







DataX是一个由阿里巴巴开源的数据同步工具,它被设计用于在各种数据源之间进行高效的数据迁移和同步。以下是DataX的一些关键特性和应用实例,可以帮助您了解它如何作为数据归档工具使用
DataX简介
DataX支持从一个地方读取数据并以极快的速度写入到另一个地方,常见的使用场景包括将数据从一个MySQL数据库同步到另一个MySQL数据库,或者从MySQL同步到MongoDB等。
DataX工作流程
DataX的工作流程包括以下几个步骤:
- read:设置一个源,DataX从源读取数据。
- write:设置一个目的地,DataX将读取到的数据写入目的地。
- setting:同步设置,例如设置并发通道、控制作业速度等。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲、流控、并发、数据转换等核心技术问题。
- 多线程:充分利用多线程来处理同步任务。
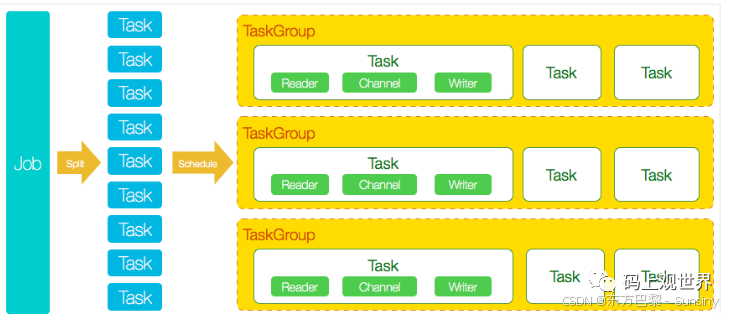
DataX核心架构
DataX的核心架构包括Job、Task和TaskGroup,支持并发执行。DataX Job模块是单个作业的中枢管理节点,负责数据清理、子任务切分和TaskGroup管理。Task是DataX作业的最小单元,每个Task负责一部分数据的同步工作。TaskGroup负责以一定的并发运行完毕分配好的所有Task。
DataX支持的数据源
DataX支持多种数据源,包括RDBMS、NoSQL和无结构化数据存储。例如,它可以从MySQL读取数据并同步到ClickHouse。
DataX部署和使用
DataX的部署相对简单,解压即可使用。用户需要编写同步任务配置文件,然后通过执行命令python bin/datax.py job.json来启动同步任务。
DataX在数据归档中的应用
DataX可以用于数据归档,因为它能够高效地从源数据库读取数据并将其同步到目标数据库或数据仓库,这对于数据备份和历史数据归档非常有用。例如,您可以使用DataX将生产数据库中的数据同步到一个归档数据库中,以便于历史数据分析和报告。
综上所述,DataX作为一个强大的数据同步工具,非常适合用于数据归档任务,它能够处理大量数据的迁移和同步,同时保持高效率和稳定性。
使用案例
windows上安装一个python(最好和我的保持一致)
去阿里巴巴那边下载datax的安装包,也可以找我私聊要
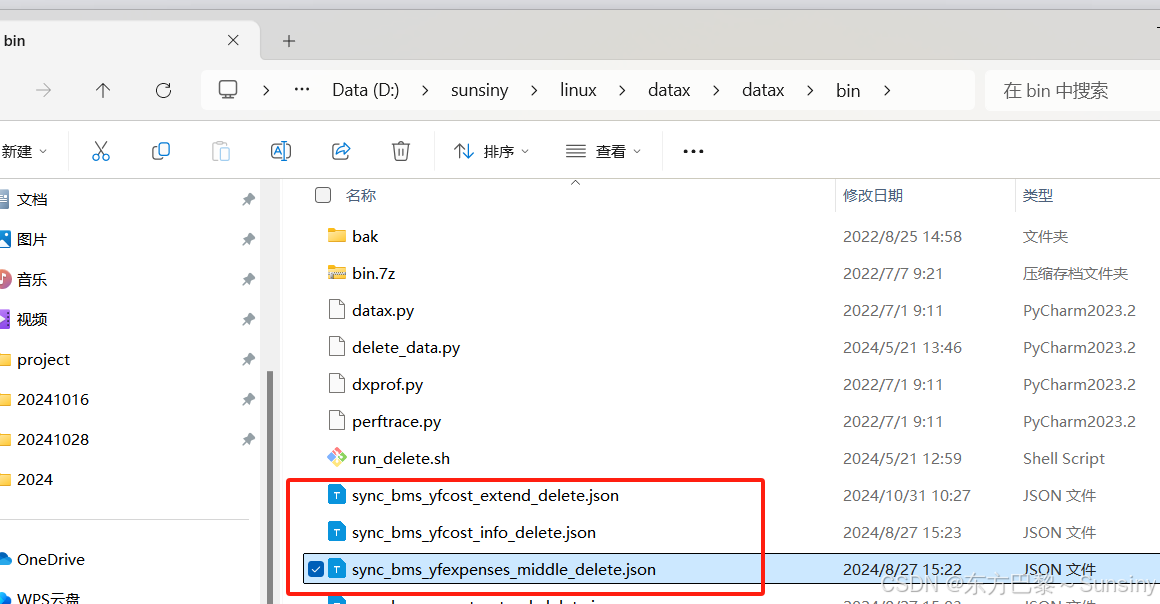
同步数据的脚本
{
"job": {
"setting": {
"speed": {
"channel": 5,
"record": 5000
},
"errorLimit": {
"record": 0,
"percentage": 0.001
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "mita",
"password": "mita",
"column": [
"*"
],
"splitPk": "id",
"connection": [
{
"querySql": [
"select t1.* from bms_yfcost_extend t1 left join bms_yfcost_info t2 on t1.expenses_id = t2.id where t2.business_time < '2024-05-27 00:00:00' and t2.del_flag = 1 and t1.del_flag = 1 GROUP BY t1.id"
],
"jdbcUrl": [
"jdbc:mysql://mita:3306/mita?autoReconnect=true&useUnicode=true&characterEncoding=utf8"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "mita",
"password": "mita",
"column": [
"*"
],
"session": [
"set session sql_mode='ANSI'"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://mita:3306/mita?useUnicode=true&characterEncoding=utf8",
"table": [
"bms_yfcost_extend_delete"
]
}
]
}
}
}
]
}
}
执行同步的命令
切换到你datax的安装目录bin下:
py -2 datax.py sync_bms_yfcost_extend_delete.json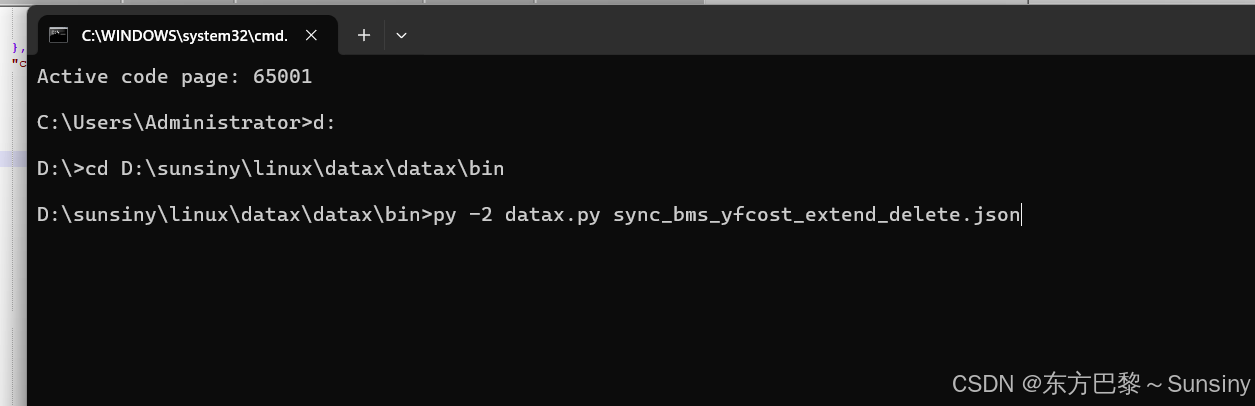
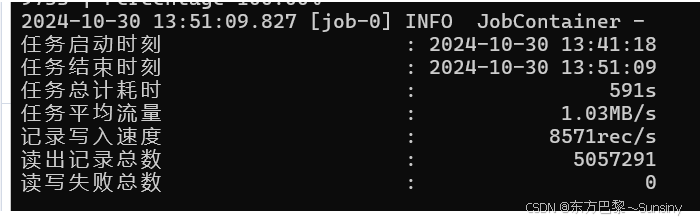
同步成功的标志:
学废了吗
🔍 DataX支持哪些数据转换功能?
DataX支持的数据转换功能主要包括以下几个方面:
-
字段类型转换:
DataX支持多种内部数据类型,包括Long、Double、String、Date、Bool和Bytes,以及它们之间的相互转换。例如,可以将一个日期类型的字段转换为字符串类型,或者将浮点数转换为整数等。 -
脏数据处理:
DataX能够识别和处理脏数据,包括类型转换错误、写入目标端失败的数据等。用户可以设置脏数据阈值,当超过这个阈值时,DataX作业会报错退出。 -
数据脱敏和补全:
DataX提供了数据脱敏和补全的功能,可以在数据传输过程中对敏感数据进行脱敏处理,或者对缺失的数据进行补全。 -
过滤功能:
DataX允许用户在数据同步过程中对数据进行过滤,只同步符合特定条件的数据。 -
自定义Transformer:
DataX支持自定义Transformer,用户可以编写自己的转换逻辑来实现特定的数据转换需求。这包括Java类或者Groovy脚本,用户可以在DataX的架构中加入这些自定义转换。 -
Groovy函数:
DataX内置了Groovy函数,用户可以直接在配置文件中使用Groovy脚本来实现复杂的数据转换逻辑。 -
JavaScript函数:
DataX还支持使用JavaScript函数进行数据转换,用户可以利用JavaScript的灵活性来处理数据转换需求。 -
自动类型转换:
DataX在Reader和Writer之间传输数据时,会自动进行类型转换,以确保数据在不同数据源之间能够正确地传输。 -
丰富的数据转换功能:
DataX作为一个服务于大数据的ETL工具,提供了丰富的数据转换功能,包括数据脱敏、补全、过滤等,以及自动的Groovy函数,让用户自定义转换函数。
通过这些数据转换功能,DataX能够满足用户在数据同步过程中的多样化需求,实现数据的高效、准确传输。
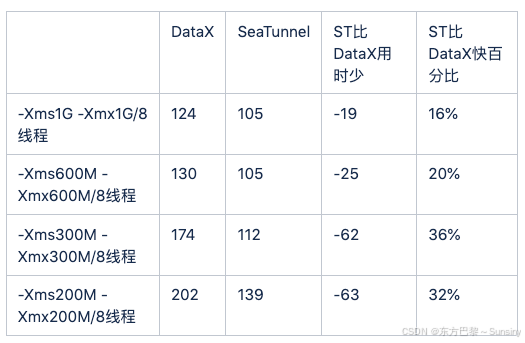
🔧 能否分享一些实际调优DataX性能的案例?
以下是一些实际调优DataX性能的案例:
1. DataX全局速度控制优化
在DataX内部,对每个Channel会有严格的速度控制,包括每秒同步的记录数和字节数。默认的速度限制是1MB/s,但可以根据具体硬件情况设置这个byte速度或者record速度。例如,可以配置单个Channel的速度上限为5MB,以提升传输速度:
{
"core": {
"transport": {
"channel": {
"speed": {
"byte": 5242880,
"record": 500
}
}
}
},
"job": {
"setting": {
"speed": {
"channel": 5
}
}
}
}
通过调整这些参数,可以显著提升DataX的同步速度。
2. DataX Channel并发数优化
提升DataX Job内Channel并发数是另一种常见的优化手段。并发数等于taskGroup的数量乘以每个TaskGroup并发执行的Task数。可以通过配置全局Byte限速以及单Channel Byte限速,或者全局Record限速以及单Channel Record限速,或者直接配置Channel个数来实现:
{
"job": {
"setting": {
"speed": {
"channel": 10,
"record": -1,
"byte": -1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": ["id", "a"],
"splitPk": "id",
"connection": [
{
"table": ["test", "test_1", "test_2"],
"jdbcUrl": ["jdbc:mysql://localhost:3306/ws?useServerPrepStmts=true&cachePrepStmts=true"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "root",
"column": ["id", "a"],
"session": ["set session sql_mode='ANSI'"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://localhost:3306/ws1?useUnicode=true&characterEncoding=utf8",
"table": ["test"]
}
]
}
}
}
]
}
}
通过这种方式,可以有效地提升DataX处理大规模数据集的性能。
3. DataX JVM参数调整
当提升DataX Job内Channel并发数时,需要调整JVM堆参数以防止内存溢出等错误。通常建议将内存设置为4G或者8G,这个也可以根据实际情况来调整。调整JVM xms xmx参数的两种方式:一种是直接更改datax.py;另一种是在启动的时候,加上对应的参数:
python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" XXX.json
这样可以确保DataX在处理大量数据时不会因为内存问题而失败。
这些案例展示了如何通过调整DataX的配置参数来优化其性能,以适应不同的数据同步需求。
🚀 DataX与Spark相比的优势?
DataX与Spark相比,具有以下几个优势:
-
轻量级和易部署:
DataX作为一个轻量级的数据同步工具,部署起来相对简单,不需要像Spark那样依赖于复杂的Hadoop生态系统。 -
丰富的数据源支持:
DataX支持多种数据源,包括MySQL、ODPS、PostgreSQL、Hive等20多种数据源,对于关系型数据库和Hadoop生态圈的大数据存储具有较好的支持。 -
插件式开发和扩展性:
DataX采用插件式开发,易于扩展。开发者可以根据业务需求开发自定义的Reader、Writer和Transformer插件,适合根据业务进行二次开发和增强。 -
单机多线程处理:
DataX任务是单机多线程的,可以在单个机器上利用多核优势进行并行数据处理,而不需要分布式集群的支持。 -
专注于数据同步:
DataX主要专注于数据同步,特别是离线数据同步,对于需要快速、高效地在不同数据源之间迁移大量数据的场景非常适用。 -
性能优化:
DataX提供了多种调优参数,如全局速度控制、并发Channel数等,可以根据具体的硬件情况和业务需求进行性能调优。 -
社区活跃度:
尽管DataX社区活跃度相对较低,但它仍然有一定的社区支持和文档资源,可以帮助用户解决使用过程中遇到的问题。
综上所述,DataX在数据同步领域具有一定的优势,特别是在轻量级部署、丰富的数据源支持、单机处理能力以及插件式扩展性方面。对于不需要分布式计算能力的场景,DataX是一个不错的选择。而Spark则更适用于需要大规模分布式计算的场景。
🤔 在DataX中,如何自定义Reader和Writer插件?
要在DataX中自定义Reader和Writer插件,可以遵循以下步骤:
1. 新建模块
首先,从DataX的GitHub仓库克隆代码,并在项目中新建一个Maven模块用于开发你的插件。
2. 配置插件模块
插件模块的目录和文件需要满足一定的约定。具体来说,插件模块的源代码结构应该如下:
${PLUGIN_HOME}/libs:插件的依赖库。${PLUGIN_HOME}/plugin-name-version.jar:插件本身的jar包。${PLUGIN_HOME}/plugin.json:插件描述文件。
3. 编写插件代码
根据DataX提供的SPI(Service Provider Interface),实现自定义的Reader或Writer插件。通常需要继承DataX的Reader和Writer类,并实现相应的方法。
4. 插件描述文件plugin.json
在plugin.json文件中,定义插件的名称、类全限定名、描述、开发者等信息。例如:
{
"name": "mysqlreader",
"class": "com.alibaba.datax.plugin.reader.mysqlreader.MysqlReader",
"description": "useScene: prod. mechanism: Jdbc connection using the database, execute select sql, retrieve data from the ResultSet. warn: The more you know about the database, the less problems you encounter.",
"developer": "alibaba"
}
5. 插件配置模板plugin_job_template.json
创建plugin_job_template.json文件,定义插件的配置参数模板,用户将根据此模板配置作业参数。
6. 编译和打包
使用Maven进行编译和打包,确保插件能够被正确编译成jar包,并放置在正确的目录下。
7. 集成到DataX
将自定义插件的模块添加到DataX的主pom.xml文件中,并在主package.xml文件中添加插件的打包内容,以便将插件集成到DataX的整体打包中。
8. 测试插件
开发完成后,通过执行mvn clean package -DskipTests assembly:assembly命令生成DataX的可执行包,并进行测试。
9. 调试和优化
根据测试结果调试和优化插件代码,确保插件能够稳定运行,并满足性能要求。
以上步骤提供了一个基本的框架,用于在DataX中开发和集成自定义的Reader和Writer插件。具体的实现细节和代码编写将取决于所处理的数据源特性和业务需求。
🤖 DataX支持哪些类型的数据源?
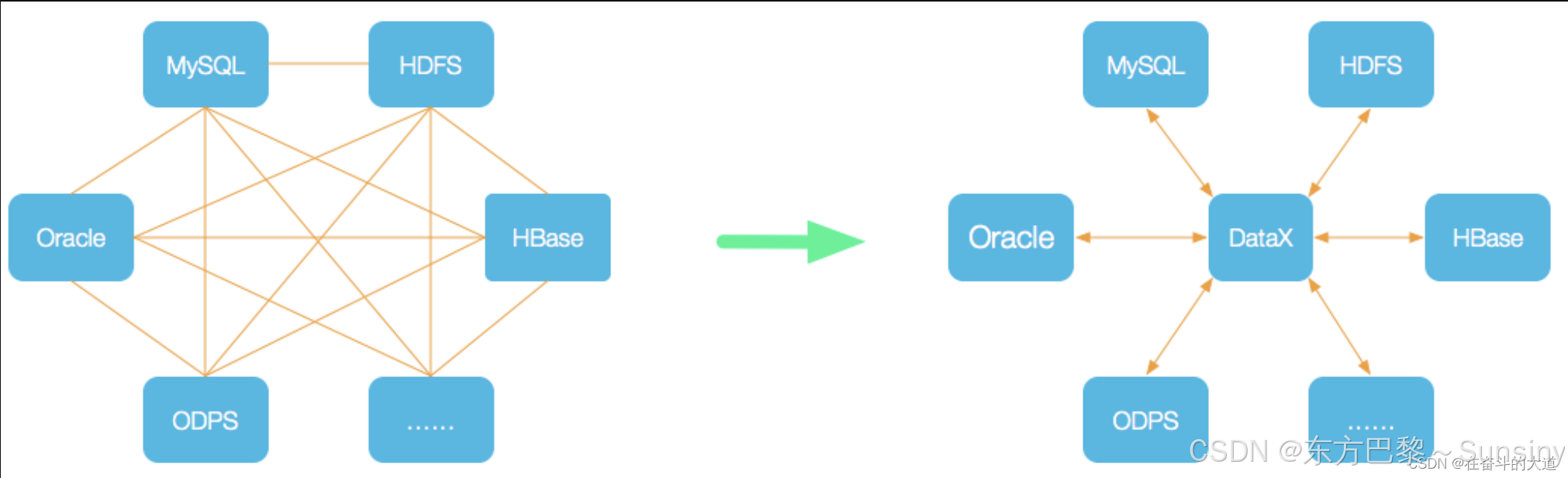
DataX支持的数据源类型非常广泛,涵盖了主流的关系型数据库、NoSQL数据库、大数据计算系统以及无结构化数据存储等。以下是DataX支持的一些主要数据源类型:
-
RDBMS关系型数据库:
- MySQL
- Oracle
- SQLServer
- PostgreSQL
- DRDS(阿里云数据库)
- 通用RDBMS(支持所有关系型数据库)
-
阿里云数仓数据存储:
- ODPS(阿里云MaxCompute)
- ADS(阿里云分析型数据库)
- OSS(阿里云对象存储服务)
- OCS(阿里云缓存服务)
-
NoSQL数据存储:
- OTS(阿里云表格存储)
- Hbase 0.94
- Hbase 1.1
- Phoenix 4.x
- Phoenix 5.x
- MongoDB
- Hive
- Cassandra
-
无结构化数据存储:
- TxtFile(文本文件)
- FTP(文件传输协议)
- HDFS(Hadoop分布式文件系统)
- Elasticsearch
-
时间序列数据库:
- OpenTSDB
- TSDB
DataX通过Reader和Writer插件实现数据源的读取和写入,采用Framework+plugin架构,使其具有很好的扩展性。每接入一套新数据源,该新加入的数据源即可实现和现有的数据源互通。
🤔 DataX的数据迁移效率如何?

DataX的数据迁移效率是非常高的,这得益于其优秀的架构设计和多种优化策略。以下是一些关键点来说明DataX的数据迁移效率:
-
插件化架构:
DataX采用插件化架构,支持多种数据源和数据存储系统之间的数据同步。这种架构使得DataX可以轻松扩展以支持新的数据源,同时保持高效的数据同步能力。 -
并发数据写入和流处理:
DataX通过并发数据写入和流式处理来实现高效的数据同步。它可以启动多个作业并发写入,显著减少总的迁移时间,相较于其他工具如Apache Sqoop,DataX在默认配置下就能提供更好的性能。 -
故障恢复能力:
DataX具备故障恢复的能力,在同步过程中如果出现失败,DataX可以从上次成功的地点继续同步,而不是从头开始,这为长时间运行的大数据处理作业节省了宝贵的时间和资源。 -
性能调优:
DataX提供了丰富的性能调优选项,包括全局速度控制、并发Channel数、JVM参数调整等。通过合理配置这些参数,可以进一步提升DataX的同步效率。 -
网络和硬件优化:
DataX的性能也受到网络带宽和硬件资源的影响。通过优化网络环境和充分利用硬件资源,可以进一步提升DataX的数据同步速度。 -
实际性能测试:
在实际的性能测试中,DataX展现出了优异的性能。例如,在将数据从MySQL同步到HDFS的场景下,DataX相比于其他同步工具,能够实现更快的同步速度。 -
社区支持和持续优化:
DataX有一个活跃的社区,定期发布更新和修复bug,同时持续开发新的功能特性以满足更广泛的应用需求,这也保证了DataX能够不断适应技术发展趋势,保持高效的数据同步能力。
综上所述,DataX的数据迁移效率是非常高的,它通过多种优化策略和强大的社区支持,为用户提供了一个高效、稳定、可扩展的数据同步解决方案。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











