






验证码识别
目前大部分验证码都是文字的序列,因此现有的识别方法,大都来自OCR(光学字符识别)的技术。 OCR用于印刷体扫描后文字的识别,一般分为三个步骤:
1、预处理
因为有些印刷文字会存在字迹不清、污点、颜色不统一等问题,所以在最开始都要对图像进行预处理。这些处理包括边缘检测、二值化等操作。边缘检测就是根据颜色和图形的特征,检测出一个文字的边缘,这样就可以得到文字的轮廓。而二值化就是将图片变成黑白的,有些验证码将背景和文字变为不同颜色,实际上在这一步会被识别出来。如果验证码的设计要增加预处理的难度,就需要增加更大的噪点、使用色彩渐变等方式使文字更加难以分辨,但是这样做也同时增加了人识别的难度。而这部分来说,计算机和人的识别能力差不多,甚至要优于人的识别力。所以在这方面做的工作效果并不好。
2、字符分割
我们人类阅读经常说“一目十行”,但是计算机识别大段的文字,却只能按照一个一个文字进行识别。字符分割就是将文字拆分成一个个的字符,以便于单独进行识别的过程。为什么要这么做呢?这要从OCR的核心:图像识别技术说起。
图像识别 的基本原理都是一样的:给计算机一个图像集合A,告诉计算机这些图像分别对应的含义,等它“学懂”后,然后再让它去判断新的图像b,跟集合A中的哪个图像(或者哪类图像)更相似,再借此判断它的含义。这个过程又有个很形象的名字叫“机器学习”。在机器学习的术语里,集合A称为“训练集(training set)”,A的含义叫做“标记(label)”,学习的过程叫做“训练(training)”,推断A的含义的过程叫做“分类(classify)”或者“标注(labeling)”,而把图像转化成计算机能理解的过程叫做“特征提取(feature extract)”。
这个过程有个很大的问题,在于训练集的规模。 计算机的存储能力是很强的,推理能力却是很弱的,给它一个"abcd"组合的图片,告诉它"这是abcd",如果算法足够强大,它以后能够识别出所有"abcd"组合的图片,但是它绝无可能识别出一个"acbd"组合的图片。这种情况下,如果要识别“acbd”,那么必须再设计一套"acbd"组合的图片。如果是6位的验证码,每位由大小写和数字组成,那么一共有(26*2+10)^62=56,800,235,584种可能,就需要设计这么多种图片让计算机去学习。这显然是难以实现的。还有一种做法是将图片拆开,拆成一个个小区域,一次只识别一个字母,这样每个区域需要识别的类型就大大减少。仍以验证码为例,此时仅需要52张图片作为训练即可。
所以,字符分割可以大大降低验证码识别的难度。字符分割方面用到的技术更多,不过在这方面,人却比计算机有较大的优势。目前一种较安全的验证码设计方式就是直接在所有字母中加一条横线,对人类阅读几乎无影响,对计算机切分就比较困难了。还有一种做法是将所有字母变化并重合在一起,这样也能起到难以分割的效果。
 横线分割的验证码
横线分割的验证码
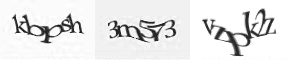 扭曲的验证码
扭曲的验证码
3、字符识别
字符识别使用的就是上面说到的图像识别方法。只要切分成功,那么图像识别的任务就是识别一个区域的图像对应的字母。很多验证码技术都对字母进行了变形,最常见的就是扭曲。但是破解者同样可以将扭曲后的文字作为训练集交给计算机。假设一种文字有100种扭曲方法,那么实际上也只有6200种情况需要计算机来判断,这实在是小菜一碟。















 5402
5402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









