









解析(Parsing-general)
既然解析是渲染引擎中一个非常重要的过程,我们将稍微深入的研究它。首先简要介绍一下解析。解析一个文档即将其转换为具有一定意义的结构——编码可以理解和使用的东西。你想啊!HTML是一个纯文本的东西,计算机要怎么理解了?所以需要解析文档文档内容了嘛!所以HTML代码要遵守W3C的规范嘛!没有规则的东西是解析不了的,你说是不是!解析的结果通常是表达文档结构的节点树,称为解析树或语法树。例如,解析“2+3-1”这个表达式,可能返回这样一棵树。

图5:数学表达式树节点
语法(Grammars)
解析基于文档依据的语法规则——文档的语言或格式。每种可被解析的格式必须具有由词汇及语法规则组成的特定的文法,所以HTML也是有语法规则的,按照语法规则来解析。解析器-词法分析器(Parser-Lexer combination)
解析可以分为两个子过程——语法分析及词法分析
词法分析就是将输入分解为符号,符号是语言的词汇表——基本有效单元的集合。对于人类语言来说,它相当于我们字典中出现的所有单词。
语法分析指对语言应用语法规则。
解析器一般将工作分配给两个组件——词法分析器(有时也叫分词器)负责将输入分解为合法的符号,解析器则根据语言的语法规则分析文档结构,从而构建解析树,词法分析器知道怎么跳过空白和换行之类的无关字符。

图6:从源文档到解析树
转换(Translation)
很多时候,解析树并不是最终结果。解析一般在转换中使用——将输入文档转换为另一种格式。编译就是个例子,编译器在将一段源码编译为机器码的时候,先将源码解析为解析树,然后将该树转换为一个机器码文档。
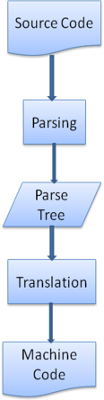
图7:编译流程
解析实例Parsing example
图5中,我们从一个数学表达式构建了一个解析树,这里定义一个简单的数学语言来看下解析过程。
词汇表:我们的语言包括整数、加号及减号。
语法:
1. 该语言的语法基本单元包括表达式、term及操作符
2. 该语言可以包括多个表达式
3. 一个表达式定义为两个term通过一个操作符连接
4. 操作符可以是加号或减号
5. term可以是一个整数或一个表达式
现在来分析一下“2+3-1”这个输入
第一个匹配规则的子字符串是“2”,根据规则5,它是一个term,第二个匹配的是“2+3”,它符合第2条规则——一个操作符连接两个term,下一次匹配发生在输入的结束处。“2+3-1”是一个表达式,因为我们已经知道“2+3”是一个term,所以我们有了一个term紧跟着一个操作符及另一个term。“2++”将不会匹配任何规则,因此是一个无效输入。
词汇表及语法的定义
词汇表通常利用正则表达式来定义。
例如上面的语言可以定义为:
INTEGER:0|[1-9][0-9]*
PLUS:+
MINUS:-
正如看到的,这里用正则表达式定义整数。
语法通常用BNF格式定义,我们的语言可以定义为:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
如果一个语言的文法是上下文无关的,则它可以用正则解析器来解析。对上下文无关文法的一个直观的定义是,该文法可以用BNF来完整的表达。
解析器类型(Types of parsers)
有两种基本的解析器——自顶向下解析及自底向上解析。比较直观的解释是,自顶向下解析,查看语法的最高层结构并试着匹配其中一个;自底向上解析则从输入开始,逐步将其转换为语法规则,从底层规则开始直到匹配高层规则。
来看一下这两种解析器如何解析上面的例子:
自顶向下解析器从最高层规则开始——它先识别出“2+3“,将其视为一个表达式,然后识别出”2+3-1“为一个表达式(识别表达式的过程中匹配了其他规则,但出发点是最高层规则)。
自底向上解析会扫描输入直到匹配了一条规则,然后用该规则取代匹配的输入,直到解析完所有输入。部分匹配的表达式被放置在解析堆栈中。
| Stack | Input |
| 2 + 3 – 1 | |
| term | + 3 - 1 |
| term operation | 3 – 1 |
| expression | - 1 |
| expression operation | 1 |
| expression |
自底向上解析器称为shift reduce解析器,因为输入向右移动(想象一个指针首先指向输入开始处,并向右移动),并逐渐简化为语法规则。
自动化解析(Generating parsers automatically)
解析器生成器这个工具可以自动生成解析器,只需要指定语言的文法——词汇表及语法规则,它就可以生成一个解析器。创建一个解析器需要对解析有深入的理解,而且手动的创建一个有较好性能的解析器并不容易,所以解析生成器很有用。Webkit使用两个知名的解析生成器——用于创建语法分析器的Flex及创建解析器的Bison(你可能接触过Lex和Yacc)。Flex的输入是一个包含了符号定义的正则表达式,Bison的输入是用BNF格式表示的语法规则。
------------------------------------------------下一章节将讲解,html解析器------------------------------------------------
















 1847
1847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











