







Kafka Streaming
Kafka Streaming简介
官方文档:https://kafka.apache.org/20/documentation/streams/
Kafka Streaming是基于Kafka的轻量级实时处理API,可以从一个topic中接收数据,进行简单处理后,导入另外一个topic中
Kafka Streaming最简单的拓扑结构:
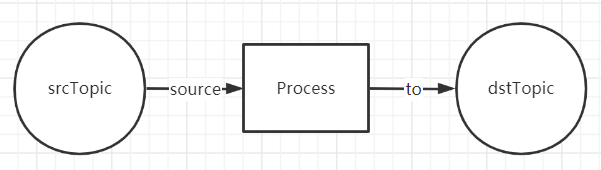
从一个topic中读取数据,经过处理操作后,写入到另一个topic中
读取数据后,可以获得一个KStream对象,该对象包含了对数据集合的处理方法(类似与SparkRDD)
可以定义多个数据源或者多个写出topic,组成更加复杂的拓扑结构:


简单案例
首先新建maven项目,并导入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.0.0</version>
</dependency>
</dependencies>
下面定义一个简单的Kafka案例,将topicin中的数据直接导出到topicout中,演示KafkaStreaming编程基本流程
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class MyStreamDemo {
public static void main(String[] args) {
// 创建Properties对象,配置Kafka Streaming配置项
Properties prop = new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "demo"); // 配置任务名称
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "num01:9092"); // 配置Kafka主机IP和端口
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); // 配置Key值类型
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); // 配置Value值类型
// 创建流构造器
StreamsBuilder builder = new StreamsBuilder();
// 用构造好的builder将in 数据写入到 out
builder.stream("in").to("out");
// 构建 Topology 结构
Topology topology = builder.build();
final KafkaStreams kafkaStreams = new KafkaStreams(topology, prop);
// 固定的启动方式(这里就不介绍其他的启动方式了)
CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream") {
@Override
public void run() {
kafkaStreams.close();
latch.countDown();
}
});
kafkaStreams.start();
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
}
接下来启动程序,代码没有错误的话程序会进入等待状态,这是我们启动Kafka向in中写入数据,同时打开out消费数据来测试效果

可以看到,在in中生产的数据,成功发送到了out中
接下来实现一个计算数字总和的需求,及在一个topic中传入数值,另外一个topic中可得到累计的数值总和
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class SumStreamDemo {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "sum");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "num01:9092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 3000);
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
builder.stream("sumIn") // 从sumin主题获取数据
.map((key, value) -> new KeyValue<>("sum", value.toString())) // 因为上面指定的是String类型的value值,所以将数值转为String类型
.groupByKey()
.reduce((value1, value2) -> { // 数值相加功能,顺带输出下中间计算的结果,逻辑和spark的reduce功能完全相同
int sum = Integer.valueOf(value1) + Integer.valueOf(value2);
System.out.println(Integer.valueOf(value1) + "+" + Integer.valueOf(value2) + " = " + sum);
return Integer.toString(sum);
})
.toStream().to("sumOut"); // 重新转为stream后输出到sumout主题
Topology topology = builder.build();
final KafkaStreams kafkaStreams = new KafkaStreams(topology, prop);
CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream") {
@Override
public void run() {
kafkaStreams.close();
latch.countDown();
}
});
kafkaStreams.start();
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
}
接下来启动程序,待程序进入等待状态后,分别启动sumIn和sumOut主题用来传入数值和测试结果(左侧窗口生产消息,右上消费sumIn,右下消费sumOut):

这里要注意:从sumIn转入sumOut的中间值并不是保存在topic中,而是和application关联的。这里可以做个测试,我们将上面的sumIn和sumOut主题删除,并创建一组新的主题inSum和outSum,上面的代码中将对应的topic名字修改下,重新测试:

可以看到,虽然使用了新创建的主题,但是总和并不是从0开始计算的,而是从上次最后一个结果28的基础上继续求和的。
如果想要重新开始求和,就必须修改Consumer组:配置项里面的StreamsConfig.APPLICATION_ID_CONFIG对应的value修改一个名字就可以了(修改ConsumerConfig.GROUP_ID_CONFIG是没有效果的)。
最后,用Kafka实现WordCount:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class WordCount {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordCount");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "num01:9092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 3000);
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
builder.stream("wordin") // 从wordin导入数据
.flatMapValues((value) -> Arrays.asList(value.toString().split("\\s+"))) // 按照空白字符切割为多个单词
.map((key, value) -> new KeyValue<>(value, "1")) // 转换为(单词,1)的键值对形式
.groupByKey() // 根据单词分组
.count() // 计算各分组value的数量
.toStream()
.map(((key, value) -> new KeyValue<>(key, key + " : " + value.toString())))
.to("wordout"); // 输出到wordout
Topology topology = builder.build();
final KafkaStreams kafkaStreams = new KafkaStreams(topology, prop);
CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream") {
@Override
public void run() {
kafkaStreams.close();
latch.countDown();
}
});
kafkaStreams.start();
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
}
效果演示:

窗口
Kafka Stream的窗口和其他流处理框架(Spark Streaming和Flink)类似,只是概念略有不同;
Kafka Stream共分四种窗口类型:
Hopping time window
跳跃时间窗口,完全可以按照其他实时框架中的滑动时间窗口来理解,只是在Kafka Stream中采用了不同的叫法。
这类窗口需要传入两个参数size和advance interval,分别代表窗口的宽度和创建窗口的时间间隔。应用开始运行的时间就是第一个窗口的起始时间,然后每经过一个advance interval便会创建一个新的窗口,同时每个窗口的宽度都是size(时间上的宽度)。
下面是官网提供的一个size=5min,advance interva=1min的Hopping time window示意图

同一列的方块代表对应时间发生的一个事件在不同窗口中的体现,可以得出一个结论:同一个事件在Hopping Time Window中出现的最大(除了最开始的时间,剩余时间发生的事件被收集次数都是最大次数)次数为size/(advanced interval),因为窗口的界限是左闭右开的,10:05-10:10时间段的窗口并不能收集到10:10发生的事件。
案例代码:
public static void main(String[] args) {
// 上面的配置和普通Kafka Stream没什么区别
Properties prop = new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG, "window_demo1");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "num01:9092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 3000);
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
TimeWindowedKStream<String, String> windowdemo = builder.stream("windowdemo")
.flatMapValues(value -> {
String[] split = value.toString().split("\\s+");
return Arrays.asList(split);
})
.map((key, value) -> new KeyValue<>(value, "1"))
.groupByKey()
// 使用TimeWindos定义时间窗口,of方法内传入毫秒值表示的size,得到结果调用advanceBy方法限定advanced interval时间间隔
.windowedBy(TimeWindows.of(Duration.ofSeconds(15).toMillis()).advanceBy(Duration.ofSeconds(5).toMillis()));
KStream<Windowed<String>, Long> windowedLongKStream = windowdemo.count().toStream();
windowedLongKStream.foreach((key, value) -> System.out.println("key:" + key + "\tvalue:" + value));
Topology topology = builder.build();
final KafkaStreams kafkaStreams = new KafkaStreams(topology, prop);
CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream") {
@Override
public void run() {
kafkaStreams.close();
latch.countDown();
}
});
kafkaStreams.start();
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.exit(0);
}
Tumbling time window
滚动时间窗口,是跳跃时间窗口的一种特例,当跳跃时间窗口的size和advance iterval值相等时,它就变成了滚动时间窗口。
滚动时间窗口只有一个参数:size,表示窗口的尺寸,一个窗口的结束点会是下一个窗口的起始点。窗口之间没有间隙,也不重叠。
size = 5min的滚动时间窗口示意图:

滚动时间窗口的界限同样是左闭右开的
案例代码:
StreamsBuilder builder = new StreamsBuilder();
TimeWindowedKStream<String, String> windowdemo = builder.stream("windowdemo")
.flatMapValues(value -> {
String[] split = value.toString().split("\\s+");
return Arrays.asList(split);
})
.map((key, value) -> new KeyValue<>(value, "1"))
.groupByKey()
// 只需要将Hopping Time Window中的advanceBy方法去掉就可以了
.windowedBy(TimeWindows.of(Duration.ofSeconds(15L).toMillis()));
KStream<Windowed<String>, Long> windowedLongKStream = windowdemo.count().toStream();
windowedLongKStream.foreach((key, value) -> System.out.println("key:" + key + "\tvalue:" + value));
Session window
会话窗口,与其他窗口完全不同,其他窗口都是基于时间的,而会话窗口是基于session的。每个窗口的宽度并不是确定的。创建会话窗口只需要一个参数:gap时间间隔或者叫超时时间,即从上次事件发生起,为发生事件的时间达到限定的时间间隔时,当前会话窗口就会关闭(会话窗口的关闭还可以是因为session的关闭)。当下个事件发生,数据会由下个窗口获取
设置间隔时间为5min

如图所示,“绿色”事件的间隔超过了5min,因为就分到了两个会话窗口中
而如果中间有事件发生,使得中间事件与前后事件的间隔都不足5min,那么这三个事件就会被划分到一个窗口内:

同时,窗口的起始时间并非为程序启动时间,而是取决于事件的发生时间
案例代码:
SessionWindowedKStream<String, String> windowdemo = builder.stream("windowdemo")
.flatMapValues(value -> {
String[] split = value.toString().split("\\s+");
return Arrays.asList(split);
})
.map((key, value) -> new KeyValue<>(value, "1"))
.groupByKey()
// 基本逻辑和其他窗口大同小异,只是需要使用SessionWindows,传入的参数是时间间隔的毫秒值
.windowedBy(SessionWindows.with(Duration.ofSeconds(15).toMillis()));
KStream<Windowed<String>, Long> windowedLongKStream = windowdemo.count().toStream();
windowedLongKStream.foreach((key, value) -> System.out.println("key:" + key.key() + "\tvalue:" + value));
Sliding time window
滑动时间窗口,Kafka中的滑动时间窗口和其他实时框架的滑动时间窗口不同,Kafka Stream的滑动时间窗口主要用于join操作和窗口聚合。该窗口需要传入两个参数:时间间隔和容忍时间。发生时间差小于时间间隔的两个时间会出现在同一个窗口内。
滑动时间窗口会从前向后记录包含不同事件组合的快照:

时间窗口定义方式:
import org.apache.kafka.streams.kstream.SlidingWindows;
// 定义需要传入的两个参数
Duration timeDifferenceMs = Duration.ofMinutes(10);
Duration gracePeriodMs = Duration.ofMinutes(30);
SlidingWindows.withTimeDifferenceAndGrace(timeDifferenceMs,gracePeriodMs);
简单总结
Kafka Stream由于使用限制比较多,例如每次数据转换操作Key和Value都需要切换为固定的数值类型,实际使用并不方便,对于操作稍复杂的转换操作还是推荐使用Spark Streaming或者Flink。但是Kafka Stream胜在轻量,当数据转换操作较为简单时,使用Kafka Stream进行转换是个不错的选择,再或者Kafka Stream可以在数据传入其他实时框架前执行一些简单的清洗工作。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









