




 本文详细介绍了MapReduce作业从提交到初始化的过程,包括作业文件的上传、InputSplit文件的生成及作业提交到JobTracker的具体步骤。此外,还深入解析了DistributedCache的工作原理及其在MapReduce中的应用。
本文详细介绍了MapReduce作业从提交到初始化的过程,包括作业文件的上传、InputSplit文件的生成及作业提交到JobTracker的具体步骤。此外,还深入解析了DistributedCache的工作原理及其在MapReduce中的应用。
一个MapReduce作业的提交与初始化过程,即从用户输入提交作业命令到作业初始化的整个过程。该过程涉及JobClient、JobTracker和TaskScheduler三个组件,它们的功能分别是准备运行环境、接收作业以及初始化作业。
作业提交过程比较简单,它主要为后续作业执行准备环境,主要涉及创建目录、上传文件等操作;而一旦用户提交作业后,JobTracker端便会对作业进行初始化。作业初始化的主要工作是根据输入数据量和作业配置参数将作业分解成若干个Map T ask以及Reduce Task,并添加到相关数据结构中,以等待后续被调度执行。总之,可将作业提交与初始化过程分为四个步骤:
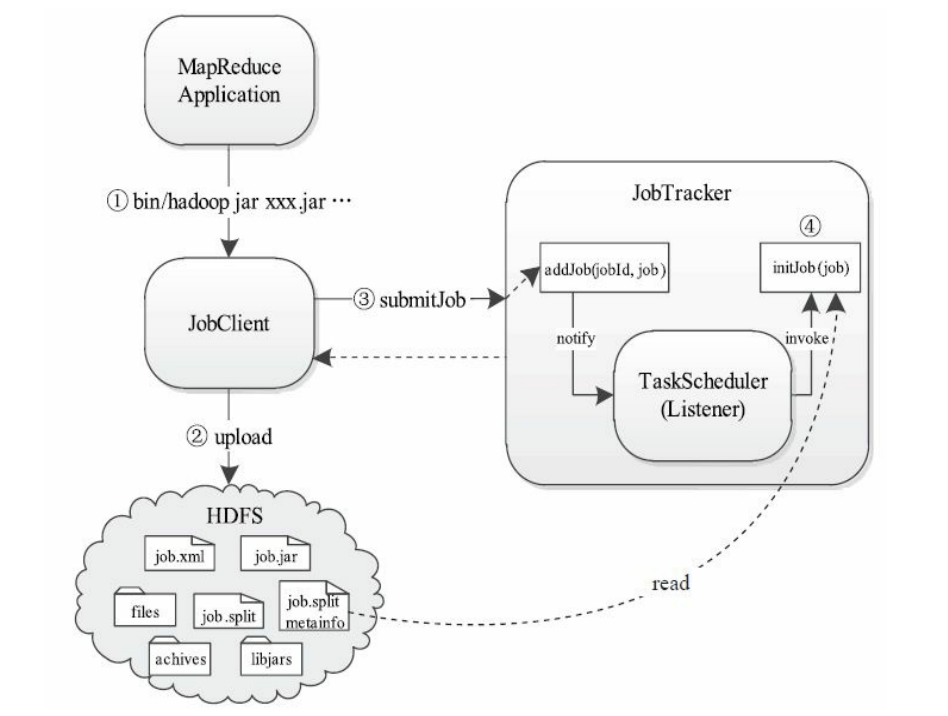
步骤1 用户使用Hadoop提供的Shell命令提交作业。
步骤2 JobClient按照作业配置信息(JonConf)将作业运行需要的全部文件上传到JobTracker文件系统(通常为HDFS)的某个目录下。
步骤3 JobClient调用RPC接口向JobTracker提交作业。
步骤4 JobTracker接收到作业后,将其告知TaskScheduler,由TaskScheduler
对作业进行初始化。
作业提交过程详解
1.执行Shell命令
当用户输入以上命令后,bin/hadoop脚本根据“jar ”命令将作业交给RunJar类
处理,相关shell代码如下:
……
elif[“$COMMAND”=”jar”];then
CLASS=org.apache.hadoop.util.RunJar
……
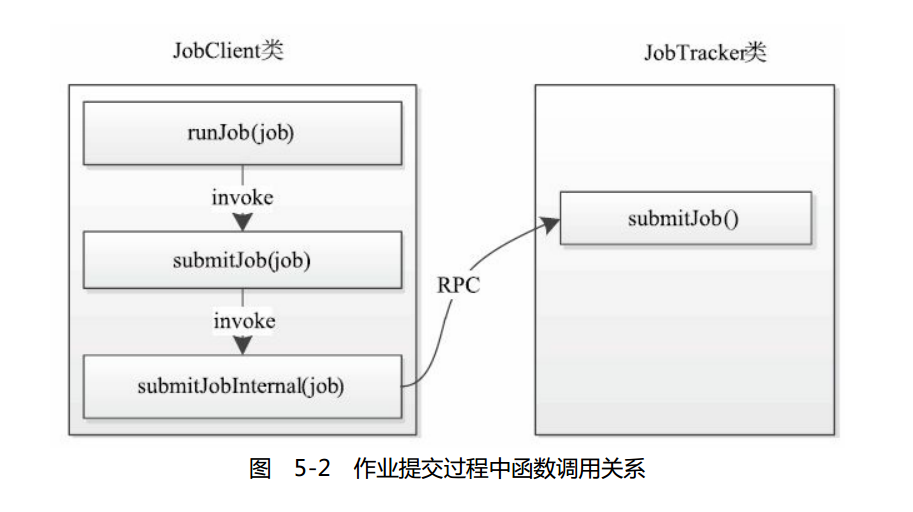
RunJar类中的main函数经解压jar包和设置环境变量后,将运行参数传递给
MapReduce程序,并运行之。用户的MapReduce程序已经配置了作业运行时需要的各种信息(如Mapper类,Reducer类,ReduceTask个数等),它最终在main函数中调用JobClient.runJob函数(新MapReduce API则使用
job.waitForCompletion(true)函数)提交作业,这之后会依次经过如图所示的函数调用顺序才会将作业提交到JobTracker端。
2.作业文件上传
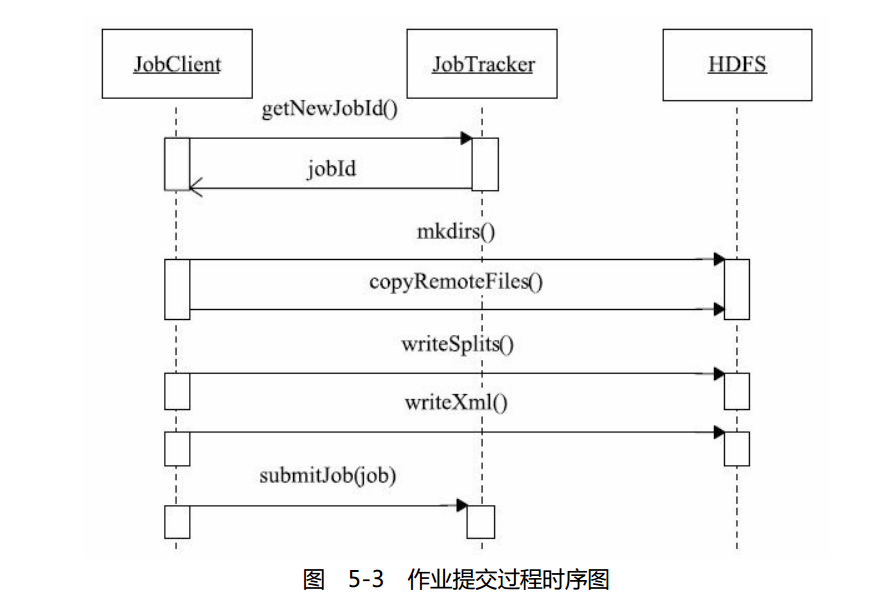
JobClient将作业提交到JobT rack er端之前,需要进行一些初始化工作,包括:获
取作业ID,创建HDFS目录,上传作业文件以及生成Split文件等。这些工作由函数
JobClient.submitJobInternal(job)实现,具体流程如图5-3所示。
MapReduce作业文件的上传与下载是由DistributedCache工具完成的。它是
Hadoop为方便用户进行应用程序开发而设计的数据分发工具。其整个工作流程对用
户而言是透明的,也就是说,用户只需在提交作业时指定文件位置,至于这些文件的分发(需广播到各个TaskTracker上以运行Task),完全由DistributedCache工具完成,不需要用户参与。
3.产生InputSplit文件
用户提交MapReduce作业后,JobClient会调用InputFormat的getSplits方法生
成InputSplit相关信息。该信息包括两部分:InputSplit元数据信息和原始InputSplit信息。其中,第一部分将被JobTracker使用,用以生成Task本地性(T ask Locality)相关的数据结构;而第二部分则将被MapTask初始化时使用,用以获取自己要处理的数据。
4.作业提交到JobTracker
JobClient最终调用RPC方法submitJob将作业提交到JobTracker端,在
JobTracker.submitJob中,会依次进行以下操作:
(1)为作业创建JobInProgress对象
JobTracker会为每个作业创建一个JobInProgress对象。该对象维护了作业的运
行时信息。它在作业运行过程中一直存在,主要用于跟踪正在运行作业的运行状态和进度。
(2)检查用户是否具有指定队列的作业提交权限
Hadoop以队列为单位管理作业和资源,每个队列分配有一定量的资源,每个用
户属于一个或者多个队列且只能使用所属队列中的资源。
(3)检查作业配置的内存使用量是否合理
用户提交作业时,可分别用参数mapred. job.map.memory.mb和
mapred. job.reduce.memory.mb指定MapTask和ReduceTask占用的内存量;而管理员可通过参数mapred.cluster.max.map.memory.mb和
mapred.cluster.max.reduce.memory.mb限制用户配置的任务最大内存使用量,一
旦用户配置的内存使用量超过系统限制,则作业提交失败。
(4)通知TaskScheduler初始化作业
JobTracker收到作业后,并不会马上对其初始化,而是交给调度器,由它按照一
定的策略对作业进行初始化。之所以不选择JobTracker而让调度器初始化,主要考虑到以下两个原因:
❑作业一旦初始化后便会占用一定量的内存资源,为了防止大量初始化的作业排
队等待调度而占用大量不必要的内存资源,Hadoop按照一定的策略选择性地初始化
作业以节省内存资源;
❑任务调度器的职责是根据每个节点的资源使用情况对其分配最合适的任务,而
只有经过初始化的作业才有可能得到调度,因而将作业初始化策略嵌到调度器中是一种比较合理的设计。
Hadoop的调度器是一个可插拔模块,用户可通过实现TaskScheduler接口设计
自己的调度器。当前Hadoop默认的调度器是JobQueueTaskScheduler。它采用的调度策略是先来先服务(First In First Out, FIFO)。另外两个比较常用的调度器是FairScheduler和Capacity Scheduler
JobTracker采用了观察者设计模式(也称为发布-订阅模式)将“提交新作业”这
一事件告诉TaskScheduler
JobTracker采用观察者设计模式将作业变化(添加/删除/更新作业)通知
TaskScheduler
作业初始化过程详解
调度器调用JobTracker. initJob()函数对新作业进行初始化。作业初始化的主要工
作是构造Map Task和Reduce Task并对它们进行初始化。
Hadoop将每个作业分解成4种类型的任务,分别是Setup Task、
Map Task、Reduce Task和Cleanup Task。它们的运行时信息由T askInProgress类维护,因此,创建这些任务实际上是创建TaskInProgress对象。
Hadoop DistributedCache原理分析
DistributedCache是Hadoop为方便用户进行应用程序开发而设计的文件分发工
具。它能够将只读的外部文件自动分发到各个节点上进行本地缓存,以便Task运行时加载使用。它的大体工作流程如下:用户提交作业后,Hadoop将由-files和-archives选项指定的文件复制到JobTracker的文件系统(一般为HDFS)中;之后,当某个TaskTracker收到该作业的第一个Task后,该任务将负责从JobTracker文件系统中将文件下载到本地磁盘进行缓存,这样后续的Task就可以直接在本地访问这些文件了。除了文件分发外,DistributedCache还可用于软件自动安装部署。比如,用户使用PHP语言编写了MapReduce程序,为了能够让程序成功运行,用户需要求运维人员在Hadoop集群的各个节点上提前安装好PHP解释器,而当需要升级PHP解释器时,可能需通知Hadoop运维人员进行一次升级,这使得软件升级变得非常麻烦。为了让软件升级变得更可控,用户可采用DistributedCache将PHP解释器分发到各个节点上,每次运行程序时,DistributedCache会检查PHP解释器被改过(比如升级新版本),如果是,则会自动重新下载。
用户编写的MapReduce应用程序往往需要一些外部的资源,比如分词程序需词
表文件,或者依赖于三方的jar包。这时候,我们希望每个Task初始化时能够加载这些文件,而DistributedCache正是为了完成该功能而提供的。
使用Hadoop DistributedCache可分为3个步骤:
步骤1 在HDFS上准备好文件(文本文件、压缩文件、jar包等),并按照文件可见级别设置目录/文件的访问权限;
步骤2 调用相关API添加文件信息,这里主要是配置作业的JobConf对象;
步骤3 在Mapper或者Reducer类中使用文件,Mapper或者Reducer开始运行
前,各种文件已经下载到本地的工作目录中,直接调用文件读写API即可获取文件内容。
步骤1 准备文件。将文件dictionar y .zip和third-par ty . jar上传到HDFS上的目
录/data/private/中,blacklist.txt和whitelist.txt上传到目录/data/public/中。其
中,目录/data/private/的权限为“ dr wxr -xr –”,目录/data/public/的权限
为“ dr wxr -xr -x”。
$bin/hadoop fs-copyFromLocal dictionary.zip/data/private/
$bin/hadoop fs-copyFromLocal third-party.jar/data/private/
$bin/hadoop fs-copyFromLocal blacklist.txt/data/public/
$bin/hadoop fs-copyFromLocal whitelist.txt/data/public/步骤2 配置JobConf。
JobConf job=new JobConf();
DistributedCache.addCacheFile(new URI("/data/public/blacklist.txt#blacklist"),job);
DistributedCache.addCacheFile(new URI("/data/public/whitelist.txt#whitelist",job);
DistributedCache.addFileToClassPath(new Path("/data/private/third-party.jar"),job);
DistributedCache.addCacheArchive(new URI("/data/private/dictionary.zip",job);
DistributedCache.createSymlink(job);步骤3 在Mapper或者Reducer类中使用文件。
public static class MapClass extends MapReduceBase
implements Mapper<K, V,K, V>{
private Path[]localArchives;
private Path[]localFiles;
public void configure(JobConf job){
//在本地获取archives或者files
localArchives=DistributedCache.getLocalCacheArchives(job);
localFiles=DistributedCache.getLocalCacheFiles(job);
//调用文件API读取文件内容,保存到相关变量中
……
}
public void map(K key, V value,
OutputCollector<K, V>output, Reporter reporter)
throws IOException{
//在此使用缓存中的archives/files
//……
output.collect(k, v);
}
}
















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









