







这一周学习的主要内容是Linux的内存的寻址和内存管理,对应的书本就是Linux操作系统原理与应用的第二章和第四章。
第二章刚开始部分回顾了寻址方式的演变过程,由最原始的4位机到后来的16位,引入了段的概念到后来的32位后,段寄存器的存在却成了向下兼容与支持保护模式的一大障碍。寄存器大概分为两大类,一类是基本结构寄存器,有通用寄存器、段寄存器、指令寄存器和标志寄存器,另一类是系统级寄存器,有控制寄存器、系统地址寄存器、调试和测试寄存器。我们所能用到的基本上是第一类寄存器,这是提供给用户可以访问的寄存器,而第二类则是系统自己使用的,在Linux寻址中用到的主要是控制寄存器中的CR0、CR2、CR3,控制寄存器都 是32位的。CR0的最低位PE是保护允许位,为0的话系统运行在实模式下,为1时系统运行在保护模式下,CR0最高位PG位是分页允许位,该位为0表示不允许,为1时表示允许。CR2存放的是最近一次缺页的32位线性地址,CR3的高20位存放的是页目录的基址,低12位默认为0,即使不为0也会被忽略。
第二章比较让人迷惑的是物理地址、虚拟地址、线性地址这三个概念,第一个是物理内存所对应的实际地址,第二个是程序员编程时所使用的地址,这个地址可以非常大,所以程序也可以非常的大,第三个是当前机器(如32位机)所对应的最小地址0到最大地址232之间的连续地址。
分段的实现依赖于段寄存器,段表用8个字节描述,基址32位,界限20位,属性12位,段寄存器中存放是选择符,高13位放的是索引,对应于段表中的索引(0、1、2…),RPL对应于低2位,表示请求者的特权级,0对应于内核态,3对应于用户态,第三位TI用于选择相应的段描述符,为0表示从全局描述符表中选择,为1表示从局部描述符表中选择,全局描述符表是唯一的存在,实际指的就是存放段表结构入口地址的数组,而局部描述符表则可以不唯一,是任务所用的描述符表,一个任务最多只能有一个。这里所用到的寄存器是系统地址寄存器GDTR(32位入口地址+16位表的界限)和LDTR(对程序可见的是16位)。由于段基址和偏移量都是32位,这样每个程序的寻址空间都达到了4G,Linux中为了简化实现段的复杂性绕过了分段机制,将段基址设置为0,这样的话0+偏移量=线性地址,Linux想实现的是一种纯粹的分页机制。
2.6版本内核采用了四级页表,为了能够简单的了解由线性地址到物理地址的转换过程,书本上采用了二级页表来讲解,地址结构的高10位是页目录,接着的10位是页号,低12位是偏移量,其中10位的页目录和10位的页都中是为了实现索引的作用,转换流程如下图:
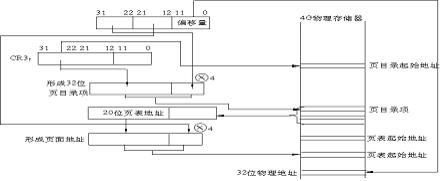
第一步从CR3中取出高20位页目录的基地址,再从线性地址取出高10位乘以4(因为页目录项占4字节长度,以4字节为一跳),两个相加就得到了相应的页目录项,取高20位,给低12位补零就得到了二级页表的基址。
第二步取线性地址的12~21位乘以4(同理,一个页表项4个字节),再与第一步得到的二级页表基址相加就得到了相应页表项在内存的地址。
第三步读取页表项的高20位,并给低12位补零后就是线性地址对应物理块的基址,与线性地址的低12位相加后就是转换后的32位页面物理地址。
第二章中还讲了AT&T与INTEL汇编的简单对比,主要涉及到前缀、操作数方向、内存寻址、操作码后缀。前缀主要讲了寄存器的前缀要加%,立即数加前缀$,十六进制立即数加前缀0x,操作数方向与INTEL方向正好相反,源操作数放在前面,目的操作数放后面,内存寻址中的偏移量放在()前面,基寄存器用()括起来,例如一个基址变址的例子:5(%ebx,%eax,2),相应的绝对地址是ebx+2*eax+5,操作码的后缀问题,l/w/b分别对应长整(32位)/字/字节,将这个加在指令后面就不用像INTEL中还要在操作数前加上类型的说明,如movw %bx %ax。
第四章主要学习了Linux的内存管理,主要内容包括相关概念、进程用户空间的管理、请页机制、物理内在的分配与回收、交换机制等。
因linux简化了分段机制,使得虚地址与线性地址保持了一致性,4G的线性地址划分为内核空间和用户空间,内核空间是较高的1G,较低的3G则被称为用户空间,虚地址对于CPU来说是不可知的,CPU只会根据当前执行进程的页表来完成虚地址到物理地址的转换,而其他时刻各进程间的虚地址互不影响。内核空间的虚拟地址与物理内存之间存在着一一映射的关系,虚拟地址减去3G的位移量后就得到了映射的物理地址。
进程用户空间管理中最重要的结构体有mm_struct(用户空间的描述,成员有pdg、*mmp等)和vm_area_struct两个结构体(虚存区的描述,成员有vm_end、vm_start、vm_next等),虚存区结构体中还有一个指针成员指向虚存区操作结构体,用来完成对虚存区的操作(因为Linux把虚存区当作一个对象),整个的关系指向如下:task_struct中的*mm成员指向mm_struct,mm_struct中的pdg指向页目录、*mmp指向vm_area_struct,vm_area_struct中的vm_end和vm_start分别指向虚存区的起始地址、vm_next指向下一个vm_area_struct结构体,用fork调用创建子进程时就是构造这几个结构体的过程,在构造vm_area_struct链时,采用了平衡树AVL方法来加速检索。
虚存区的映射的方式有共享方式、私有方式和匿名方式,共享方式是几个进程共享一个映射,私有方式是采用写时复制的手段,这种映射主要是为了读文件,匿名映射则映射与文件无关,映射调用的函数是do_mmap()。
下面主要内容就是请页机制,对于书本上的缺页异常处理流程图我看的不太懂,可以通过调用do_no_page()最终落实到__get_free_page()函数上。这一节中一个很重要的思想是写时复制,这个手段是一种可以推迟甚至避免复制数据的技术,当创建子进程时,让父子进程共享同一个副本,只有当对共享页面进行写操作时才会复制副本,fork调用创建的子进程基本上并不是为了执行父进程的代码,而是为了新的任务而生的,这时可以调用exec()来使子进程执行别的任务。
内存的分配与回收中介绍了Linux所采用的伙伴算法,伙伴算法块的划分采用了10级,最大为512个页面,描述的结构体如下:struct free_area_struct{
struct page *next;
struct page *prev;
unsigned int *map;
}free_area[10];
空闲块采用双链表的方式链接起来,数字10则代表是哪个级别的空闲块。伙伴的定义则要满足两个条件:两个块大小相同,两个块的物理地址连续。分配的函数定义如下:unsigned long __get_free_pages(int gfp_mask,unsigned long order);其中gfp_mask是分配标志,常用的有GFP_KERNEL(可以用于睡眠)和GFP_ATOMIC(不能用于睡眠,用于中断处理程序),order表示申请块的大小是2的order次方个页,整个算法中还会涉及到页面的交换,当总的空闲页面小于阙值时会交换一部分页,而在回收内存的时候还会涉及到伙伴块的合并。
当要分配的内存很小,可能不足一个页面时Linux采用slab分配模式,slab分配模式是把对象分组放进缓冲区中,这里的对象还会根据大小分为大对象和小对象(以512字节为分界线),这里的对象一般是数据结构,把相同类型的数据结构放在同一组中,缓冲区又分为专用和通用缓冲区,专用缓冲区通过调用kmem_cache_creat()函数来创建,这个函数后两个参数是函数指针,指向构造函数和析构函数,这里一般为空,使用kmem_cache_alloc()来创建对象,使用kmem_cache_free()函数来释放对象。通用缓冲区kmalloc()函数来分配缓冲区,kfree()函数来释放缓冲区。内核空间非连续内存区的分配是在高端内存区,内核空间从3G开始到high_memory是物理内存区的映射,这里是与物理内存地址一一映射的,high_memory+8M开始到4G是高端内存区,每个内存区插入4KB的安全区,分配函数可以采用kmalloc()和vmalloc(),前者分配的是连续的页,而后者分配的却不是连续的页,为此还要专门建立页表项,获得的页必须逐个的进行映射,这就会导致比直接内存映射大得多的缓冲区刷新,一般为了获得大块内存时才能会调用vmalloc()函数。















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









