







http://www.52rd.com/Blog/Detail_RD.Blog_wqyuwss_7934.html
C stbal sample table atom
存储媒体数据的单位是samples。一个sample是一系列按时间顺序排列的数据的一个element。Samples存储在media中的chunk内,可以有不同的durations。Chunk存储一个或者多个samples,是数据存取的基本单位,可以有不同的长度,一个chunk内的每个sample也可以有不同的长度。例如如下图,chunk 2和3不同的长度,chunk 2内的sample5和6的长度一样,但是sample 4和5,6的长度不同。
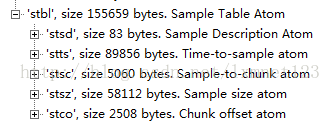
i stsd
sample description atom的类型是'stsd',包含了一个sample description表。根据不同的编码方案和存储数据的文件数目,每个media可以有一个到多个sample description。sample-to-chunk atom通过这个索引表,找到合适medai中每个sample的description。
| 字段 | 长度(字节) | 描述 |
| 尺寸 | 4 | 这个atom的字节数 |
| 类型 | 4 | stsd |
| 版本 | 1 | 这个atom的版本 |
| 标志 | 3 | 这里为0 |
| 条目数目 | 4 | sample descriptions的数目 |
| Sample description |
| 不同的媒体类型有不同的sample description,但是每个sample description的前四个字段是相同的,包含以下的数据成员 |
| 尺寸 | 4 | 这个sample description的字节数 |
| 数据格式 | 4 | 存储数据的格式。 |
| 保留 | 6 |
|
| 数据引用索引 | 2 | 利用这个索引可以检索与当前sample description关联的数据。数据引用存储在data reference atoms。 |
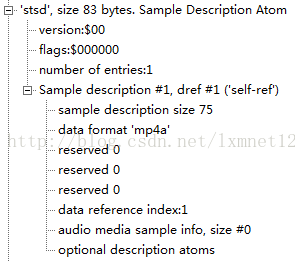

可以看出这个sample只有一个description,对应得的数据格式是'mp4a',14496-12定义了这种结构,mp4解码器会识别此description。
ii stts Time-to-sample atoms
Time-to-sampleatoms存储了media sample的duration 信息,提供了时间对具体data sample的映射方法,通过这个atom,你可以找到任何时间的sample,类型是'stts'。
这个atom可以包含一个压缩的表来映射时间和sample序号,用其他的表来提供每个sample的长度和指针。表中每个条目提供了在同一个时间偏移量里面连续的sample序号, 以及samples的偏移量。递增这些偏移量,就可以建立一个完整的time-to-sample表.
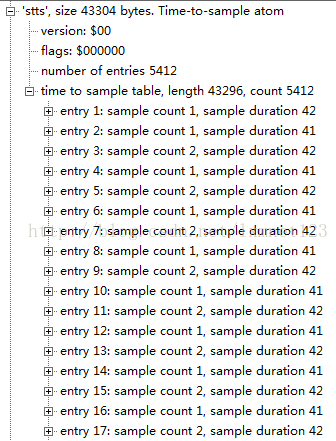
通过这个表,可以得知,任意时间所对应的第几个sample。 由 mdhd 知 timescale = 1000。 如计算0.2s所对应的sample为第几个时。对应的duration = timescale * 0.2 s = 200 entry 4 所对应的sample 第 5 个sample
iii stsc sample to chunk atoms
当添加samples到media时,用chunks组织这些sample,这样可以方便优化数据获取。一个trunk包含一个或多个sample,chunk的长度可以不同,chunk内的sample的长度也可以不同。sample-to-chunkatom存储sample与chunk的映射关系。
Sample-to-chunkatoms的类型是'stsc'。它也有一个表来映射sample和trunk之间的关系,查看这张表,就可以找到包含指定sample的trunk,从而找到这个sample。
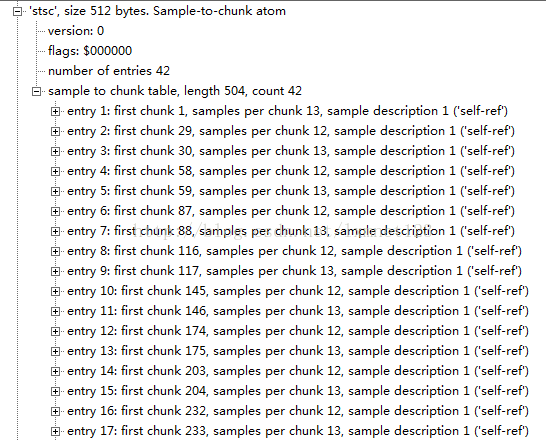
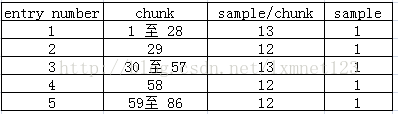
第 500个sample 500 = 28*13 + 12 + 13*9 + 7 所以相当于在chunk = 39 的 第7个sample中,这样 我们可以根据 stco 这个表找到 在chunk = 39位置所对应的偏移地址。 再根据 stsz 中找到第 494 至 496 中每个sample所占的大小。这样我们就可以求得 第500个sample的偏移地址,这样可以 seek 快进 快退。
如果要快进到任意时间,先根据 stts 表获取是第几个sample。在根据上面步骤就可快进。
iv stsz sample size atoms
sample size atoms定义了每个sample的大小,它的类型是'stsz',包含了媒体中全部sample的数目和一张给出每个sample大小的表。这样,媒体数据自身就可以没有边框的限制。
| 字段 | 长度(字节) | 描述 |
| 尺寸 | 4 | 这个atom的字节数 |
| 类型 | 4 | stsz |
| 版本 | 1 | 这个atom的版本 |
| 标志 | 3 | 这里为0 |
| Sample size | 4 | 全部sample的数目。如果所有的sample有相同的长度,这个字段就是这个值。否则,这个字段的值就是0。那些长度存在sample size表中 |
| 条目数目 | 4 | sample size的数目 |
| sample size |
| sample size表的结构。这个表根据sample number索引,第一项就是第一个sample,第二项就是第二个sample |
| 大小 | 4 | 每个sample的大小 |
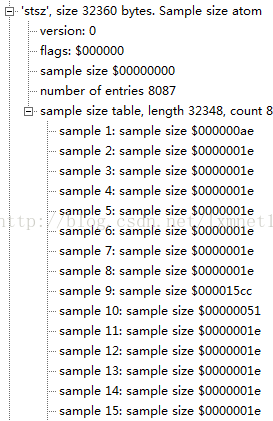
可以看到这个vedio track的sample的长度都不一样。
v stco (Chunk offset atoms)
Chunk offset atoms 定义了每个trunk在媒体流中的位置,它的类型是'stco'。位置有两种可能,32位的和64位的,后者对非常大的电影很有用。在一个表中只会有一种可能,这个位置是在整个文件中的,而不是在任何atom中的,这样做就可以直接在文件中找到媒体数据,而不用解释atom。需要注意的是一旦前面的atom有了任何改变,这张表都要重新建立,因为位置信息已经改变了。
| 字段 | 长度(字节) | 描述 |
| 尺寸 | 4 | 这个atom的字节数 |
| 类型 | 4 | stco |
| 版本 | 1 | 这个atom的版本 |
| 标志 | 3 | 这里为0 |
| 条目数目 | 4 | chunk offset的数目 |
| chunk offset |
| 字节偏移量从文件开始到当前chunk。这个表根据chunk number索引,第一项就是第一个trunk,第二项就是第二个trunk |
| 大小 | 4 | 每个sample的大小 |
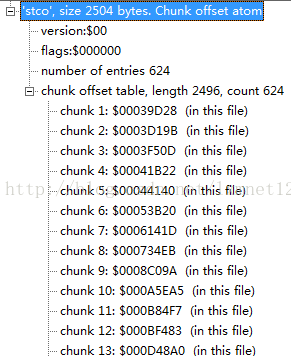
计算:
1 计算电影时长
方法1
从mvhd - movie header atom中找到time scale和duration,duration除以time scale即是整部电影的长度。
time scale相当于定义了标准的1秒在这部电影里面的刻度是多少。
例如audio track的time scale = 8000, duration = 560128,所以总长度是70.016,video track的timescale = 600, duration = 42000,所以总长度是70
方法2
首先计算出共有多少个帧,也就是sample(从sample size atoms中得到),然后
整部电影的duration = 每个帧的duration之和(从Time-to-sample atoms中得出)
例如audio track共有547个sample,每个sample的长度是1024,则总duration是560128,电影长度是70.016;video track共有1050个sample,每个sample的长度是40,则总duration是42000,电影长度是70
2 计算图像的宽 高
从tkhd – track header atom中找到宽度和高度即是。
3 电影声音采样率
从tkhd – track header atom中找出audio track的timescale即是声音的采样频率。
4 计算视频帧率
首先计算出整部电影的duration,和帧的数目然后
帧率 = 整部电影的duration / 帧的数目
5 计算电影的比特率
整部电影的尺寸除以长度,即是比特率,此电影的比特率为846623/70 = 12094 bps
6 查找sample
当播放一部电影或者一个track的时候,对应的media handler必须能够正确的解析数据流,对一定的时间获取对应的媒体数据。如果是视频媒体, mediahandler可能会解析多个atom,才能找到给定时间的sample的大小和位置。具体步骤如下:
1.确定时间,相对于媒体时间坐标系统
2.检查time-to-sample atom来确定给定时间的sample序号。
3.检查sample-to-chunk atom来发现对应该sample的chunk。
4.从chunk offset atom中提取该trunk的偏移量。
5.利用sample size atom找到sample在trunk内的偏移量和sample的大小。
例如,如果要找第1秒的视频数据,过程如下:
1. 第1秒的视频数据相对于此电影的时间为600
2. 检查time-to-sampleatom,得出每个sample的duration是40,从而得出需要寻找第600/40 = 15 + 1 = 16个sample
3. 检查sample-to-chunkatom,得到该sample属于第5个chunk的第一个sample,该chunk共有4个sample
4. 检查chunkoffset atom找到第5个trunk的偏移量是20472
5. 由于第16个sample是第5个trunk的第一个sample,所以不用检查sample size atom,trunk的偏移量即是该sample的偏移量20472。如果是这个trunk的第二个sample,则从sample size atom中找到该trunk的前一个sample的大小,然后加上偏移量即可得到实际位置。
6. 得到位置后,即可取出相应数据进行解码,播放
7 查找关键帧
查找过程与查找sample的过程非常类似,只是需要利用sync sample atom来确定key frame的sample序号
- 确定给定时间的sample序号
- 检查sync sample atom来发现这个sample序号之后的key frame
- 检查sample-to-chunk atom来发现对应该sample的chunk
- 从chunk offset atom中提取该trunk的偏移量
- 利用sample size atom找到sample在trunk内的偏移量和sample的大小















 5271
5271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









