






引子
前段时间改造链路,发现链路上可能会出现丢掉threadlocal中数据的情况,排查发现是在执行parallelStream后出现了丢标,并且这个丢标是偶发的。
public static void main(String[] args) {
List<Integer> lists = Lists.newArrayList();
for (int i = 0; i < 4; i++) {
lists.add(i);
}
//add threadLocal
//something...
//get threadLocal;
lists.parallelStream().forEach(e -> {
//set threadLocal;
//do something
//clear threadLocal;
});
//get threadLocal
}
多次执行后发现,parallelStream之后的标出现偶发性的被吞。(注:这里因为使用了部分集团内部组件,因此使用threadLocal替代)
[1]什么是ParallelStream
Stream(流)是JDK8中引入的一种类似与迭代器(Iterator)的单向迭代访问数据的工具。ParallelStream则是并行的流,它通过Fork/Join 框架(JSR166y)来拆分任务,加速流的处理过程。最开始接触parallelStream很容易把其当做一个普通的线程池使用,因此也出现了上面提到的开始的时候打标,结束的时候去掉标的动作。
ForkJoinPool又是什么
ForkJoinPool是在Java 7中引入了一种新的线程池,其简单类图如下:

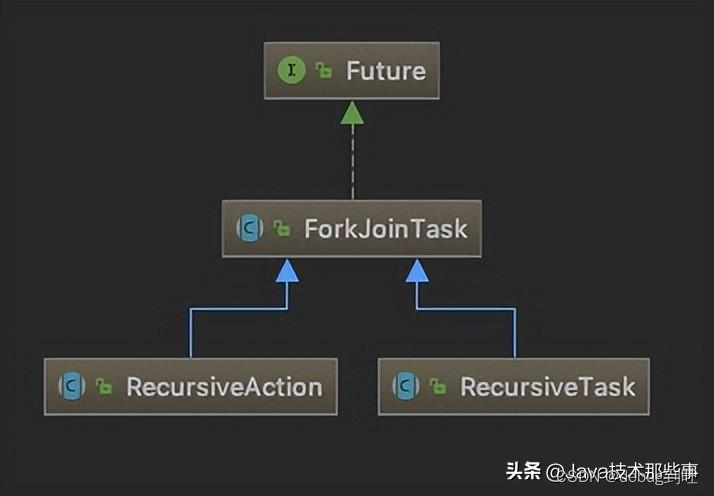
可以看到ForkJoinPool是ExecutorService的实现类,是一种线程池。创建了ForkJoinPool实例之后,可以通过调用submit(ForkJoinTask task) 或invoke(ForkJoinTask task)方法来执行指定任务。 ForkJoinTask表示线程池中执行的任务,其有两个主要的抽象子类:RecusiveAction和RecusiveTask。其中RecusiveTask代表有返回值的任务,而RecusiveAction代表没有返回值的任务。它们的类图如下:
ForkJoinPool来支持使用分治法(Divide-and-Conquer Algorithm)来解决问题,即将一个任务拆分成多个“小任务”并行计算,再把多个“小任务”的结果合并成总的计算结果。相比于ThreadPoolExecutor,ForkJoinPool能够在任务队列中不断的添加新任务,在线程执行完任务后可以再从任务列表中选择其他任务来执行;并且可以选择子任务的执行优先级,因此能够方便的执行具有父子关系的任务。ForkJoinPool内部维护了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值(最大为MAX_CAP = 0x7fff)。

回过头来看ParallelStream原理
运行如下代码:
public static void main(String[] args) {
List<Integer> lists = Lists.newArrayList();
for (int i = 0; i < 10000; i++) {
lists.add(i);
}
Set<String> sequenceThreadNameSet = Sets.newHashSet();
Set<String> parallelThreadNameSet = Sets.newHashSet();
lists.forEach(e -> sequenceThreadNameSet.add(Thread.currentThread().getName()));
lists.parallelStream().forEach(e -> parallelThreadNameSet.add(Thread.currentThread().getName()));
System.out.println(sequenceThreadNameSet);
System.out.println(parallelThreadNameSet);
}
得到结果:
[main]
[ForkJoinPool.commonPool-worker-7, ForkJoinPool.commonPool-worker-1, ForkJoinPool.commonPool-worker-2, main, ForkJoinPool.commonPool-worker-5, ForkJoinPool.commonPool-worker-6, ForkJoinPool.commonPool-worker-3, ForkJoinPool.commonPool-worker-4]
可以看出,串行的流使用的是main线程,而parallelStream使用了线程名为ForkJoinPool.commonPool-worker-*的线程,而这些线程来自于:

java.util.concurrent.ForkJoinPool#makeCommonPool函数在ForkJoinPool类的静态方法块中别调用,返回结果赋值给一个静态成员元素common,这个common是Java 8中引入的一个通用的静态线程池,这个线程池用来处理那些没有被显式提交到任何线程池的任务,ParallelStream其实就是自动的使用了这个通用ForkJoinPool线程池来实现并行化。

代码中可以看到,线程池数量取决于parallelism,而parallelism要么在3412、3419行中从环境变量中获得,要么在3435行被赋值为处理器数量减一,之后再判定如果其值小于0或者大于MAX_CAP,则取1或者MAX_CAP。注意这里,parallelism < 0,也就是如果启动jvm时候对其赋值为0,则会使用0作为参数进行线程池的创建。
commonPool线程数好像不太对?
从上面可以看出,commonPool的线程数量默认会使用处理器数量减去1,比如我的电脑是八核(其实是八线程)的,其实commonPool的线程池是7个线程,这个通过打印ForkJoinPool.getCommonPoolParallelism()也能看出,这样做是因为还有一个主线程,主线程加上线程池线程刚好等于cpu核心数,这样能同时跑满cpu,并且不会因为线程太多造成线程本身的切换浪费资源,这样最有效率。
回过头来看上面代码的输出:[ForkJoinPool.commonPool-worker-7, ForkJoinPool.commonPool-worker-1, ForkJoinPool.commonPool-worker-2, main, ForkJoinPool.commonPool-worker-5, ForkJoinPool.commonPool-worker-6, ForkJoinPool.commonPool-worker-3, ForkJoinPool.commonPool-worker-4],发现main也参与了ParallelStream中的计算。这是因为forEach将执行forEach本身的线程也被当作为线程池中的一个工作线程进行工作,因此使用刚好等于cpu核心数的线程来执行了多个任务。
因此,前面说的丢标的问题也得到解决,因为ParallelStream任务执行时,可能将main线程作为执行线程,因此如果在forEach中清标,可能会导致主线程中的标被丢掉。解决的方式也很简单,在执行完并行流之后,重新set一下标即可。
所以就无脑用ParallelStream了?
ParallelStream可能引起阻塞
对CPU密集型的任务来说,并行流使用ForkJoinPool,为每个CPU分配一个任务,这是非常有效率的,但是如果任务不是CPU密集的,而是I/O密集的,并且任务数相对线程数比较大,那么直接用ParallelStream并不是很好的选择。如下代码:
public static void main(String[] args) {
List<Integer> lists = Lists.newArrayList();
for (int i = 0; i < Runtime.getRuntime().availableProcessors(); i++) {
lists.add(i);
}
Date start = new Date();
lists.parallelStream().forEach(e -> {
try {
//do something
Thread.sleep(10000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
});
lists.parallelStream().forEach(e -> {
try {
//do something
Thread.sleep(10000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
});
Date end = new Date();
System.out.println((end.getTime() - start.getTime()) / 1000);
}
发现其执行时长为20秒,但是如下代码:
public class Test {
public static void main(String[] args) throws InterruptedException {
List<Integer> lists = Lists.newArrayList();
for (int i = 0; i < Runtime.getRuntime().availableProcessors(); i++) {
lists.add(i);
}
Date start = new Date();
ForkJoinPool forkJoinPool1 = new ForkJoinPool(Runtime.getRuntime().availableProcessors());
ForkJoinPool forkJoinPool2 = new ForkJoinPool(Runtime.getRuntime().availableProcessors());
CountDownLatch countDownLatch = new CountDownLatch(2);
taskProcess(lists, forkJoinPool1, countDownLatch);
taskProcess(lists, forkJoinPool2, countDownLatch);
countDownLatch.await();
Date end = new Date();
System.out.println((end.getTime() - start.getTime()) / 1000);
}
private static void taskProcess(List<Integer> lists, ForkJoinPool forkJoinPool, CountDownLatch countDownLatch) {
forkJoinPool.submit(() -> {
lists.parallelStream().forEach(e -> {
try {
//do something
Thread.sleep(10000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
});
countDownLatch.countDown();
});
}
}
执行可以发现,10秒可以执行完毕。这是因为第一份代码中,每次提交8个任务到commonPool,提交了两次,第二次的任务得等第一次执行完毕后才能执行,并且主线程也被阻塞。而第二次,使用独立的ForkJoinPool来执行线程,没有影响主线程的执行,如果在每个任务中打印一下线程名字也能看出来:
ForkJoinPool-2-worker-1
ForkJoinPool-1-worker-0
ForkJoinPool-1-worker-2
ForkJoinPool-1-worker-4
ForkJoinPool-1-worker-5
ForkJoinPool-1-worker-7
ForkJoinPool-1-worker-6
ForkJoinPool-2-worker-5
ForkJoinPool-2-worker-4
ForkJoinPool-1-worker-3
ForkJoinPool-2-worker-6
ForkJoinPool-2-worker-7
ForkJoinPool-2-worker-2
ForkJoinPool-2-worker-3
ForkJoinPool-2-worker-0
ForkJoinPool-1-worker-1
ParallelStream是多线程,注意线程安全
请看下面的代码
public class Test {
public static void main(String[] args) throws InterruptedException {
List<Integer> listOfIntegers =
new ArrayList<>();
for (int i = 0; i <100; i++) {
listOfIntegers.add(i);
}
List<Integer> parallelStorage = new ArrayList<>() ;
listOfIntegers
.parallelStream()
.filter(i->i%2==0)
.forEach(i->parallelStorage.add(i));
parallelStorage
.stream()
.sorted((o1, o2) -> {
if (o1 == null) {
return -1;
} else if (o2 == null) {
return 1;
} else {
return o1 > o2 ? 1 : o1.equals(o2) ? 0 : -1;
}
})
.forEach(e -> System.out.print(e + " "));
}
}
执行完后,发现parallelStorage中居然出现了null:
null 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90 92 94 96 98
这是因为在ArrayList中存储数据的过程不是一个线程安全的过程导致的。因此使用ParallelStream时要注意这点。
一些思考
勿在浮沙筑高台。一些常用的东西,底层的设计还是很巧妙的,而这些巧妙间却埋了不少的坑,当然踩坑还是应为CURD虽然撸得多但是对实现不了解,需要多去了解底层。














 3209
3209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









