







一、交换两个数,不使用第三个变量(临时变量)
0)通常我们的做法是(尤其是在学习阶段):定义一个新的变量,借助它完成交换。代码如下:
int a,b;
a=10; b=15;
int t;
t=a; a=b; b=t;
这种算法易于理解,特别适合帮助初学者了解计算机程序的特点,是赋值语句的经典应用。在实际软件开发当中,此算法简单明了,不会产生歧义,便于程序员之间的交流,一般情况下碰到交换变量值的问题,都应采用此算法(以下称为标准算法)。
上面的算法最大的缺点就是需要借助一个临时变量。那么不借助临时变量可以实现交换吗?答案是肯定的!这里我们可以用三种算法来实现:1)算术运算;2)指针地址操作;3)位运算。
1) 算术运算(直接进行算数代入运算)
简单来说,就是通过普通的+和-运算来实现。代码如下:
int a,b;
a=10;b=12;
a=b-a; //a=2;b=12
b=b-a; //a=2;b=10
a=b+a; //a=10;b=10
通过以上运算,a和b中的值就进行了交换。表面上看起来很简单,但是不容易想到,尤其是在习惯标准算法之后。
0-------------a-----------------b----------------->>>X轴
它的原理是:把a、b看做数轴上的点,围绕两点间的距离来进行计算。
具体过程:第一句“a=b-a”求出ab两点的距离,并且将其保存在a中;
第二句“b=b-a”求出a到原点的距离(b到原点的距离与ab两点距离之差),并且将其保存在b中;
第三句“a=b+a”求出b到原点的距离(a到原点距离与ab两点距离之和),并且将其保存在a中。完成交换。
此算法与标准算法相比,多了三个计算的过程,但是没有借助临时变量。(以下称为算术算法)
2) 指针地址操作
因为对地址的操作实际上进行的是整数运算,比如:两个地址相减得到一个整数,表示两个变量在内存中的储存位置隔了多少个字节;地址和一个整数相加即“a+10”表示以a为基地址的在a后10个a类数据单元的地址。所以理论上可以通过和算术算法类似的运算来完成地址的交换,从而达到交换变量的目的。即:
int *a,*b; //假设
*a=new int(10);
*b=new int(20); //&a=0x00001000h,&b=0x00001200h
a=(int*)(b-a); //&a=0x00000200h,&b=0x00001200h
b=(int*)(b-a); //&a=0x00000200h,&b=0x00001000h
a=(int*)(b+int(a)); //&a=0x00001200h,&b=0x00001000h
通过以上运算a、b的地址真的已经完成了交换,且a指向了原先b指向的值,b指向原先a指向的值了吗?上面的代码可以通过编译,但是执行结果却令人匪夷所思!原因何在?
首先必须了解,操作系统把内存分为几个区域:系统代码/数据区、应用程序代码/数据区、堆栈区、全局数据区等等。在编译源程序时,常量、全局变量等都放入全局数据区,局部变量、动态变量则放入堆栈区。这样当算法执行到“a=(int*)(b-a)”时,a的值并不是0x00000200h,而是要加上变量a所在内存区的基地址,实际的结果是:0x008f0200h,其中0x008f即为基地址,0200即为a在该内存区的位移。它是由编译器自动添加的。因此导致以后的地址计算均不正确,使得a,b指向所在区的其他内存单元。再次,地址运算不能出现负数,即当a的地址大于b的地址时,b-a<0,系统自动采用补码的形式表示负的位移,由此会产生错误,导致与前面同样的结果。
有办法解决吗?当然!以下是改进的算法:
if(a<b)
{
a=(int*)(b-a);
b=(int*)(b-(int(a)&0x0000ffff));
a=(int*)(b+(int(a)&0x0000ffff));
}
else
{
b=(int*)(a-b);
a=(int*)(a-(int(b)&0x0000ffff));
b=(int*)(a+(int(b)&0x0000ffff));
}
算法做的最大改进就是采用位运算中的与运算“int(a)&0x0000ffff”,因为地址中高16位为段地址,后16位为位移地址,将它和0x0000ffff进行与运算后,段地址被屏蔽,只保留位移地址。这样就原始算法吻合,从而得到正确的结果。
此算法同样没有使用第三变量就完成了值的交换,与算术算法比较它显得不好理解,但是它有它的优点即在交换很大的数据类型时,它的执行速度比算术算法快。因为它交换的时地址,而变量值在内存中是没有移动过的。(以下称为地址算法)
3) 位运算(直接进行算数代入运算)
通过异或运算也能实现变量的交换,这也许是最为神奇的,请看以下代码:
int a=10,b=12; //a=1010^b=1100;
a=a^b; //a=0110^b=1100;
b=a^b; //a=0110^b=1010;
a=a^b; //a=1100=12;b=1010;
此算法能够实现是由异或运算的特点决定的,通过异或运算能够使数据中的某些位翻转,其他位不变。这就意味着任意一个数与任意一个给定的值连续异或两次,值不变。
即:a^b^b=a。将a=a^b代入b=a^b则得b=a^b^b=a;同理可以得到a=b^a^a=b;轻松完成交换。
以上三个算法均实现了不借助其他变量来完成两个变量值的交换,相比较而言算术算法和位算法计算量相当,地址算法中计算较复杂,却可以很轻松的实现大类型(比如自定义的类或结构)的交换,而前两种只能进行整形数据的交换(理论上重载“^”运算符,也可以实现任意结构的交换)。
介绍这三种算法并不是要应用到实践当中,而是为了探讨技术,展示程序设计的魅力。从中可以看出,数学中的小技巧对程序设计而言具有相当的影响力,运用得当会有意想不到的神奇效果。而从实际的软件开发看,标准算法无疑是最好的,能够解决任意类型的交换问题。
二、直接给内存地址赋值 ===(指针<<==>>地址)
int *p; 2 p=(int*)0xbc010290; 3 *p=3;
三、根据结构体变量地址反推结构体首地址
1. container_of宏(即实现了题目中的功能)----可以直接实现“从结构体(type)某成员变量(member)指针(ptr)来求出该结构体(type)的首指针。” (linux 内核已经实现....)
【定义】:
#define container_of(ptr, type, member) ({const typeof( ((type *)0)->member ) *__mptr = (ptr); (type *)( (char *)__mptr -offsetof(type,member) );})
【功能】:
从结构体(type)某成员变量(member)指针(ptr)来求出该结构体(type)的首指针。
【例子】:
struct A
{
int x ;
int y;
int z;
};
struct A myTest;
int *pz = myTest.z;
struct A* getHeaderPtr( int *pz )
{
return container_of( pz , struct A, z );
}
【分析】:
(1) typeof( ( (type *)0)->member )为取出member成员的变量类型。
(2) 定义__mptr指针ptr为指向该成员变量的指针(即指向ptr所指向的变量处)
(3) (char *)__mptr - offsetof(type,member)) 用该成员变量的实际地址减去该变量在结构体中的偏移,来求出结构体起始地址。
(4) ({ })这个扩展返回程序块中最后一个表达式的值。
2.分析过程
1). offsetof宏
获得一个结构体变量成员在此结构体中的偏移量。
这里有个地方需要注意:就是offsetof虽然同样适用于union结构,但它不能用于计算位域(bitfield)成员在数据结构中的偏移量。
【定义】:#define offsetof(TYPE, MEMBER) ((size_t) & ((TYPE *)0)->MEMBER )
【功能】: 获得一个结构体变量成员在此结构体中的偏移量。
【例子】:
struct A
{
int x ;
int y;
int z;
};
void main()
{
printf("the offset of z is %d",offsetof( struct A, z ) );
}
// 输出结果为 8
【分析】:
该宏,TYPE为结构体类型,MEMBER 为结构体内的变量名。
(TYPE *)0) 是欺骗编译器说有一个指向结构TYPE 的指针,其地址值0
(TYPE *)0)->MEMBER 是要取得结构体TYPE中成员变量MEMBER的地址. 因为基址为0,所以,这时MEMBER的地址当然就是MEMBER在TYPE中的偏移了。
2). offsetof宏详细解释
关于#define offsetof(s,m) (size_t)&(((s *)0)->m)最详细的解释如下:
((s *)0):强制转化成数据结构指针,并使其指向地址0;
((s *)0)->m:使该指针指向成员m
&(((s *)0)->m):获取该成员m的地址
(size_t)&(((s *)0)->m):转化这个地址为合适的类型
你可能会迷惑,这样强制转换后的结构指针怎么可以用来访问结构体字段?呵呵,其实这个表达式根本没有也不打算访问m字段。ANSI C标准允许任何值为0的常量被强制转换成任何一种类型的指针,并且转换结果是一个NULL指针,因此((s*)0)的结果就是一个类型为s*的NULL指针。如果利用这个NULL指针来访问s的成员当然是非法的,但&(((s*)0)->m)的意图并非想存取s字段内容,而仅仅是计算当结构体实例的首址为((s*)0)时m字段的地址。聪明的编译器根本就不生成访问m的代码,而仅仅是根据s的内存布局和结构体实例首址在编译期计算这个(常量)地址,这样就完全避免了通过NULL指针访问内存的问题。又因为首址的值为0,所以这个地址的值就是字段相对于结构体基址的偏移。
本文出自 “对影成三人” 博客
3. container_of宏---自己的实现(引自:http://blog.csdn.net/ma52103231/article/details/20036705)
<span style="font-size:18px;"><span style="font-size:18px;"> typedef struct
{
int a;
int b;
int c;
}ABC; </span></span><span style="font-size:18px;"><span style="font-size:18px;"> int main(void)
{
ABC abc;
printf("abc : %p\n",&(abc));
printf("abc.c : %p\n",&(abc.c));
return 0;
} </span></span><span style="font-size:18px;"><span style="font-size:18px;"> abc : 0022FF44
abc.c : 0022FF4C
</span></span><span style="font-size:18px;"><span style="font-size:18px;"> 因为成员c的地址比abc高,所以按照数学公式:差 = 成员C地址 - abc地址 ===>>>>
abc地址 = 成员C地址 - 差(成员C的地址 相对于 结构体abc地址的 偏移量) </span></span>(1)做如下处理:
<span style="font-size:18px;"><span style="font-size:18px;">printf("abc : %p\n",&(abc.c) - (size_t)&(((ABC*)0)->c));</span></span><span style="font-size:18px;"><span style="font-size:18px;">printf("abc : %p\n",(unsigned char*)&(abc.c) - (size_t)&(((ABC*)0)->c));</span></span>(2)最终定义为:
<span style="font-size:18px;"><span style="font-size:18px;"> #define container_in(ptr,TYPE,member) \
(TYPE*)((unsigned char*)(ptr) - (size_t)&(((TYPE*)0)->member)) </span></span>
把差值强制转换为(TYPE*),是因为这个宏的目的就是返回(TYPE*)类型的指针
<span style="font-size:18px;"><span style="font-size:18px;">#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define container_in(ptr,TYPE,member) \
(TYPE*)((unsigned char*)(ptr) - (size_t)&(((TYPE*)0)->member))
typedef struct
{
char a;
char b;
char c;
}TEST1;;
typedef struct
{
char a;
char b;
}TEST2;;
typedef struct
{
char a;
TEST1 test1;
short b;
TEST2 test2;
int c;
}ABC;
int main(void)
{
ABC abc;
ABC* p = NULL;
abc.a = 1;
abc.b = 2;
abc.c = 4;///成员变量地址
p = container_in(&(abc.c),ABC,c);/根据成员地址获取结构体的首地址,
printf("%u %u %u\n",p->a,p->b,p->c);//打印成员变量的内容
return 0;
}</span></span>
四、module 模块的自动加载
1.可以参看: http://www.docin.com/p-472954660.html





2.系统启动时自动加载模块
要了解如何在系统启动时自动加载模块(Automatically load kernel modules),就得先了解系统是如何启动的,启动的过程中按什么顺序做了什么,怎么做的,这些启动操作都有那些文件和脚本控制。整个开机流程是:
(1) 载入BIOS的硬件信息,并取得第一个开机装置的代号
(2)读取第一个开机装置的MBR的boot Loader (grub)的开机信息
(3)载入OS Kernel信息,解压Kernel,尝试驱动硬件
(4) Kernel执行init程序并获得run-lebel信息(如3或5)
(5) init执行/etc/rc.d/rc.sysinit
(6)启动内核外挂模块(/etc/modprobe.conf)
(7) init执行run-level的各种Scripts,启动服务
(8) init执行/etc/rc.d/rc.local
(9)执行/bin/login,等待用户Login
(10)Login后进入Shell
看来正确的方式是把需要加载的模块放在(5)或(6),我修改了/etc/rc.d/rc.sysinit就成功加载了。初步尝试在rc.sysinit最后增加 modprobe.conf ip_vs,重启后lsmod | grep ip_vs,发现成功自动加载了。于是仿效rc.sysinit中其他模块的加载方法,扩展改脚本文件,在最后增加下来一段:
# load LVS IPVS modules
if [ -d /lib/modules/$unamer/kernel/net/ipv4/ipvs ]; then
for module in /lib/modules/$unamer/kernel/net/ipv4/ipvs/* ; do
module=${module##*/}
module=${module%.ko}
modprobe $module >/dev/null 2>&1
done
fi
就把/lib/modules/2.6.21-1.3194.fc7/kernel/net/ipv4/ipvs/下的所有模块都自动加载。重启后lsmod | grep ip_vs就会得到:
ip_vs_wrr 6977 0
ip_vs_wlc 6081 0
ip_vs_sh 6593 0
ip_vs_sed 6081 0
ip_vs_rr 6081 0
ip_vs_nq 5953 0
ip_vs_lc 5953 0
ip_vs_lblcr 10565 0
ip_vs_lblc 9797 0
ip_vs_ftp 10053 0
ip_vs_dh 6593 0
ip_vs 79425 22 ip_vs_wrr,ip_vs_wlc,ip_vs_sh,ip_vs_sed,ip_vs_rr,ip_vs_nq,ip_vs_lc,ip_vs_lblcr,ip_vs_lblc,
内核模块如果引用到Linux内核中的符号,这个则不属于模块间的依赖,因为内核导出的符号本身就是供内核模块所使用。本帖要讨论的是在两个独立编译的模块A和B之间,B如果要引用A导出的符号,在Makefile中该如何把这一信息加入的问题。
绝大多数情形下,内核配置时能会启用CONFIG_MODVERSIONS,这意味着无论是内核还是内核模块,在导出符号时都会为该符号生成CRC校验码,这个校验码保存在Module.symvers文件中。
最常见的是,模块会引用到内核导出的符号,此时模块的Makefile没有什么特殊的地方。现在假设A导出一个符号A_sym,那么A_sym的CRC校验码会存在于A模块所在目录的Module.symvers文件中,如果B模块引用到A模块的A_sym符号,那么是需要在它的'__versions'section中生成A_sym符号的校验码的,这个校验码直接取自于A模块的Module.symvers文件。如果B模块在编译时从它的Makefile中无法获得这一信息,首先编译阶段就会产生一个WARNING,其次加载阶段也会因为符号没有CRC校验码而导致加载失败。
此时我们需要在B模块的Makefile文件中加上下面一行,以告诉模块的编译工具链到何处查找A_sym符号的CRC校验码:
KBUILD_EXTMOD := A模块所在的目录
如此,modpost工具除了到内核所在目录下查找外,还会到KBUILD_EXTMOD指定的目录下查找Module.symvers,以确定本模块所有未定义符号的CRC值。
最后给一个具体的Makefile:
<span style="font-size:18px;"><span style="font-size:18px;"> obj-m := dep_on_A.o
KERNELDIR := /lib/modules/$(shell uname -r)/build
KBUILD_EXTMOD := /home/dennis/workspace/Linux/book/kmodule/A_mod
PWD := $(shell pwd)
default:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
</span></span>
六、set_bit && clear_bit(置位 && 清位)
#define set_bit(x,b) (x) |= (1U<<(b)) , 用宏定义一个类似函数的功能,即set_bit(x,b)的作用是将x的二进制数中的从左数第b位(最左端为第0位)设置为1,
比如set_bit(8,1)=10, 因为8的2进制为1000,第一位为0,设置成1后变为1010即10进制的10
#define clear_bit(x,b) (x) &= ~(1U<<(b)) ,功能是清除x的第b位,即设置第b位为0,与set_bit的作用刚好相反
七、交换两个数,不使用第三个变量(临时变量)
1.volatile的作用是: 作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值.
在C语言中可以用volatile限定符来修饰变量,就是告诉编译器,即使在编译时指定了优化选项,每次读这个变量仍然要老老实实从内存读取,每次写这个变量也仍然要老老实实写回内存,不能省略任何步骤。
|
1
2
3
4
|
XBYTE[2]=0x55;
XBYTE[2]=0x56;
XBYTE[2]=0x57;
XBYTE[2]=0x58;
|
对外部硬件而言,上述四条语句分别表示不同的操作,会产生四种不同的动作,但是编译器却会对上述四条语句进行优化,认为只有XBYTE[2]=0x58(即忽略前三条语句,只产生一条机器代码)。如果键入volatile,则编译器会逐一的进行编译并产生相应的机器代码(产生四条代码).
2.extern可置于变量或者函数前,以表示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。
3.局部变量和全局变量的类型与名称完全一致问题
如果局部变量和全局变量的类型与名称完全一致,在局部变量定义的有效域中,局部变量将覆盖全局变量。直到退出局部变量定义域,全局变量的定义才又重新可见;
局部变量仅在一个函数内有效,如果你需要在此函数内使用全局变量,可以使用与全局变量不同名的变量
但是如果是在定义局部变量的函数外,全局变量是不受影响的。
4.static用法小结(作用域:本模块(文件)/ /函数等)
static关键字是C, C++中都存在的关键字, 它主要有三种使用方式, 其中前两种只指在C语言中使用, 第三种在C++中使用(C,C++中具体细微操作不尽相同, 本文以C++为准).
(1)局部静态变量
(2)外部静态变量/函数
(3)静态数据成员/成员函数
(1)、局部静态变量
在C/C++中, 局部变量按照存储形式可分为三种auto, static, register
与auto类型(普通)局部变量相比, static局部变量有三点不同
1. 存储空间分配不同
auto类型分配在栈上, 属于动态存储类别, 占动态存储区空间, 函数调用结束后自动释放, 而static分配在静态存储区, 在程序整个运行期间都不释放. 两者之间的作用域相同, 但生存期不同.
2. static局部变量在所处模块在初次运行时进行初始化工作, 且只操作一次
3. 对于局部静态变量, 如果不赋初值, 编译期会自动赋初值0或空字符, 而auto类型的初值是不确定的. (对于C++中的class对象例外, class的对象实例如果不初始化, 则会自动调用默认构造函数, 不管是否是static类型)
特点: static局部变量的”记忆性”与生存期的”全局性”
所谓”记忆性”是指在两次函数调用时, 在第二次调用进入时, 能保持第一次调用退出时的值.
示例程序一
#include <iostream>
using namespace std;
void staticLocalVar()
{
static int a = 0; // 运行期时初始化一次, 下次再调用时, 不进行初始化工作
cout<<"a="<<a<<endl;
++a;
}
int main()
{
staticLocalVar(); // 第一次调用, 输出a=0
staticLocalVar(); // 第二次调用, 记忆了第一次退出时的值, 输出a=1
return 0;
}
应用:
利用”记忆性”, 记录函数调用的次数(示例程序一)
利用生存期的”全局性”, 改善”return a pointer / reference to a local object”的问题. Local object的问题在于退出函数, 生存期即结束,. 利用static的作用, 延长变量的生存期.
注意事项:
1. “记忆性”, 程序运行很重要的一点就是可重复性, 而static变量的”记忆性”破坏了这种可重复性, 造成不同时刻至运行的结果可能不同.
2. “生存期”全局性和唯一性. 普通的local变量的存储空间分配在stack上, 因此每次调用函数时, 分配的空间都可能不一样, 而static具有全局唯一性的特点, 每次调用时, 都指向同一块内存, 这就造成一个很重要的问题 ---- 不可重入性!!!
这样在多线程程序设计或递归程序设计中, 要特别注意这个问题.
(2)、外部静态变量/函数
在C中static有了第二种含义:用来表示不能被其它文件访问的全局变量和函数。,但为了限制全局变量/函数的作用域, 函数或变量前加static使得函数成为静态函数。但此处“static”的含义不是指存储方式,而是指对函数的作用域仅局限于本文件(所以又称内部函数)。注意此时, 对于外部(全局)变量, 不论是否有static限制, 它的存储区域都是在静态存储区, 生存期都是全局的. 此时的static只是起作用域限制作用, 限定作用域在本模块(文件)内部.
使用内部函数的好处是:不同的人编写不同的函数时,不用担心自己定义的函数,是否会与其它文件中的函数同名。
示例程序三:
//file1.cpp
static int varA;
int varB;
extern void funA()
{
……
}
static void funB()
{
……
}
//file2.cpp
extern int varB; // 使用file1.cpp中定义的全局变量
extern int varA; // 错误! varA是static类型, 无法在其他文件中使用
extern vod funA(); // 使用file1.cpp中定义的函数
extern void funB(); // 错误! 无法使用file1.cpp文件中static函数
(3)、静态数据成员/成员函数(C++特有)
C++重用了这个关键字,并赋予它与前面不同的第三种含义:表示属于一个类而不是属于此类的任何特定对象的变量和函数. 这是与普通成员函数的最大区别, 也是其应用所在, 比如在对某一个类的对象进行计数时, 计数生成多少个类的实例, 就可以用到静态数据成员. 在这里面, static既不是限定作用域的, 也不是扩展生存期的作用, 而是指示变量/函数在此类中的唯一性. 这也是”属于一个类而不是属于此类的任何特定对象的变量和函数”的含义. 因为它是对整个类来说是唯一的, 因此不可能属于某一个实例对象的. (针对静态数据成员而言, 成员函数不管是否是static, 在内存中只有一个副本, 普通成员函数调用时, 需要传入this指针, static成员函数调用时, 没有this指针. )
请看示例程序四(<effective c++ (2nd)>(影印版)第59页)
class EnemyTarget {
public:
EnemyTarget() { ++numTargets; }
EnemyTarget(const EnemyTarget&) { ++numTargets; }
~EnemyTarget() { --numTargets; }
static size_t numberOfTargets() { return numTargets; }
bool destroy(); // returns success of attempt to destroy EnemyTarget object
private:
static size_t numTargets; // object counter
};
// class statics must be defined outside the class;
// initialization is to 0 by default
size_t EnemyTarget::numTargets;
另外, 在设计类的多线程操作时, 由于POSIX库下的线程函数pthread_create()要求是全局的, 普通成员函数无法直接做为线程函数, 可以考虑用Static成员函数做线程函数.
5.const (只读性,不可修改)
const是一个C语言的关键字,它限定一个变量不允许被改变。使用const在一定程度上可以提高程序的安全性和可靠性。Const 是C++中常用的类型修饰符,常类型是指使用类型修饰符const说明的类型,常类型的变量或对象的值是不能被更新的。
/如指针使用CONST
(1)指针本身是常量不可变(指针不可以变化)
(char*) const pContent;
const (char*) pContent;
(2)指针所指向的内容是常量不可变(*内容不可以变化)
const (char) *pContent;
(char) const *pContent;
(3)两者都不可变
const char* const pContent;
(4)还有其中区别方法,沿着*号划一条线:
如果const位于*的左侧,则const就是用来修饰指针所指向的变量,即指针指向为常量;
如果const位于*的右侧,const就是修饰指针本身,即指针本身是常量。
6.&是取地址运算符。
7.全局变量只能用常量表达式初始化,如果定义int p = i;就错了,因为i不是常量表达式,然而用i的地址来初始化一个指针却没有错,因为i的地址是在编译链接时能确定的,而不需要到运行时才知道,&i是常量表达式
8.各种指针
“野指针”(Unbound Pointer):有一种情况需要特别注意,定义一个指针类型的局部变量而没有初始化。在堆栈上分配的变量初始值是不确定的,也就是说指针p所指向的内存地址是不确定的,后面用*p访问不确定的地址就会导致不确定的后果,如果导致段错误还比较容易改正,如果意外改写了数据而导致随后的运行中出错,就很难找到错误原因了。像这种指向不确定地址的指针称为“野指针”(Unbound Pointer),为避免出现野指针,在定义指针变量时就应该给它明确的初值,或者把它初始化为NULL。
空指针:Null,就是把地址0转换成指针类型,称为空指针,它的特殊之处在于,操作系统不会把任何数据保存在地址0及其附近,也不会把地址0~0xfff的页面映射到物理内存,所以任何对地址0的访问都会立刻导致段错误。*p = 0;会导致段错误,就像放在眼前的炸弹一样很容易找到,相比之下,野指针的错误就像埋下地雷一样,更难发现和排除,这次走过去没事,下次走过去就有事。
Void * 类型指针:在编程时经常需要一种通用指针,可以转换为任意其它类型的指针,任意其它类型的指针也可以转换为通用指针,最初C语言没有void *类型,就把char*当通用指针,需要转换时就用类型转换运算符(),ANSI在将C语言标准化时引入了void *类型,void *指针与其它类型的指针之间可以隐式转换,而不必用类型转换运算符。注意,只能定义void *指针,而不能定义void型的变量,因为void *指针和别的指针一样都占4个字节,而如果定义void型变量(也就是类型暂时不确定的变量),编译器不知道该分配几个字节给变量。同样道理,void *指针不能直接Dereference,而必须先转换成别的类型的指针再做Dereference
9.ArrayList 和 LinkedList
一般大家都知道ArrayList和LinkedList的大致区别:
1).ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2).对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3).对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
八、android 的启动过程

九、SD卡驱动
电源如何加载
如何识别是哪个sd卡?
1. SD卡的基本知识:
(1)SD卡有9个pin脚(micro-SD为8个,少一个接地pin脚)
(2)SD的数据传输方式有两种,普通SD模式和SPI模式,以SD模式为例,9个pin脚分别是VDD,VSS,CLK,以及我们需要关注的一根指令线CMD,4根数据线DAT0~DAT3。
(3)分类:
- 按存储大小,普通SD卡(<=2GB,支持FAT12/FAT16),HCSD卡(>2GB,<=32GB,支持FAT32)
- 按体积大小,普通SD卡,mini-SD卡,micro-SD卡(TF卡)
(4)速度
- 默认模式: 12.5MB/s
- 高速模式: 25MB/s
-
(5)SDIO总线:SD总线通信基于命令和数据流。
SDIO总线 和 USB总线类似,SDIO也有两端,其中一端是HOST端,另一端是device端。所有的通信 都是 由HOST端 发送 命令开始的,Device端只要能解析命令,就可以相互通信。
CLK信号:HOST给DEVICE的 时钟信号,每个时钟周期传输一个命令。
CMD信号:双向 的信号,用于传送 命令和 反应。
DAT0-DAT3 信号:四条用于传送的数据线。
VDD信号:电源信号。
VSS1,VSS2:电源地信号。
(6)SDIO热插拔原理:
方法:设置一个 定时器检查 或 插拔中断检测
硬件:假如GPG10(EINT18)用于SD卡检测
GPG10 为高电平 即没有插入SD卡
GPG10为低电平 即插入了SD卡
(7)工作电压:按照工作电压分类,SDMemory Card可以分为两种类型:
u High Voltage SD Memory Cards,工作电压为2.7 - 3.6V。
u UHS-II SD Memory Card,工作电压 VDD1为2.7 - 3.6V, VDD2为1.7 - 1.95V
(8)资料
//理论储备
Linux的SDIO子系统
http://blog.csdn.net/qianjin0703/article/details/5918041
Android的Vold架构:
Vold - Volume Daemon存储类的守护进程,作为Android的一个本地服务,
负责处理诸如SD、USB等存储类设备的插拔等事件。
http://blog.csdn.net/qianjin0703/article/details/6362389///主要职责
- 移植SD卡和inand驱动。
- 解决bug, 如快速热插拔不识别,部分SD卡不识别,系统启动后inand不识别等。
2. SD卡在MTK6572中的架构
涉及到的文件有:
alps\mediatek/platform/mt6573/kernel/drivers/mmc-host
alps\kernel\drivers\mmc\下面的card,core等文件夹
下面就整个驱动的流程过一下:
系统起来的时候执行 static int __init mt_msdc_init(void)在这个函数里最重要的是执行platform_driver_register(&mt_msdc_driver),即注册到内核的虚拟总线上,注册的原则是把驱动mt_msdc_driver各参数进行初始化。
下面进入变量mt_msdc_driver各成员的初始化。其中最重要的成员是msdc_drv_probe的执行。当在虚拟platform总线上driver和device的名字"mtk-msdc"相匹配时即执行probe函数。其中device的注册文件位于:
alps\mediatek\platform\mt6572\kernel\core\mt_devs.c
未完待续。
十、USB驱动(http://blog.csdn.net/qianjin0703/article/details/6559033)
USB博大精深,不是一两篇博文能够解释清楚的。想要深入研究USB的话,USB协议(外加Host和OTG协议)是必要的知识,另外,国内有本fudan_abc的<<USB那些事>>也写的很好很详细,唯一美中不足的就是写得太详细了反而感觉思路架构不是很清晰了,本人学识还浅,想简单地把USB在Linux里的结构框架大致整理下,其中重点解析下USB Core和Hub。
0. 预备理论
说实话,读USB2.0协议还是蛮痛苦的,它仅仅是一个协议,一个在USB世界里制定的游戏规则,就像法律条文一样,它并不是为了学习者而写的,可读性很差。这里总结以下几个重点基本点。
0.1 拓扑结构 (ch4.1.1)
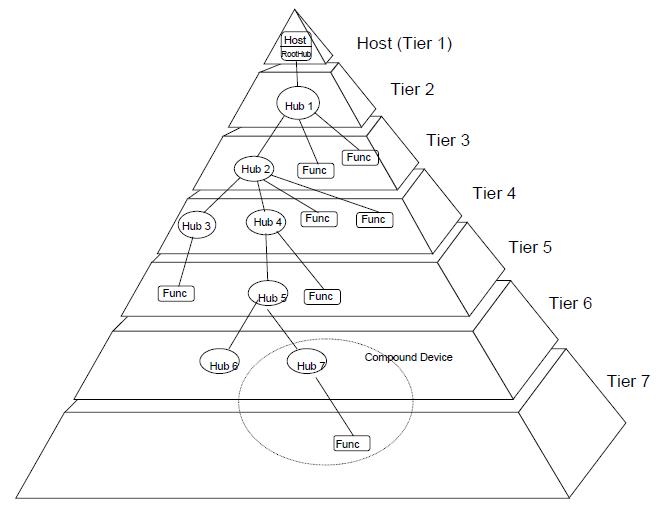
- 之所以要规定这个树形拓扑结构是为了避免环形连接。
- 一条USB总线有且只有一个USB Host,对应一个RootHub
- USB设备分为两类,Hub和Functions,Hub通过端口Port连接更多USB设备,Functions即USB外接从设备。
- 层次最多7层,且第7层不能有Hub,只能有functions。
- Compound Device - 一个Hub上接多个设备组成一个小设备。
- Composite Device - 一个USB外接设备具有多个复用功能。
0.2 机械性能 (ch5)
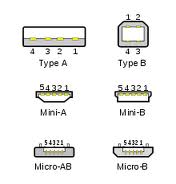
- 连接件connector,就是设备上的那个连接口。
- 插头plug,就是USB电缆线两头的插口。
- Mini-AB, Micro-AB指的是支持A和B两类插头的连接件。
0.3 电气性能 (ch6)
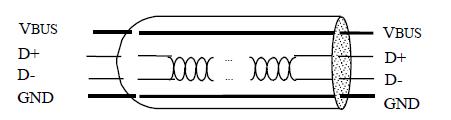
- VBUS - +5V电源供电。
- D+ D- - 用于数据传输的电缆线。
- 低速 low-speed 10-100Kb/s 应用于鼠标和键盘等
- 全速 full-speed 500Kb-10Mb/s 应用于音频和麦克等
- 高速 high-speed 25-400Mb/s 应用于存储和视频等 (USB3.0比之块10倍)
0.4 四大描述符 (ch9.5)
协议规定了USB的四个描述符descriptor - 设备device,配置configure,接口interface,端点endpoint。
终端下输入命令 # ls /sys/bus/usb/devices
usb1
1-0:1.0
usb2
2-0:1.0 // USB总线(RootHub) No.2,USB port端口号No.0,配置号No.1,接口号No.0。
- 区别port和endpoint,port之于hub,endpoint是每个USB设备用于数据传输所必需的端点。
- 设备device>配置configure>接口interface>设置setting>端点endpoint。
- 设备可以有多个配置,配置可以有一个或多个接口,接口可以有一个或多个设置。
- 一个接口对应一个驱动,接口是端点的集合。
0.5 启动流程 (ch9.1,9.2)
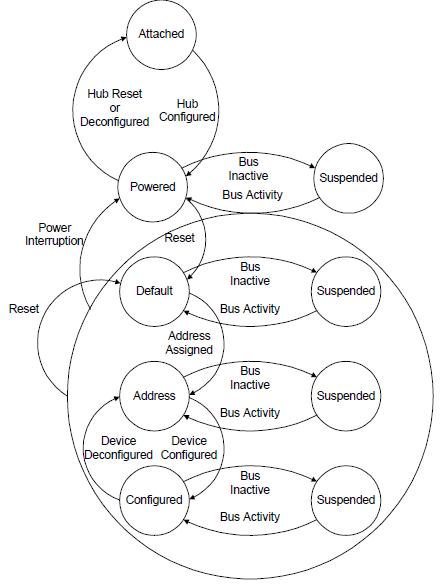
- attached->powered->default->address->configured
- 启动流程与其他设备比如SD卡相比,最大的不同在于Hub,主机Host通过Hub状态的变化判断USB外接设备的有无。
- USB外接设备插入和拔出整个实现过程称为总线枚举Bus Enumeration。
0.6 数据流传输 (ch5)
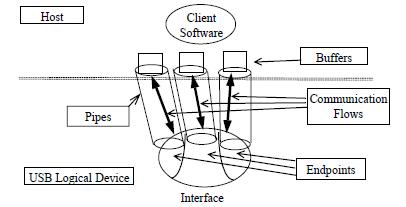
- endpoint分零端点和非零端点,零端点作为默认的控制方法用于初始化和操控USB逻辑设备。
- 数据流传输分 control/bulk/interrupt/isochronous data transfer。
0.7 数据包 (ch8)
- 数据包分Token, Data, Handshake, Special,四种包有自己的数据组织方式。
- Token令牌包只能由主机传送给设备,分IN, OUT, SOF和SETUP。
- SETUP包实现主机向设备发出的请求request,也要满足特定的格式。(ch9.3,9.4)
1. USB Core
先啰嗦几句,回答一个困扰我很久的问题,读Linux源码究竟要读到什么程度?这是个永恒的话题,每个同道中人都有自己的看法。以笔者之见,如何阅读源码主要取决于自己的职业定位,是研发还是开发,是为Linux社区作贡献还是用已有的方案开发?我想大多数驱动工程师属于后者,那么,面对已经很完善的核心层源码,还有必要看吗,或者有必要去深入研究吗?我认为既然我们已经站在了巨人的肩膀上,至少要知道这宽阔的肩膀是如何炼成的,它所存在的价值以及如何去使用它。
既然如此,那USB核心层到底是什么,它都默默地做了些什么,我们要如何使用它?这里主要有两个重点,USB总线和urb。
1.1 USB子系统结构
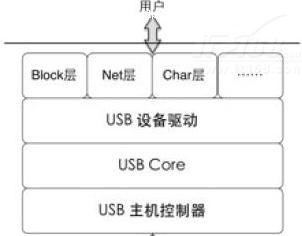
协议里说,HCD提供主控制器驱动的硬件抽象,它只对USB Core一个负责,USB Core将用户的请求映射到相关的HCD,用户不能直接访问HCD。换句话说,USB Core就是HCD与USB设备唯一的桥梁。
1.2 USB子系统的初始化
USB core源码位于./drivers/usb/core,其中的Makefile摘要如下,

usbcore这个模块代表的不是某一个设备,而是所有USB设备赖以生存的模块,它就是USB子系统。
./drivers/usb/core/usb.c里实现了初始化,伪代码如下,

usbcore注册了USB总线,USB文件系统,USB Hub以及USB的设备驱动usb generic driver等。
1.3 USB总线
注册USB总线通过bus_register(&usb_bus_type);
struct bus_type usb_bus_type = {
.name = "usb",
.match = usb_device_match, // 这是个很重要的函数,用来匹配USB设备和驱动。
.uevent = usb_uevent,
.pm = &usb_bus_pm_ops,
};
下面总结下USB设备和驱动匹配的全过程,
-> step 1 - usb device driver
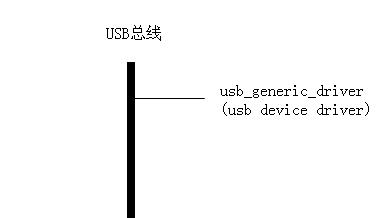
USB子系统初始化的时候就会注册usb_generic_driver, 它的结构体类型是usb_device_driver,它是USB世界里唯一的一个USB设备驱动,区别于struct usb_driver USB驱动。
- USB设备驱动(usb device driver)就只有一个,即usb_generice_driver这个对象,所有USB设备都要绑定到usb_generic_driver上,它的使命可以概括为:为USB设备选择一个合适的配置,让设备进入configured状态。
- USB驱动(usb driver)就是USB设备的接口驱动程序,比如adb驱动程序,u盘驱动程序,鼠标驱动程序等等。
-> step 2 - usb driver
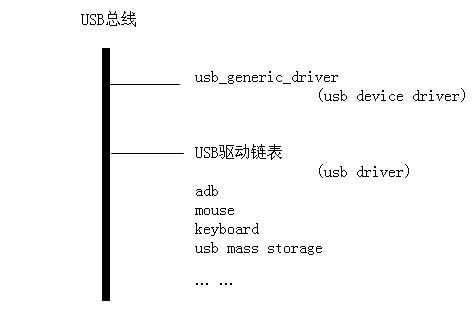
Linux启动时注册USB驱动,在xxx_init()里通过usb_register()将USB驱动提交个设备模型,添加到USB总线的驱动链表里。
-> step 3 - usb device
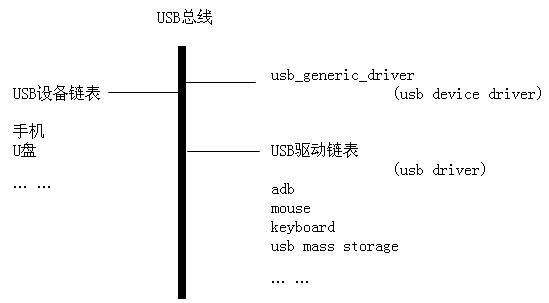
USB设备连接在Hub上,Hub检测到有设备连接进来,为设备分配一个struct usb_device结构体对象,并将设备添加到USB总线的设备列表里。
-> step 4 - usb interface
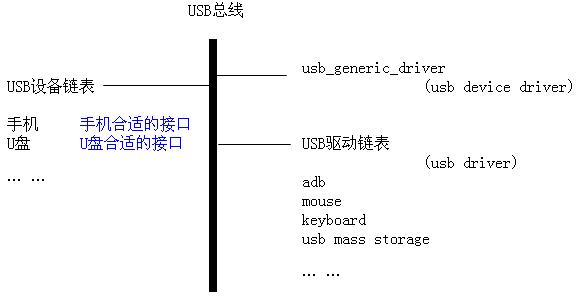
USB设备各个配置的详细信息在USB core里的漫漫旅途中已经被获取并存放在相关的几个成员里。
usb_generic_driver得到了USB设备的详细信息,然后把准备好的接口送给设备模型,Linux设备模型将接口添加到设备链表里,然后去轮询USB总线另外一条驱动链表,针对每个找到的驱动去调用USB总线的match函数,完成匹配。
1.4 USB Request Block (urb)
USB主机与设备间的通信以数据包(packet)的形式传递,Linux的思想就是把这些遵循协议的数据都封装成数据块(block)作统一调度,USB的数据块就是urb,结构体struct urb,定义在<linux/usb.h>,其中的成员unsigned char *setup_packet指针指向SETUP数据包。下面总结下使用urb完成一次完整的USB通信需要经历的过程,
-> step 1 - usb_alloc_urb()
创建urb,并指定USB设备的目的端点。
-> step 2 - usb_control_msg()
将urb提交给USB core, USB core将它交给HCD主机控制器驱动。
-> step 3 - usb_parse_configuration()
HCD解析urb,拿到数据与USB设备通信。
-> step 4
HCD把urb的所有权交还给驱动程序。
协议层里最重要的函数就是usb_control/bulk/interrupt_msg(),这里就简单地理一条线索,
usb_control_msg() => usb_internal_control_msg() => usb_start_wait_urb() => usb_submit_urb() => usb_hcd_submit_urb => hcd->driver->urb_enqueue() HCD主控制器驱动根据具体平台实现USB数据通信。
2. USB Hub
Hub集线器用来连接更多USB设备,硬件上实现了USB设备的总线枚举过程,软件上实现了USB设备与接口在USB总线上的匹配。
下面总结下USB Hub在Linux USB核心层里的实现机制,
USB子系统初始化时,usb_hub_init()开启一个名为"khubd"的内核线程,
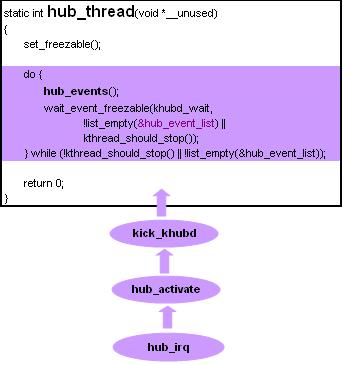
内核线程khubd从Linux启动后就自始至终为USB Hub服务,没有Hub事件时khubd进入睡眠,有USB Hub事件触发时将会经由hud_irq() => hub_activate() => kick_khubd() 最终唤醒khubd,将事件加入hub_event_list列表,并执行hub_events()。hub_events()会不停地轮询hub_events_list列表去完成hub触发的事件,直到这个列表为空时退出结束,回到wait_event_xxx继续等待。
处理hub事件的全过程大致可分为两步,
- 第一步 判断端口状态的变化
通过hub_port_status()得到hub端口的状态。
源码里类似像hub_port_status(), hub_hub_status()等功能函数,都调用了核心层的usb_control_msg()去实现主控制器与USB设备间的通信。
- 第二步 处理端口的变化
hub_port_connect_change()是核心函数,以端口发现有新的USB设备插入为例,USB Hub为USB设备做了以下几步重要的工作,注意这里所谓的USB设备是指插入USB Hub的外接USB设备(包括Hub和Functions),接下来Hub都在为USB设备服务。
1) usb_alloc_dev() 为USB设备申请一个sturct usb_device结构。
2) usb_set_device_state() 设置USB设备状态为上电状态。(硬件上设备已进入powered状态)。
3) choose_address() 为USB设备选择一个地址,利用一个轮询算法为设备从0-127里选择一个地址号。
4) hub_port_init() 端口初始化,实质就是获取设备描述符device descriptor。
5) usb_get_status() 这个有点特殊,它是专门给Hub又外接Hub而准备的。
6) usb_new_device() 这时USB设备已经进入了Configured状态,调用device_add()在USB总线上寻找驱动,若匹配成功,则加载对应的驱动程序。
3. USB OTG
引入OTG的概念是为了让设备可以充当主从两个角色,主设备即HCD,从设备即UDC,也就是Gadget。这里就简单梳理下协议和源码。
3.1 协议
1) Protocol
OTG的传输协议有三类 - ADP,SRP,HNP。
- ADP(Attach Detection Protocol) 当USB总线上没有供电时,ADP允许OTG设备或USB设备决定连接状态。
- SRP(Session Request Protocol) 允许从设备也可以控制主设备。
- HNP(Host Negotiation Protocol) 允许两个设备互换主从角色。
2) Device role
协议定义两种角色,OTG A-device和OTG B-device,A-device为电源提供者,B-device为电源消费者,默认配置下,A-device作为主设备,B-device作为从设备,之后可以通过HNP互换。
3) OTG micro plug
协议上说"An OTG product must have a single Micro-AB receptacle and no other USB receptacles."这句话有点问题。。。应该还包括mini-AB receptacle,以下所有micro都可以是mini。
OTG电缆一端为micro-A plug,另一端为micro-B plug。
OTG加了第5个pin脚,名为ID-pin,micro-A plug的ID-pin接地,micro-B plug的ID-pin悬空。
OTG设备被接上micro-A plug后被称为micro-A device,被接上micro-B plug后被称为micro-B device。
3.2 源码浅析
OTG控制器集成在CPU内,Linux下的源码驱动由各家开发平台提供,位于./drivers/usb/otg/下。
以Freescale平台为例,主要的思路就是,当有OTG线插入OTG设备时产生中断,中断处理函数上半部通过读取OTG控制器寄存器相应值判断OTG设备属于Host(HCD)还是Gadget(UDC),下半部通过工作队列由回调函数类似host->resume()或gadget->resume()重启Host或Gadget控制器,resume()具体的实现过程在HCD或UDC相关驱动里实现。
4. USB Host
USB主控制器(HCD)同样集成在CPU内,由开发平台厂商提供驱动,源码位于./drivers/usb/host/下。
主控制器主要有四类:EHCI, FHCI, OHCI, UHCI, 它们各自的寄存器接口协议不同,嵌入式设备多为EHCI。
该驱动的结构体类型为struct hc_driver,其中的成员(*urb_enqueue)最为重要,它是主控制器HCD将数据包urb传向USB设备的核心实现函数,之前已经提到,协议层里最主要的函数usb_control_msg()最终就会回调主控制器的(*urb_enqueue)。
usb_control_msg() => usb_internal_control_msg() => usb_start_wait_urb() => usb_submit_urb() => usb_hcd_submit_urb => hcd->driver->urb_enqueue()
5. USB Gadget
当年写过一篇Gadget...http://blog.csdn.net/qianjin0703/archive/2011/01/15/6141763.aspx
Gadget源码位于./drivers/usb/gadget/下,涉及的驱动程序和数据结构相对较多。
驱动主要有,
- 平台相关的Gadget控制器驱动
- 平台无关的复用设备驱动composite.c
- android平台的复用设备驱动android.c
- adb驱动f_adb.c,U盘驱动f_mass_storage.c等一些复用的USB驱动
数据结构主要有,
- struct usb_gadget 里面主要有(*ops)和struct usb_ep *ep0。
- struct usb_gadget_driver 其中的(*bind)绑定复用设备驱动,(*setup)完成USB枚举操作。
- struct usb_compostie_driver 其中的(*bind)绑定比如android复用设备驱动。
- struct usb_request USB数据请求包,类似urb。
- struct usb_configuration 就是这个gadget设备具有的配置,其中的struct usb_function *interface[]数组记录着它所拥有的USB接口/功能/驱动。
- struct usb_function 其中的(*bind)绑定相关的USB接口,(*setup)完成USB枚举操作。
整体框架可概括为,(mv_gadget为gadget控制器的数据)

6. USB Mass Storage
全世界只有一个Linux U盘驱动,位于./drivers/usb/storage/usb.c,伪代码如下,这里需要注意的是,在进行U盘驱动的初始化probe之前,USB core和hub已经对这个U盘做了两大工作,即
1) 完成了USB设备的枚举,此时U盘已经进入configured状态,U盘数据存放在struct usb_interface。
2) 完成了USB总线上设备和驱动的匹配,这时总线上已经找到了接口对应的驱动即U盘驱动。
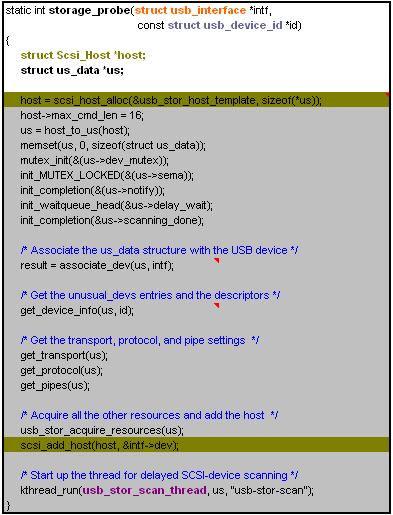
- 土黄色部分由SCSI子系统封装实现最终的U盘驱动注册。
- usb_stor_scan_thread 扫描U盘的线程,等待5秒,如果5秒内不拔出就由SCSI进行全盘扫描,
- usb_stor_contro_thread 一个核心的线程,具体参看《USB那些事》...

十一、I2C驱动
/速率:如何修改I2C speed:工作速率有100Kbit/s、400Kbit/s和3.4Mbit/s三种;
Mediatek\custom\common\kernel\imgsensor\src\kd_sensorlist.c
iWriteReg()中最前面加上g_pstI2Cclient->timing,表示设置I2C的速度
如果不设置,为默认值100K ,
比如想将I2C的speed设置为400K,可将g_pstI2Cclient->timing设置为400K
/简单的I2C协议理解
一). 技术性能:
工作速率有100Kbit/s、400Kbit/s和3.4Mbit/s三种;
支持多机通讯;
支持多主控模块,但同一时刻只允许有一个主控;
由数据线SDA和时钟SCL构成的串行总线;
每个电路和模块都有唯一的地址;
每个器件可以使用独立电源;
连接到总线的接口数量只由总线电容是400pF的限制决定;
二). 基本工作原理:
SDA和SCL都是双向线路,都通过一个电流源或上拉电阻连接到正的电源电压。当总线空闲时,这两条线路都是高电平。连接到总线的器件输出级必须是漏极开路或集电极开路才能执行线与的功能。
以启动信号START来掌管总线,以停止信号STOP来释放总线;
每次通讯以START开始,以STOP结束;
启动信号START后紧接着发送一个地址字节,其中7位为被控器件的地址码,一位为读/写控制位R/W,R/W位为0表示由主控向被控器件写数据,R/W为1表示由主控从被控器件读数据;
当主机发送了一个地址后,系统中的每个器件都在起始条件后将头7位与自己的地址比较,如果被控器件检测到收到的地址与自己的地址相同,在第9个时钟期间反馈应答信号;
每个数据字节在传送时都是高位(MSB)在前;
写通讯过程:
1. 主控在检测到总线空闲的状况下,首先发送一个START信号掌管总线;
2. 发送一个地址字节(包括7位地址码和一位R/W);
3. 当被控器件检测到主控发送的地址与自己的地址相同时发送一个应答信号(ACK);
4. 主控收到ACK后开始发送第一个数据字节;
5. 被控器收到数据字节后发送一个ACK表示继续传送数据,发送NACK表示传送数据结束;
6. 主控发送完全部数据后,发送一个停止位STOP,结束整个通讯并且释放总线;
读通讯过程:
1. 主控在检测到总线空闲的状况下,首先发送一个START信号掌管总线;
2. 发送一个地址字节(包括7位地址码和一位R/W);
3. 当被控器件检测到主控发送的地址与自己的地址相同时发送一个应答信号(ACK);
4. 主控收到ACK后释放数据总线,开始接收第一个数据字节;
5. 主控收到数据后发送ACK表示继续传送数据,发送NACK表示传送数据结束;
6. 主控发送完全部数据后,发送一个停止位STOP,结束整个通讯并且释放总线;
四). 总线信号时序分析
1. 总线空闲状态
SDA和SCL两条信号线都处于高电平,即总线上所有的器件都释放总线,两条信号线各自的上拉电阻把电平拉高;
2. 启动信号START
时钟信号SCL保持高电平,数据信号SDA的电平被拉低(即负跳变)。启动信号必须是跳变信号,而且在建立该信号前必修保证总线处于空闲状态;
3. 停止信号STOP
时钟信号SCL保持高电平,数据线被释放,使得SDA返回高电平(即正跳变),停止信号也必须是跳变信号。
4. 数据传送
SCL线呈现高电平期间,SDA线上的电平必须保持稳定,低电平表示0(此时的线电压为地电压),高电平表示1(此时的电压由元器件的VDD决定)。只有在SCL线为低电平期间,SDA上的电平允许变化。
5. 应答信号ACK
I2C总线的数据都是以字节(8位)的方式传送的,发送器件每发送一个字节之后,在时钟的第9个脉冲期间释放数据总线,由接收器发送一个ACK(把数据总线的电平拉低)来表示数据成功接收。
6. 无应答信号NACK
在时钟的第9个脉冲期间发送器释放数据总线,接收器不拉低数据总线表示一个NACK,NACK有两种用途:
a. 一般表示接收器未成功接收数据字节;
b. 当接收器是主控器时,它收到最后一个字节后,应发送一个NACK信号,以通知被控发送器结束数据发送,并释放总线,以便主控接收器发送一个停止信号STOP。
五). 寻址约定
地址的分配方法有两种:
1. 含CPU的智能器件,地址由软件初始化时定义,但不能与其它的器件有冲突;
2. 不含CPU的非智能器件,由厂家在器件内部固化,不可改变。
高7位为地址码,其分为两部分:
1. 固定部分,不可改变,由厂家固化的统一地址;
2. 可编程部分,此部分由器件可使用的管脚决定。例如,如果器件有4个固定的和3个可编程的地址位,那么相同的总线上共可以连接8个相同的器件(并非所有器件都可以设定)。
十二、audio驱动(refer:http://blog.csdn.net/qianjin0703/article/details/6387662)
ALSa驱动架构
0. 专用术语
ASLA - Advanced Sound Linux Architecture
OSS - 以前的Linux音频体系结构,被ASLA取代并兼容
Codec - Coder/Decoder
I2S/PCM/AC97 - Codec与CPU间音频的通信协议/接口/总线
DAI - Digital Audio Interface 其实就是I2S/PCM/AC97
DAC - Digit to Analog Conversion
ADC - Analog to Digit Conversion
DSP - Digital Signal Processor
Mixer - 混音器,将来自不同通道的几种音频模拟信号混合成一种模拟信号
Mute - 消音,屏蔽信号通道
PCM - Pulse Code Modulation 一种从音频模拟信号转换成数字信号的技术,区别于PCM音频通信协议
采样频率 - ADC的频率,每秒采样的次数,典型值如44.1KHZ
量化精度 - 比如24bit,就是将音频模拟信号按照2的24次方进行等分
SSI - Serial Sound Interface
DAPM - Dynamic Audio Power Management
1. 物理结构
音频编解码器Codec负责处理音频信息,包括ADC,DAC,Mixer,DSP,输入输出以及音量控制等所有与音频相关的功能。
Codec与处理器之间通过I2C总线和数字音频接口DAI进行通信。
I2C总线 - 实现对Codec寄存器数据的读写。
DAI - 实现音频数据在CPU和Codec间的通信。(DAI - Digital Audio Interface 其实就是I2S/PCM/AC97)
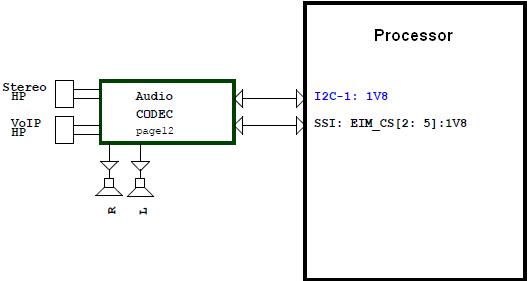
以Codec作为研究对象,它的输入有Mic(Microphone),PhoneIn 电话信号等,输出有耳机HP(HeadPhone),扬声器Speaker和PhoneOut电话信号。另外需要注意在Codec与CPU端间也有音频数字信号的输入输出。
1) 播放音乐
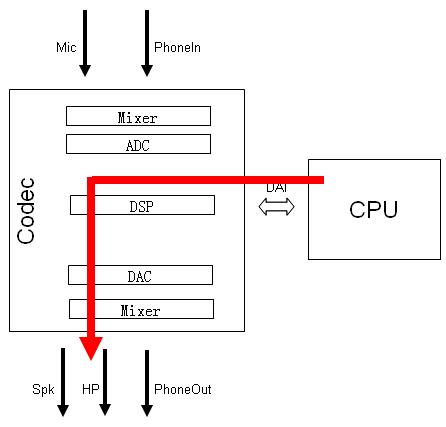
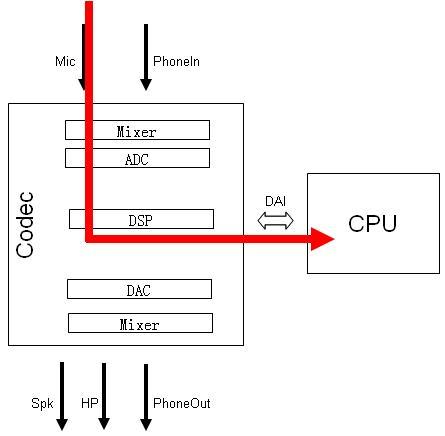
2) 录音
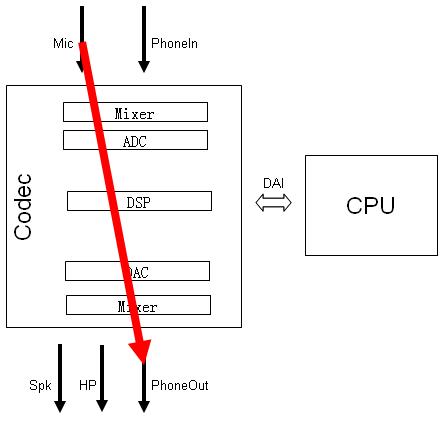
3) 电话
--- 打电话 --- --- 接听---
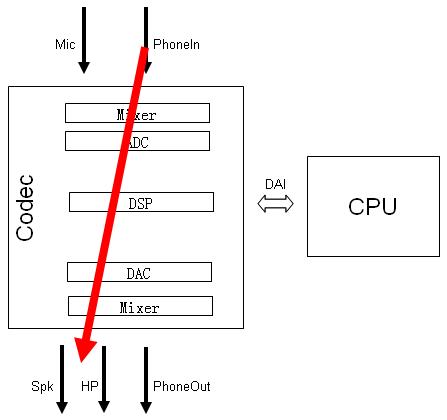
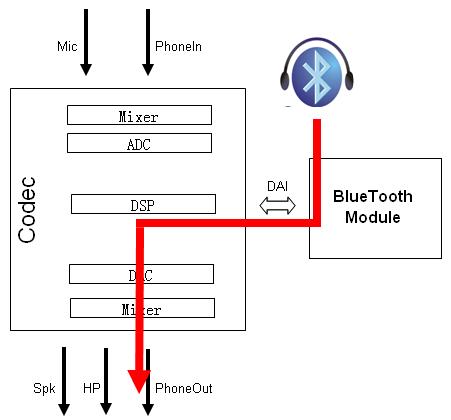
4) 通过蓝牙打电话
--- 打电话 --- --- 接听---
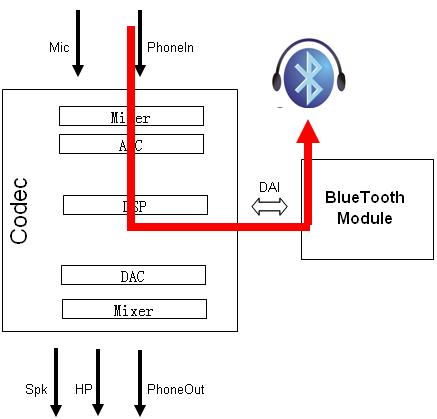
2. 系统架构
Android的音频系统拥有一个比较标准和健全的架构,从上层应用,java framework服务AudioMananger,本地服务AudioFlinger,抽象层AlsaHAL,本地库,再调用external的Alsa-lib外部支持库,最后到底层驱动的codec,可谓"五脏俱全"。
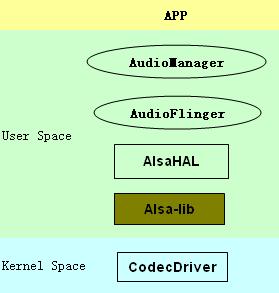
以系统启动AuidoFlinger为例,简要窥探Alsa Sound的组织架构。
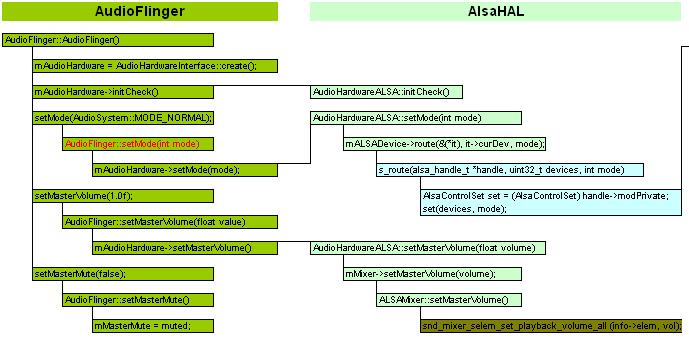
Java服务AudioManager作为服务端,本地服务AudioFlinger作为客户端,两者通过Binder机制交互。AudioFlinger对硬件功能的具体实现(比如setMode设置电话/蓝牙/录音等模式)交给硬件抽象层AlsaHAL完成。抽象层可以调用本地标准接口,比如mASLADevice->route,或者直接调用Alsa-lib库去操作底层驱动。
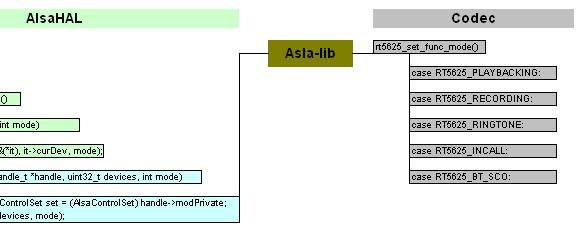
Linux的音频驱动结构相对复杂,源码位于内核目录下的/sound/soc/,其中/codec文件夹下存放与平台无关的编解码器驱动,/imx文件夹下存放于freescale imx平台相关的音频驱动,主要可分为SSI驱动和DAI驱动。
以声卡驱动的数据结构为切入点分析,

1) struct snd_soc_codec - 由与平台无关的codec驱动实现。
2) struct snd_soc_platform - 由与imx平台相关的DAI驱动实现,主要实现了音频数据的DMA传输功能。
3) struct snd_soc_dai_link - 将平台相关的DAI与平台无关的codec联系起来。
十三、android recovery模式
中断注册(按键在哪注册的?)
十四、android 电源管理模块















 1531
1531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









