







Kafka 事务在流处理中应用很广泛,比如原子性的读取消息,立即处理和发送,如果中途出现错误,支持回滚操作。这篇文章来讲讲事务是如何实现的,首先来看看事务流程图。
事务流程
Kafka的整个事务处理流程如下图:

上图中的 Transaction Coordinator 运行在 Kafka 服务端,下面简称 TC 服务。
__transaction_state 是 TC 服务持久化事务信息的 topic 名称,下面简称事务 topic。
Producer 向 TC 服务发送的 commit 消息,下面简称事务提交消息。
TC 服务向分区发送的消息,下面简称事务结果消息。
寻找 TC 服务地址
Producer 会首先从 Kafka 集群中选择任意一台机器,然后向其发送请求,获取 TC 服务的地址。Kafka 有个特殊的事务 topic,名称为__transaction_state ,负责持久化事务消息。这个 topic 有多个分区,默认有50个,每个分区负责一部分事务。事务划分是根据 transaction id, 计算出该事务属于哪个分区。这个分区的 leader 所在的机器,负责这个事务的TC 服务地址。
事务初始化
Producer 在使用事务功能,必须先自定义一个唯一的 transaction id。有了 transaction id,即使客户端挂掉了,它重启后也能继续处理未完成的事务。
Kafka 实现事务需要依靠幂等性,而幂等性需要指定 producer id 。所以Producer在启动事务之前,需要向 TC 服务申请 producer id。TC 服务在分配 producer id 后,会将它持久化到事务 topic。
发送消息
Producer 在接收到 producer id 后,就可以正常的发送消息了。不过发送消息之前,需要先将这些消息的分区地址,上传到 TC 服务。TC 服务会将这些分区地址持久化到事务 topic。然后 Producer 才会真正的发送消息,这些消息与普通消息不同,它们会有一个字段,表示自身是事务消息。
这里需要注意下一种特殊的请求,提交消费位置请求,用于原子性的从某个 topic 读取消息,并且发送消息到另外一个 topic。我们知道一般是消费者使用消费组订阅 topic,才会发送提交消费位置的请求,而这里是由 Producer 发送的。Producer 首先会发送一条请求,里面会包含这个消费组对应的分区(每个消费组的消费位置都保存在 __consumer_offset topic 的一个分区里),TC 服务会将分区持久化之后,发送响应。Producer 收到响应后,就会直接发送消费位置请求给 GroupCoordinator。
发送提交请求
Producer 发送完消息后,如果认为该事务可以提交了,就会发送提交请求到 TC 服务。Producer 的工作至此就完成了,接下来它只需要等待响应。这里需要强调下,Producer 会在发送事务提交请求之前,会等待之前所有的请求都已经发送并且响应成功。
提交请求持久化
TC 服务收到事务提交请求后,会先将提交信息先持久化到事务 topic 。持久化成功后,服务端就立即发送成功响应给 Producer。然后找到该事务涉及到的所有分区,为每 个分区生成提交请求,存到队列里等待发送。
读者可能有所疑问,在一般的二阶段提交中,协调者需要收到所有参与者的响应后,才能判断此事务是否成功,最后才将结果返回给客户。那如果 TC 服务在发送响应给 Producer 后,还没来及向分区发送请求就挂掉了,那么 Kafka 是如何保证事务完成。因为每次事务的信息都会持久化,所以 TC 服务挂掉重新启动后,会先从 事务 topic 加载事务信息,如果发现只有事务提交信息,却没有后来的事务完成信息,说明存在事务结果信息没有提交到分区。
发送事务结果信息给分区
后台线程会不停的从队列里,拉取请求并且发送到分区。当一个分区收到事务结果消息后,会将结果保存到分区里,并且返回成功响应到 TC服务。当 TC 服务收到所有分区的成功响应后,会持久化一条事务完成的消息到事务 topic。至此,一个完整的事务流程就完成了。
客户端原理
使用示例
下面代码实现,消费者读取消息,并且发送到多个分区的事务
// 创建 Producer 实例,并且指定 transaction id
KafkaProducer producer = createKafkaProducer(
“bootstrap.servers”, “localhost:9092”,
“transactional.id”, “my-transactional-id”);
// 初始化事务,这里会向 TC 服务申请 producer id
producer.initTransactions();
// 创建 Consumer 实例,并且订阅 topic
KafkaConsumer consumer = createKafkaConsumer(
“bootstrap.servers”, “localhost:9092”,
“group.id”, “my-group-id”,
"isolation.level","read_committed");
consumer.subscribe(singleton(“inputTopic”));
while(true) {
ConsumerRecords records = consumer.poll(Long.MAX_VALUE);
// 开始新的事务
producer.beginTransaction();
for(ConsumerRecord record : records) {
// 发送消息到分区
producer.send(producerRecord(“outputTopic_1”, record));
producer.send(producerRecord(“outputTopic_2”, record));
}
// 提交 offset
producer.sendOffsetsToTransaction(currentOffsets(consumer),"my-group-id");
// 提交事务
producer.commitTransaction();
}
运行原理
上面的例子使用了 Producer的接口实现了事务,但负责与 TC 服务通信的是 TransactionManager 类。TransactionManager 类会发送申请分配 producer id 请求,上传消息分区请求和事务提交请求,在完成每一步请求,TransactionManager 都会更新自身的状态。
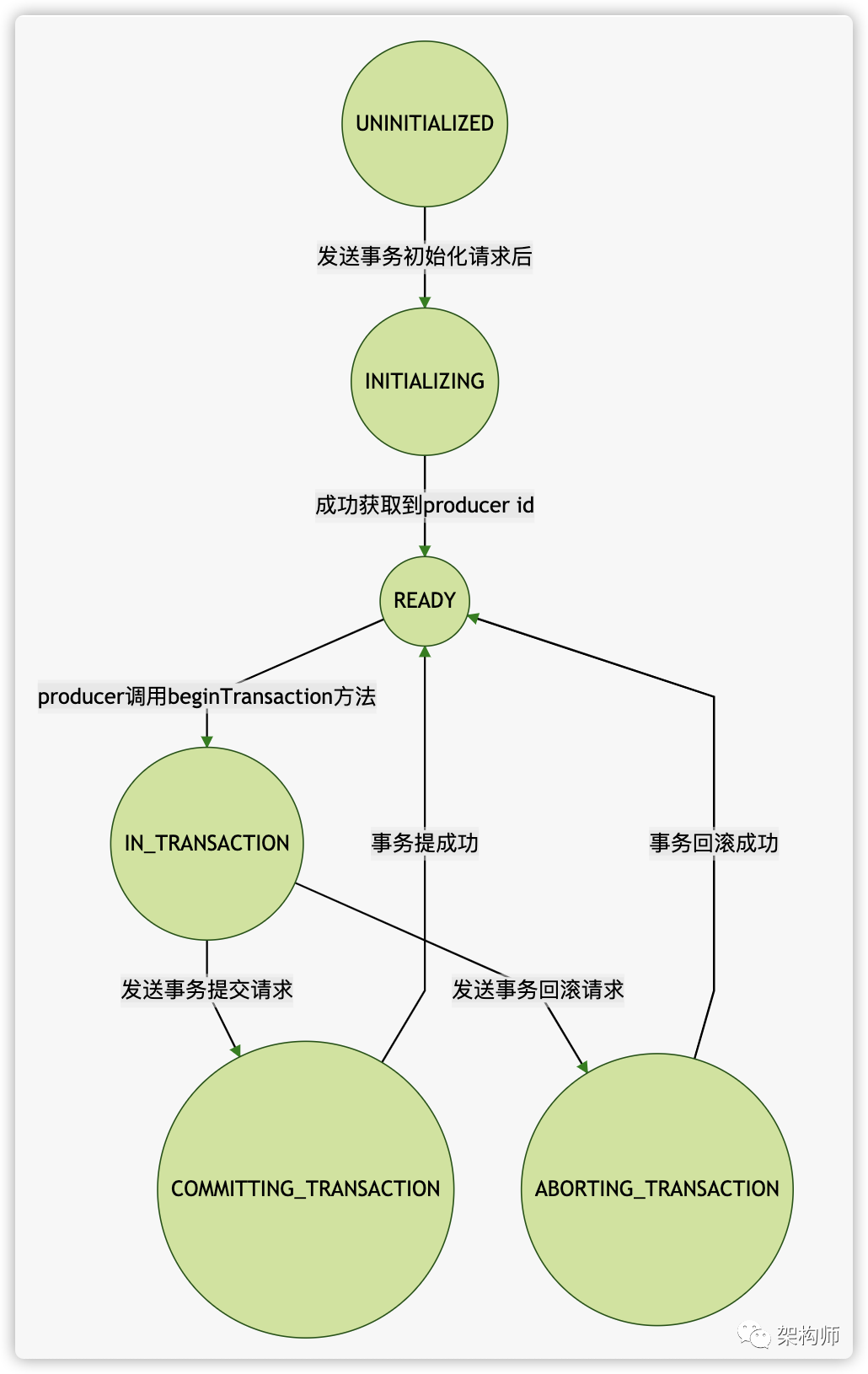
状态
privateenumState {
UNINITIALIZED,
INITIALIZING,
READY,
IN_TRANSACTION,
COMMITTING_TRANSACTION,
ABORTING_TRANSACTION,
ABORTABLE_ERROR,
FATAL_ERROR;
}
这里还有两个状态没有列出来 ABORTABLE_ERROR或FATAL_ERROR,这是当请求出错后,状态就会变为它们。
服务端原理
TC 服务会为每个 transaction id 都维护了元数据,元数据的字段如下:
classTransactionMetadata(
val transactionalId: String, // 事务 id
var producerId: Long, // pruducer id
var producerEpoch: Short, // producer epoch
var txnTimeoutMs: Int, // 事务超时时间
var state: TransactionState, // 事务当前状态
val topicPartitions: mutable.Set[TopicPartition], // 该事务涉及到的分区列表
@volatile var txnStartTimestamp: Long = -1, // 事务开始的时间
@volatile var txnLastUpdateTimestamp: Long)//事务的更新时间
对于服务端,每个事务也有对应的状态

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1385
1385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











