







 本文介绍一种从TXT文件中仅读取最后一行的16进制数据,并将其转换为bytes类型的方法。通过调整文件指针位置,确保能够正确读取任意长度文件的最后一行内容。
本文介绍一种从TXT文件中仅读取最后一行的16进制数据,并将其转换为bytes类型的方法。通过调整文件指针位置,确保能够正确读取任意长度文件的最后一行内容。
目录
一、数据源
1. TXT文本名称
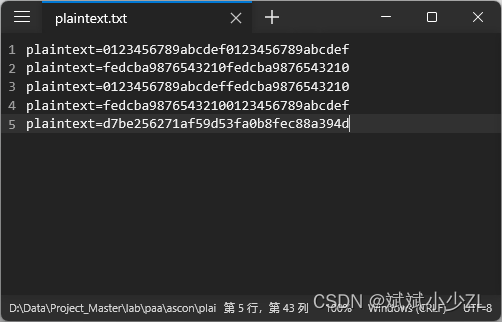
plaintext.txt
2. TXT文本内容
plaintext=0123456789abcdef0123456789abcdef
plaintext=fedcba9876543210fedcba9876543210
plaintext=0123456789abcdeffedcba9876543210
plaintext=fedcba98765432100123456789abcdef
plaintext=d7be256271af59d53fa0b8fec88a394d
- 文本内容以5行示例。实际可能会有很多行,百万乃至1亿行。
- “plaintext=”是以字符串存储的提示信息。
- “0123456789abcdef0123456789abcdef”等数据是以字符串存储的,指示16进制数据。
二、处理需求
- 只读取文本的最后一行(末行)。
- 将末行的非数据和数据分隔开,只要数据部分。
- 将string类型的“d7be256271af59d53fa0b8fec88a394d”转换成bytes类型的[0xd7, 0xbe, 0x25, 0x62, 0x71, 0xaf, 0x59, 0xd5, 0x3f, 0xa0, 0xb8, 0xfe, 0xc8, 0x8a, 0x39, 0x4d]。
三、完整代码
def fileRead(filePath):
# 打开文件, ‘rb’不可忽略
fileName = open(filePath[0], 'rb')
# 文件指针移动到末行行首之前,否则末行读取不完整
# 尝试将文件指针从文件尾部向前移动100个字节
# 若指针移动超过文件总大小,则自动调整并匹配
seek = 100
while True:
try:
fileName.seek(-seek, 2)
break
except:
seek -= 1
# 读取文件指针之后的全部行,取末行到endLine变量中,string类型
endLine = str(fileName.readlines()[-1])
# 将非数字部分和数据部分分隔开
[name, strLine] = endLine.split(sep='=')
# 删除数字部分中不可转换的内容
# 可print出strLine变量看看需要删除哪些字符
strLine = strLine.replace('\\n', '')
# 将字符串形式的16进制,转换成bytes形式的16进制
hexData = bytes(bytearray.fromhex(strLine))
# 返回处理结果
return hexData
if __name__ == '__main__':
# 文件路径相对和绝对均可
filePath = ['plaintext.txt']
# 获取文件末行bytes类型数据
fileData = fileRead(filePath)
# 处理结果展示
print("fileData type is {} ".format(type(fileData)))
print("fileData info is {} ".format(fileData))
print("fileData hex is {} ".format(fileData.hex()))
- 经验证,获取文件末行的功能对于CSV表格文件也同样适用
四、结果输出
fileData type is <class 'bytes'>
fileData info is b'\xd7\xbe%bq\xafY\xd5?\xa0\xb8\xfe\xc8\x8a9M'
fileData hex is d7be256271af59d53fa0b8fec88a394d
五、扩展部分
1. 多文件操作
上述代码为对单TXT文件进行操作,对多文件进行第二章所要求的操作呢?
同理,其它文件的内容类似于 图1-1 所示,若干行组成,每行由单词、等号、16进制数组成。
- 下面给出对多文件进行操作的代码,有命令行参数传入的功能。该python脚本命名为run.py
import argparse
def fileRead(filePath):
fileNum = len(filePath)
hexList = [bytes([])]*fileNum
for i in range(fileNum):
# 打开文件, ‘rb’不可忽略
fileName = open(filePath[i], 'rb')
# 文件指针移动到末行行首之前,否则末行读取不完整
# 尝试将文件指针从文件尾部向前移动100个字节
# 若指针移动超过文件总大小,则自动调整并匹配
seek = 100
while True:
try:
fileName.seek(-seek, 2)
break
except:
seek -= 1
# 读取文件指针之后的全部行,取末行到endLine变量中,string类型
endLine = str(fileName.readlines()[-1])
# 将非数字部分和数据部分分隔开
[name, strLine] = endLine.split(sep='=')
# 删除数字部分中不可转换的内容
# 可print出strLine变量看看需要删除哪些字符
strLine = strLine.replace('\\n', '')
# 将字符串形式的16进制,转换成bytes形式的16进制
hexList[i] = bytes(bytearray.fromhex(strLine))
return hexList
if __name__ == '__main__':
# 设置参数选项
parser = argparse.ArgumentParser(description='可描述该脚本的用途,可以为空')
parser.add_argument('-k', dest='keyPath', type=str, help='key input file', default=True)
parser.add_argument('-n', dest='noncePath', type=str, help='nonce input file', default=True)
parser.add_argument('-p', dest='plaintextPath', type=str, help='plaintext input file', default=True)
parser.add_argument('-c', dest='ciphertextPath', type=str, help='ciphertext check file', default=True)
parser.add_argument('-t', dest='ciphertagPath', type=str, help='ciphertag check file', default=True)
args = parser.parse_args(sys.argv[1:])
# 文件路径相对和绝对均可
filePath = [args.keyPath,
args.noncePath,
args.plaintextPath,
args.ciphertextPath,
args.ciphertagPath]
# 获取文件末行bytes类型数据, fileData为列表类型,列表中单个元素为bytes类型
fileData = fileRead(filePath)
- 脚本使用方法
python run.py -k ./key.txt \
-n ./nonce.txt \
-p ./plaintext.txt \
-c ./ciphertext.txt \
-t ./ciphertag.txt
2. 更换需求
- 将string类型的“1101010110110100”转换成bytes类型的[0xd5, 0xb4]。
strLine = '1101010110110100'
hexList = bytes([])
for i in range(0, len(strLine), 8):
hexList += bytes([int(strLine[i:i+8], 2)])
print(hexList.hex())
# 打印结果:
# d5b4


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











