwSize中传递用来标识要解除的第一个页面的内存地址和要释放的字节数。此回收过程同样也是以页面为单位来进行的,将回收设定范围所涉及到的所有页面。下面这段代码演示了对先前保留区域的提交过程,并在使用完毕后将其回收:
// 在地址空间中保留一个区域
LPBYTE bBuffer = (LPBYTE)VirtualAlloc(NULL, 65536, MEM_RESERVE, PAGE_READWRITE);
// 提交物理存储器
VirtualAlloc(bBuffer, 65536, MEM_COMMIT, PAGE_READWRITE);
……
// 回收提交的物理存储器
VirtualFree(bBuffer, 65536, MEM_DECOMMIT);
// 释放已保留的区域
VirtualFree(bBuffer, 0, MEM_RELEASE);
由于未经提交的保留区域实际是无法使用的,因此在编程过程中允许通过一次VirtualAlloc()调用而完成对地址空间的区域保留及对保留区域的物理存储器的提交。相应的,回收、释放过程也可由一次VirtualFree()调用来实现。上述代码可按此方法改写为:
// 在地址空间中保留一个区域并提交物理存储器
LPBYTE bBuffer = (LPBYTE)VirtualAlloc(NULL, 65536, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
……
// 释放已保留的区域并回收提交的物理存储器
VirtualFree(bBuffer, 0, MEM_RELEASE | MEM_DECOMMIT);
页文件的使用
在前面曾多次提到物理存储器,这里所说的物理存储器并不局限于计算机内存,还包括在磁盘空间上创建的页文件,其存储空间大小为计算机内存和页文件存储容量之和。由于通常情况下磁盘存储空间要远大于内存的存储空间,因此页文件的使用对于应用程序而言相当于透明的增加了其所能使用的内存容量。在使用时,由操作系统和CPU负责对页文件进行维护和协调。只有在应用程序需要时才临时将页文件中的数据加载到内存供应用程序访问之用,在使用完毕后再从内存交换回页文件。
进程中的线程在访问位于已提交物理存储器的保留区域的内存地址时,如果此地址指向的数据当前已存在于内存,CPU将直接将进程的虚拟地址映射为物理地址,并完成对数据的访问;如果此数据是存在于页文件中的,就要试图将此数据从页文件加载到内存。在进行此处理时,首先要检查内存中是否有可供使用的空闲页面,如果有就可以直接将数据加载到内存中的空闲页面,否则就要从内存中寻找一个暂不使用的可释放的页面并将数据加载到此页面。如果被释放页面中的数据仍为有效数据(即以后还会用到),就要先将此页面从内存写入到页文件。在数据加载到内存后,仍要在CPU将虚拟地址映射为物理地址后方可实现对数据的访问。与对物理存储器中数据的访问有所不同,在运行可执行程序时并不进行程序代码和数据的从磁盘文件到页文件的复制过程,而是在确定了程序的代码及其数据的大小后,由系统直接将可执行程序的映像用作程序的保留地址空间区域。这样的处理方式大大缩短了程序的启动时间,并可减小页文件的尺寸。

上面提到的“数据是否在内存中”,我认为应该是判断系统缓存中是否有需要的页面。
==========================================================================================
对内存的管理
使用虚拟内存技术将能够对内存进行管理。对当前内存状态的动态信息可通过GlobalMemoryStatus()函数来获取。GlobalMemoryStatus()的函数原型为:
VOID GlobalMemoryStatus(LPMEMORYSTATUS lpBuffer);
其参数lpBuffer为一个指向内存状态结构MEMORYSTATUS的指针,而且要预先对该结构对象的数据成员进行初始化。MEMORYSTATUS结构定义如下:
typedef struct _MEMORYSTATUS {
DWORD dwLength; // MEMORYSTATUS结构大小
DWORD dwMemoryLoad; // 已使用内存所占的百分比
DWORD dwTotalPhys; // 物理存储器的总字节数
DWORD dwAvailPhys; // 空闲物理存储器的字节数
DWORD dwTotalPageFile; // 页文件包含的最大字节数
DWORD dwAvailPageFile; // 页文件可用字节数
DWORD dwTotalVirtual; // 用户模式分区大小
DWORD dwAvailVirtual; // 用户模式分区中空闲内存大小
} MEMORYSTATUS, *LPMEMORYSTATUS;
下面这段代码通过设置一个定时器而每隔5秒更新一次当前系统对内存的使用情况:
// 设置定时器
SetTimer(0, 5000, NULL);
……
void CSample22Dlg::OnTimer(UINT nIDEvent)
{
// 获取当前内存使用状态
MEMORYSTATUS mst;
GlobalMemoryStatus(&mst);
// 已使用内存所占的百分比
m_dwMemoryLoad = mst.dwMemoryLoad;
// 物理存储器的总字节数
m_dwAvailPhys = mst.dwAvailPhys / 1024;
// 空闲物理存储器的字节数
m_dwAvailPageFile = mst.dwAvailPageFile / 1024;
// 页文件包含的最大字节数
m_dwAvailVirtual = mst.dwAvailVirtual / 1024;
// 页文件可用字节数
m_dwTotalPageFile = mst.dwTotalPageFile / 1024;
// 用户模式分区大小
m_dwTotalPhys = mst.dwTotalPhys / 1024;
// 用户模式分区中空闲内存大小
m_dwTotalVirtual = mst.dwTotalVirtual / 1024;
// 更新显示
UpdateData(FALSE);
CDialog::OnTimer(nIDEvent);
}
对内存的管理除了对当前内存的使用状态信息进行获取外,还经常需要获取有关进程的虚拟地址空间的状态信息。可由VirtualQuery()函数来进行查询,其原型声明如下:
DWORD VirtualQuery(
LPCVOID lpAddress, // 内存地址
PMEMORY_BASIC_INFORMATION lpBuffer, // 指向内存信息结构的指针
DWORD dwLength // 内存的大小
);
其中lpAddress参数为要查询的虚拟内存地址,该值将被调整到最近的页边界处。当前计算机的页面大小可通过GetSystemInfo()函数获取,该函数需要一个指向SYSTEM_INFO结构的指针作为参数,获取到的系统信息将填充在该数据结构对象中。下面这段代码通过对GetSystemInfo()的调用而获取了当前的系统信息:
// 得到当前系统信息
GetSystemInfo(&m_sin);
// 位屏蔽,指明哪个CPU是活动的
m_dwActiveProcessorMask = m_sin.dwActiveProcessorMask;
// 保留的地址空间区域的分配粒度
m_dwAllocationGranularity = m_sin.dwAllocationGranularity;
// 进程的可用地址空间的最小内存地址
m_dwMaxApplicationAddress = (DWORD)m_sin.lpMaximumApplicationAddress;
// 进程的可用地址空间的最大内存地址
m_dwMinApplicationAddress = (DWORD)m_sin.lpMinimumApplicationAddress;
// 计算机中CPU的数目
m_dwNumberOfProcessors = m_sin.dwNumberOfProcessors;
// 页面大小
m_dwPageSize = m_sin.dwPageSize;
// 处理器类型
m_dwProcessorType = m_sin.dwProcessorType;
//进一步细分处理器级别
m_wProcessorLevel = m_sin.wProcessorLevel;
// 系统处理器的结构
m_wProcessorArchitecture = m_sin.wProcessorArchitecture;
// 更新显示
UpdateData(FALSE);
VirtualQuery()的第二个参数lpBuffer为一个指向MEMORY_BASIC_INFORMATION结构的指针。VirtualQuery()如成功执行,该结构对象中将保存查询到的虚拟地址空间状态信息。MEMORY_BASIC_INFORMATION结构的定义为:
typedef struct _MEMORY_BASIC_INFORMATION {
PVOID BaseAddress; // 保留区域的基地址
PVOID AllocationBase; // 分配的基地址
DWORD AllocationProtect; // 初次保留时所设置的保护属性
DWORD RegionSize; // 区域大小
DWORD State; // 状态(提交、保留或空闲)
DWORD Protect; // 当前访问保护属性
DWORD Type; // 页面类型
} MEMORY_BASIC_INFORMATION;
通过VirtualQuery()函数对由lpAddress和dwLength参数指定的虚拟地址空间区域的查询而获取得到的相关状态信息:
// 更新显示
UpdateData(TRUE);
// 虚拟地址空间状态结构
MEMORY_BASIC_INFORMATION mbi;
// 查询指定虚拟地址空间的状态信息
VirtualQuery((LPCVOID)m_dwAddress, &mbi, 1024);
// 保留区域的基地址
m_dwBaseAddress = (DWORD)mbi.BaseAddress;
// 分配的基地址
m_dwAllocateBase = (DWORD)mbi.AllocationBase;
// 初次保留时所设置的保护属性
m_dwAllocateProtect = mbi.AllocationProtect;
// 区域大小
m_dwRegionSize = mbi.RegionSize;
// 状态(提交、保留或空闲)
m_dwState = mbi.State;
// 当前访问保护属性
m_dwProtect = mbi.Protect;
// 页面类型
m_dwType = mbi.Type;
// 更新显示
UpdateData(FALSE);
小结
本文主要对内存管理中的虚拟内存技术的基本原理、使用方法和对内存的管理等进行了介绍。通过本文将能够掌握虚拟内存的一般使用方法,与之相关的内存管理技术还包括内存文件映射和堆管理等技术,读者可参阅相关文章。这几种内存管理技术同属Windows编程中的高级技术,在应用程序中适当使用将有助于程序性能的提高。本文所述程序在Windows 2000 Professional下由Microsoft Viusual C++ 6.0编译通过。
进程的虚拟地址空间
每个进程都被赋予它自己的虚拟地址空间。对于3 2位进程来说,这个地址空间是4 G B,因为3 2位指针可以拥有从0 x 0 0 0 0 0 0 0 0至0 x F F F F F F F F之间的任何一个值。这使得一个指针能够拥有4 294 967 296个值中的一个值,它覆盖了一个进程的4 G B虚拟空间的范围。对于6 4位进程来说,这个地址空间是1 6 E B(1 01 8字节),因为6 4位指针可以拥有从0 x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0至0 x F F F F F F F F F F F F F F F F之间的任何值。这使得一个指针可以拥有18 446 744 073 709 551 616个值中的一个值,它覆盖了一个进程的1 6 E B虚拟空间的范围。这是相当大的一个范围。
由于每个进程可以接收它自己的私有的地址空间,因此当进程中的一个线程正在运行时,该线程可以访问只属于它的进程的内存。属于所有其他进程的内存则隐藏着,并且不能被正在运行的线程访问。
注意在Windows 2000中,属于操作系统本身的内存也是隐藏的,正在运行的线程无法访问。这意味着线程常常不能访问操作系统的数据。Windows 98中,属于操作系统的内存是不隐藏的,正在运行的线程可以访问。因此,正在运行的线程常常可以访问操作系统的数据,也可以破坏操作系统(从而有可能导致操作系统崩溃)。在Windows 98中,一个进程的线程不可能访问属于另一个进程的内存。
前面说过,每个进程有它自己的私有地址空间。进程A可能有一个存放在它的地址空间中的数据结构,地址是0 x 1 2 3 4 5 6 7 8,而进程B则有一个完全不同的数据结构存放在它的地址空间中,地址是0 x 1 2 3 4 5 6 7 8。当进程A中运行的线程访问地址为0 x 1 2 3 4 5 6 7 8的内存时,这些线程访问的是进程A的数据结构。当进程B中运行的线程访问地址为0 x 1 2 3 4 5 6 7 8的内存时,这些线程访问的是进程B的数据结构。进程A中运行的线程不能访问进程B的地址空间中的数据结构。反之亦然。
当你因为拥有如此大的地址空间可以用于应用程序而兴高采烈之前,记住,这是个虚拟地址空间,不是物理地址空间。该地址空间只是内存地址的一个范围。在你能够成功地访问数据而不会出现违规访问之前,必须赋予物理存储器,或者将物理存储器映射到各个部分的地址空间。本章后面将要具体介绍这是如何操作的。
虚拟地址空间如何分区
每个进程的虚拟地址空间都要划分成各个分区。地址空间的分区是根据操作系统的基本实现方法来进行的。不同的Wi n d o w s内核,其分区也略有不同。表 1显示了每种平台是如何对进程的地址空间进行分区的。
表1 进程的地址空间如何分区
分区 | 32位Windows 2000(x86和Alpha处理器) | 32位Windows 2000(x86w/3GB用户方式) | 64位Windows 2000(Alpha和IA-64处理器) | Windows 98 |
N U L L指针分配的分区 | 0 x 0 0 0 0 0 0 0 0 ——0x 0 0 0 0 F F F F | 0 x 0 0 0 0 0 0 0 0 0 x 0 0 0 0 F F F F | 0x00000000 00000000 0x00000000 0000FFFF | 0 x 0 0 0 0 0 0 0 0 0 x 0 0 0 0 0 F F F |
DOS/16位Windows应用程序兼容分区 | 无 | 无 | 无 | 0 x 0 0 0 0 0 1 0 0 0 0 x 0 0 3 F F F F F |
用户方式 | 0 x 0 0 0 1 0 0 0 0—— 0 x 7 F F E F F F F<将近2G> | 0 x 0 0 0 1 0 0 0 0 0 x B F F E F F F F F | 0x00000000 00010000 0x000003FF FFFEFFFF | 0 x 0 0 4 0 0 0 0 0 0 x 7 F F F F F F F |
64-KB禁止进入分区 | 0 x 7 F F F 0 0 0 0——0x7FFF FFFF | 0 x B F F F 0 0 0 0——0 x B F F F F F F F | 0 x 0 0 0 0 0 3 F F F F F F 0 0 0 0——0 x 0 0 0 0 0 3 F F F F F F F F F F | 无 |
共享内存映射 | 无 | 无 | 无 | 0 x 8 0 0 0 0 0 0 0 |
文件(MMF)内核方式 | 0 x 8 0 0 0 0 0 0 0 —— 0 x F F F F F F F F<共2G> | 0 x C 0 0 0 0 0 0 0 0 x F F F F F F F F | 0x00000400 00000000 0xFFFFFFFFF FFFFFFF | 0 x B F F F F F F F 0 x C 0 0 0 0 0 0 0 0 x F F F F F F F F |
1. NULL指针分区是NULL指针的地址范围。
对这个区域的读写企图都将引发访问违规。
2. DOS/WIN16分区是98中专门用于16位的
DOS和windows程序运行的空间,所有的16
位程序将共享这个4M的空间。Win2000中不
存在这个分区,16位程序也会拥有自己独立的虚拟地址空间。有的文章中称win2000中不能运行16位程序,是不确切的。
3.用户分区是进程的私有领域,Win2000中,程序的可执行代码和其它用户模块均加载在这里,内存映射文件也会加载在这里。Win98中的系统共享DLL和内存映射文件则加载在共享分区中。
4.禁止访问分区只有在win2000中有。这个分区是用户分区和内核分区之间的一个隔离带,目的是为了防止用户程序违规访问内核分区。
5. MMF分区只有win98中有,所有的内存映射文件和系统共享DLL将加载在这个地址。而2000中则将其加载到用户分区。
6. 内核方式分区对用户的程序来说是禁止访问的,操作系统的代码在此。内核对象也驻留在此。
另外要说明的是,win98中对于内核分区本也应该提供保护的,但遗憾的是并没有做到,因而98中程序可以访问内核分区的地址空间。
对于用户分区,又可以细分成若干区域。(这些区域具体会在第四阶段详细剖析。因为这部分内容牵扯到PE文件结构,只有学习并理解了PE文件结构后,才能理解这部分内容,为了便于后面的讲解,在此讲这部分区域先大致分为4块:)
3 2位Windows 2000的内核与6 4位Windows 2000的内核拥有大体相同的分区,差别在于分区的大小和位置有所不同。另一方面,可以看到Windows 98下的分区有着很大的不同。下面让我们看一下系统是如何使用每一个分区的。
NULL指针分配的分区—适用于Windows 2000和Windows 98
进程地址空间的这个分区的设置是为了帮助程序员掌握N U L L指针的分配情况。如果你的进程中的线程试图读取该分区的地址空间的数据,或者将数据写入该分区的地址空间,那么C P U就会引发一个访问违规。保护这个分区是极其有用的,它可以帮助你发现N U L L指针的分配情况。
C / C + +程序中常常不进行严格的错误检查。例如,下面这个代码就没有进行任何错误检查:
int* pnSomeInteger = (int*) malloc(sizeof(int));
*pnSomeInteger = 5;
如果m a l l o c不能找到足够的内存来满足需要,它就返回N U L L。但是,该代码并不检查这种可能性,它认为地址的分配已经取得成功,并且开始访问0 x 0 0 0 0 0 0 0 0地址的内存。由于这个分区的地址空间是禁止进入的,因此就会发生内存访问违规现象,同时该进程将终止运行。这个特性有助于编程员发现应用程序中的错误。
用户方式分区—适用于Windows 2000和Windows 98
这个分区是进程的私有(非共享)地址空间所在的地方。一个进程不能读取、写入、或者以任何方式访问驻留在该分区中的另一个进程的数据。对于所有应用程序来说,该分区是维护进程的大部分数据的地方。由于每个进程可以得到它自己的私有的、非共享分区,以便存放它的数据,因此,应用程序不太可能被其他应用程序所破坏,这使得整个系统更加健壮。
在Windows 2000中,所有的. e x e和D L L模块均加载这个分区。每个进程可以将这些D L L加载到该分区的不同地址中(不过这种可能性很小)。系统还可以在这个分区中映射该进程可以访问的所有内存映射文件
共享的MMF分区—仅适用于Windows 98
这个1 G B分区是系统用来存放所有3 2位进程共享数据的地方。例如,系统的动态链接库K e r n e l 3 2 . d l l、A d v A P I 3 2 . d l l、U s e r 3 2 . d l l和G D I 3 2 . d l l等,全部存放在这个地址空间分区中,因此,所有3 2位进程都能很容易同时访问它们。系统还为每个进程将D L L加载相同的内存地址。此外,系统将所有内存映射文件映射到这个分区中。
物理存储器与页文件
在较老的操作系统中,物理存储器被视为计算机拥有的R A M的容量。换句话说,如果计算机拥有1 6 M B的R A M,那么加载和运行的应用程序最多可以使用1 6 M B的R A M。今天的操作系统能够使得磁盘空间看上去就像内存一样。磁盘上的文件通常称为页文件,它包含了可供所有进程使用的虚拟内存
当然,若要使虚拟内存能够运行,需要得到C P U本身的大量帮助。当一个线程试图访问一个字节的内存时, C P U必须知道这个字节是在R A M中还是在磁盘上。
从应用程序的角度来看,页文件透明地增加了应用程序能够使用的R A M(即内存)的数量。如果计算机拥有6 4 M B的R A M,同时在硬盘上有一个100 MB的页文件,那么运行的应用程序就认为计算机总共拥有1 6 4 M B的R A M。
实际上并不拥有1 6 4 M B的R A M。相反,操作系统与C P U相协调,共同将R A M的各个部分保存到页文件中,当运行的应用程序需要时,再将页文件的各个部分重新加载到R A M。由于页文件增加了应用程序可以使用的R A M的容量,因此页文件的使用是视情况而定的。如果没有页文件,那么系统就认为只有较少的R A M可供应用程序使用。但是,我们鼓励用户使用页文件,这样他们就能够运行更多的应用程序,并且这些应用程序能够对更大的数据集进行操作。最好将物理存储器视为存储在磁盘驱动器(通常是硬盘驱动器)上的页文件中的数据。这样,当一个应用程序通过调用Vi r t u a l A l l o c函数,将物理存储器提交给地址空间的一个区域时,地址空间实际上是从硬盘上的一个文件中进行分配的。系统的页文件的大小是确定有多少物理存储器可供应用程序使用时应该考虑的最重要的因素, R A M的容量则影响非常小。
第一种情况中,线程试图访问的数据是在R A M中。在这种情况下, C P U将数据的虚拟内存地址映射到内存的物理地址中,然后执行需要的访问。线程试图访问的数据不在R A M中,而是存放在页文件中的某个地方。这时,试图访问就称为页面失效, C P U将把试图进行的访问通知操作系统。这时操作系统就寻找R A M中的一个内存空页。如果找不到空页,系统必须释放一个空页。如果一个页面尚未被修改,系统就可以释放该页面。但是,如果系统需要释放一个已经修改的页面,那么它必须首先将该页面从R A M拷贝到页交换文件中,然后系统进入该页文件,找出需要访问的数据块,并将数据加载到空闲的内存页面。然后,操作系统更新它的用于指明数据的虚拟内存地址现在已经映射到R A M中的相应的物理存储器地址中的表。这时C P U重新运行生成初始页面失效的指令,但是这次C P U能够将虚拟内存地址映射到一个物理R A M地址,并访问该数据块。
当阅读了上一节后,你必定会认为,如果同时运行许多文件的话,页文件就可能变得非常大,而且你会认为,每当你运行一个程序时,系统必须为进程的代码和数据保留地址空间的一些区域,将物理存储器提交给这些区域,然后将代码和数据从硬盘上的程序文件拷贝到页文件中已提交的物理存储器中。
实际上系统并不进行上面所说的这些操作。如果它进行这些操作的话,就要花费很长的时间来加载程序并启动它运行。相反,当启动一个应用程序的时候,系统将打开该应用程序的. e x e文件,确定该应用程序的代码和数据的大小。然后系统要保留一个地址空间的区域,并指明与该区域相关联的物理存储器是在. e x e文件本身中。即系统并不是从页文件中分配地址空间,而是将. e x e文件的实际内容即映像用作程序的保留地址空间区域。当然,这使应用程序的加载非常迅速,并使页文件能够保持得非常小
一、开始之前,让我们来了解一下Windows中内存管理的一些知识:
1. 机器的物理内存由两部分组成。一部分为机器的主存RAM,也就是我们内存条的大小;另一部分为虚拟内存,它就在机器的硬盘上,以页文件的形式存在。
2. 每个进程都有自己的虚拟地址空间,对于具有32位寻址能力的机器来说,这个虚拟空间的大小为4GB。现在我们使用的机器就是4GB。
3. 进程的4GB虚拟地址空间又可以分成几个部分,其中进程真正私有的空间少于2GB(这段地址空间被称作“用户方式分区”),其余的2GB多空间都是给操作系统的,且这部分空间被所有的进程共享。(参考Windows核心编程Chapter 13)
4. 为进程“分配内存”,这个概念可以细化:“保留一段地址空间”,“提交一段内存空间”,“将内存空间映射到主存”。在程序中我们通常所访问的地址都必须是进程地址空间中被保留和提交的那段地址空间。
4.1 “保留一段地址空间”:即从进程的4GB地址空间中保留一段地址空间,这个过程通过VirtualAlloc函数完成,并把分配类型参数设置为MEM_RESERVE。这段空间的起始地址必须是系统分配粒度的整数倍,大小必须是系统页面大小的整数倍。
4.2 “提交一段内存空间”:即为进程已保留的地址空间映射机器的物理内存,这里要特别注意,所谓物理内存一般并不是机器的主存,而只是机器的虚拟内存。这个过程同样又VirtualAlloc完成,只是把分配类型参数设置为MEM_COMMIT。这段空间的起始地址和大小都必须是页面大小的整数倍。这样进程的对应被提交的区域就被映射到机器的虚拟内存上。
4.3 “将内存空间映射到主存”:这点很重要,操作系统总是只有在进程提交的页面被访问时才将相应的页面加载到主存中,同时修改进程对应页面的地址空间映射。这时,进程的地址空间中的对应区域才和机器上的主存对应起来。
Virtual Size:
该指标记录了当前进程申请成功的其虚拟地址空间的总的空间大小,包括DLL/EXE占用的地址和通过VirtualAlloc API Reserve的Memory Space数量。请注意,该指标包括保留的地址空间。
Private Bytes:
该指标记录了进程用户方式分区地址空间中已提交的总的空间大小。无论是直接调用API申请的内存,被Heap Manager申请的内存,或者是CLR 的managed heap,都算在里面。
Working Set:
该指标记录了所有映射到进程虚拟地址空间的机器主存的大小,它不仅仅是用户方式分区部分的映射,而是整个进程地址空间的映射。即它同时包括内核方式分区中映射到机器主存的部分。由4.3可知,在用户方式分区部分只有在进程提交的页面被访问时才将相应的页面加载到主存中。而对于该部分的大小总是系统页面大小的整数倍。
这里有一个问题,随着进程的不断运行,进程被访问的页面将可能不断增加,这是否意味着“Working Set”的大小会不断的累加呢?显然不是。在程序运行过程中影响“Working Set”的因素包括:(1) 机器可用主存的大小 (2) 进程本身“Working Set”的大小范围。当机器的可用主存小于一定值时,系统会释放一些老的最近没有被访问的页面,把这些页面通过交换文件交换到机器的虚拟内存中;当Working Set的大小大于该进程所设置的最大值时,同样会把一些老的页面交换到机器的虚拟内存中。当这些页面下次再被访问时,它们才加载到主存。
由上可知,”Working Set“一定比”Private Bytes“小,因为它只是”Private Bytes“对应的地址空间中被加载到主存的那部分。
“Page Faults”
该指标和”Working Set“密切相关,当进程访问某个页面,而这个页面却不在主存中时,就要发生一次“Page Fault“,即进程访问非”Working Set“中的页面时,发生一次”Page Fault“,同时系统将对应页面加载到主存中。
接下来的三个指标是对”Working Set“的细化:
”WS Private“
该指标记录了进程”Working Set“中被该进程所独享的空间大小。
"WS Shareable"
该指标记录了进程”Working Set“中能与别的进程共享的空间大小
”WS Shared“
该指标记录了进程”Working Set“中已经与别的进程共享的空间大小
”WS Shareable“和”WS Shared“两个指标乍一看令人感到疑惑,因为既然”Working Set“属于”Private Bytes“中的一部分,而”Private Bytes“是进程私有的,为什么会有”WS Shareable“和”WS Shared“这两项呢?
认真一想,其实很容易理解,比如两个进程都需要同一个DLL的支持,所以在进程运行过程中,这个DLL被映射到了两个进程的地址空间中,如果这个DLL的大小为4K,在两个进程中都要提交4K的虚拟地址空间来映射这个DLL。当第一个进程访问了这个DLL时,这个DLL被加载到机器主存中,这时,第二个进程也要访问该DLL,这时,系统就不会再加载一遍该DLL了,因为这个DLL已经在主存中了。当然上面所说的访问仅仅是读取的操作,如果这时候某个进程要修改DLL对应这段地址中的某个单元时,这时,系统必须为第二个进程分配另外的新页面,并把要修改位置对应的页面拷贝的这个新页面,同时,第二个进程中的这个DLL被映射到这个新页面上。
上面的分析中,DLL对应的4K的内存在第一个进程中便是”WS Shareable“。另外,内核方式分区中的所有代码都是被所有进程共享的,只要一个进程访问了这些页面,则在所有的进程的”Working Set“中都能体现。
三、下面我们来讨论一下这些内存指标与进程内存消耗之间的关系
在计算机更新换代不断加速的今天,我们往往很少关注程序对内存的消耗,除非程序的内存消耗超出了我们的忍受范围——大量的泄漏、运行速度下降等。
那么,当我们在测进程的内存使用量时,到底应该使用哪个指标能更好的反应程序的内存消耗呢?由于Windows自带的Task Manager中的”Memory Usage“所对应的指标就是”Working Set“,所以大部分人认为该指标能够很好的反应进程的内存使用量。
在得出结论之前,让我们来分析一下以上的这些指标:
就从”Working Set“开始吧。
”Working Set“:
进程中被加载到机器主存的所有页面大小的和。它可细分为”WS Shareable“和”WS Shared“。进程访问页面不再”Working Set“中时,会发生一次”Page Fault“且同时发生一次主存与虚拟内存之间的数据交换。综上所述,我们可以得出结论:
(a)”Working Set“不是进程内存消耗的全部;
(b)所有进程”Working Set“的和也不等有机器主存总的消耗量,因为存在”Working Shareable“与别的进程共享;
(c)”Working Set“太大会影响机器的运行速度,因为”Working Set“太大会导致机器的可用主存太少,从而导致将进程的老页面释放到虚拟内存,同时,进程”Working Set“中的页面减少后,使进程发生”Page Fault“的频率更高。因为在主存与虚拟内存之间交换数据需要时间,所以机器的运行速度要减慢。
(d)”Working Set“由于数据交换的存在,该指标是动态的,在测量的过程中会不断变化。(变化的最小单位为4K)
所以”Working Set“指标强调的是进程对机器主存的消耗,不是进程内存的全部信息。
"Private Bytes"
该指标包含所有为进程提交的内存,包括机器主存和虚拟内存,可以认为它是进程对物理内存消耗,且该指标相对来说更加稳定。在程序产生内存泄漏时,该值一定是不断上涨的。
综上所述,个人更倾向于使用”Private Bytes“来定量进程的内存消耗和分析进程的内存泄漏。
==============================================================================================================================================================================================================================
HeapCreate
这个函数创建一个只有调用进程才能访问的私有堆。进程从虚拟地址空间里保留出一个连续的块并且为这个块特定的初始部分分配物理空间。
HANDLE HeapCreate(DWORD flOptions , DWORD dwInitialSize , DWORD dwMaxmumSize);
参数:
flOptions:堆的可选属性。这些标记影响以后对这个堆的函数操作,函数有:HeapAlloc , HeapFree , HeapReAlloc , HeapSize .
下面给_出在此可以指定的标记:
HEAP_NO_SERIALIAZE:指定当函数从堆里分配和释放空间时不互斥(不使用互斥锁)。当不指定该标记时默认为使用互斥。序列化允许多个线程操作同一个堆而不会错误。这个标记是可忽略的。
HEAP_SHARED_READONLY:这个标记指定这个堆只能由创建它的进程进行写操作,对其他进程是只读的。如果调用者不是可靠的,调用将会失败,错误代码ERROR_ACCESS_DENIDE 。
注解:为了使用标记为HEAP_SHARED_READONLY的堆,运行在kernel mode(核心状态)是必须的。
dwInitialSize:堆的初始大小,单位为Bytes。这个值决定了分配给堆的初始物理空间大小。这个值将向上舍入知道下个page boundary(页界)。若需得到主机的页大小,使用GetSystemInfo 函数。
dwMaxmumSize:如果该参数是一个非零的值,它指定了这个堆的最大大小,单位为Bytes。该函数会向上舍入该值直到下个页界,然后为这个堆在进程的虚拟地址里保留舍入后大小的块。如果函数 HeapAlloc 和 HeapReAlloc 要求分配的空间超过参数 dwInitialSize 指定的大小,系统会分配额外的空间给该堆直到这个堆的最大大小。If dwMaximumSize is nonzero, the heap cannot grow and an absolute limitation arises where all allocations are fulfilled within the specified heap unless there is not enough free space. (如果该参数非零,除非没有足够的空间,这个堆总可以增长到该大小)。如果该参数为零,那么该堆大小的唯一限制是可用的内存空间。分配大小超过 0x0018000 Bytes的空间总会失败,因为获得这么大的空间需要系统调用 VirtualAlloc 函数。需要使用大空间的应用应该把该参数设置为零。
返回值:
成功:一个指向新创建的堆的指针。
失败:NULL
调用函数 GetLastError 获得更多的错误信息。
附注:
这个函数在调用进程里创建一个私有堆,进程可调用 HeapAlloc 函数分配内存空间。这些页在进程的虚拟空间内创建了一个块,在那里堆可以增长。
如果 HeapAlloc 函数请求的空间超过了现有的页大小,如果物理空间足够的话,额外的空间将会从已保留的空间里附加。
只有创建私有堆的进程可以访问私有堆。
如果一个DLL(动态链接库)创建了一个私有堆,那么这么私有堆是在调用该DLL的进程的地址空间内,且仅该进程可访问。
系统会使用私有堆的一部分空间去储存堆的结构信息,所以,不是所有的堆内空间对进程来说是可用的。例如:HeapAlloc函数从一个最大大小为 64KB 的堆里申请 64KB 的空间,由于系统占用的一部分空间,这个请求通常会失败。
要求:
系统版本:WinCE 1.0 以上。
头文件:Winbase.h
链接库:Coredll.lib
================================================================================================================================================================================================================================================================================================================
/*
* 创建指定大小的堆
*判断当前进程堆的个数
*在指定的堆上分配内存
*获取 堆分配的内存块的大小
* 释放堆分配的内存
*销毁HeapCreate 创建的堆
*/
#include<windows.h>
#include<iostream>
using namespace std;
void main()
{
//定义变量
HANDLE hHeap; //堆句柄
SYSTEM_INFO si; //定义结构
DWORD dwHeapNumber; //堆的数量
HANDLE hHeaps[24]; //堆句柄数组,
LPVOID lpMemory; //指向堆分配的内存
size_t dwHeapSize; //分配的内存字节数
BOOL flag; // 标志
//1 获取系统信息
GetSystemInfo(&si);
//2 创建一个指定大小的堆
hHeap=HeapCreate(
HEAP_NO_SERIALIZE, //堆属性
si.dwPageSize*4 , //初始化字节数,上舍人页大小的整数倍。The value is rounded up to the next page boundary.
si.dwPageSize*8); //最大分配字节数,页大小的整数倍 未0则自动增长 直到内存耗完
//判断创建是否成功
if(hHeap==NULL)
{
cout<<"create heap fail,code is : "<<GetLastError()<<endl;
return;
}
//3 判断当前进程堆的个数
dwHeapNumber=GetProcessHeaps(
24,
hHeaps);
//4 在指定的堆上分配内存
lpMemory=HeapAlloc(
hHeap,
HEAP_ZERO_MEMORY,
si.dwPageSize*2); //分配内存大小,in byte
//判断是否成功
if(lpMemory==NULL)
{
cout<<"allocate memory fail,code is : "<<GetLastError()<<endl;
return;
}
//5 获取 hHeap堆分配的 lpMemory指向的内存块的大小
dwHeapSize=HeapSize(
hHeap, //堆句柄
HEAP_NO_SERIALIZE,
lpMemory); //堆上分配内存指针
Sleep(10);
//6 释放堆分配的内存
flag=HeapFree(
hHeap,
HEAP_NO_SERIALIZE,
lpMemory);
if(flag==NULL)
{
cout<<"free memory fail,code is : "<<GetLastError()<<endl;
return;
}
Sleep(10);
//7 销毁HeapCreate 创建的堆
flag=HeapDestroy(hHeap);
if(flag==NULL)
{
cout<<"destroy heap fail,code is : "<<GetLastError()<<endl;
return;
}
}
================================================================================================================================================================================================================================================================================================================
关于堆分配的几个函数:
(1)GetProcessHeap
用以获取和调用进程的堆句柄.
(2).HeapAlloc
HeapAlloc是一个Windows API函数。它用来在指定的堆上分配内存,并且分配后的内存不可移动。
|
值
|
意义
|
|---|---|
|
HEAP_GENERATE_EXCEPTIONS
|
如果分配错误将会抛出异常,而不是返回NULL。异常值可能是STATUS_NO_MEMORY, 表示获得的内存容量不足,或是STATUS_ACCESS_VIOLATION,表示存取不合法。
|
|
HEAP_NO_SERIALIZE
|
不使用连续存取。
|
|
HEAP_ZERO_MEMORY
|
将分配的内存全部清零。
|
返回值:HEAP_GENERATE_EXCEPTIONS,则返回NULL。
|
异常代码
|
描述
|
|---|---|
|
STATUS_NO_MEMORY
|
由于缺少可用内存或者是堆损坏导致分配失败。
|
|
STATUS_ACCESS_VIOLATION
|
|
如果分配内存失败,并且没有指定
由于堆损坏或者是不正确的函数参数导致分配失败。.
|
(3)HeapCreate
================================================================================================================================================================================================================================================================================================================
很多地方都会使用内存,内存使用过程中操作不当就容易崩溃,无法运行程序,上网Google学习一下,了解整理下他们之间的区别以及使用 ,获益匪浅
0x01 各自的定义和理解
(1)先看GlobalAlloc()
GlobalAlloc()主要用于Win32应用程序实现从全局堆中分配出内存供2017-03-05程序使用,是16位WINDOWS程序使用的API,对应于系统的全局栈,返回一个内存句柄,在实际需要使用时,用GlobalLock()来实际得到内存 区。但32位WINDOWS系统中全局栈和局部堆的区别已经不存在了,因此不推荐在Win32中使用该函数,应使用新的内存分配函数HeapAlloc()以得到更好的支持,GlobalAlloc()还可以用,主要是为了 兼容。
一般情况下我们在编程的时候,给应用程序分配的内存都是可以移动的或者是可以丢弃的,这样能使有限的内存资源充分利用,所以,在某一个时候我们分配的那块 内存的地址是不确定的,因为他是可以移动的,所以得先锁定那块内存块,这儿应用程序需要调用API函数GlobalLock函数来锁定句柄。如下: lpMem=GlobalLock(hMem); 这样应用程序才能存取这块内存。所以我们在使用GlobalAllock时,通常搭配使用GlobalLock,当然在不使用内存时,一定记得使用 GlobalUnlock,否则被锁定的内存块一直不能被其他变量使用。
GlobalAlloc对应的释放空间的函数为GlobalFree。
(2)HeapAlloc()
HeapALloc是从堆上分配一块内存,且分配的内存是不可移动的(即如果没有连续的空间能满足分配的大小,程序不能将其他零散的 空间利用起来,从而导致分配失败),该分配方法是从一指定地址开始分配,而不像GloabalAlloc是从全局堆上分配,这个有可能是全局,也有可能是 局部
(3)malloc()
是C运行库中的动态内存分配函数,主要用于ANSI C程序中,是标准库函数。WINDOWS程序基本不再使用这种方法进行内存操作,因为它比WINDOWS内存分配函数少了一些特性,如整理内存
(4)new
标准C++一般使用new语句分配动态的内存空间,需要申请数组时,可以直接使用new int[3]这样的方式,释放该方法申请的内存空间使用对应的delete语句,需要释放的内存空间为一个数组,则使用delete [] ary;这样的方式。
要访问new所开辟的结构体空间,无法直接通过变量名进行,只能通过赋值的指针进行访问.
new在内部调用malloc来分配内存,delete在内部调用free来释放内存。
(5)
(1) VirtualAlloc 下面是网友的解释 但我个人的理解这个才是内存申请的鼻祖,所有的内存的申请都感觉默认调用了它
PVOID VirtualAlloc(PVOID pvAddress, SIZE_T dwSize, DWORD fdwAllocationType, DWORD fdwProtect)
VirtualAlloc是Windows提供的API,通常用来分配大块的内存。例如如果想在进程A和进程B之间通过共享内存的方式实现通信,可以使用该函数(这也是较常用的情况)。不要用该函数实现通常情况的内存分配。该函数的一个重要特性是可以预定指定地址和大小的虚拟内存空间。例如,希望在进程的地址空间中第50MB的地方分配内存,那么将参数 50*1024*`1024 = 52428800 传递给pvAddress,将需要的内存大小传递给dwSize。如果系统有足够大的闲置区域能满足请求,则系统会将该块区域预订下来并返回预订内存的基地址,否则返回NULL。
使用VirtualAlloc分配的内存需要使用VirtualFree来释放。
0x02 区别与联系
它们之间的区别主要有以下几点:
1、GlobalAlloc()函数在程序的堆中分配一定的内存,是Win16的函数,对应于系统的全局栈,而在Win32中全局栈和局部堆的区别已经不存在了,因此不推荐在Win32中使用该函数。
2、malloc()是标准库函数,而new则是运算符,它们都可以用于申请动态内存。
3、new()实际上调用的是malloc()函数。
4、new运算符除了分配内存,还可以调用构造函数,但是malloc()函数只负责分配内存。
5、对于非内部数据类型的对象而言,只使用malloc()函数将无法满足动态对象的要求,因为malloc()函数不能完成执行构造函数的任务。
6、malloc(); 和 HeapAlloc(); 都是从堆中分配相应的内存,不同的是一个是c run time的函数,一个是windows系统的函数, 对于windows程序来说,使用HeapAlloc();会比malloc();效率稍稍高一些。
0x03关于内存的初始化和使用
1、内存分配方式
内存分配方式有三种:
(1)从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在
。例如全局变量,static变量。
(2)在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存
储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
(3) 从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自
己负责在何时用free或delete释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
2.内存使用错误
发生内存错误是件非常麻烦的事情。编译器不能自动发现这些错误,通常是在程序运行时才能捕捉到。
而这些错误大多没有明显的症状,时隐时现,增加了改错的难度。有时用户怒气冲冲地把你找来,程序却没有
发生任何问题,你一走,错误又发作了。 常见的内存错误及其对策如下:
* 内存分配未成功,却使用了它。
编程新手常犯这种错误,因为他们没有意识到内存分配会不成功。常用解决办法是,在使用内存之前检查
指针是否为NULL。如果是用malloc或new来申请内存,应该用if(p==NULL) 或if(p!=NULL)进行防错处理。
* 内存分配虽然成功,但是尚未初始化就引用它。
犯这种错误主要有两个起因:一是没有初始化的观念;二是误以为内存的缺省初值全为零,导致引用初值
错误(例如数组)。 内存的缺省初值究竟是什么并没有统一的标准,尽管有些时候为零值,我们宁可信其无不
可信其有。所以无论用何种方式创建数组,都别忘了赋初值,即便是赋零值也不可省略,不要嫌麻烦。
* 内存分配成功并且已经初始化,但操作越过了内存的边界。
例如在使用数组时经常发生下标“多1”或者“少1”的操作。特别是在for循环语句中,循环次数很容易搞
错,导致数组操作越界。
* 忘记了释放内存,造成内存泄露。
含有这种错误的函数每被调用一次就丢失一块内存。刚开始时系统的内存充足,你看不到错误。终有一次
程序突然死掉,系统出现提示:内存耗尽。
动态内存的申请与释放必须配对,程序中malloc与free的使用次数一定要相同,否则肯定有错误
(new/delete同理)。
* 释放了内存却继续使用它。
有三种情况:
(1)程序中的对象调用关系过于复杂,实在难以搞清楚某个对象究竟是否已经释放了内存,此时应该重新
设计数据结构,从根本上解决对象管理的混乱局面。
(2)函数的return语句写错了,注意不要返回指向“栈内存”的“指针”或者“引用”,因为该内存在函
数体结束时被自动销毁。
(3)使用free或delete释放了内存后,没有将指针设置为NULL。导致产生“野指针”。
【规则1】用malloc或new申请内存之后,应该立即检查指针值是否为NULL。防止使用指针值为NULL的内存
【规则2】不要忘记为数组和动态内存赋初值。防止将未被初始化的内存作为右值使用。
【规则3】避免数组或指针的下标越界,特别要当心发生“多1”或者“少1”操作。
【规则4】动态内存的申请与释放必须配对,防止内存泄漏。
【规则5】用free或delete释放了内存之后,立即将指针设置为NULL,防止产生“野指针”。















 2928
2928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









