







1.mysql索引 的基本定义
- 索引也是一张表,该表保存了主键和索引字段,并指向真正的表。正确适合的索引可以加快查询结果的速度。
2.索引的分类
- 普通索引,仅加快查询速度,没有任何限制,是我们常用的索引。
- 唯一索引,与普通索引不同的是,它的列字段是唯一的。
- 全文索引,仅MyISAM引擎可以建立全文索引,只有char、varchar、text类型可以建立全文索引,5.6版本之后innoDB引擎支持全文索引,5.7版本之后通过通过ngram插件支持中文全文索引。
- 组合索引
这样看起来,这个索引的分类意义何在,跟普通索引作用没什么不同?比如说全文索引的特点,使用场景?
全文索引一般用在检索文章,唯一索引是唯一不允许重复。
索引从种类上分,又分为聚集索引和非聚集索引:
- 聚集索引
聚集索引好比就是字典中按照字母顺序来检索,a开头的汉字都在a目录中,b开头的汉字在b目录中…我们按照字母检索的时候就是有一定顺序的。 - 非聚集索引
非聚集索引好比就是这个字典根据笔画来检索,根据笔画来检索的话,它的目录不是按照笔画来排序的,所以查找的时候是无序的。
3.索引的优缺点
- 优点
索引是由数据库中的一行或者多行组成,索引可以加快查询速度。 - 缺点
索引的创建和维护需要耗费资源和时间,索引固然可以加快查询速度,但是同时在inset into 和 update的时候可能会重构索引,所以减慢插入和更新的速度。
索引一般不要太多,最多6个。
4.索引的设计原则

建立索引的原则:
-
定义主键的数据列一定要建立索引。
-
定义有外键的数据列一定要建立索引。
-
对于经常查询的数据列最好建立索引。
-
对于需要在指定范围内的快速或频繁查询的数据列;
-
经常用在WHERE子句中的数据列。
-
经常出现在关键字order by、group by、distinct后面的字段,建立索引。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用。
-
对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
-
对于定义为text、image和bit的数据类型的列不要建立索引。
-
对于经常存取的列避免建立索引
-
限制表上的索引数目。对一个存在大量更新操作的表,所建索引的数目一般不要超过3个,最多不要超过5个。索引虽说提高了访问速度,但太多索引会影响数据的更新操作。
-
对复合索引,按照字段在查询条件中出现的频度建立索引。在复合索引中,记录首先按照第一个字段排序。对于在第一个字段上取值相同的记录,系统再按照第二个字段的取值排序,以此类推。因此只有复合索引的第一个字段出现在查询条件中,该索引才可能被使用,因此将应用频度高的字段,放置在复合索引的前面,会使系统最大可能地使用此索引,发挥索引的作用。
5.索引的实现原理(为什么索引能加快查询速度)
索引可以加快查询速度,索引是根据索引的字段+主键建立一个表,指向原表。存储索引数据一般使用的是b-、b+树结构,结果图如下

其中磁盘块1,2,3,4代表4个磁盘块,如磁盘块1中包含数据项17和35,包含指针P1,P2,P3.数据项17,35是虚拟的数据项代表小于17的数据项和大于35的数据项,真正的数据都在叶子节点。P1,P2,P3指针分别指向子节点。在没有索引的查询中,需要遍历全表的数据项一遍,根据查询条件符合要求的就放入查询结果中,复杂度是o(n)。而在有索引的查询中,只需要查询这个索引的数的高度h次,复杂度是o(log2 n);n一定的情况下,当每个磁盘块存放的数据项越多,那么树的高度也就越低,需要查询的次数越少。
图中有14条数据,每个磁盘块存放的数据是2,计算树的高度的方式是log (2+1)14 = h,3h=14,h->3
6.关于索引的一些补充
a)在使用like的时候,如果使用‘%%’,会不会用到索引呢
explain select * from record where date like ‘%2019-07-01’
关于使用like的时候会不会用到索引,经测试发现:
通过EXPLAIN SELECT * FROM user WHERE username LIKE ‘%ptd_%’;的方式可以查看是否使用索引,
 图1
图1
 图2
图2
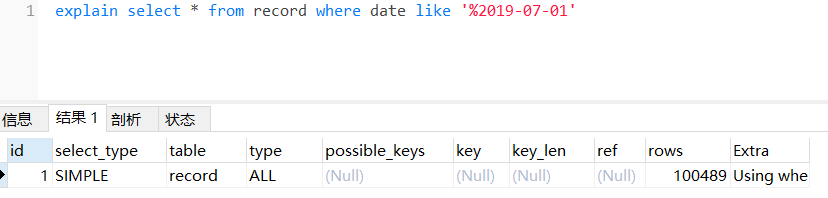 图3
图3
从上面三张图片可以看出,只有在第一种情况下是使用了索引“dt”的,其他情况都没有使用。
b)索引的四种类型fulltext(全文索引)、normal(普通)、spatial(组合)、unique(唯一)
c)索引的存储方式b tree 、hash,现在索引的一般存储方式都是b-树b+树数据结构















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









