







我的俄罗斯名叫作“不折腾不舒服斯基”,所以,不将分区表好好折腾一下,我就是不舒服。
在前面,我们介绍过怎么样直接创建一个分区表,也介绍过怎么将一个普通表转换成一个分区表。那么,这两种方式创建的表有什么区别呢?现在,我又最新地创建了两个表:
第一个表名为Sale,这个表使用的是《SQL Server 2005中的分区表(一):什么是分区表?为什么要用分区表?如何创建分区表?》中的方法创建的,在创建完之后,还为该表添加了一个主键。
第二个表名Sale1,这个表使用的是《SQL Server 2005中的分区表(三):将普通表转换成分区表 》中的方法创建的,也就是先创建了一个普通表,然后通过为普通表添加聚集索引的方式将普通表转换成已分区表的方式。
通过以上方法都可以得到一个已分区表,但是,这两个已分区表还是有点区别的,区别在哪里呢?我们分别查看一下这两个表的索引和主键吧,如下图所示。

从上图可以看出,直接创建的分区表Sale的索引里,只有一个名为PK_Sale的索引,这个索引是唯一的、非聚集的索引,也就是在创建PK_Sale主键时SQL Server自动创建的索引。而经普通表转换成分区表的Sale1的索引里,除了在创建主键时由SQL Server自动创建的名为PK_Sale1的唯一的、非聚集的索引之外,还存在一个名为CT_Sale1的聚集索引。
对于表Sale来说,可以通过修改分区函数的方式来将其转换成普通表,具体的修改方式请看《SQL Server 2005中的分区表(四):删除(合并)一个分区》,事实上,就是将分区函数中的所有分区分界都删除,那么,这个分区表中的所有数据就只能存在第一个分区表中了。在本例中,可以使用以下代码来修改分区函数。
- ALTER PARTITION FUNCTION partfunSale()
- MERGE RANGE ('20100101')
- ALTER PARTITION FUNCTION partfunSale()
- MERGE RANGE ('20110101')
- ALTER PARTITION FUNCTION partfunSale()
- MERGE RANGE ('20120101')
- ALTER PARTITION FUNCTION partfunSale()
- MERGE RANGE ('20130101')
事实上,这么操作之后,表Sale还是一个分区表,如下图所示,只不过是只有一个分区的分区了,这和普遍表就没有什么区别了。
对于通过创建分区索引的方法将普通表转换成的分区表而言,除了上面的方法之外,还可以通过删除分区索引的办法来将分区表转换成普通表。但必须要经过以下两个步骤:
1、删除分区索引
2、在原来的索引字段上重建一个索引。
先说删除分区索引吧,这一步很简单,你可以直接在SQL Server Management Studio上将分区索引删除,也可以使用SQL语句删除,如本例中可以使用以下代码删除已经创建的分区索引。
- drop index Sale1.CT_Sale1
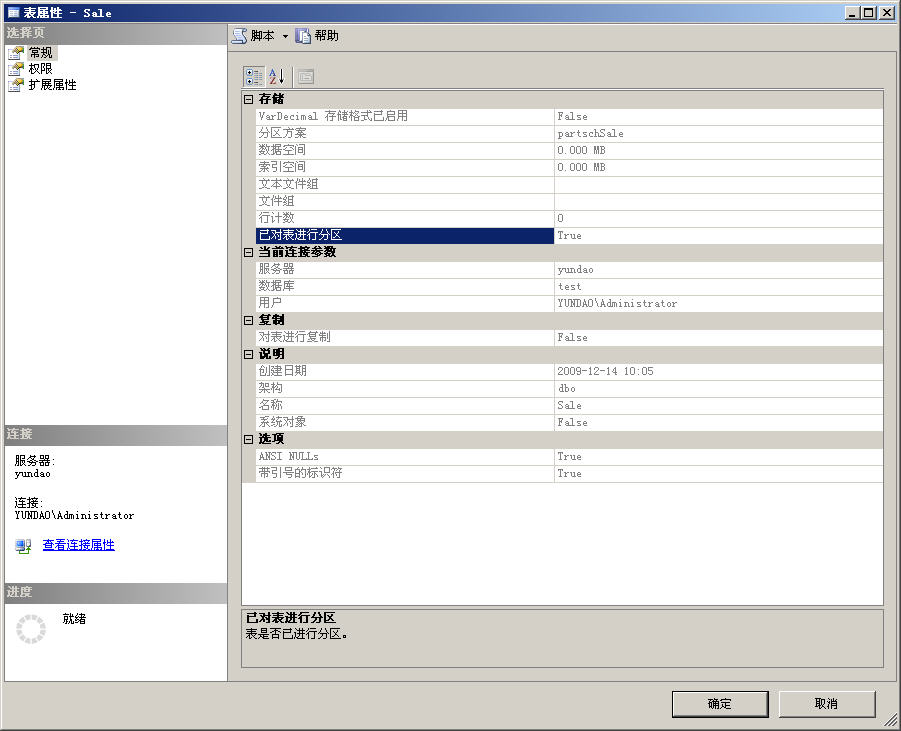
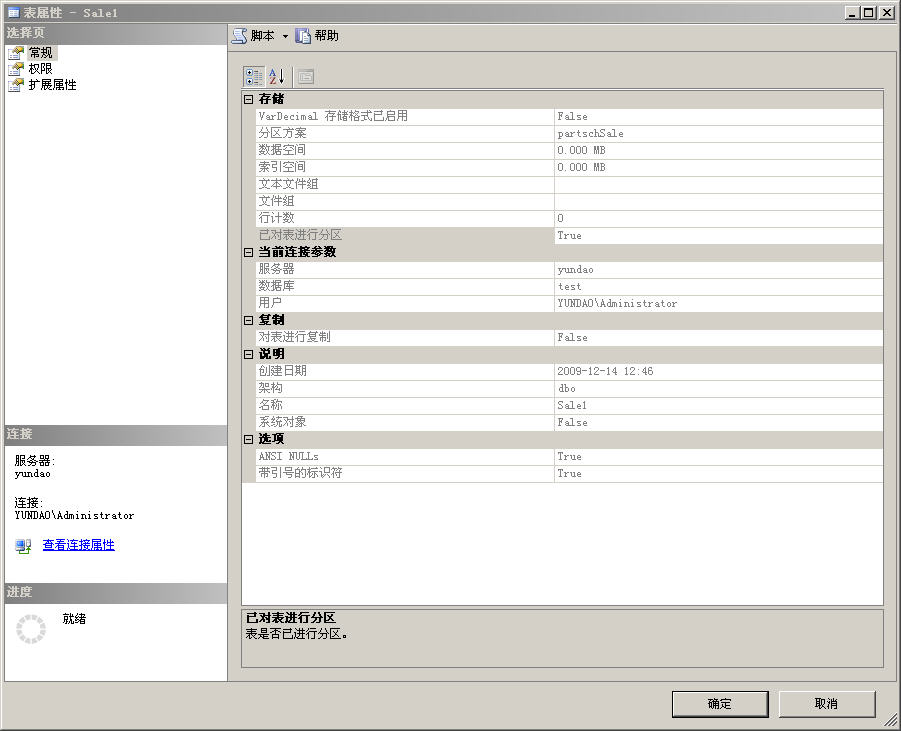
一开始,我还以为只要删除了分区索引,那么分区表就会自动转换成普通表了,可是在删除索引之后,查看一下该表的属性,结果还是已分区表,如下图所示。
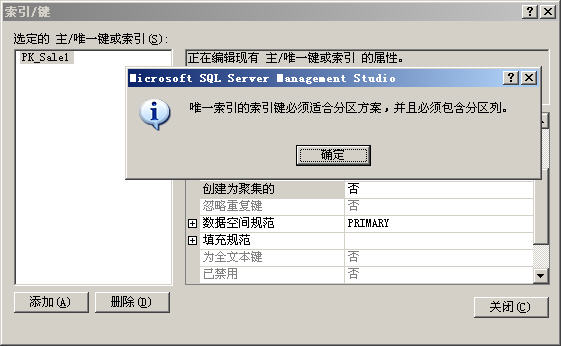
不但如此,而且,还不能将原来的聚集的唯一索引(在本例中为主键的那个索引)改成聚集索引,如下图所示。
如果要彻底解决这个问题,还必须要在原来创建分区索引的字段上重新创建一下索引,只有重新创建过索引之后,SQL Server才能将已分区表转换成普通表。在本例中可以使用以下代码重新创建索引。
- CREATE CLUSTERED INDEX CT_Sale1 ON Sale1([SaleTime])
- ON [PRIMARY]
- Go
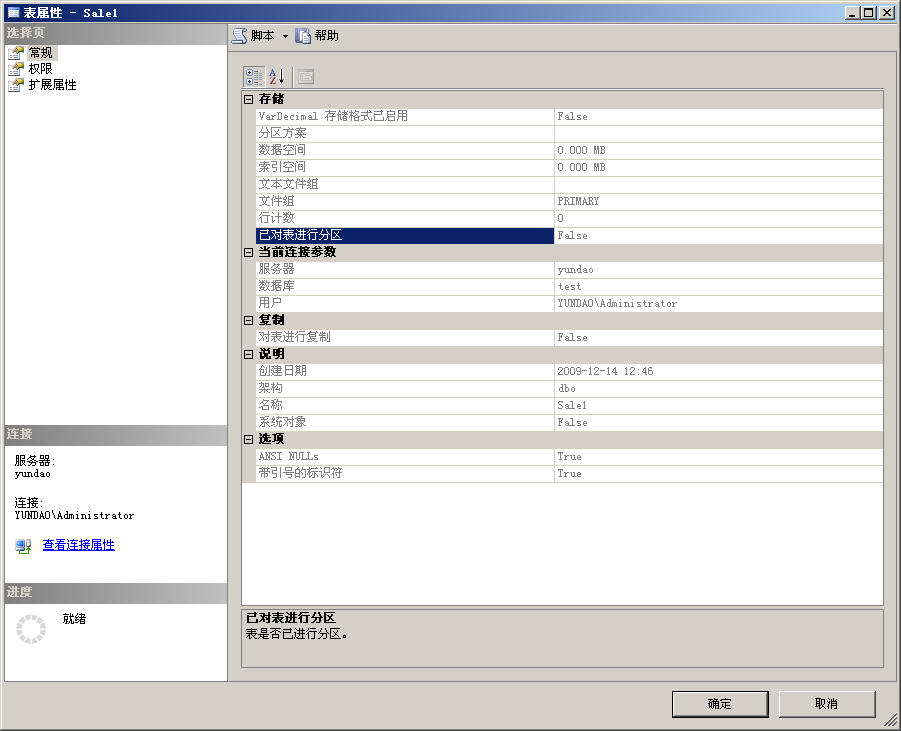
重建索引之后,分区表就变成了普通表,现在再查看一下Sale1表的属性,我们可以看到原来的分区表已经变成了普通表,如下图所示。
当然,以上两个步骤也可以合成一步完成,也就是在重建索引的同时,将原索引删除。如以下代码所示:
- CREATE CLUSTERED INDEX CT_Sale1 ON Sale1([SaleTime])
- WITH ( DROP_EXISTING = ON)
- ON [PRIMARY]
按理说,在SQL Server Management Studio中的操作和使用SQL语句的操作是一样的,可是我在SQL Server Management Studio中将聚集索引删除后再在该字段上重新创建一个同名的索引,并重新生成和组织该索引,可是分区表还是没有变成普通表,这就让我百思不得其解了。不过呢,只要能用SQL语句达到目的,那我们就用它吧。















 1676
1676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









