







摘 要
ChatGPT的出现迅速引爆了AI的又一波热潮。在通信行业中,网络规划、建设、维护、优化、运营是非常耗时、复杂且需要大量人力成本的工作。语言大模型在通信运营商中有着非常广阔的应用前景。阐述了语言大模型开发的基本技术方案及原理并对其在通信行业的应用进行了研究与展望。
前 言
ChatGPT的出现迅速引爆了AI的又一波热潮。作为一种人工智能技术驱动的语言大模型,ChatGPT使用了Transformer神经网络架构,拥有语言理解和文本生成能力。ChatGPT不单是几乎与人无异的聊天机器人,还能执行撰写邮件、视频脚本、文案、翻译、代码等任务。ChatGPT极大便利了AI的开发和应用,给AI的发展带来革命性的影响。每个行业、每个领域都值得AI化,人工智能将从服务的规模化、个性化、普惠化和持续化带动井喷式增长,促进经济高速发展。AI2.0时代,AI将成为数字经济的重心,有望超越云计算成为第4波计算浪潮。
越来越多的企业开始关注如何将大模型应用于生产实践中,以提高业务效率和降低成本。在通信行业中,网络规划、建设、维护、优化、运营是非常耗时、复杂且需要大量人力成本的工作。我国通信网络规模庞大,网络结构复杂,网络需要支撑的业务要求很高,网络稳定运行和保证优秀的网络服务质量的压力很大,这些都给网络日常生产运营工作带来了巨大的挑战和压力。如何把大模型应用到网络生产运营过程中,助力网络向自智网络演进是我们需要重点考虑的问题。
ChatGPT通用大模型采用自回归生成式训练、单向注意力机制、多层Transformer架构,通过海量参数和海量数据产生了极大的性能提升,辅以有监督调优和人类反馈的强化学习,形成了突破性的AI产品。但是通用大模型并不能“包治百病”,通用大模型的直接应用存在数据可信度不高、数据安全不可控、行业知识缺乏等问题,无法完全满足运营商的生产运营需求。企业从头训练一个私有化的通用大模型则需要海量数据和海量算力,还需要一批顶尖的AI人才,难度极大。为了解决这些问题,可以通过构建通信行业领域大模型来提高网络相关工作效率,并为一线网络运维工程师提供优质的智能化网络应用产品。
0 1
语言大模型技术方案研究
1.1 基础模型选择
语言模型是一种利用人工智能技术来预测或生成自然语言表达的方法,它们在自然语言处理(NLP)领域有着广泛的应用。语言模型的发展经历了从基于统计的方法到使用神经网络的方法,再到最近的预训练语言模型(PLM)技术的转变。PLM技术是一种利用Transformer模型在大规模文本数据上进行预训练,然后在特定任务上进行微调的方法,它可以提高语言模型的语言理解和表示能力,提升NLP任务的性能。
大型语言模型(LLM)是一种规模非常庞大的PLM,它们具有超过一定阈值(例如10亿或100亿)的参数数量,可以显著提高语言模型的性能,并展示出一些小型语言模型所不具备的能力,例如上下文学习、常识推理、知识融合等。LLM具有强大的语言理解和生成能力,可以应用于多种NLP任务,例如机器翻译、问答、摘要、对话等。但是,LLM也带来了一些技术和伦理方面的挑战和风险,例如计算资源消耗、数据质量控制、模型可解释性、社会责任等。
OpenAI和Google是LLM的领导者,他们分别开发了GPT系列和BERT系列等多个大型模型集合。这些大型模型集合包括了各种不同领域和任务的PLM,可以应用于多种场景,例如搜索引擎、社交媒体、教育、医疗等。但是,这些PLM可能存在一些偏见、误解、伦理等问题,例如歧视、误导、欺骗等。因此,需要对LLM进行更深入的研究和监督,以确保它们能够为人类社会带来积极的影响,而不是负面的后果。同时,也需要加强对LLM的公平性、可靠性、安全性等方面的评估和改进。
1.2 大模型训练调优
1.2.1 大模型的预训练
LLM是一种利用大量文本数据训练的深度学习模型,能够在多种自然语言处理任务中表现出优异的性能。然而,创建或复制LLM并不是一件容易的事情,它需要解决技术和计算资源的难题。我们可以借鉴已有的LLM经验和公共资源,如开源模型检查点、API、语料库和支持LLM的库等,来降低开发成本和难度。
LLM的核心是数据预训练,即使用大量无标注或弱标注的数据来训练模型的基础参数,使其能够学习到语言的通用规律和知识。数据预训练需要高质量的数据集,包括通用数据和专业性数据。通用数据是指覆盖广泛领域和主题的文本数据,如网页、对话、书籍、多语言文本等;专业性数据是指针对特定领域或任务的文本数据,如科学文本和代码数据等。不同类型的数据可以提供不同层次的语言信息,有助于提升LLM的泛化能力和适应能力。LLM的预训练数据来源分布如图1所示。
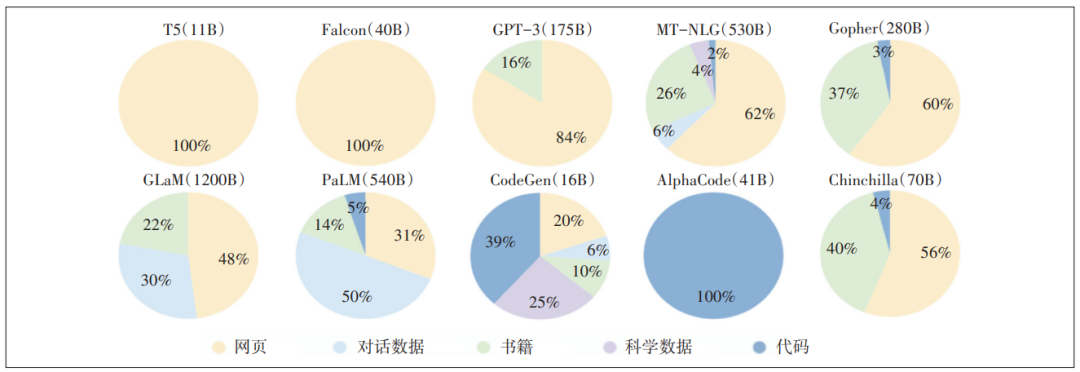
图1 LLM的预训练数据来源分布
除了数据预训练外,LLM还需要进行数据预处理、网络框架设计和训练方式选择等步骤。数据预处理是指对原始数据进行清洗、分词、编码等操作,以便于模型输入和输出。网络框架设计是指选择合适的深度神经网络结构,以实现高效的信息传递和表示学习。训练方式选择是指采用合适的自监督学习方式,以利用无标注或弱标注的数据进行模型训练。目前,最常用的网络框架是Transformer模型,最常用的自监督学习方式是掩码语言建模(MLM),它们已经在多个LLM中得到了广泛应用。
1.2.2 大模型微调调优
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









