







1.exists和in
我们区分in和exists主要是驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系
如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in,反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。
2.merge into
create table test1(eid number(10), name varchar2(20),birth varchar(255),salary number(8,2));
insert into test1 values (1001, '张三', '2015-1-8', 2300);
insert into test1 values (1002, '李四', '2013-1-18', 6600);
select * from test1;
create table test2(eid number(10), name varchar2(20),birth varchar(255),salary number(8,2));
select * from test2;
merge into test2
using test1
on (test1.eid = test2.eid)
when matched then
update set name = test1.name, birth = test1.birth, salary = test1.salary
when not matched then
insert
(eid, name, birth, salary)
values
(test1.eid, test1.name, test1.birth, test1.salary);3.参照完整性约束foreign key
建立如下两张表
CREATE TABLE person
(
pid NUMBER primary key,
name VARCHAR(30) NOT NULL ,
tel VARCHAR(50) ,
age NUMBER
) ;
CREATE TABLE book
(
bid NUMBER ,
name VARCHAR(50) ,
pid NUMBER REFERENCES person(pid) ON DELETE CASCADE
) ;
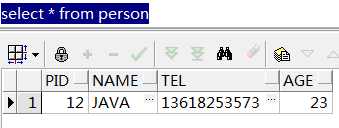
参照完整性约束要求:如果某个字段是外键 那么该值要么为空 要么在主键表中 有对应的主键值
所以往book中插入的数据pid要么是12,要么为null
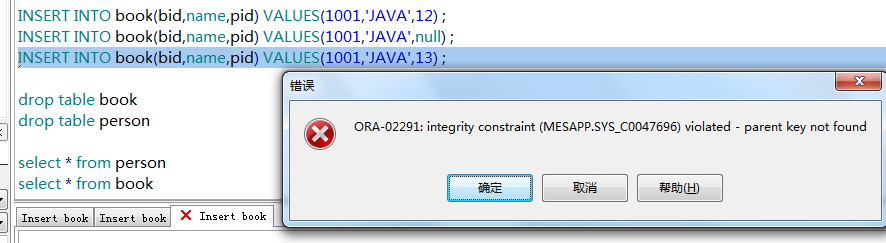
可见,当插入的pid为13时报错
4.视图View
视图的数据来源于基础表,修改视图的数据当然就会修改基础表,建议不要修改视图数据,要修改数据直接在基础表修改。 如果要把视图设置成只读,后面加上With READ ONLY
5.索引
建立索引的优点
1.大大加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
4.在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
索引的缺点
1.索引需要占物理空间。
2.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
索引的创建和效率
create index abc on student(sid,sname);
create index abc1 on student(sname,sid);
这两种索引方式是不一样的
索引abc对Select * from student where sid=1; 这样的查询语句更有效
索引abc1对Select * from student where sname=‟louis‟; 这样的查询语句更有效
另外,如果经常查询x=?和y=?,那推荐使用组合index(x,y),这种情况下组合索引的效率是远高于两个单独的索引的。
6.SQL优化
SQL优化的实质就是在结果正确的前提下,用优化器可以识别的语句,充份利用索引,执行过程中访问尽量少的数据块,减少表扫描的I/O次数,尽量避免全表扫描和其他额外开销。
1.正确使用exist和in(本文第一点有说明)
2.尽量用NOT EXISTS或者外连接替代NOT IN操作符,因为NOT IN不能应用表的索引
3.尽量不用“<>”或者“!=”操作符,不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描。比如:a<>0 改为 a>0 or a<0
4.在设计表时,把索引列设置为NOT NULL,判断字段是否为空一般是不会应用索引的,因为B树索引是不索引空值的。
5.尽量不用通配符“%”或者“_”作为查询字符串的第一个字符。当通配符“%”或者“_”作为查询字符串的第一个字符时,索引不会被使用。比如用T表中Column1 LIKE "%5400%‟ 这个条件会产生全表扫描,如果改成Column1 ‟X5400%‟ OR Column1 LIKE ‟B5400%‟ 则会利用Column1的索引进行两个范围的查询,性能肯定大大提高。
6.WHERE后面的条件顺序要求,WHERE后面的条件,表连接语句写在最前,可以过滤掉最大数量记录的条件居后。
7.使用表的别名,并将之作为每列的前缀,这样可以减少解析时间
8.如果数据本身重复行存在可能性较小时,用union all会比用union效率高很多!
9.尽量使用cached sequences 来生成primary key :提高主键生成速度和使用性能。
10.很好地利用空间:如用VARCHAR2 数据类型代替CHAR等
7.序列SEQUENCE
CREATE SEQUENCE numberIndex
START WITH 1 -- 从1开始计数
INCREMENT BY 10-- 每次加几个
MAXvalue 50-- 不设置最大值NOMaxvalue
CYCLE<span style="white-space:pre"> </span>--NOCYCLE
NOCache;--NOCache8.PLSQL代码块
------------------declare if-else
DECLARE
SCORE DECIMAL;
BEGIN
SCORE := 75;
IF (SCORE < 60) THEN
DBMS_OUTPUT.PUT_LINE('及格');
ELSE
DBMS_OUTPUT.PUT_LINE('不及格');
END IF;
END;
------------------declare case-when
DECLARE
SCORE INTEGER;
BEGIN
SCORE := TRUNC(DBMS_RANDOM.VALUE(0, 100));
CASE
WHEN SCORE < 60 THEN
DBMS_OUTPUT.PUT_LINE('及格');
ELSE
DBMS_OUTPUT.PUT_LINE('不及格');
END CASE;
END;
----------------while
DECLARE
T INTEGER;
BEGIN
T := 0;
WHILE T < 5 LOOP
DBMS_OUTPUT.PUT_LINE(T);
T := T + 1;
END LOOP;
END;也可以选择手动输入
T := &en;
9.游标
create table emp(
empno integer,
ename varchar2(20)
);
insert into emp values(1, 'll');
insert into emp values(2, 'mm');DECLARE
CURSOR mycur IS SELECT * FROM emp;
empInfo emp%ROWTYPE;
BEGIN -- 游标操作使用循环,但是在操作之前必须先将游标打开
FOR empInfo IN mycur LOOP
DBMS_OUTPUT.put_line('雇员编号:' || empInfo.empno);
DBMS_OUTPUT.put_line('雇员姓名:' || empInfo.ename);
END LOOP;
END;














 1917
1917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









