






RPC服务追踪的原理与实践
2017-03-09
文章目录
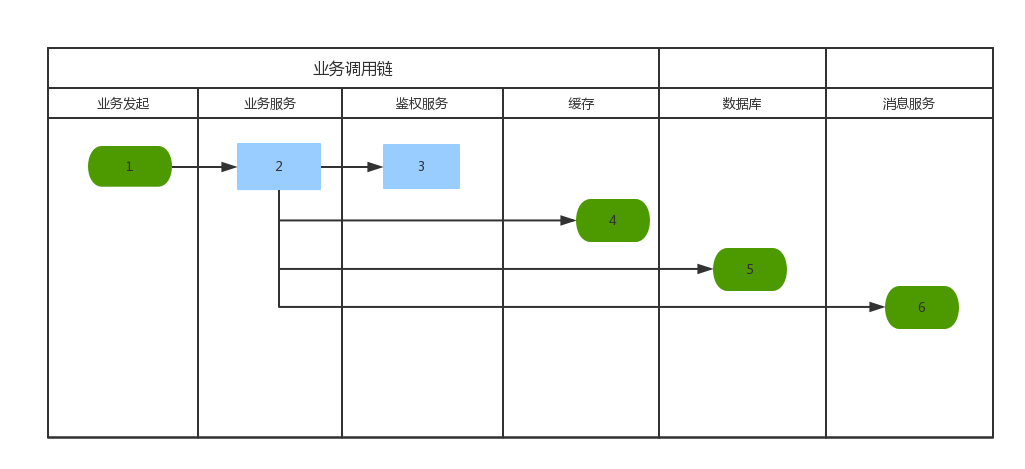
在分布式服务化架构下,由于分布式服务间存在相互依赖,彼此协同来完成各类业务场景。下图是一个典型的业务场景,从前端发起一个请求,到最后的业务完成,需要经过很多环节,这些环节可能都是分布式服务的方式提供,部署在不同的服务器上进行。而在这种复杂的分布式服务场景下,为了定位问题、性能瓶颈查询、异常日志跟踪等,如果没有服务追踪和分析工具的帮助,都是非常困难的。
说到分布式追踪,当然不得不提Google为其基于日志的分布式跟踪系统Dapper发表的[论文],在这边论文里,Google介绍了他们在分布式追踪领域的经验,总体来看其核心概念有三个:
- TraceID:用来标识每一条业务请求链的唯一ID,TraceID需要在整个调用链路上传递**
- Span:请求链中的每一个环节为一个Span,每一个Span有一个SpanId来标识,前后Span间形成父子关系**
- Annotation:业务自定义的埋点信息,可以是sql、用户ID等关键信息**
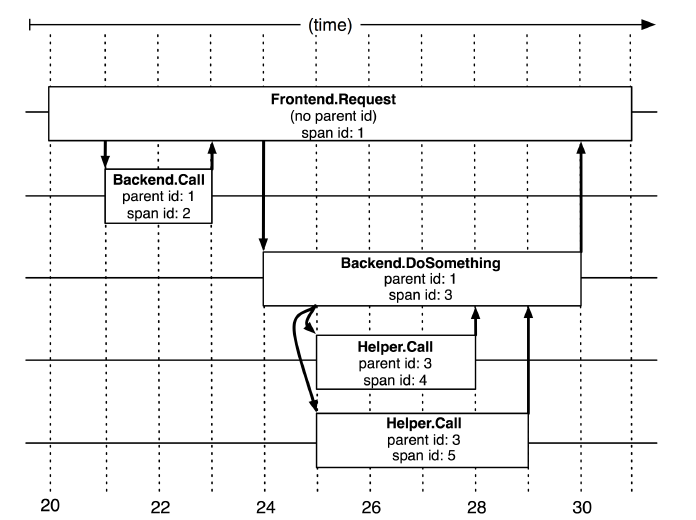 图:5个span在Dapper跟踪树中的关联关系(图来自google论文)
图:5个span在Dapper跟踪树中的关联关系(图来自google论文)
Google论文出来后,业界出现了很多基于其思想实现的开源框架,如Twitter的zipkin,其中zipkin是严格按照来Dapper论文来设计的,他提供了完整的跟踪记录收集、存储功能,以及查询API与界面。其存储支持多种数据库:MySql、ElasticSearch、Cassandra、Redis等等,收集API支持HTTP和Thrift。
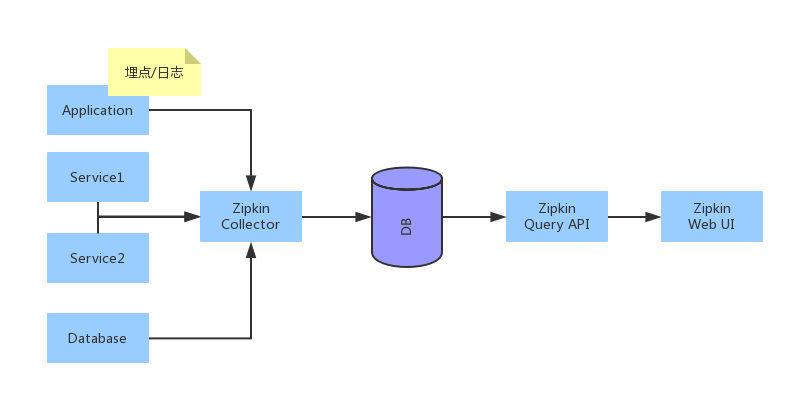
但作为服务跟踪中最难处理的一环,即跟踪埋点,zipkin并没有提供,需要使用方自己实现。业界也有Brave这样的开源项目可以使用,但是评估过后,发现Brave的实现过于复杂,依赖组件也过多,并且其实现的组件更多是支持HTTP服务的调用,对于我们的Thrift RPC服务不能支持,所以没有使用Brave,改为自己实现。自己实现服务埋点和追踪有几个问题需要解决:
TraceID生成
由于要唯一标示每一次调用,所以TraceID需要保证全局唯一。唯一的ID,第一个想到的当然是使用UUID,UUID是一个较为高效又使用方便的唯一ID生成方式,但问题是,zipkin要求TraceID是int64类型,不能是字符串,同时,UUID还有一个问题是不能保证单调有序。对此,有两个架构方案可选:
使用数据库自增长ID来生成,同时需要解决以下问题:
- 性能上,如果每次请求都访问数据库一次,会带来较大的性能损失,所以需要在客户端缓存一个区间的数字,当这个区间的数字不够时再从数据库获取。
- 出于安全要求不能跟数据库直连的客户端不适合,如Web服务器。可以考虑使用一个中间服务作为ID分发。 结合上面两点要求,架构方案如下:
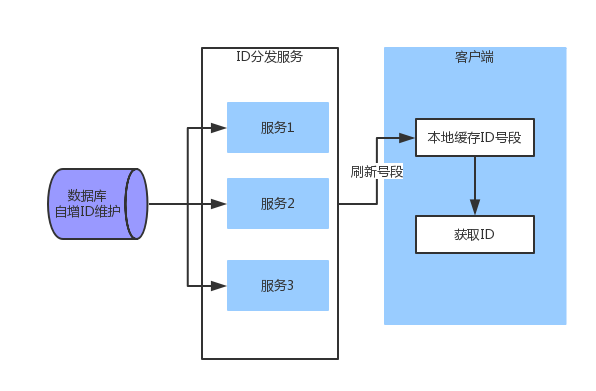
此方案中,ID分发服务的高可用性要求很高,如果该服务出现不可用,将影响到所有服务均不可用,增加了后续运营维护的麻烦。
采用分机器(进程)的方式,保证机器间(进程间)ID不冲突,同时保证单机器(进程)内ID是递增不重复的。这种方式的最大好处时不需要中心化的节点进行ID分发,省掉了系统间的依赖。对于此种方案,最常用的算法是Twitter-Snowflake算法,也是我们最终选择的算法。Snowflake核心思想是将int64的除第一位外的其他63位分成三段,前面41位为时间戳、后面10位为工作机器(进程)ID,也称为WorkerID ,最后12位为递增序列号。
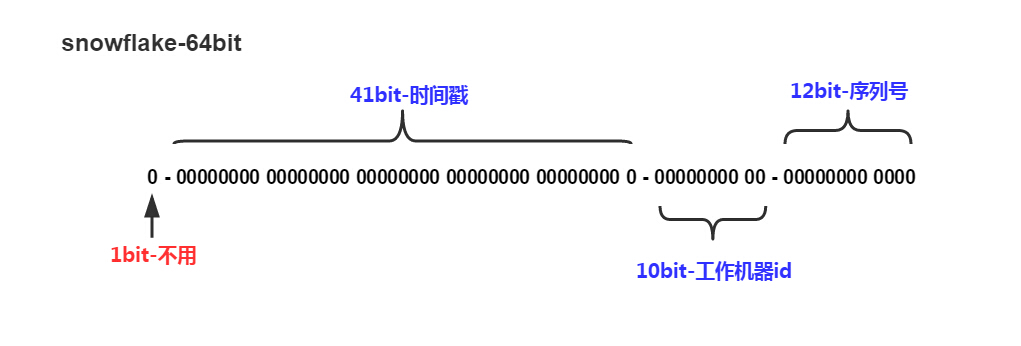
当然,以上长度分段只是默认,可以根据实际情况进行区分,比如41位的时间戳,最长可以用
(-1L ^ -1L<<41)/(3600 * 24 * 365 * 1000)=69年
10位的WorkerID最多支持1023台机器(进程),12位为递增序列表示每毫秒最多4095个ID,在实际中,我们为了支持更多的机器(进程),采取了16位WorkerID,4位标识序列号,即最多支持65535台机器(进程),每毫秒最多生成15个ID。该方案中,WrokerID的分配是需要特别注意的,WorkerID应该每个进程唯一,不能相同,如果相同的话就会出现低概率的ID重复。
分配WorkerID最简单的办法是采取配置的方式,将WorkerID配置到程序的配置文件,但这种方式运营部署起来很麻烦,也容易沟通不到位,导致配置错误或重复。所以我们采取了通过Zookeeper动态分配WorkerID的方案,即在程序启动时,向Zookeeper发起请求,找到一个可用的WorkerID,如果找到一个可用的WorkerID,即创建一个临时子节点,利用Zookeeper临时节点可以自动释放的特性,当程序关闭时,该WorkerID就自动释放了,以达到了WorkerID的重用。只在进程启动时,访问一次Zookeeper来获取WorkeID,所以运行时不需要Zookeeper持续提供服务,性能也不会有损失。
数据埋点
所谓数据埋点,即将跟踪信息(TraceID、Span信息等)写入服务调用的上下文中,如果这个交给业务代码来完成的话,会导致业务代码变得冗余,同时如果业务代码忘记埋点,那就会丢失跟踪信息,所以在底层框架提供数据埋点,非常有必要。 数据埋点主要包括四个阶段:
- Client Send:客户端发起请求时,如果当前线程上下文已经有Trace信息,继续透传当前Trace信息,如果没有,表示一个信息的请求,生成信息的Trace信息进行传递。
- Server Recieve: 服务端接收到请求时间点,此时从当前请求里获取Trace信息,并将当前信息存入线程上下文。
- Server Send:服务端处理业务完成,准备返回响应时,标记业务处理完成,同时将当前Trace信息提交归档。
- Client Receive:客户端接收到服务端响应时,标记服务调用完成,同时将当前Trace信息提交归档。
如下的流程示例图说明各阶段埋点的位置,其中CS、SR为发起创建Trace信息到当前线程上下文的位置,CR、SS为归档提交Trace信息的位置。
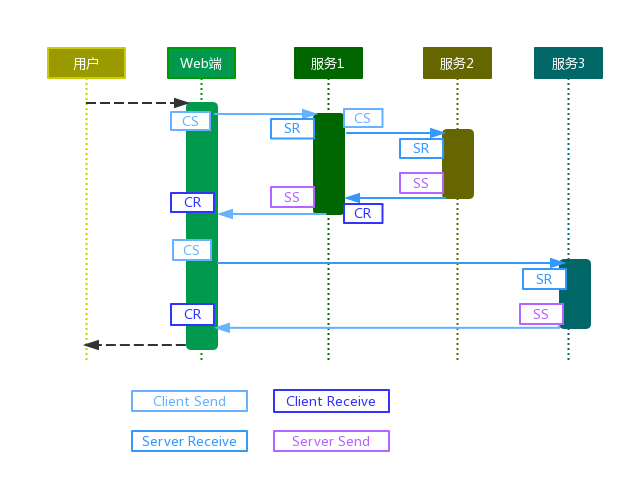
以上解释了在什么地方埋点和收集Trace信息,但是如何将当前上下文中的信息进行临时存储,并保证线程安全呢?这一点可以借助ThreadLocal来完成,发起创建Trace信息时,往ThreadLocal中写入记录,当前请求过程中再发起新的请求时,从ThreadLocal中获取Trace信息继续往下传递,等信息可以提交归档的时候,从ThreadLocal读取,并清除ThreadLocal中的信息。但是有一个问题需要注意,当发起异步请求时,发起请求的线程和最终被服务响应锁唤起的线程不是同一个线程,对于这种情况,如果响应线程是可由当前线程创建,使用可继承InheritableThreadLocal即可,如果不是,如由线程池来创建,则需要实现特别的线程池管理。另外还有一个办法就是,如果异步回调代码是可以注入的,那我们就可以在发起响应回调的时候注入代码即可。我们的RPC Client里就是采取这种方式。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | AsyncMethodCallback callback=new AsyncMethodCallback() { @Override public void onComplete(Object o) { if (transport != null) { closeTransport(url,transport); } //注入trace跟踪处理 Tracer.appendSpan(spanInfo); Tracer.addAannotation(serviceName, url.getIpByInt(), url.getPort(), AnnotationNames.CLIENT_RECV); Tracer.submitCurrentSpan(); //执行业务回调 resultHandler.onComplete(o); } }; |
同时,这里有个性能优化点需要注意,当Trace信息可以归档提交时,并不是往zipkin中直接写入,因为zipkin的性能有限,同时网络开销也较大,可以采取异步提交zipkin的方式,客户端归档信息后先从上下文往当前内存队列里写入,然后由单独的线程向zipkin提交记录。
Trace信息传递
前文说到,服务追踪的核心是将Trace信息(TraceID、SpanID)在整个调用链上进行传递,而这些类似上下文的信息,一般不适合作为参数置于服务调用方法里进行传递。如果是HTTP调用,我们可以用HTTP Header来传递信息是非常方便的,但是Thrift服务并没有所谓的Header信息可以传递。 通过研究Thrift代码,发现在Thrift的传输协议实现里,服务端读取数据反序列化协议的入口方法是:
public abstract TMessage readMessageBegin() throws TException;
返回的TMessage对象中,有一个name的属性,其存储的是需要调用的服务方法名,比如我们调用:UserService.getUser(1),那这里的name属性值就是“getUser”。既然这里name可以传递一个公用的字符串,那我们自然可以在此进行扩展,在name属性上传递更多信息。将name按一个文本格式协议,组装成一个header信息进行传递。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | //读取消息头 TMessage message = iprot.readMessageBegin(); // 提取Header文本 int index = message.name.lastIndexOf(TMultiplexedProtocol.SEPARATOR); String headersValue = message.name.substring(0, index); //采取Http Header文本格式传递 Headers headers = Headers.parseHeaders(headersValue); String traceID = headers.get(Constants.TPROTOCOL_HEADER_TRACE_ID);//arr[1]; String spanID = headers.get(Constants.TPROTOCOL_HEADER_SPAN_ID);//arr[2]; .... //将message.name还原,继续走thrift标准处理流程 int len = headersValue.length() + TMultiplexedProtocol.SEPARATOR.length(); String methodName = message.name.substring(len); TMessage standardMessage = new TMessage( methodName, message.type, message.seqid ); actualProcessor.process(new SomeProtocol(standardMessage)) |
关于此种扩展方式,Thrift标准库为了实现同一个server里host多个服务Processor,也采取了这种方式,只是标准库只扩展了一个ServiceName字段进行传递而已。具体可以参考Thrift标准库的TMultiplexedProtocol 与TMultiplexedProcessor的代码。
总结
本文介绍了从原理到实现上介绍了如何实现RPC服务追踪的细节,其关键基于调用链的概念。但是在实现上为了做到业务开发透明,还要不影响业务性能,还是需要很多谨慎考虑的。同时,我们其实还有很多未尽事宜需要继续优化,如提供安全的、埋点Tarce上下文的线程池,提供其他多种埋点客户端等等。同时,当Trace信息变成海量后,怎么存储这些信息,以及快速分析,从中挖取更多有意义、有价值的信息,将会成为我们新的挑战。
==================================================================================================================================================================
分布式锁进阶-设计概要
2016-11-01
锁在并发编程领域很为常见,当有资源竞争时就会有锁,在单进程的程序里,由于编程语言一般均提供了相应的原语,只需要简单的一个函数调用或声明,及可实现线程的互斥访问和操作。比如:
| 1 2 3 | lock(obj){ doSomthing(); } |
但是,如果程序需要在不同的进程间互斥访问或操作共享资源,那语言级别的的锁定原语就无能为力。比如:我们有两个客户端对同一个文件进行修改,相互的修改需要互斥,不能相互覆盖也不能脏读,显然我们只在进程内加锁是无法实现多个客户端之间的协同和互斥的。对于此类场景,分布式锁就派上用场了。
简单来说,分布式锁就是需要一个资源中心,客户端向该资源中心请求某一资源的锁定,如果请求成功,则锁定该资源,其他客户端不能继续锁定该资源,直到该资源被释放为止。
说到资源中心,我们最容易想到的就是数据库了,数据库是天然收敛的,具有中心化特点,同时他有可以提供数据行级别的原子锁定操作,比较适合作为分布式锁的中心。可以创建一个如下的表:
| 1 2 3 4 5 6 7 8 | CREATE TABLE lock_resource_t{ id int(11) NOT NULL AUTO_INCREMENT resource_name varchar(200) NOT NULL, insert_time timestamp NULL, lock_token varchar(32) NOT NULL, PRIMARY KEY (id), UNIQUE KEY uidx_resouce_name (resouce_name) USING BTREE }ENGINE=InnoDB; |
为resource_name创建了唯一索引,用数据库的唯一约束来进行资源互斥。可以定义以下的操作:
| 1 2 3 4 5 6 7 8 9 10 11 12 | //锁定操作 bool tryLock(string resouceName){ String lockToken=uuid(); return exex_sql(insert into lock_resource_t(resouce_name,lock_token) values(resouceName,lockToken);commit;); } //释放锁,lockToken用于保证只有当前锁定者才可以释放自己所锁定的资源 bool releaseLock(string resouceName,string lockToken){ return exex_sql(delete from lock_resource_t where resouce_name = resouceName and lock_token=lockToken);commit;; } |
上面的简单代码就基本模拟了一个分布式锁的核心功能:资源互斥。但是要作为一个可用的分布式锁这还远远不够。 注意到上面的锁定和释放,均只调用了一次,当有资源互斥的时候,它们会直接返回失败,如果失败了,那客户端只能不断重试,对于此,我们可以将重试的逻辑加到lock和release的API中去,这样就可以精简客户端的调用:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | //锁定操作,并自动重试 bool tryLock(string resouceName,int tryTimes){ String lockToken=uuid(); while(--tryTimes >= 0)){ if(exex_sql(insert into lock_resource_t(resouce_name,lock_token) values(resouceName,lockToken);commit;)){ return true; }else{ thread.sleep(200); } } return false; } bool releaseLock(string resouceName,string lockToken,int tryTimes){ while(--tryTimes >= 0)){ if(exex_sql(delete from lock_resource_t where resouce_name = resouceName and lock_token=lockToken;commit;)){ return true; }else{ thread.sleep(200); } } return false; } |
以上实现,在客户端均能正常调用的情况下没有问题,但是当客户端出现异常时,可能导致锁无法被释放。比如某客户端锁定某资源后,还没有来得及释放该资源的锁就崩溃了,将导致该资源一直被锁定,其他客户端均无法访问该资源。对于此类问题,一般引入锁定的超时时间来解决,即在调用锁定失败之后,判断原来锁的时间与当前时间差是不是超过了锁定周期,如果超过,及释放掉原来的锁,重新获取锁成功。代码如:
| 1 2 3 4 5 6 7 8 9 10 11 | //锁定操作,并自动重试 bool tryLock(string resouceName){ String lockToken=uuid(); int timeout=30000; //先删除已过期的锁,再执行锁定,但必须保证删除和锁定的原子性 return exec( delete from lock_resource_t where resouce_name = resouceName and insert_time<now()-timeout; insert into lock_resource_t(resouce_name,lock_token, insert_time) values(resouceName,lockToken,now()); commit; ); } |
上述实现中,由于考虑到各个客户端可能存在时钟差异,我们直接使用数据库时钟来获取时间。 受限于数据库的性能,基于数据库的分布式锁方案,当并发访问较高时,吞吐量一般,延时也较大, 可以使用redis来替代数据库。由于redis可以为某个key设置超时,所以我们只需要在插入该key时设置超时时间即可,而不用客户端再来处理超时:
| 1 | SET resource_name lock_token NX PX 60000 |
以上指令将设置resource_name的值,仅当其不存在时生效(NX选项), 且设置其生存期为60000毫秒(PX选项)。并且上述指令是原子性的,所以只要上述命令能执行成功,即代表客户端可以获取到锁,否则认为失败。但是由于Redis没有提供能判断值的相等性后执行删除的原子命令,所以需要借助Lua脚本(Redis的单线程特性,执行Lua脚本命令也是单线程执行)
| 1 2 3 4 5 | if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end |
现在有了互斥、重试以及超时管理,我们基本解决了客户端获取锁的问题,既保证了在任何时候只有一个客户端可以获得锁,也保证了锁在没有正常释放的情况下,资源也能继续被使用。但是还有一个问题需要解决,我们前面均只考虑了只存在一个中心的情况,无论是数据库还是redis,如果只有一个中心节点,那就存在单点问题。分布式锁作为系统的中心,如果其不可用(除了可用性问题,采用Redis的方案,如果单节点出现failover,可能导致数据丢失,锁的状态也可能丢失,引起锁的不安全性问题),将导致所有客户端均不能正常使用。容易想到的解决方案是,建立数据库集群或者redis集群来解决。但是集群真的能锁的不安全问题吗?它会不会带来新的问题?
举例来说,采取主从架构来部署Redis集群,每个Redis的主节点挂载一个从节点作为备份,当主节点不可用时,切换到从节点,可以明显提升Redis的可用性。但是这里忽略了一个问题,由于Redis的主从间数据复制时异步的,所以当主节点崩溃的时候,数据可能还未完全同步从节点,当从节点接管服务后,有可能丧失了锁的安全性。鉴于此情况,Redis的作者提出了基于N(N通常为奇数)个Redis节点的Redlock的算法(https://redis.io/topics/distlock ),算法概述如下:
1、客户端获取本地机器时间;
2、客户端循环遍历N个Redis节点,执行以下命令以尝试获取锁:
| 1 | SET resource_name lock_token NX PX 60000 |
3、由于需要向多个Redis节点获取锁,为了保证某个Redis节点不可用时算法可以继续运行,获取锁的操作过程中通常还需要设置一个超时时间,并且这个超时时间应该比锁的有效持有时间短很多。当客户端向某个Redis获取锁失败时,立即尝试从下一个节点获取锁。
4、获取锁完成后用当前时间减去第一步记录的时间,得到获取锁过程的总时长,如果超过半数的Redis节点最终获取成功锁,并且获取锁的总时长小于锁的有效持有时间,则客户端成功获取锁,否则获取锁失败。
5、如果客户端最终判断获取锁失败,则立即向每个Redis节点释放锁,需要注意的是,无论这个节点有没有获取成功,均需要释放,因为如果是超时引起的获取失败节点,其最终有没有锁成功的状态是未知的。
以上基于通过超时来自动释放锁的方式,存在一个局限是要求客户端的实际操作必须在锁定超时时间内完成,如果客户端的处理时间超过超时时间,则状态会变成不安全,超时时间的选择是一个比较困难的点。Redlock要求获取锁的时间应远小于超时时间,以给客户端的操作预留足够的处理时间,所以该如何选择锁定成功的有效时间呢?又是一个比较困难的问题。除了这个问题,Redlock还是依然存在几种可能导致不安全锁的情况。
先看第一种情况,假设有1、2、3三个Redis节点,分别发生以下锁获取的事件:
- 客户端A通过成功从1、2节点获取锁,节点3未成功获取,最终判定为获取锁成功。
- 此时节点2发生重启,导致客户端A在该节点上的锁定状态丢失。
- 节点2重启之后,客户端B又通过从节点2、3成功获取相同资源的锁,即对于相同资源,两个客户端都同时获取到了锁,导致了不安全的情况。
以上问题,默认情况下可以借助于Redis的AOF持久化机制来尽量保证数据状态不丢失,同时设置Redis每次修改操作都执行fsync,但会明显降低Redis的写入性能(不同的操作系统,fsync也不一定能完全保证不丢失数据)。
第二种情况,同样假设有1、2、3三个Redis节点,分别发生以下事件:
- 客户端A通过成功从1、2节点获取锁,最终判定为获取锁成功
- 节点2的机器发生机器时间前移(比如有人手工更新了机器时间或NAT同步错误),导致节点2上的锁快速过期
- 客户端B又通过从节点2、3成功获取相同资源的锁,即对于相同资源,两个客户端都同时获取到了锁,导致了不安全的情况。
以上问题,是由分布式锁的实现依赖了不可靠的时钟导致。
另外以上所有基于超时时间来让锁自动解决的方案,存在一种解决不了的情况,那就是当客户端本身发生延时无法判断锁的有效性,导致不安全的情况。比如,分别发生以下事件:
- 客户端A向分布式锁服务获取到了锁,并成功为锁设置超时时间
- 客户端A获取锁后,马上进入了暂停状态,比如发生Full GC
- 在客户端A暂停期间,锁过期,分布式锁的服务将锁分配给客户端B
- 客户端A从暂停的状态中恢复,继续执行,此时客户端A并不知道自身的锁已经过时,即发生不安全情况,锁同时被客户端A和客户端B持有。
接下来,我们来看看基于zookeeper的分布式锁实现,能不能解决上述问题呢?基于zookeeper来实现分布式锁的一般实现方式如下:
- 客户端尝试向zookeeper创建一个节点“/lock_token”,如果客户端创建节点成功,则获取锁成功,否则则认为失败;
- 客户端释放锁时,只需要将创建的节点删除,即可完成锁的释放
- 由于zookeeper有临时节点的功能,所以只要创建的节点是临时节点,当客户端崩溃后,由于会话消失,临时节点会被自动删除,锁也一定会释放
上述方案解决了上面说的锁自动释放问题,同时由于zookeeper的多节点持久化存储功能,所以也解决了由于数据状态丢失导致的不安全锁问题。但是回到上面说到的如果客户端获取后马上进入暂停状态,如Full GC,会不会发生不安全锁的问题?这主要要分析zookeeper时怎么判断会话丢失的。zookeeper的会话存活判断基于与客户端之间的心跳,心跳从客户端发往zookeeper,如果超过一定时间没有收到客户端的心跳即认为客户端已经不存活了,但是不幸的是,客户端进入Full GC的暂停状态时,或客户端与zookeeper间出现网络隔离,会话丢失,将同样会发生锁失效导致其他客户端同时获取锁的问题。所以,基于zookeeper的实现,也同样无法根本解决不安全锁的问题。
尽管基于zookeeper的实现,无法提供真正安全的分布式锁,但借助于zookeeper的一些功能特性,将使得分布式锁的实现变得简单。
一个是zookeeper的watch机制,客户端在没有获取成功锁时,不需要一直向zookeeper查询锁的状态,借助watch机制由zookeeper主动通知客户端来来唤醒,从而使客户端不用进入“自旋”状态。二是zookeeper可以建立顺序子节点,这一点非常有助于实现分布式锁的公平性,具体将在下一篇关于分布式锁的具体代码实现的文章里继续介绍。














 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









