









使用 FireFox 作为实例。
抓取的首页为电子工业出版社网站(http://www.phei.com.cn/)。
了解 Selenium 能做什么
像 Requests 一样,抓取网页的源代码。Selenium 模拟了浏览器的行为,我们甚至可以更细粒度地控制浏览器的行为。
代码如下:
实现的功能为:让程序自动打开浏览器下载网页的源代码,保存到一个文件,然后关闭浏览器。
# 利用 webdriver 可以初始化各种浏览器
from selenium import webdriver
import time
# 初始化一个 Firefox 浏览器用于抓取的实施
firefox = webdriver.Firefox()
url = 'http://www.phei.com.cn/'
# 调用 get 方法抓取
firefox.get(url)
# 抓取的页面完全加载以后,会有 10s 的等待时间用于观察
time.sleep(10) # 以秒为单位
with open('phei.html', 'w', encoding='utf8') as fw:
# page_source 属性存储的是页面加载以后的 HTML 文本
fw.write(firefox.page_source)
# 调用 quit() 方法退出浏览器
firefox.quit()注意:
1、这里要下载 mozilla/geckodriver
网址:https://github.com/mozilla/geckodriver/releases
2、解压后将 geckodriver 存放至 /usr/local/bin/ 路径下即可
示例代码:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
3、打开文件的时候 encoding='utf8' 要添加上
通过修改首选项参数来改变浏览器行为。
在火狐浏览器中输入:about:config
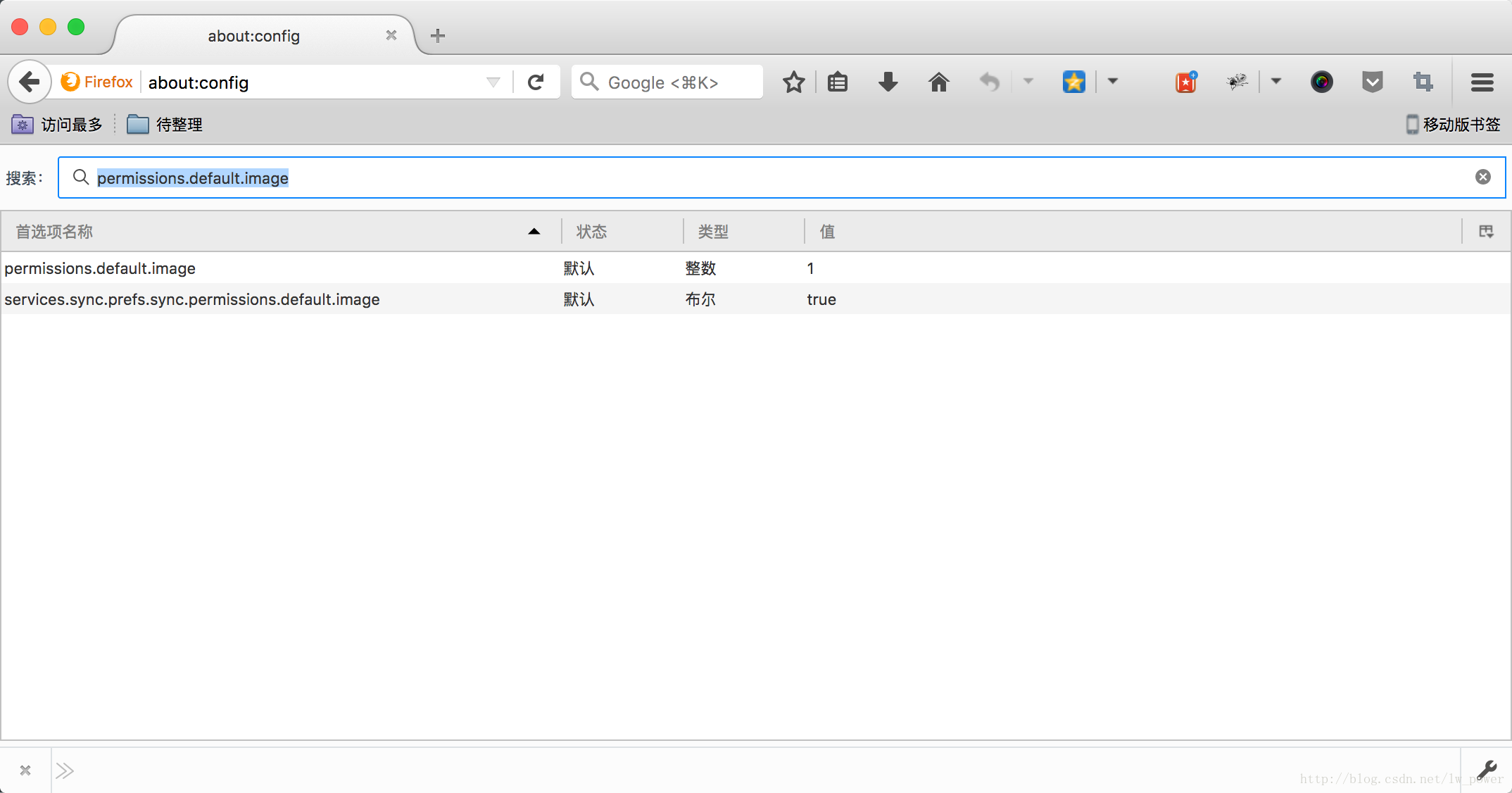
将 permissions.default.image 将这个值改为 2。这样,再点网站就看不到图了。
但是,这是通过手动调整浏览器,设置相关参数的方法来改变浏览器的行为。
那么,我们如何通过编程来达到同样的效果呢?
通过编程设置相关参数以改变浏览器行为的方法
Selenium 提供了可以通过编程设置相关参数以改变浏览器行为的方法。
1、限制浏览器加载 CSS
2、禁止执行 Javascript
3、禁止图片下载和显示
示例代码:
from selenium import webdriver
import time
# 初始化一个 FirefoxProfile 的实例 FirefoxProfile
firefox_profile = webdriver.FirefoxProfile()
# 禁用样式表文件
firefox_profile.set_preference("permissions.default.stylesheet", 2)
# 不下载和加载图片
firefox_profile.set_preference("permissions.default.image", 2)
# 禁止 Javascript 的执行
firefox_profile.set_preference("javascript.enabled", False)
firefox_profile.update_preferences()
firefox = webdriver.Firefox(firefox_profile)
url = 'http://www.phei.com.cn/'
print('start load')
t_start = time.time()
firefox.get(url)
t_end = time.time()
print('loading time is:', t_end - t_start)
print("+" * 20)
# 抓取的页面完全加载以后,会有 10s 的等待时间用于观察
time.sleep(10) # 以秒为单位
# 调用 quit() 方法退出浏览器
firefox.quit()控制台输出:
start load
loading time is: 0.5872759819030762
++++++++++++++++++++
注意:这里的 0.5872759819030762 这个时间的单位是秒。
注意:关闭 Javascript 的代码执行以后,flash 也相应地消失了。
from selenium import webdriver
import time
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# n 实验次数
# css_val:数据类型为整形,1 代表正常处理 css,2 代表禁用 css
# image_val:数据类型为整形:1 代表正常处理图片,2 代表禁用图片
# js_flag:数据类型为布尔型,True 代表正常处理 Javascript 脚本,2 代表禁用 Javascript 脚本
def performance(n, css_val, image_val, js_flag):
loading_time = []
for i in range(0, n):
firefox_profile = webdriver.FirefoxProfile()
firefox_profile.set_preference("permissions.default.stylesheet", css_val)
firefox_profile.set_preference("permissions.default.image", image_val)
firefox_profile.set_preference("javascript.enabled", js_flag)
firefox_profile.update_preferences()
# 利用参数化配置文件初始化 Firefox 浏览器
firefox = webdriver.Firefox(firefox_profile)
url = 'http://www.phei.com.cn/'
print('start load')
t_start = time.time()
firefox.get(url)
t_end = time.time()
loading_time.append(t_end - t_start)
print('loading time is:', t_end - t_start)
print("+" * 20)
firefox.quit()
# 返回了两个列表
# 第 1 个列表其实就是 [1,2,...,n]
# 第 2 个列表中的元素依次分别对应每次实验页面加载完毕的时间
# 前者是横轴的数据
# 后者是纵轴的数据
return [x for x in range(1, n + 1)], loading_time
if __name__ == '__main__':
# CSS、图片和 Javascript 正常处理
x1_lst, y1_lst = performance(10, 1, 1, True)
# CSS、图片和 Javascript 全部禁用
x2_lst, y2_lst = performance(10, 2, 2, False)
ava_y1 = sum(y1_lst) / len(x1_lst)
ava_y2 = sum(y2_lst) / len(x2_lst)
plt.title(u"Compare loading time.")
plt.xlabel(u"Test number")
plt.ylabel(u"Loading time")
# 'go:' 是图线的展示方式:'g' 表示 green,'o' 是结点的形状,为圆形
# ':' 是节点的展示方式,以虚线连接
plt.plot(x1_lst, y1_lst, 'go:', label=str(ava_y1))
# 'rs:' 是图线的展示方式:'r' 表示 red,'s' 是结点的形状,为方形
# ':' 是节点的展示方式,以虚线连接
plt.plot(x2_lst, y2_lst, 'rs:', label=str(ava_y2))
# 上面两行中设置的 label ,需要下面这个语句才能正确显示
plt.legend()
plt.show()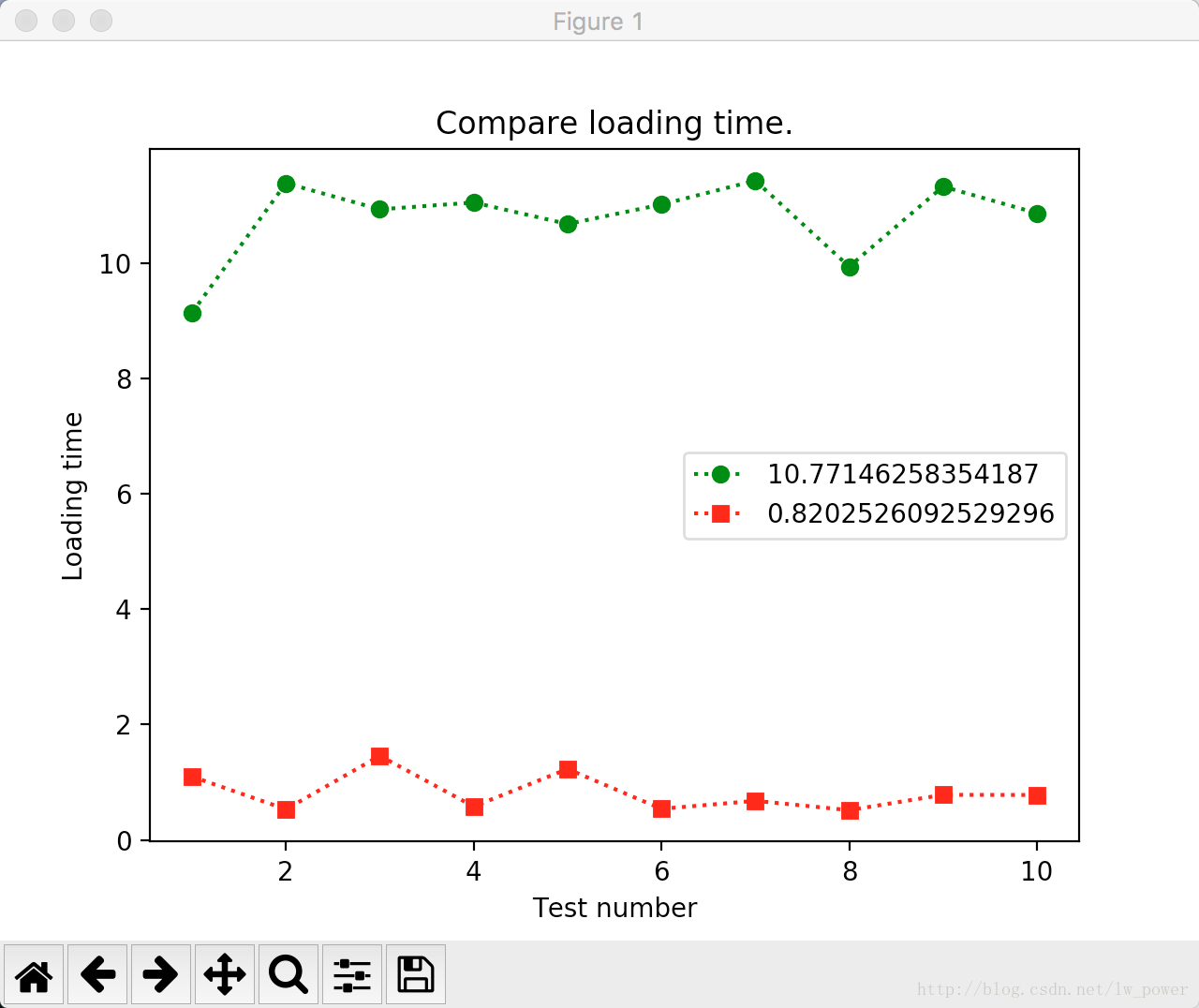
接下来,我们结合 BeautifulSoup 来实现网页的爬取。
结合 BeautifulSoup 实现网页的爬取
安装 BeautifulSoup
pip install bs4
from selenium import webdriver
from bs4 import BeautifulSoup
import time
def get_info(html):
bs = BeautifulSoup(html)
tables_lst = bs.find_all('table', attrs={'class', 'tsflxin'})
a_lst = tables_lst[0].find_all('a')
for a in a_lst:
print(a.text)
firefox_profile = webdriver.FirefoxProfile()
firefox_profile.set_preference("permissions.default.stylesheet", 2)
firefox_profile.set_preference("permissions.default.image", 2)
firefox_profile.set_preference("javascript.enabled", True)
firefox_profile.update_preferences()
# 利用参数化配置文件初始化 Firefox 浏览器
firefox = webdriver.Firefox(firefox_profile)
url = 'http://www.phei.com.cn/'
print('start load')
t_start = time.time()
firefox.get(url)
t_end = time.time()
print('loading time is:', t_end - t_start)
print("+" * 20)
get_info(firefox.page_source)
time.sleep(10)
firefox.quit()














 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









