







一、背景和原理
指数平滑(Exponential Smoothing)是一种时间序列预测方法,广泛用于需求预测、销售预测和库存控制等领域。它通过给数据中的不同时间点赋予不同的权重,近期的数据被赋予更高的权重,从而使预测能更快地适应最新的数据趋势。即不舍弃过去的数据,但基于逐渐减弱并收敛为零的权重,从而以本期观察值和前一期指数平滑值加权平均数作为预测。
1.一次指数平滑(simple exponential smoothing)
适用于没有显著趋势和季节性变化的时间序列。
(1)原理公式
其中:
:时刻 t 的平滑值(预测值),
:时刻 t 的实际观察值,
:时刻 t-1 的平滑值,
:平滑系数,取值在 0 和 1 之间。
- 平滑系数
控制着预测的“灵敏度”。如果
- 一次指数平滑的预测只考虑了当前和过去的观测值,且没有考虑趋势或季节性。
2.二次指数平滑(Holt exponential smoothing)
适用于处理包含趋势但不包含季节性变化的时间序列。一次指数平滑仅适合于平稳的时间序列(没有明显趋势或季节性变化的情况),而二次指数平滑则能够在平滑原始数据的基础上,增加一个趋势项来捕捉数据的上升或下降趋势,能够更好地适应具有线性趋势的时间序列。
应用场景:
- 销售数据:预测未来的销量变化,适用于趋势较为稳定的产品销售。
- 需求预测:在生产计划中用于预测未来一段时间的需求量。
- 财务数据:分析和预测具有趋势性但无显著季节性的财务数据,如收入或支出。
(1)原理公式
- 加性模型:加性模型假设数据可以通过叠加多个成分(例如,水平、趋势和季节性)来表示。Holt’s 方法适用于无季节性,但有趋势的加性模型。
①水平平滑公式:对时间序列的水平值进行平滑
其中:
:时刻 t 的平滑水平值(对数据本身的平滑),
:时刻 t 的实际值,
:时刻 t-1 的平滑水平值,
:时刻 t-1 的平滑趋势项(对数据趋势的平滑),
:平滑系数,控制对实际观测值的敏感度,取值范围为 0 到 1
②趋势平滑公式——对时间序列中的趋势进行平滑
其中:
:时刻 \( t \) 的趋势项,
:水平值的变化量(即趋势的变化),
:趋势平滑系数,控制对趋势变化的敏感度,取值范围也是 0 到 1
平滑系数含义:
- 平滑系数
- 趋势平滑系数
:控制对趋势项的敏感度。较高的
(2)预测公式
通过水平项和趋势项的结合,可以得到未来时刻的预测值:
其中:
:时刻 t+h 的预测值,
h:预测步长(即向未来预测的步数)
(3)建模步骤
- 1.初始化:确定初始的平滑水平值
和趋势项
。
通常可以取为第一期的观测值
。
可以取为前两期观测值之差,即
,粗略估计趋势的初始值。
- 2.计算平滑水平值
- 3.预测未来值:通过最后一个时间点的平滑水平值
3.三次指数平滑(Holt-Winters exponential smoothing)
适用于具有趋势和季节性模式的时间序列。三次指数平滑在二次指数平滑的基础上,加入了一个季节项,从而能够更好地捕捉和预测含有季节性变化的数据。核心思想是对时间序列的三个要素进行平滑:
- 水平值:数据的整体水平。
- 趋势:数据随时间的上升或下降趋势。
- 季节性:数据的周期性波动。
应用场景:
- 零售销售预测:许多产品的销量呈现季节性波动(如节假日销售高峰)并随时间逐渐增长。
- 库存管理:季节性产品的需求预测,如冬季衣物、夏季饮料等,库存管理需要根据预测需求调整。
- 能源需求预测:电力、燃气等能源消耗通常会根据季节和时间逐渐增加。
- 流量预测:网站访问量、电信流量等数据会随时间和季节波动。
常用的三次指数平滑模型包括加法模型和乘法模型,分别适用于季节性幅度固定或随时间增大的数据。假设:
:时间 t 时的实际观测值
:时间 t 时的季节项,周期为 L
(1)加法模型
适用于季节性影响与时间序列水平值独立的情况,即季节性波动幅度固定不变。例如,冬季销量每年都会增加 100 个单位。
①水平项更新公式:
②趋势项更新公式:
③季节项更新公式:
预测公式:
(2)乘法模型
适用于季节性影响与时间序列水平值成比例的情况,即季节性波动幅度随着数据水平的变化而变化。例如,某产品销量在冬季增长 20%,而不是固定增加某个数量。
①水平项更新公式:
②趋势项更新公式:
③季节项更新公式:
预测公式:
其中:
:水平项的平滑系数,控制对最新观测值的敏感度。
:趋势项的平滑系数,控制对趋势变化的敏感度。
:季节项的平滑系数,控制对季节性变化的敏感度。
h:是预测的步长(即向未来预测的步数)。
:在季节周期 \( L \) 前的季节性因素,用于周期性的循环。
(3)建模步骤
- 1.初始化:确定初始的水平值
、趋势项
和季节项
可以取为第一个周期的数据平均值。
可以取为前两个周期的平均差。
可以通过对第一个周期内的各时间点的差异进行平均来初始化。
- 2.平滑计算:使用公式逐期更新每个时间点的水平项、趋势项和季节项。
- 3.预测未来值:在计算出最新的水平项、趋势项和季节项后,利用预测公式计算未来的值。
4.背景与数据
(1)问题背景
① 用于一次指数平滑【cod】:Bay City Seafood 公司拥有捕捞船队和鱼类加工厂。为了预测未来鳕鱼销售的最低和最高收入,公司希望通过对未来几个月的鳕鱼捕捞量进行点预测和区间预测。公司已记录了过去两年的月度捕捞量数据(月度数据)。
② 用于二次指数平滑【thermostat】:每周的恒温器销售数据(周度数据)。
③ 用于三次指数平滑【bike】:瑞士一家自行车商店在过去四年的季度山地车销售量(季度数据)。
(2)数据与基础设置:
数据示例(前十行):
| cod | thermostat | bike |
| 362 | 206 | 0 |
| 381 | 245 | 31 |
| 317 | 185 | 43 |
| 297 | 169 | 16 |
| 399 | 162 | 11 |
| 402 | 177 | 33 |
| 375 | 207 | 45 |
| 349 | 216 | 17 |
| 386 | 193 | 13 |
【cod】绘制过去两年的月度捕捞量时间序列图
plot.ts(cod)
abline(h=mean(cod),col='red')
# 添加一条红色的水平线,表示捕捞量的平均值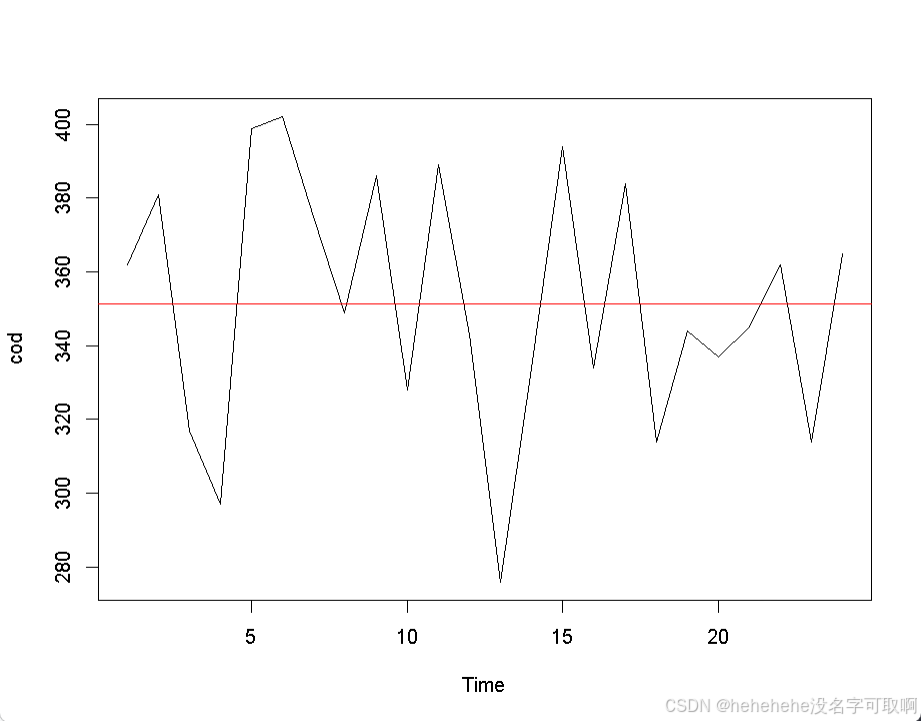
- 从图形可以观察到,数据在一个相对恒定的平均水平附近波动。
- 公司主观上认为这种波动模式会继续存在,因此可以使用简单的回归模型进行预测,即:
其中,y 表示捕捞量,T 是平均水平,e 是随机误差项。模型假设数据围绕一个恒定水平波动。
【thermostat】绘制时间序列图,显示恒温器销售量的变化趋势
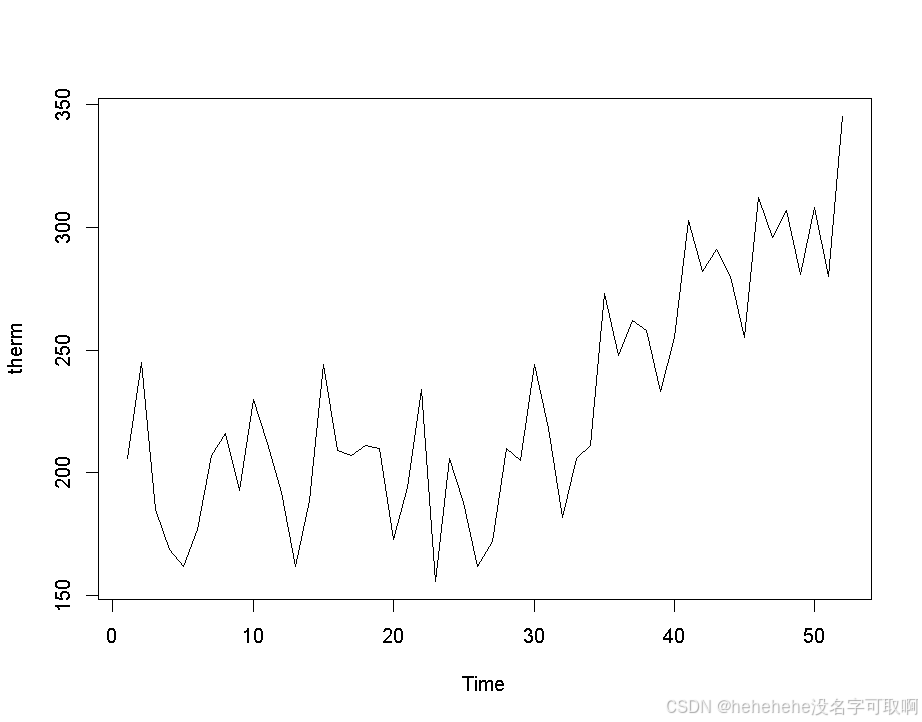
- 后期的几周内销售量出现了上升趋势,而且销售量的增长率在 52 周的时间内有所变化。
- 没有明显的季节性模式,因此适合使用 Holt's 趋势修正指数平滑法 来预测未来的销售量。
【bike】绘制时间序列图,显示山地车销售量随时间的变化
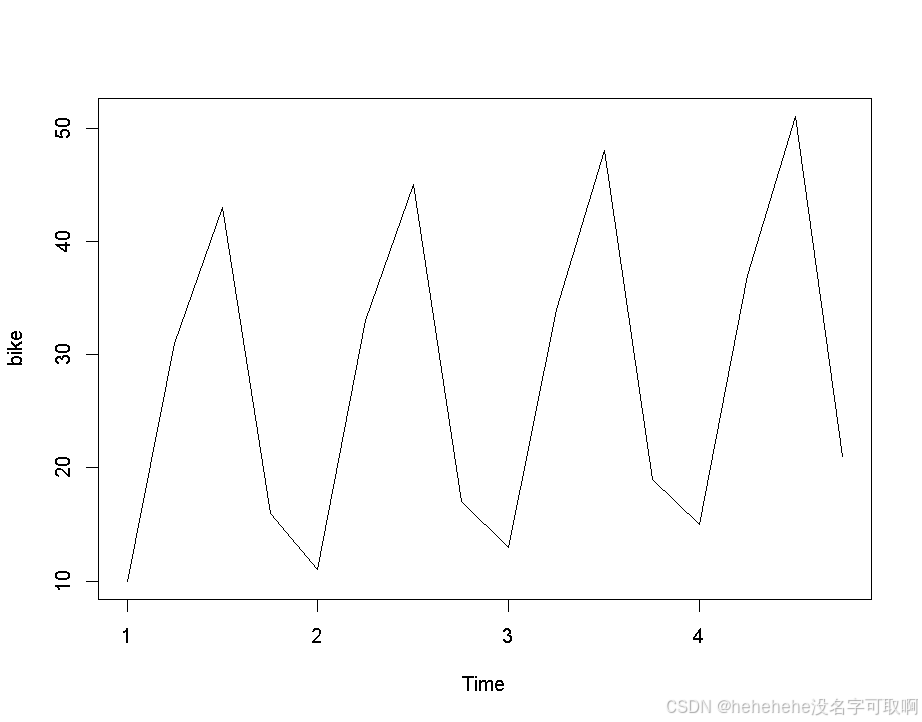
- 数据表现出一种线性需求增长趋势和固定的季节性变化。季节性变化的特点是每年销售量有规律地波动。
- 模式适合使用加性 Holt-Winters 方法进行预测,以找到未来山地车销售量的预测值。
二、一次指数平滑法预测
1.Holt-Winters()函数建模
codfit <- HoltWinters(cod, beta=FALSE, gamma=FALSE)
# beta=FALSE 和 gamma=FALSE 表示禁用趋势和季节性成分,仅使用简单的指数平滑方法。
codfit
plot(codfit)
Holt-Winters exponential smoothing without trend and without seasonal component.
HoltWinters(x = cod, beta = FALSE, gamma = FALSE)
Smoothing parameters:
alpha: 0.04627398
beta : FALSE
gamma: FALSE
Coefficients:
[,1]
a 353.4506
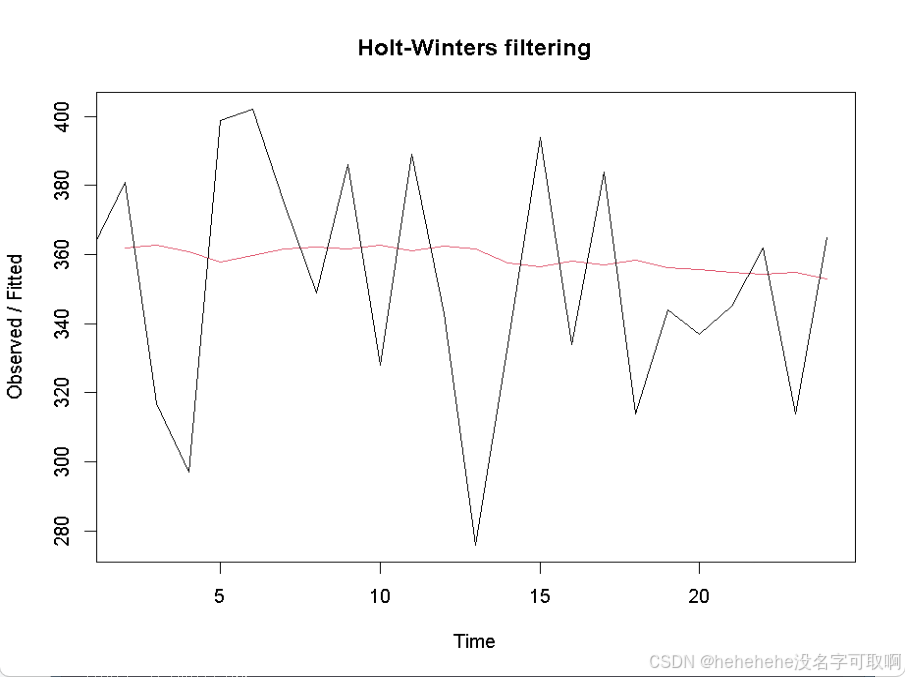
结果显示:平滑常数的值为 0.046,数据的水平成分变化不大,即捕捞量没有明显的变化趋势。
2.使用模型预测
codforecast <- forecast(codfit,h=8,level=95)
# 预测未来8个月的数据,预测区间的置信水平为 95%
codforecast
plot(codforecast)
lines(fitted(codfit)[,1], col = "red")
# 已拟合的值绘制为红色线条
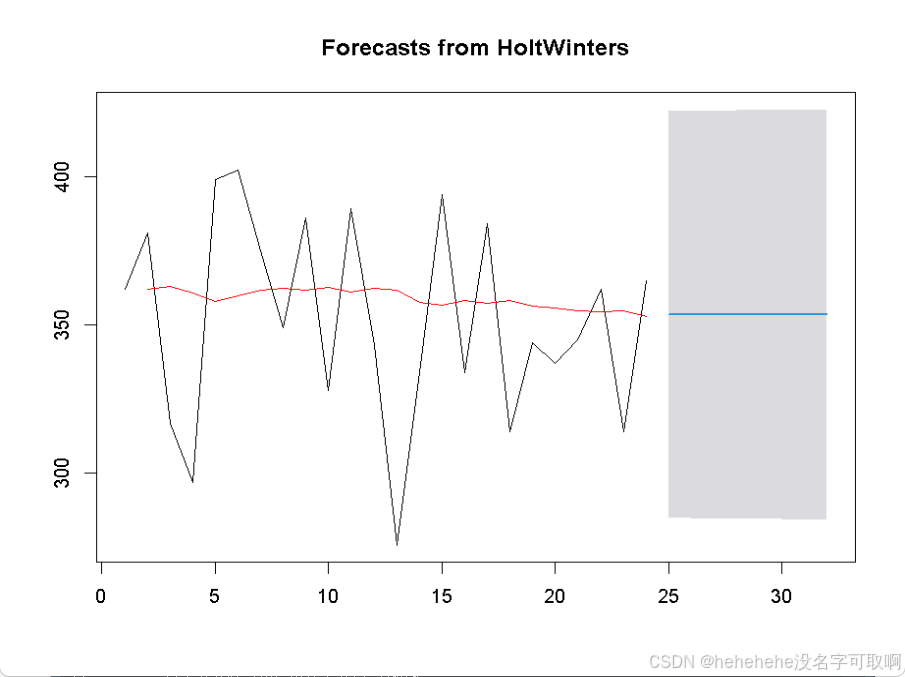
3.检查残差自相关性
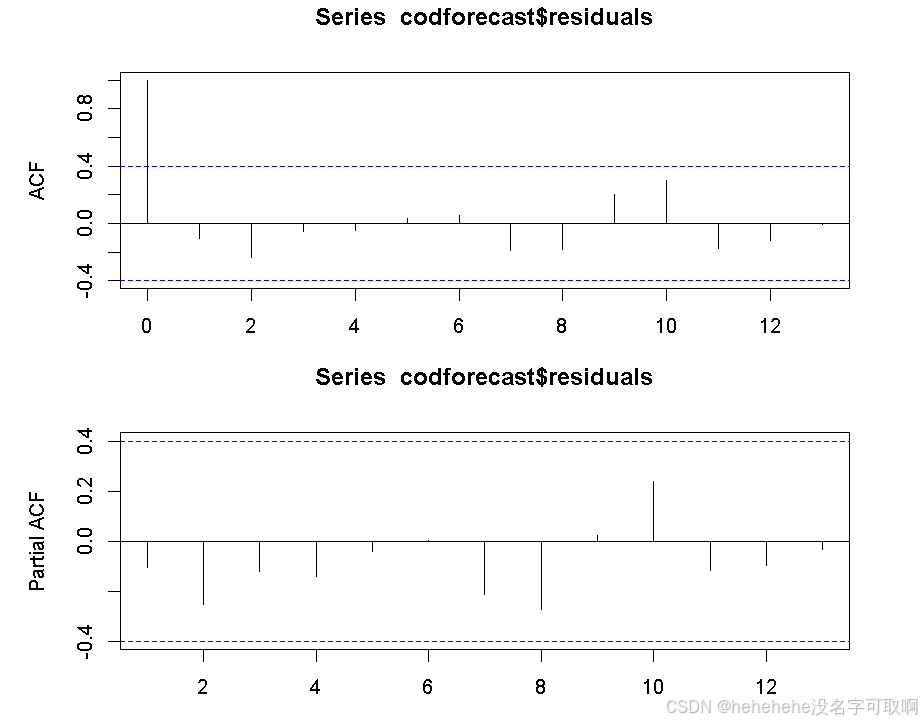
如果预测误差之间没有相关性(即 ACF 图中的相关性接近零),说明误差是随机的,模型已经足够好,无法通过其他模型显著改进。如果存在显著的自相关性,则说明可以尝试其他预测方法来改进模型。
par(mfrow=c(2,1), mar=c(3,5,3,3))
acf(codforecast$residuals, na.action = na.pass)
pacf(codforecast$residuals, na.action = na.pass)
三、 二次指数平滑法预测
1.Holt-Winters()函数建模
thermfit <- HoltWinters(therm, gamma=FALSE)
# gamma=FALSE:表示不使用季节性成分,适合无季节性但有趋势的数据
thermfit
plot(thermfit)
Holt-Winters exponential smoothing with trend and without seasonal component.
HoltWinters(x = therm, gamma = FALSE)
Smoothing parameters:
alpha: 0.6856771
beta : 0.1943463
gamma: FALSE
Coefficients:
[,1]
a 327.175169
b 7.542246
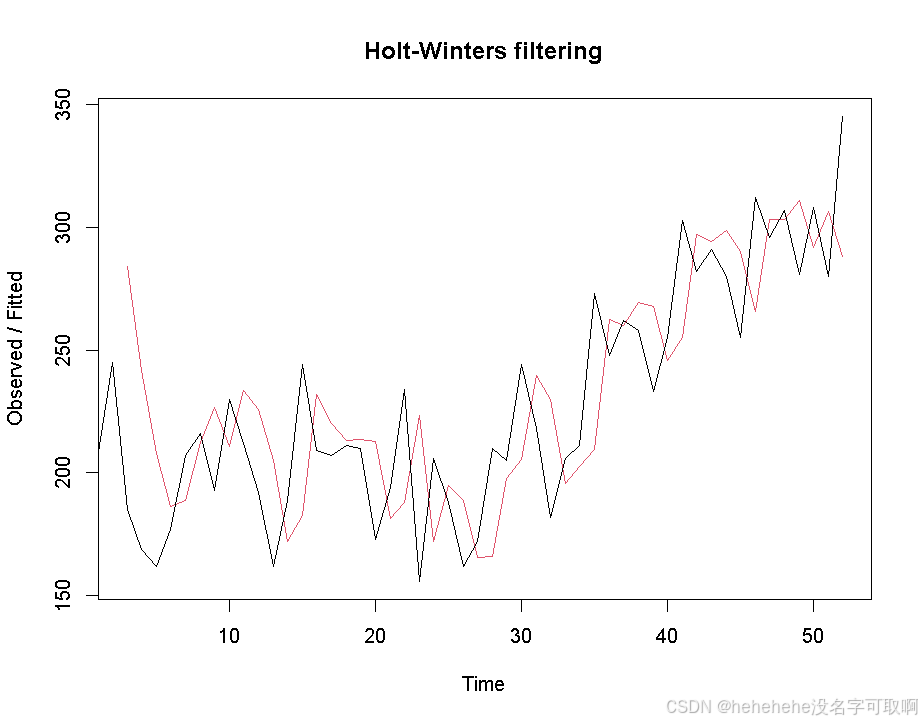
图像显示,样本内的预测值与观测值吻合得较好,虽然在某些数据点上会有轻微的滞后。这种滞后现象是指数平滑模型常见的问题,特别是在数据的趋势发生快速变化时,模型的更新速度可能稍慢,导致预测值略微滞后于实际数据。
2.使用模型预测
thermforecast <- forecast(thermfit, h=10,level=95)
# 预测未来10周数据
thermforecast
plot(thermforecast)
lines(fitted(thermfit)[,1], col = "red")
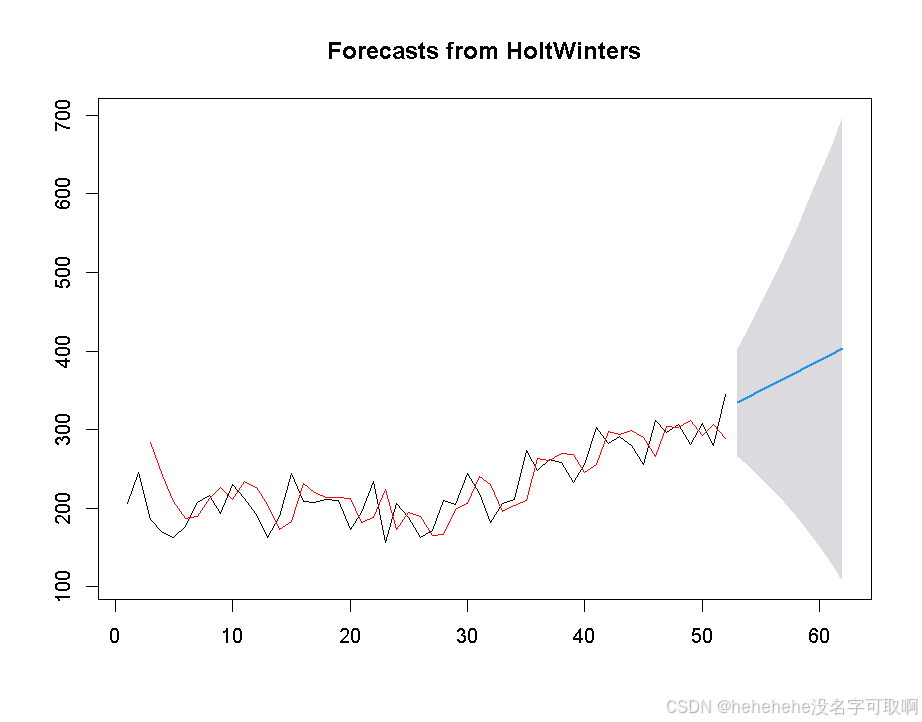 未来 10 周的预测值展示了销售量的上升趋势,并95% 置信区间提供了未来销售量的可能波动范围,红色线条表示历史数据的拟合值。
未来 10 周的预测值展示了销售量的上升趋势,并95% 置信区间提供了未来销售量的可能波动范围,红色线条表示历史数据的拟合值。
3.检查残差自相关性
par(mfrow=c(2,1), mar=c(3,5,3,3))
acf(thermforecast$residuals, na.action = na.pass)
pacf(thermforecast$residuals, na.action = na.pass)
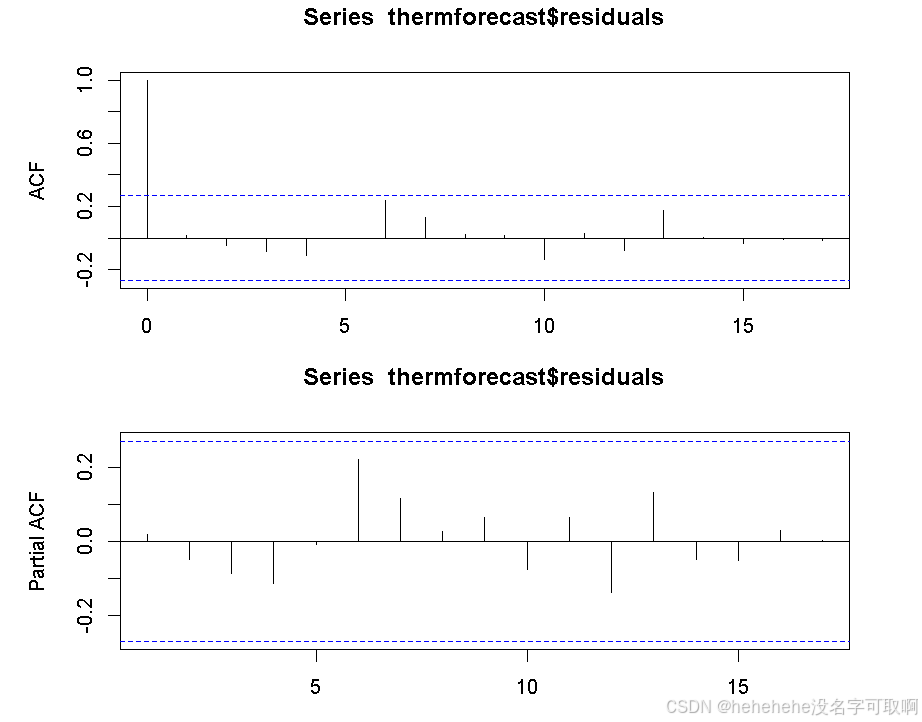
没有证据表明预测残差有非零的自相关性,即残差看起来是随机的,因此当前的预测模型(Holt’s 指数平滑法)已经足够好,不需要进一步改进。
四、 三次指数平滑法预测
1.Holt-Winters()函数建模
bikefit <- HoltWinters(bike)
# 没有指定 gamma=FALSE,默认情况下 HoltWinters() 会自动检测并应用季节性成分,即使用全参数(包括水平、趋势和季节性)
bikefit
plot(bikefit)
Holt-Winters exponential smoothing with trend and additive seasonal component.
HoltWinters(x = bike)
Smoothing parameters:
alpha: 0.05191289
beta : 1
gamma: 0.901122
Coefficients:
[,1]
a 31.1613613
b 0.5961108
s1 -14.3780066
s2 6.9750344
s3 20.3494562
s4 -10.1304749
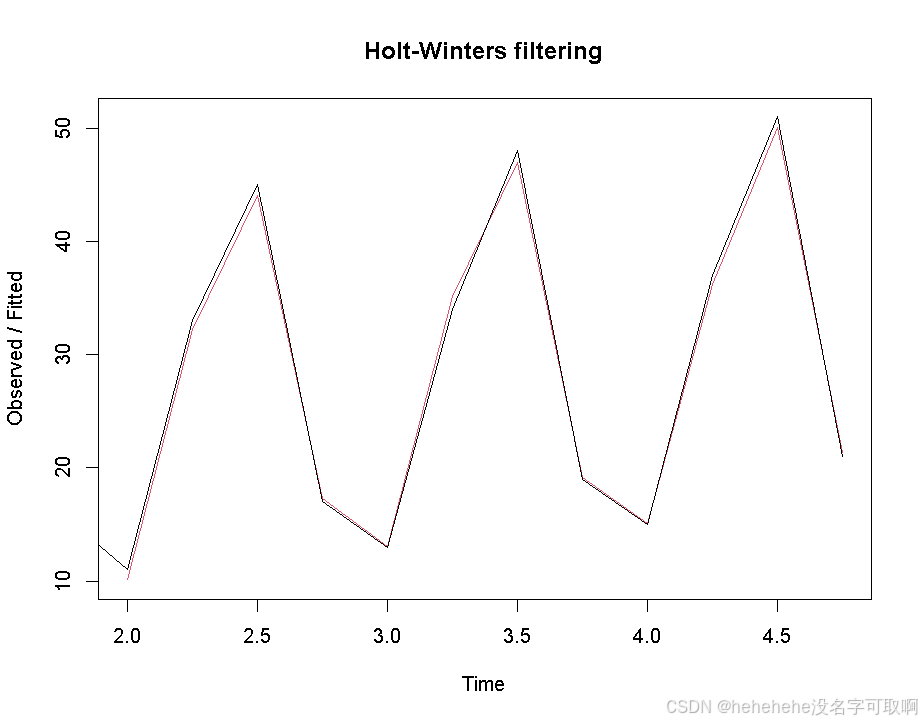
图像显示,样本内的预测值与观测值基本一致,尽管某些点上会有些微的滞后。这种滞后现象在指数平滑法中较常见,因为平滑方法的更新速度可能会略慢于数据的实际波动。
2.使用模型预测
bikeforecast <- forecast(bikefit, h=32, level=95)
# 预测未来32个季度的数据
bikeforecast
plot(bikeforecast)
lines(fitted(bikefit)[,1], col = "red")
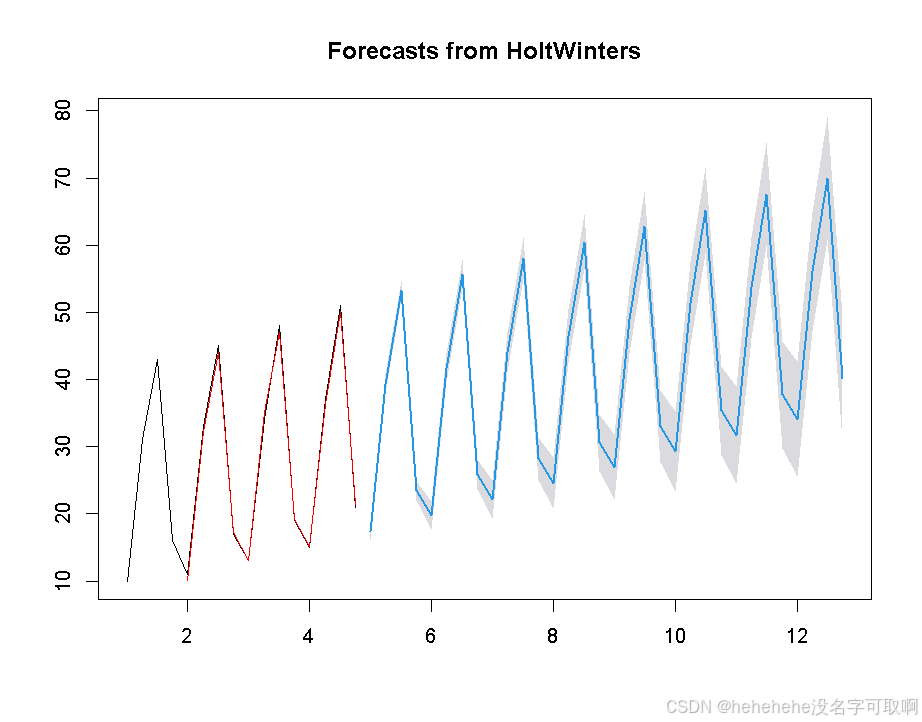
图像显示,未来几个季度的预测值展示了销售量的趋势和季节性波动,红色线条表示历史数据的拟合值。
3.检查残差自相关性
par(mfrow=c(2,1), mar=c(3,5,3,3))
acf(bikeforecast$residuals, na.action = na.pass)
pacf(bikeforecast$residuals, na.action = na.pass)
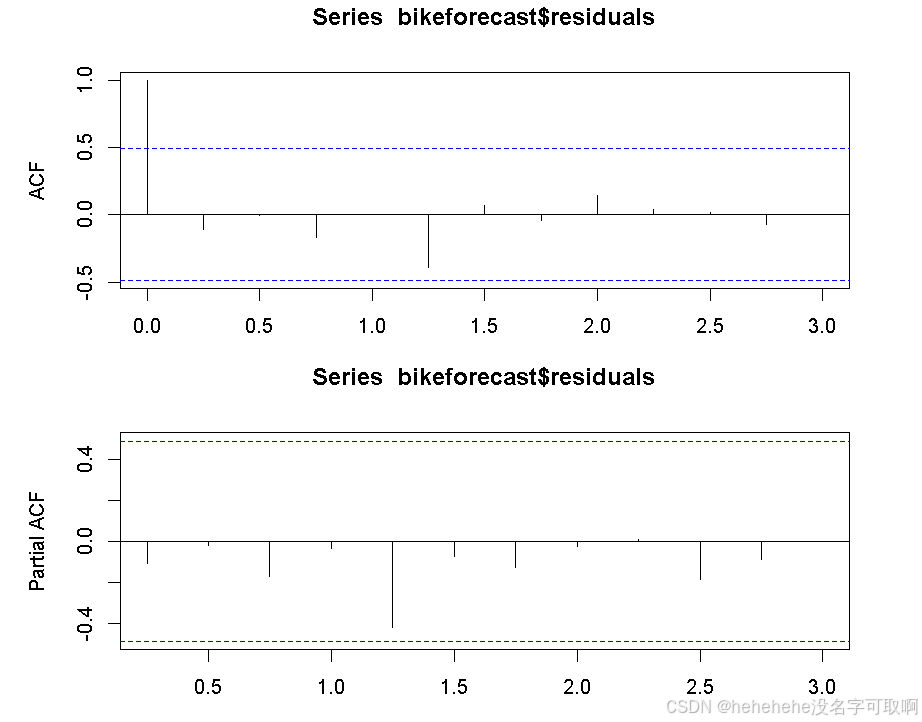
没有证据表明预测残差有非零的自相关性,即残差看起来是随机的,因此当前的预测模型已足够好。

















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









