










1.豆瓣电影搜索
2.豆瓣电影信息自动添加
搜索
众所周知,豆瓣搜索有加密,得解密才行,还好网上众多大神都给破解了,那咱们拿来直接使用就行
相关代码仓库:xadmin-server/movies/utils/douban/search.py at movies · nineaiyu/xadmin-server (github.com)
核心搜索并解密代码如下
import base64
import datetime
import plistlib
import re
import struct
from plistlib import FMT_BINARY, _BinaryPlistParser, _undefined
import requests
import xxhash
from Cryptodome.Cipher import ARC4
from math import floor
def _read_object(self, ref):
"""
read the object by reference.
May recursively read sub-objects (content of an array/dict/set)
"""
result = self._objects[ref]
if result is not _undefined:
return result
offset = self._object_offsets[ref]
self._fp.seek(offset)
token = self._fp.read(1)[0]
tokenH, tokenL = token & 0xF0, token & 0x0F
if token == 0x00:
result = None
elif token == 0x08:
result = False
elif token == 0x09:
result = True
# The referenced source code also mentions URL (0x0c, 0x0d) and
# UUID (0x0e), but neither can be generated using the Cocoa libraries.
elif token == 0x0f:
result = b''
elif tokenH == 0x10: # int
result = int.from_bytes(self._fp.read(1 << tokenL),
'big', signed=tokenL >= 3)
elif token == 0x22: # real
result = struct.unpack('>f', self._fp.read(4))[0]
elif token == 0x23: # real
result = struct.unpack('>d', self._fp.read(8))[0]
elif token == 0x33: # date
f = struct.unpack('>d', self._fp.read(8))[0]
# timestamp 0 of binary plists corresponds to 1/1/2001
# (year of Mac OS X 10.0), instead of 1/1/1970.
result = (datetime.datetime(2001, 1, 1) +
datetime.timedelta(seconds=f))
elif tokenH == 0x40: # data
s = self._get_size(tokenL)
result = self._fp.read(s)
if len(result) != s:
raise plistlib.InvalidFileException()
elif tokenH == 0x60: # ascii string
s = self._get_size(tokenL)
data = self._fp.read(s)
if len(data) != s:
raise plistlib.InvalidFileException()
result = data.decode('ascii')
elif tokenH == 0x50: # unicode string
s = self._get_size(tokenL) * 2
data = self._fp.read(s)
if len(data) != s:
raise plistlib.InvalidFileException()
result = data.decode('utf-16be')
elif tokenH == 0x80: # UID
# used by Key-Archiver plist files
result = plistlib.UID(int.from_bytes(self._fp.read(1 + tokenL), 'big'))
elif tokenH == 0xA0: # array
s = self._get_size(tokenL)
obj_refs = self._read_refs(s)
result = []
self._objects[ref] = result
result.extend(self._read_object(x) for x in obj_refs)
# tokenH == 0xB0 is documented as 'ordset', but is not actually
# implemented in the Apple reference code.
# tokenH == 0xC0 is documented as 'set', but sets cannot be used in
# plists.
elif tokenH == 0xD0: # dict
s = self._get_size(tokenL)
key_refs = self._read_refs(s)
obj_refs = self._read_refs(s)
result = self._dict_type()
self._objects[ref] = result
try:
for k, o in zip(key_refs, obj_refs):
result[self._read_object(k)] = self._read_object(o)
except TypeError:
raise plistlib.InvalidFileException()
else:
raise plistlib.InvalidFileException()
self._objects[ref] = result
return result
_BinaryPlistParser._read_object = _read_object
def crypto_rc4(raw_data: bytes, sec_key: str):
cipher = ARC4.new(sec_key.encode())
rc4_bytes = cipher.encrypt(raw_data)
return rc4_bytes
def search_from_douban(key):
url = f'https://search.douban.com/movie/subject_search?search_text={key}&cat=1002'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
}
res = requests.get(url, headers=headers)
print(f"search douban url: {res.status_code} {res.content}")
data = re.search(r'window.__DATA__ = "(.+?)"', res.text, flags=re.DOTALL).group(1)
# print(data)
i = 16
a = base64.b64decode(data)
s = floor((len(a) - 2 * i) / 3)
u = a[s: s + i]
raw_bytes = a[0:s] + a[s + i:]
# print(u)
sec_key = xxhash.xxh64_hexdigest(u, 41405)
# print(sec_key)
rc4_bytes = crypto_rc4(raw_bytes, sec_key)
# print(rc4_bytes)
pb_results = plistlib.loads(rc4_bytes, fmt=FMT_BINARY)
results = []
# print("最终结果为:")
# print(pb_results)
for x in pb_results:
# print(1111, type(x), x)
try:
data = x.get(b'k')
info = {'title': '', 'info': '', 'actor': '', 'url': ''}
for s in data:
if isinstance(s, list) and len(s) > 0 and s[0].get('title'):
# results = []
for x in s:
results.append({'title': x['title'].replace('\u200e', '').strip(),
'info': x.get('abstract'),
'actor': x.get('abstract_2'), 'url': x.get('url')})
# return results
if isinstance(s, str):
if 's_ratio_poster' in s and s.startswith('https://img'):
info['s_ratio_poster'] = s
elif '\u200e' in s:
info['title'] = s.replace('\u200e', '').strip()
elif s.startswith('https://movie.douban.com'):
info['url'] = s
elif ' / ' in s:
if s.endswith('分钟'):
info['info'] = s
else:
info['actor'] = s
if info and info['title'] and info['url']:
results.insert(0, dict(info.items()))
except Exception as e:
pass
return results
if __name__ == '__main__':
print(search_from_douban('流浪地球'))
剩下的添加
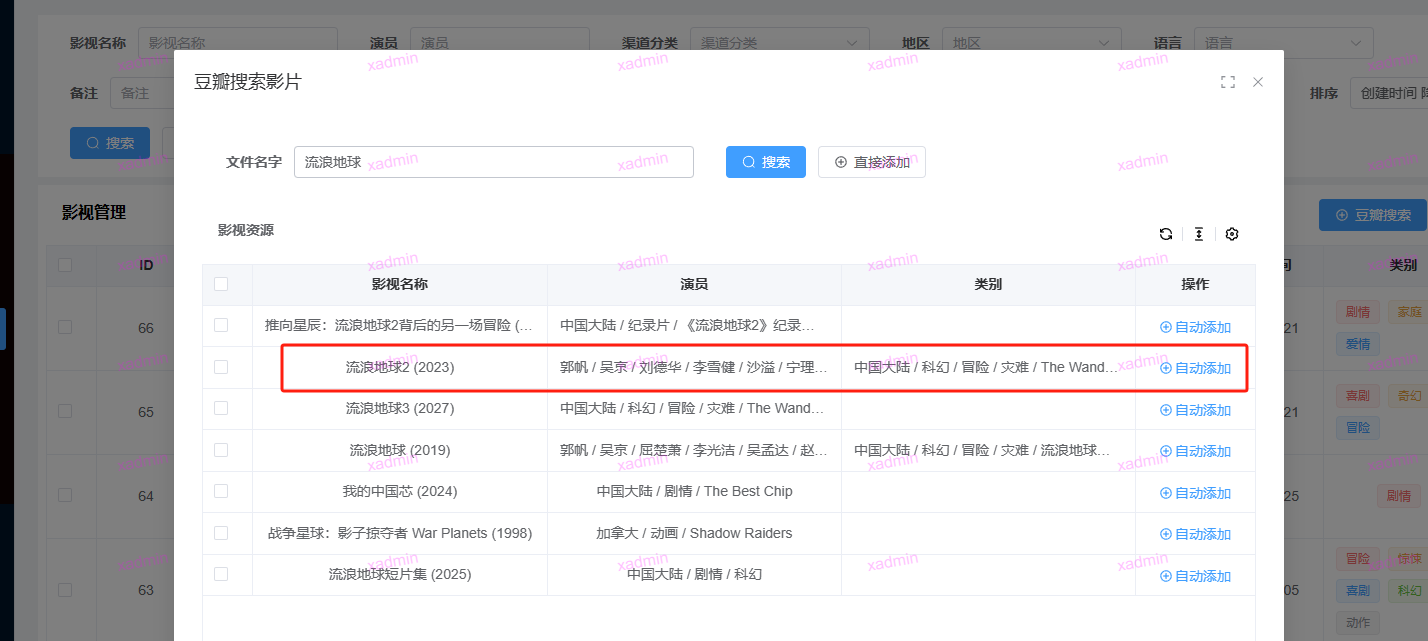
 相关功能代码参考如下:
相关功能代码参考如下:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









