









最近在做文本分析时,使用isalpha()或isupper()等(<ctype.h>,win7,VS2012)函数来判断一个字符是不是英文字母时,偶尔出错(File:f:\dd\vctools\crt_bld\self_x86\crt\src\isctype.c),如下图所示:
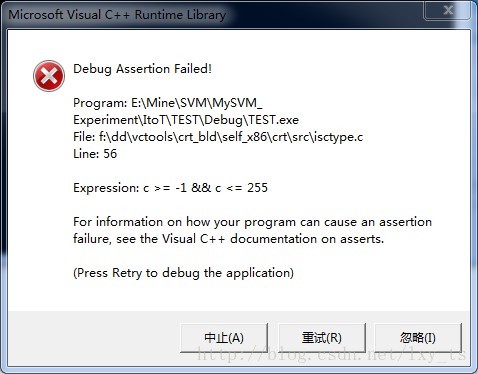
在网上找了半天,也没找到解决的办法。如是换了一种方法来做字母判断:#define LETTER(ch) ((ch>65&&ch<90)||(ch>97&&ch<122))
果然,问题解决了。
根据问题提示,分析问题出现的原因可能是isapha()函数只能对[-1,225]之间的字符做判断,而文本中可能有不在这个范围内的字符。















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









