







这里介绍的略简单了一些,稍后会补上
K-NN
k近邻算法是一种简单但也最常用的分类算法,他也可以应用于回归计算。K-NN是无参数学习,它是基于实例并在一个有监督的学习环境中使用。
K–算法的工作原理
k-NN 用于分类是,输出是一个类别,这种方法有三个关键因素:一组标记的对象,例如:一组已存储的记录、对象之间的距离以及k的值-最近邻的数量
做出预测
若要对未标记的对象进行分类,则会计算出该对象标记的对象之间的距离,确定其k近邻点,然后使用周边数量最多的最近邻点的类标签来确定对象的类标签。对于实际中输入的变量,最常用的距离度量是欧氏距离。
距离度量
欧氏距离被计算为一个新点和一个现有点在所有输入属性上的差的平方之和的平方根。
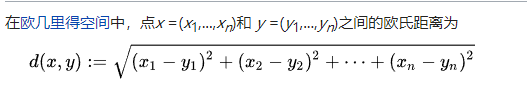
欧几里得距离 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/欧几里得距离
K的取值
求k的值并不是很容易。K值小意味着噪声会对结果产生较大的影响。而k值大则会使计算成本变高。
#导入相关库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#导入数据集
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:,[2,3]].values
y = dataset.iloc[:, 4].values
#将数据划分成训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.25,random_state = 0)
#特征缩放
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
#使用K-NN对训练集数据进行训练
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=5,metric='minkowski',p = 2)
classifier.fit(X_train,y_train)
#对测试集进行预测
y_pred = classifier.predict(X_test)
#生成混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









