






Redis 缓存有哪些淘汰策略?
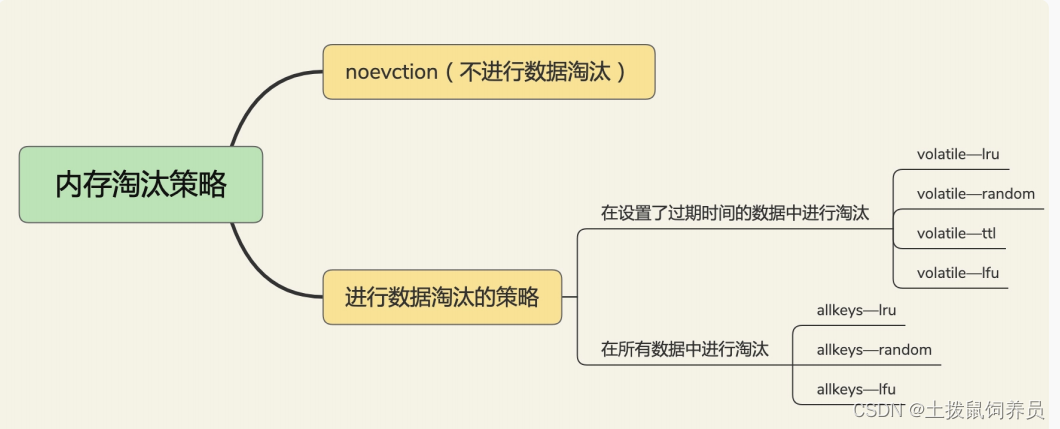
- 默认,超过maxmeory时,不会淘汰数据,noevction策略,redis不提供服务。
设置过期时间的淘汰 - volatile-ttl:根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random:随机进行删除
- volatile-lru:LRU算法淘汰(最近最少使用)
- volatile-lfu:LFU算法淘汰,在lru的基础上考虑了访问时效性和访问次数
所有数据淘汰
- allkeys-random:所有key中随机删除
- allkeys-lru:LRU 算法进行筛选
- allkeys-lfu:LFU 算法进行筛选
由于普通的lru算法依赖链表,并且需要移动,会降低redis的性能。
redis进行了简化。
- 记录每个数据的最近访问时间,redisobject的lru字段
- 在决定淘汰数据时,随机选择N个数据,将其中lru最小的数据淘汰。
maxmemory-samples中配置候选数据集- 再次淘汰数据时,挑选数据放入前一次被淘汰的集合,入选的数据的lru字段需要小于候选集合中最小的lru值。
lfu
- 为每个数据添加计数器,过期时把访问次数最低的淘汰,相同的话,淘汰上一次访问时间最久的。
- 把原来24bit的lru字段,变成了 16+8bit, ldt(访问时间戳) + counter(数据的访问次数)
- 8bit最大255,如果超过255counter值就一样了,这样根据时间淘汰就不太合理了
- lfu进行了优化:每当数据被访问一次时,首先,用计数器当前的值乘以配置项 lfu_log_factor 再加 1,再取其倒数,得到一个 p 值;然后,把这个 p 值和一个取值范围在(0,1)间的随机数 r 值比大小,只有 p 值大于 r 值时,计数器才加 1
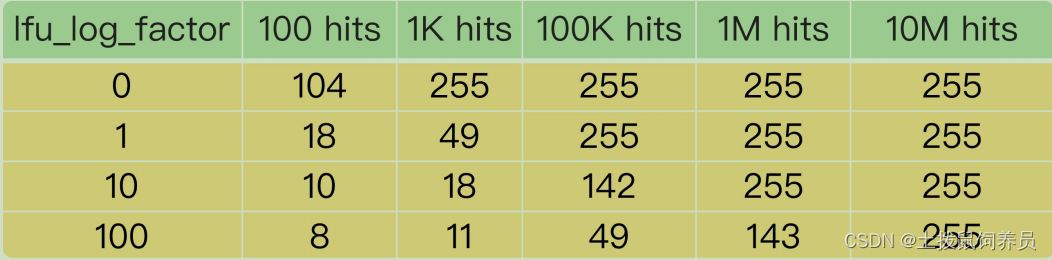
- 还实现了counter值的衰减机制,LFU 策略使用衰减因子配置项 lfu_decay_time 来控制访问次数的衰减。LFU 策略会计算当前时间和数据最近一次访问时间的差值,并把这个差值换算成以分钟为单位。然后,LFU 策略再把这个差值除以 lfu_decay_time 值,所得的结果就是数据 counter 要衰减的值。
- 如果业务应用中有短时高频访问的数据的话,建议把 lfu_decay_time 值设置为 1,这样一来,LFU 策略在它们不再被访问后,会较快地衰减它们的访问次数
LRU 策略更加关注数据的时效性,而 LFU 策略更加关注数据的访问频次。
- 如果数据有明显的冷热数据,优先使用allkeys-lru
- 没有明显的冷热数据,优先选择allkeys-random
- 如果有置顶的业务,使用 volatile-lru,同时不设置过期时间
缓存雪崩
- 缓存中有大量数据同时过期,导致大量请求无法得到处理。
- 给过期时间添加随机时间
- 服务降级:非核心数据暂停查询缓存,返回预定义信息、空值、或者报错,核心数据 任然可以查询数据库
- redis宕机
- 服务熔断和请求限流
- 搭建集群
缓存击穿
- 热点数据访问缓存失效
- 不设置过期时间。
缓存穿透
-
数据既不在redis也不在缓存
-
误操作:数据库数据和redis数据都被误删除
-
恶意攻击
- 缓存空值,
- 布隆过滤器(误判可能,空间和误判率的平衡,redis的布隆过滤器string实现,单独部署实例,big key问题)
- 请求前检测(对参数不合理,参数非法,字段不存在)直接过滤
- IP封禁
-
如果是刚上线没数据,这是正常情况
Redis分布式锁
Redlock
- 客户端获取当前时间。
- 客户端依次向N个Redis实例执行加锁操作。(客户端给一个实例超时没成功,会给下一个实例上锁,超时时间远小于锁的有效时间)
- 一旦客户端完成对所有实例的加锁操作,客户端就要计算加锁总耗时。
客户端满足下面两个条件,才认为是加锁成功。
- 客户端从超过半数(大于等于 N/2+1)的 Redis 实例上成功获取到了锁;
- 客户端获取锁的总耗时没有超过锁的有效时间。
Redis事务
原子性
事务正常执行,multi和exec可以保证原子性。
失败的话分情况。
- EXEC前,命令本来就错误,入队时会记录错误,EXEC拒绝执行所有错误,保证原子性。
- 事务入队,命令和数据类型不匹配,没检查出错误,错误命令报错,正确命令执行,无法保证原子性。
- 执行EXEC,Redis发生故障,事务失败。如果AOF记录了,可以把未执行的去除,但是没有开启就保证不了原子性。
一致性
- 入队就报错,可以保证。
- 如果没报错,执行报错,保证一致性。
- EXEC执行时故障,可以保证一致性。
隔离性
- 操作在EXEC前执行,通过WATCH保证,不然无法保证。
- 如果在WATCH之后,其他客户端修改了监控的键,就放弃事务执行。
- 并发操作在EXEC后执行,隔离性可以保证。
持久性
- RDB快照未执行前 宕机,持久性不能保证。
- AOF no,every,always都会存在数据丢失的情况。















 1756
1756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









